设置 Snowflake Notebooks¶
Snowflake Notebooks 是存储在数据库下架构中的一级对象。它们可以在两种计算架构上运行:仓库和容器。本主题提供以管理员身份设置账户并开始使用 Snowflake Notebooks 的步骤。
管理员设置¶
要使用 Snowflake Notebooks 设置组织,请执行以下步骤:
查看账户和部署要求¶
确保 *.snowflake.app 和 *.snowflake.com 在您网络(包括内容筛选系统)的允许列表中,并且可以连接到 Snowflake。对于使用容器运行时的 Streamlit 应用程序,还要将 *.snowflakecomputing.app 添加到允许列表。当这些域名列入允许列表时,您的应用程序可以不受任何限制地与 Snowflake 服务器通信。但是,在某些情况下,由于网络策略阻止了这些域下的子路径,因此添加这些域可能还不够。如果发生这种情况,请联系网络管理员。
此外,为防止连接到 Snowflake 后端出现任何问题,请确保网络配置中未阻止 WebSockets。
使用 Anaconda 的第三方包¶
Snowflake 提供对 Anaconda 构建的一组精选 Python 包的访问权限。这些包直接集成到 Snowflake 的 Python 功能中,无需额外费用。
许可条款¶
在 Snowflake 中: 受现有 Snowflake 客户协议的约束,包括本文档中描述的 Anaconda 使用限制。在 Snowflake 中使用时,无需单独遵守 Anaconda 条款。
本地开发: 来自 Snowflake 的 专用 Anaconda 存储库 (https://repo.anaconda.com/pkgs/snowflake/):遵守发布在存储库上的 Anaconda 嵌入式最终客户条款和 Anaconda 服务条款。本地使用仅限于开发/测试预期部署在 Snowflake 上的工作负载。
创建资源并授予权限¶
要创建笔记本,角色需要具有以下资源的权限:
位置的 CREATE NOTEBOOK 权限
计算资源的 USAGE 权限
(可选)外部访问集成 (EAIs) 的 USAGE 权限
有关为这些资源创建和授予权限的示例脚本,请参阅 笔记本设置模板。
位置¶
位置是指存储笔记本对象的地方。最终用户可以查询其角色有权限访问的任何数据库和架构。
要将上下文切换到不同的数据库或模式,可以在 SQL 单元格中使用 USE DATABASE 或 USE SCHEMA 命令。
在容器运行时中,创建笔记本的角色还需要具有架构的 CREATE SERVICE 权限。
权限 |
对象 |
|---|---|
USAGE |
数据库 |
USAGE |
架构 |
CREATE NOTEBOOK |
架构 |
CREATE SERVICE |
架构 |
拥有架构的角色自动具有在该架构下创建笔记本的权限,因为所有者可以创建任何类型的对象,包括笔记本。
权限 |
对象 |
|---|---|
USAGE |
数据库 |
OWNERSHIP |
架构 |
计算资源¶
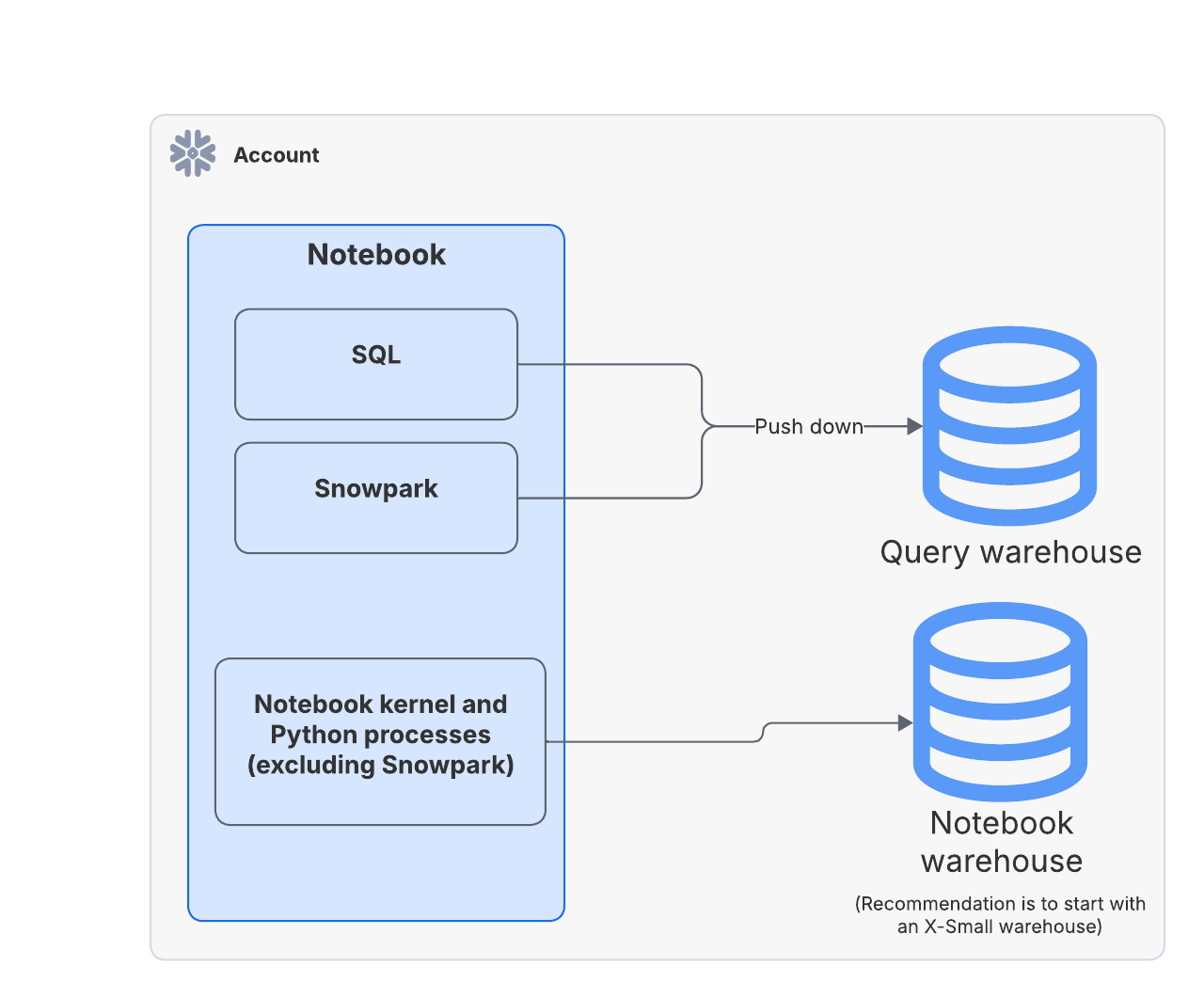
在仓库运行时中,笔记本的引擎和在笔记本中编写的代码的 Python 进程都在笔记本仓库中运行,但 SQL 查询和 Snowpark 向下推送查询则在查询仓库中运行。笔记本的所有者角色需要在两个仓库中都拥有 USAGE 权限。
如果笔记本在容器运行时中运行,则角色需要对计算池(而不是在笔记本仓库中)拥有 USAGE 权限。计算池是由 Snowflake 管理的基于 CPU 或 GPU 的虚拟机。创建计算池时,需要将 MAX_NODES 参数设置为大于 1,因为每个笔记本需要一个完整的节点来运行。有关信息,请参阅 Snowpark Container Services:使用计算池。
权限 |
对象 |
|---|---|
USAGE |
笔记本仓库或计算池 |
USAGE |
查询仓库 |
外部访问集成(可选)¶
如果您允许某些角色访问外部网络,可以使用 ACCOUNTADMIN 角色来设置并授予外部访问集成 (EAIs) 的 USAGE 权限。EAIs 允许访问特定的外部端点,以便您的团队可以下载数据和模型、发送 API 请求和响应、登录其他服务等。对于在容器运行时运行的笔记本,EAIs 还允许您的团队从 PyPi 和 Hugging Face 等仓库安装包。
有关如何为您的笔记本设置 EAI 的详细信息,请参阅 为 Snowflake Notebooks 设置外部访问。
权限 |
对象 |
|---|---|
USAGE |
外部访问集成 |
笔记本设置模板¶
由于笔记本是具有基于角色的创建和所有权权限的对象,因此您可以配置对笔记本功能的访问权限,以满足您的组织和团队的需求。以下是一些示例:
允许所有人在特定位置创建笔记本¶
以下步骤概述了如何通过授予对数据库和架构的使用权限来配置在特定位置创建笔记本的访问权限。
将 <database> 和 <database.schema> 替换为要在其中创建笔记本的特定数据库和架构:
创建专用角色¶
如果您只希望特定用户创建笔记本(假设他们还没有 OWN 任何架构),您可以创建一个专用角色来控制访问权限。例如:
将 ROLE notebook_rl 授予特定用户。然后,使用上述脚本为该角色创建资源并授予权限(将 ROLE PUBLIC 替换为 ROLE notebook_rl)。
笔记本引擎¶
笔记本引擎(“内核”)和 Python 进程在笔记本仓库上运行。Snowflake 建议您一开始先使用“X-小”仓库,以尽量减少 Credit 消耗。
当您使用笔记本时(例如,编辑代码、运行、重新排序或删除单元格),或者如果笔记本在其空闲超时设置内保持活动状态,将持续运行 EXECUTE NOTEBOOK 查询,以指示笔记本引擎处于活动状态,并且正在使用笔记本会话。您可以在 Query history 中查看该查询的状态。EXECUTE NOTEBOOK 运行时,笔记本仓库也在运行。当 EXECUTE NOTEBOOK 结束时,如果仓库中没有其他查询或任务在运行,它将根据自动暂停策略关闭。
要结束 EXECUTE NOTEBOOK 查询(结束笔记本会话),请按照以下步骤操作:
选择 Active 或从 Active 下拉菜单中选择 End session。
在 Query history 中,找到相应的 EXECUTE NOTEBOOK 查询并选择 Cancel query。
根据笔记本的闲置时间设置,让笔记本因闲置而超时。如果笔记本仓库的 STATEMENT_TIMEOUT_IN_SECONDS 和 STATEMENT_QUEUED_TIMEOUT_IN_SECONDS 参数的值设置得较小,笔记本可能会迅速关闭或无法启动,无论用户是否进行操作。
查询¶
SQL 和 Snowpark 查询(例如,session.sql)会下推到按需使用的查询仓库。当 SQL 和 Snowpark 查询完成运行后,如果没有其他作业在其上运行,查询仓库会挂起。请选择适合您查询性能需求的仓库大小。例如,如果需要运行大规模的 SQL 查询或进行计算密集型操作(如使用 Snowpark Python 的计算任务),您可能需要选择更大的仓库。对于需要大量内存的操作,考虑使用 经过优化的 Snowpark 仓库。
您可以在 Notebook Settings 中更改查询仓库。或者,您也可以在笔记本中的任何 SQL 单元格运行以下命令,以更改当前笔记本会话中所有后续查询的查询仓库:
空闲时间和重新连接¶
如果用户未执行任何操作(例如编辑代码、运行单元格、重新排序单元格或删除单元格),则空闲时间会累积。每次恢复活动时,空闲时间都会重置。空闲时间达到超时设置后,笔记本会话将自动关闭。
默认情况下,笔记本在闲置一段时间后会暂停。默认空闲超时取决于运行时:
仓库运行时笔记本: 闲置 30 分钟(1,800 秒)
容器运行时笔记本: 闲置 60 分钟(3,600 秒)
您可以将空闲超时设为最大 72 小时(259,200 秒)。要更新空闲超时设置,请使用 CREATE NOTEBOOK 或 ALTER NOTEBOOK 命令来设置 IDLE_AUTO_SHUTDOWN_TIME_SECONDS 属性的值。
登录 Snowsight。
在导航菜单中,选择 Projects » Notebooks。
打开您要更新的笔记本。
选择笔记本右上角的垂直省略号 (
 ) 菜单。
) 菜单。选择 Notebook settings。
选择 Owner。
从下拉列表中选择空闲超时设置。
手动重新启动会话以使新的空闲时间生效。
在闲置超时之前,即使您刷新页面、访问 Snowsight 的其他部分或关闭或休眠计算机,您的笔记本会话仍将保持活动状态,直到达到闲置超时时间。当您重新打开相同的笔记本时,您会重新连接到同一个会话,并且所有会话状态和变量都会保留,让您能够无缝继续工作。但请注意,Streamlit 小部件的状态将不会保留。
运行同一笔记本的每个用户都有自己独立的会话。它们互不干扰。
优化成本的建议¶
作为账户管理员,请考虑以下建议来控制运行笔记本的成本:
要求您的团队使用相同的仓库(建议使用“X-小”)作为专用的“笔记本仓库”来运行笔记本会话,以增加并发性。请注意,如果要同时执行的笔记本数量过多,可能会导致会话启动速度变慢(在仓库中排队)或内存不足错误。
允许团队使用 STATEMENT_TIMEOUT_IN_SECONDS 值较低的仓库来运行笔记本。该仓库参数控制任何查询(包括笔记本会话)可以持续多长时间。例如,如果将该参数设置为 10 分钟,则不论用户是否在笔记本会话中活动,笔记本会话最大可以运行 10 分钟。
要求团队在不打算在会话中继续活跃工作的情况下结束笔记本会话。
如果团队不需要长时间运行会话,请将空闲超时设置降至最低(例如 15 分钟)。
或者,提交支持工单,设置适用于整个账户的空闲时间默认值。笔记本所有者仍可在笔记本级别覆盖该值。
通过添加数据开始使用笔记本¶
开始使用 Snowflake Notebooks 之前,要先将数据添加到 Snowflake 中。
您可以通过多种方式向 Snowflake 添加数据:
使用 Web 界面将 CSV 文件中的数据添加到表中。请参阅 使用 Snowsight 加载数据。
从外部云存储添加数据:
要从 Amazon S3 加载数据,请参阅 从 Amazon S3 批量加载。
要从 Google Cloud Storage 加载数据,请参阅 从 Google Cloud Storage 批量加载。
要从 Microsoft Azure 加载数据,请参阅 从 Microsoft Azure 批量加载。
以编程方式批量添加数据。请参阅 从本地文件系统批量加载。
您还可以通过其他方式添加数据。有关详细信息,请参阅 数据加载概述。