从 Amazon S3 批量加载¶
If you already have an Amazon Web Services (AWS) account and use S3 buckets for storing and managing your data files, you can make use of your existing buckets and folder paths for bulk loading into Snowflake. This set of topics describes how to use the COPY command to bulk load from an S3 bucket into tables.
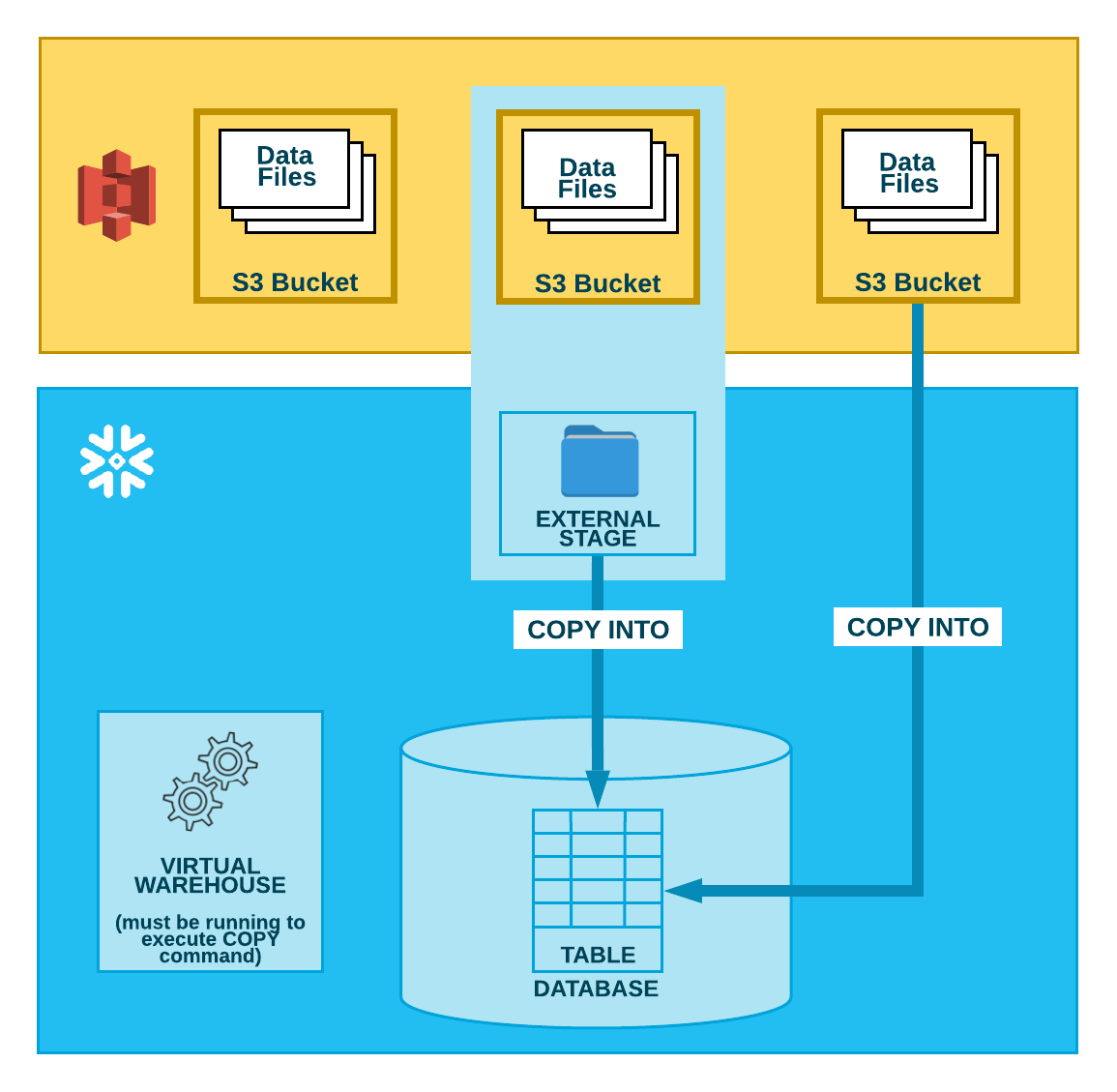
如下图所示,要从 S3 桶中加载数据,分两步执行:
- 第 1 步:
Snowflake 假定数据文件已暂存在 S3 桶中。如果尚未暂存,请使用 AWS 提供的上传界面/实用程序来暂存文件。
- 第 2 步:
使用 COPY INTO <table> 命令将暂存文件的内容加载到 Snowflake 数据库表中。您可以直接从桶中加载,但 Snowflake 建议创建一个引用该桶的外部暂存区,然后使用外部暂存区。
无论您使用哪种方法,如果您手动或在脚本中执行命令,此步骤都需要运行一个当前虚拟仓库的会话。仓库提供计算资源,以执行将行实际插入到表中的操作。
备注
Snowflake 在其每个 Amazon Virtual Private Cloud 中使用 Amazon S3 网关端点。
只要您的 Snowflake 账户托管在 AWS 上,您的网络流量就不会穿过公共互联网。无论您的 S3 桶位于哪个区域,都是如此。
后续主题:
配置任务(根据需要完成):
数据加载任务(针对您加载的每组文件完成):