用于加载数据的 Snowpipe REST 端点概述¶
本主题概述调用公共 REST 端点加载数据和检索加载历史记录报告时的使用详细信息。
身份验证¶
对公共 Snowpipe REST 端点的调用使用基于密钥的身份验证,而不是常见的用户名/密码身份验证,因为引入服务不会维护客户端会话。
为了遵循最小权限的一般原则,我们建议使用管道创建单独的用户和角色以用于引入文件。创建用户时应将此角色作为其默认角色,并且该角色应具有将文件插入目标表以进行数据加载所需的较低权限集。
流程流¶
客户端应用程序使用数据文件名列表和引用的管道名(为方便起见,提供了 Java 和 Python SDKs)调用公共 REST 端点。如果在暂存区中发现与列表匹配的新数据文件,则将为它们排队以等待加载。Snowflake 提供的计算资源会根据管道中定义的参数将数据从队列加载到 Snowflake 表中。
下图显示了 Snowpipe REST API 的流程流:
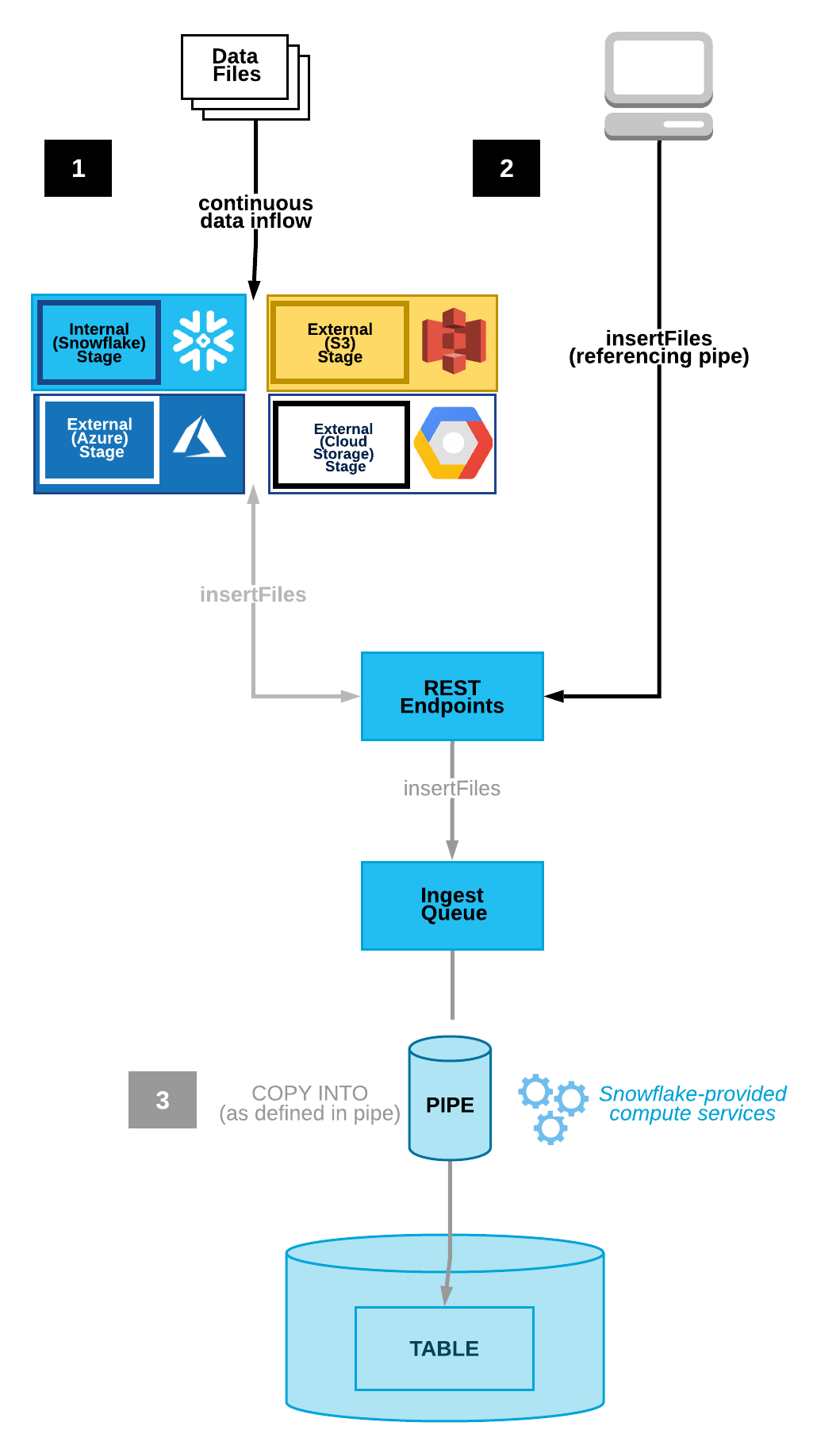
数据文件会复制到内部 (Snowflake) 或外部(Amazon S3、Google Cloud Storage 或 Microsoft Azure)暂存区。
客户端使用要引入的文件列表和已定义的管道调用
insertFiles端点。端点会将这些文件移动到引入队列。
Snowflake 提供的虚拟仓库根据指定管道中定义的参数将数据从排队文件加载到目标表中。
工作流程¶
本部分简要概述了设置和加载工作流程。
配置 Snowpipe¶
创建一个已命名的暂存区对象,您的数据文件将暂存在其中。Snowpipe 支持内部(Snowflake)暂存区和外部暂存区,即 S3 桶。
使用 CREATE PIPE 创建管道对象。
为将执行连续数据加载的用户配置安全性。如果计划将 Snowpipe 数据加载限制为单个用户,则只需为该用户配置一次密钥对身份验证。在此之后,您只需要为用于每次数据加载的数据库对象授予访问控制权限即可。
安装客户端 SDK(Java 或 Python),用于调用 Snowpipe 公共 REST 端点。
使用 Snowpipe REST API 加载数据¶
选项 1:使用客户端调用 REST API¶
使用客户端调用 REST API。提供了Java 和 Python SDK 示例代码。有关更多信息,请参阅 Option 1: Load data with the Snowpipe REST API。
调用 REST 端点,其中包含暂存时要加载的文件列表。
检索加载历史记录。
选项 2:使用 AWS Lambda 来调用 REST API¶
使用 AWS Lambda 函数来调用 REST API,从而自动化 Snowpipe。Lambda 函数可以调用 REST API,仅从存储在 Amazon S3 中的文件加载数据。有关更多信息,请参阅 Option 2: Automate Snowpipe with AWS Lambda。
Create an AWS Lambda function that calls the Snowpipe REST API to load data from your external (i.e. S3) stage.
检索加载历史记录。