在 Snowflake Notebooks 中开发和运行代码¶
本主题介绍如何在 Snowflake Notebooks 中编写和运行 SQL、Python 和 Markdown 代码。
笔记本单元格基础知识¶
本部分介绍一些基本单元格操作。当您 创建笔记本 时,会显示三个示例单元格。您可以修改这些单元格或者添加新的单元格。
创建新单元格¶
Snowflake Notebooks 支持三种类型的单元格:SQL、Python 和 Markdown。要创建新单元格,您可以将鼠标悬停在现有单元格上或滚动到笔记本的底部,然后选择要添加的其中一个单元格类型按钮。

使用以下方法之一为现有单元格更改语言:
选择语言下拉菜单,然后选择其他语言。
使用 键盘快捷键。
编辑单元格¶
为防止编辑冲突,一次仅有一名用户能编辑一个单元格。如有其他用户尝试编辑活动单元格,系统将显示通知。60 秒未活动后,单元格将可供编辑。
移动单元格¶
您可以通过使用鼠标拖放单元格或使用操作菜单来移动单元格:
(选项 1)将鼠标悬停在要移动的现有单元格上。选择单元格左侧的 |drag-drop|(拖放)图标,然后将单元格移动到新位置。
(选项 2)选择垂直省略号 |vertical-ellipsis|(操作)菜单。然后选择适当的操作。
备注
要在单元格之间移动焦点,请使用 向上 和 向下 箭头。
删除单元格¶
要删除单元格,请在笔记本中完成以下步骤:
选择垂直省略号 |vertical-ellipsis|(更多操作)菜单。
选择 Delete。
再次选择 Delete 以确认。
您还可以使用 键盘快捷键 来删除单元格。
使用 Python 和 SQL 单元格时的注意事项,请参阅 运行笔记本的注意事项。
在 Snowflake Notebooks 中运行单元格¶
要在 Snowflake Notebooks 中运行 Python 和 SQL 单元格,您可以:
运行单个单元格:频繁更新代码时请选择此选项。
在 Mac 键盘上按 CMD + return,或在 Windows 键盘上按 CTRL + Enter。
选择
 或 Run this cell only。
或 Run this cell only。
按顺序运行笔记本中的所有单元格:在演示或共享笔记本之前选择此选项,以确保收件人看到最新的信息。此选项从上到下执行笔记本中的所有 SQL 和 Python 代码单元格。如有任何单元格出现错误,执行将会停止,后续单元格将不会运行。此行为也适用于已计划的笔记本。例如,如果运行一个包含 10 个单元格的笔记本,并且在单元格 2 中存在 SQL 语法错误,则该笔记本将在单元格 2 之后停止运行。
在 Mac 键盘上按 CMD + shift + return,或在 Windows 键盘上按 CTRL + Shift + Enter。
选择 Run all。
运行单元格并前进到下一个单元格:选择此选项可以运行单元格并更快地前进到下一个单元格。
在 Mac 键盘上按 shift + return,或在 Windows 键盘上按 Shift + Enter。
选择垂直省略号 |vertical-ellipsis|(更多操作)单元格,然后选择 Run cell and advance。
运行上述全部:运行引用早期单元格结果的单元格时选择此选项。
选择垂直省略号 |vertical-ellipsis|(更多操作)单元格,然后选择 Run all above。
运行以下全部:运行后续单元格所依赖的单元格时选择此选项。此选项运行当前单元格和所有后续单元格。
选择垂直省略号 |vertical-ellipsis|(更多操作)单元格,然后选择 Run all below。
当一个单元格正在运行时,其他运行请求将排队,并将在当前正在运行的单元格完成后执行。
折叠和展开单元格¶
您可以通过选择笔记本顶部的其中一个单元格显示选项来控制笔记本的可见程度:
选择垂直省略号 |vertical-ellipsis|(更多操作)菜单。
选择 Show/hide all 并选择相应的选项:
显示全部: 显示每个单元格的代码和结果。
仅显示代码: 隐藏结果并仅显示代码单元格。
仅显示结果: 隐藏代码并仅显示输出。
全部隐藏: 折叠所有单元格的代码和结果。
这些选项在以下情况下很有用:
您想专注于阅读代码或查看结果。
您正在展示或共享您的笔记本。
您需要更高效地浏览大型笔记本。
复制单元格¶
复制单元格可以帮助解决以下问题:
测试查询或函数的变体。
在不替换工作版本的情况下进行调试。
并排比较不同的输出。
在不丢失原始单元格的情况下重复使用代码或修改现有单元格。
要复制笔记本单元格,请执行以下操作:
在要复制的单元格中,选垂直省略号 |vertical-ellipsis|(更多操作)菜单。
选择 Duplicate。
单元格的副本会紧接着出现在原始单元格的下方。
单元格小地图¶
单元格小地图显示在笔记本的右侧栏中,提供了笔记本中所有单元格的可拖动紧凑列表。小地图中的每个条目对应于一个代码或文本单元格,并反映了单元格出现的顺序。
当前单元格: 所选单元格将在小地图中突出显示。
重新排序: 在小地图中拖放项目可快速更改笔记本中单元格的顺序。
导航: 点击小地图中的单元格名称可直接跳转到该单元格。
此功能对于更有效地浏览大型笔记本和重新组织内容非常有用。
带参数运行笔记本¶
当你使用 EXECUTE NOTEBOOK 命令运行笔记本时,可以向笔记本传递实参。在笔记本的 Python 单元格中,您可以使用 sys.argv 变量访问这些实参,该变量是 Python 内置列表,用于存储命令行实参。
通过向笔记本传递实参,您可以自定义笔记本行为。您可以:
对笔记本执行进行个性化或自定义。
重复使用同一笔记本进行多次输入。
支持自动化或任务调度。
示例¶
在笔记本的 Python 单元格中,您可以使用 sys.argv 变量访问这些实参。
查看传递给笔记本的所有实参¶
打印传递给笔记本的完整实参列表。
如果使用以下命令执行笔记本:
输出将是:
打印每个实参¶
循环遍历并单独打印每个实参。
输出将是:
访问特定实参¶
访问第二个实参。
输出将是:
解析包含逗号分隔值的实参¶
如果实参包含逗号分隔的值列表,可以将其拆分为单独的值。
输出将是:
您也可以循环遍历这些值:
提取包含键值对的实参¶
如果实参包含键值对(例如 key=value),则提取该值。
输出将是:
单个字符串的替代语法¶
您可以将 会话变量 设置为实参的值,并将会话变量传递给笔记本。
查看参数化运行的结果¶
要查看通过 EXECUTE NOTEBOOK 触发的笔记本运行结果,请执行以下步骤:
Sign in to Snowsight.
In the navigation menu, select Projects » Notebooks.
选择 Calendar 图标。
选择 View run history。
找到对应的笔记本执行记录并打开结果。
系统将打开一个只读笔记本,显示该次运行的结果。
备注¶
sys.argv仅包含通过 EXECUTE NOTEBOOK 传递的字符串。仅支持字符串类型。如果传递了其他数据类型(例如整数),则会将其解释为 NULL。有关更多信息,请参阅 EXECUTE NOTEBOOK。
检查单元格状态¶
单元格运行的状态由单元格显示的颜色表示。此状态颜色显示在两个位置:单元格的左侧边框和右侧的单元格导航图中。
单元格状态颜色:
蓝点:该单元格已被修改但尚未运行。
红色:该单元格在当前会话中运行,并且发生了错误。
绿色:该单元格在当前会话中运行,没有错误。
移动绿色:该单元格当前正在运行。
灰色:该单元格已在上一次会话中运行,显示的结果来自上一次会话。上一次交互式会话的单元格结果将保留 7 天。交互式会话意味着用户在 Snowsight 中以交互方式运行笔记本,而不是按照计划或 EXECUTE NOTEBOOK SQL 命令运行。
灰色闪烁:选择 Run All 后,单元格正在等待运行。
备注
Markdown 单元格不显示任何状态。
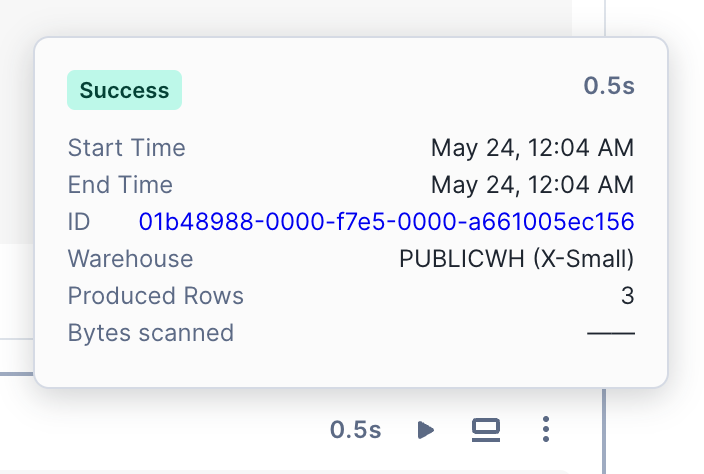
单元格运行完成后,运行所花费的时间将显示在单元格的顶部。选择此文本可查看运行详细信息,包括开始和结束时间以及总耗时。
SQL 单元格包含其他信息,例如用于运行查询的仓库、返回的行以及指向查询 ID 页面的超链接。
停止正在运行的单元格¶
要停止执行当前正在运行的任意代码单元格,请选择单元格右上角的 Stop。您还可以选择笔记本页面右上角的 Stop。单元格正在运行时,Run all 变成 Stop。
这会停止执行当前正在运行的单元格以及所有已计划运行的后续单元格。
键盘快捷键¶
Snowflake Notebooks 支持多种键盘快捷键,帮助加速您的开发过程。
您也可以选择右下角的图标,然后选 Keyboard shortcuts 来查看键盘快捷键的列表。
任务 |
MacOS |
Windows |
|---|---|---|
运行所有单元格 |
CMD + Shift + Return |
CTRL + Shift + Enter |
运行所选单元格 |
CMD + Return |
CTRL + Enter |
运行所选单元格并前进到下一个单元格 |
Shift + Return |
Shift + Enter |
在单元格之间移动 |
向上 和 向下 箭头 |
向上 和 向下 箭头 |
停止所有单元格 |
ii |
ii |
在单元格内查找 |
CMD + f |
CTRL + f |
上移单元格 |
CMD + SHIFT + 向上 箭头 |
CTRL + SHIFT + 向上 箭头 |
下移单元格 |
CMD + SHIFT + 向下 箭头 |
CTRL + SHIFT + 向下 箭头 |
在当前选定单元格上方添加一个单元格 |
a |
a |
在当前选定单元格下方添加一个单元格 |
b |
b |
删除当前选定的单元格 |
dd 或 DELETE |
dd 或 DELETE |
将一个 SQL 或 Python 单元格转换为 Markdown 单元格 |
m |
m |
将一个单元格转换为代码单元格:
|
y |
y |
显示键盘快捷键 |
Shift + ? |
Shift + ? |
此外,您还可以使用与工作表相同的键盘快捷键。请参阅 使用键盘快捷键执行任务。
使用 Markdown 格式化文本¶
要将 Markdown 包含在笔记本中,请添加一个 Markdown 单元格:
使用 键盘快捷键 并选择 Markdown,或选择 + Markdown。
选择 Edit markdown 铅笔图标或双击单元格,开始编写 Markdown。
您可以输入有效的 Markdown 来格式化文本单元格。键入时,格式化的文本会显示在 Markdown 语法下方。
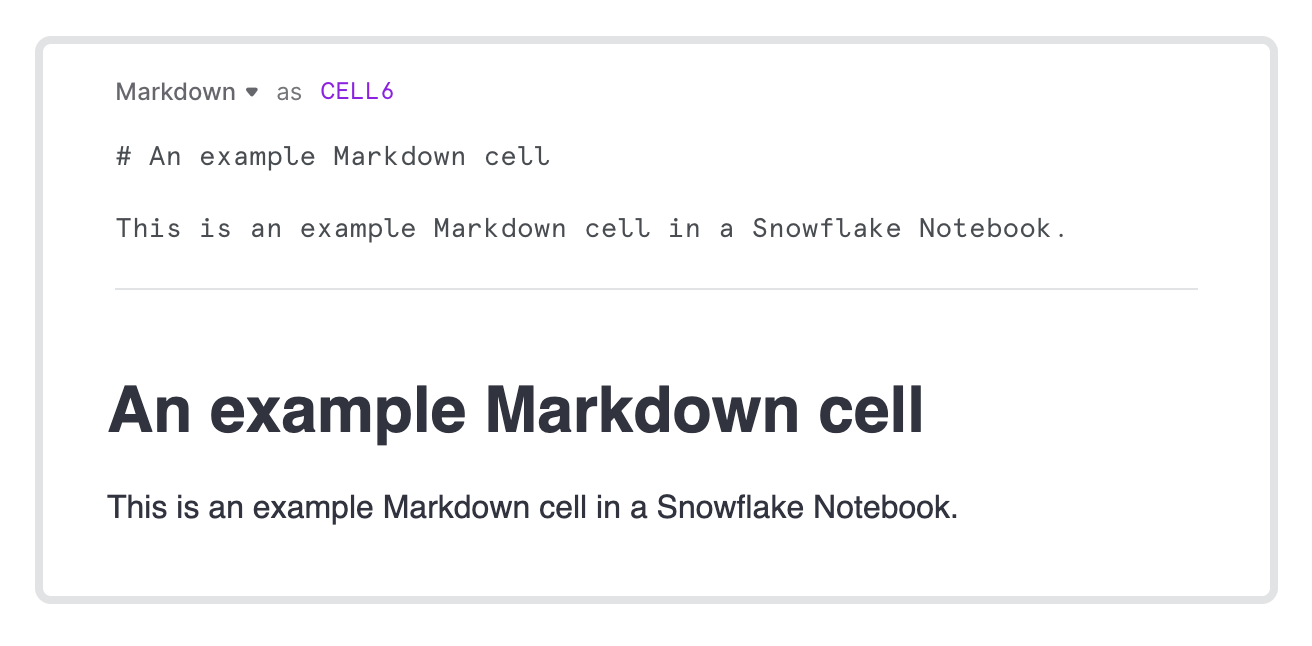
要仅查看格式化的文本,请选择 Done editing 复选标记图标。

备注
Markdown 单元格目前不支持 HTML 渲染。
Markdown 基础知识¶
本部分介绍基本的 Markdown 语法,帮助您入门。
标头
标题级别 |
Markdown 语法 |
示例 |
|---|---|---|
顶级 |

|
|
2 级 |

|
|
3 级 |

|
内联文本格式
文本格式 |
Markdown 语法 |
示例 |
|---|---|---|
斜体 |

|
|
粗体 |

|
|
链接 |

|
列表
列表类型 |
Markdown 语法 |
示例 |
|---|---|---|
有序列表 |

|
|
无序列表 |

|
代码格式
语言 |
Markdown 语法 |
示例 |
|---|---|---|
Python |
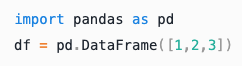
|
|
SQL |

|
嵌入图像
文件类型 |
Markdown 语法 |
示例 |
|---|---|---|
图像 |

|
有关演示这些 Markdown 示例的笔记本,请参阅视觉数据故事笔记本中的 Markdown 单元格 (https://github.com/Snowflake-Labs/snowflake-demo-notebooks/blob/main/Visual%20Data%20Stories%20with%20Snowflake%20Notebooks/Visual%20Data%20Stories%20with%20Snowflake%20Notebooks.ipynb) 部分。
了解单元格输出¶
运行 Python 单元格时,笔记本会在结果中显示单元格的以下输出类型:
写入控制台的任何结果,例如日志、错误、警告以及来自 print() 语句的输出。
使用 Streamlit 的交互式表 (https://docs.streamlit.io/develop/api-reference/data/st.dataframe),
st.dataframe()时自动打印 DataFrames。支持的 DataFrame 显示类型包括 pandas DataFrame、Snowpark DataFrames 和 Snowpark Tables。
对于 Snowpark,会立即评估已打印的 DataFrames,无需运行
.show()命令。如果您不想立即评估 DataFrame,例如,在非交互模式下运行笔记本时,Snowflake 建议删除 DataFrame 打印语句来加快 Snowpark 代码的整体运行时。
可视化效果在输出中呈现。要了解有关数据可视化的更多信息,请参阅 Snowflake Notebooks 中的可视化数据。
此外,您可以在 Python 中访问 SQL 查询的结果,反之亦然。请参阅 在 Snowflake Notebooks 中引用单元格和变量。
单元格输出限制¶
仅 10,000 行或 8 MB 的 DataFrame 输出显示为单元格结果,以较低者为准。然而,整个 DataFrame 仍可在笔记本会话中使用。例如,即使未渲染整个 DataFrame,您仍然可以执行数据转换任务。
每个单元格最多允许 20 MB 的输出。如果单元格输出的大小超过 20 MB,输出将会删除。如果发生这种情况,请考虑将内容拆分为多个单元格。
在 Snowflake Notebooks 中引用单元格和变量¶
您可以在笔记本单元格中引用前一个单元格结果。例如,引用 SQL 单元格的结果或者 Python变量的值,请参阅下表:
备注
引用的单元格名称区分大小写,并且必须与所引用单元格的名称完全匹配。
在 Python 单元格中引用 SQL 输出:
引用单元格类型 |
当前单元格类型 |
引用语法 |
示例 |
|---|---|---|---|
SQL |
Python |
|
将 SQL 结果表转换为 Snowpark DataFrame。 如果在名为 您可以引用单元格来访问 SQL 结果: 将结果转换为 pandas DataFrame: |
引用 SQL 代码中的变量:
重要
在 SQL 代码中,您只能引用类型 string 的 Python 变量。您不能引用 Snowpark DataFrame、pandas DataFrame 或其他 Python 原生 DataFrame 格式。
引用单元格类型 |
当前单元格类型 |
引用语法 |
示例 |
|---|---|---|---|
SQL |
SQL |
|
例如,在名为 |
Python |
SQL |
|
例如,在名为 使用 Python 变量作为值 您可以在名为 使用 Python变量作为标识符 如果 Python 变量表示 SQL 标识符(如列名或表名): 如果 Python 变量表示 SQL 标识符,例如列名或表名 ( 确保区分用作值(带引号)和用作标识符(不带引号)的变量。 注意:不支持引用 Python DataFrames。 |
运行笔记本的注意事项¶
笔记本以调用方权限运行。有关其他注意事项,请参阅 更改笔记本的会话上下文。
您可以导入 Python 库以在笔记本中使用。有关详细信息,请参阅 导入 Python 包以在笔记本中使用。
在 SQL 单元格中引用对象时,您必须使用完全限定的对象名称,除非您引用的是指定数据库或架构中的对象名称。请参阅 更改笔记本的会话上下文。
笔记本草稿每三秒钟保存一次。
您可以使用 Git 集成 来维护笔记本版本。
您可以配置空闲超时设置,以便在满足设置后自动关闭笔记本会话。有关信息,请参阅 空闲时间和重新连接。
笔记本单元格结果仅对运行笔记本的用户可见,并在会话之间缓存。重新打开笔记本会显示用户上次使用 Snowsight 运行笔记本时的结果。
BEGIN ...END (Snowflake Scripting) 在 SQL 单元格中不受支持。相反,在 Python 单元格中使用 Session.sql().collect() 方法运行脚本块。链接
sql调用与collect调用以立即执行 SQL 查询。以下代码使用
session.sql().collect()方法运行 Snowflake Scripting 块: