在工作区中编辑和运行笔记本¶
设置执行上下文¶
工作区中的笔记本不会自动设置数据库或架构。要查询数据,必须在单元格中使用以下 SQL 命令定义执行上下文:
为确保笔记本在不同环境和客户端中一致运行,请对表和其他对象使用完全限定名称。例如:
使用角色和仓库选择器¶
可以为笔记本设置活动角色和仓库。
使用笔记本编辑器左上角的选择器:
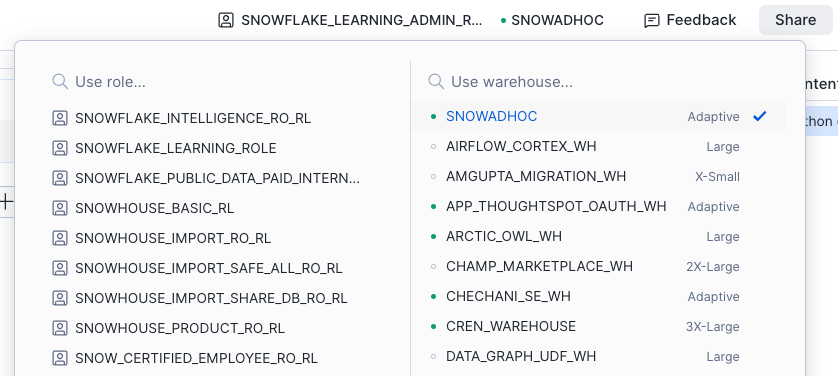
请运行以下 SQL 命令:
查询仓库用于执行笔记本调用的 SQL 查询和 Snowpark 下推计算。它还用于呈现交互式数据网格,但此操作不消耗 Credit。
有关 Credit 使用详情,请参阅 设置计算。
创建 Snowpark 会话¶
Snowpark 是一个 Snowflake 开发者框架,可用于直接在 Snowflake 内部构建数据管道、转换和机器学习逻辑,而无需将数据移出平台。它提供将 Snowflake 数据作为 DataFrames 进行操作的 APIs,将计算推送到 Snowflake 的引擎,以实现可扩展性、高性能和安全性。
要在笔记本中使用 Snowpark Python APIs,请首先在 Python 单元格中创建 Snowpark 会话:
运行单元格¶
支持四种执行选项:
运行所有单元格
运行单个单元格
运行当前单元格及其上方的所有单元格(通过单元格的省略号菜单)
运行当前单元格及其下方的所有单元格(通过单元格的省略号菜单)
取消单元格执行¶
可在笔记本顶部使用 Stop,或在单元格中使用 Cancel execution。
这两种操作都会停止当前正在执行的单元格,以及由 Run all 触发的任何排队单元格。
备注
当笔记本正在连接或重新连接服务时,Run all 按钮可能会暂时显示为 Stop。
单元格名称¶
您可以为单元格命名,以便更方便地导航,并提供上下文标签。
如果导入的 .ipynb 文件已包含名称或标题元数据,将自动使用这些值。
单元格引用¶
双向 SQL 与 Python 单元格引用可在两种语言间重用结果和变量,从而实现 SQL 与 Python 工作流程的无缝衔接。
您可以将鼠标悬停在结果提示工具上,查看可在 Python 和 SQL 中引用该结果的 DataFrame 名称。
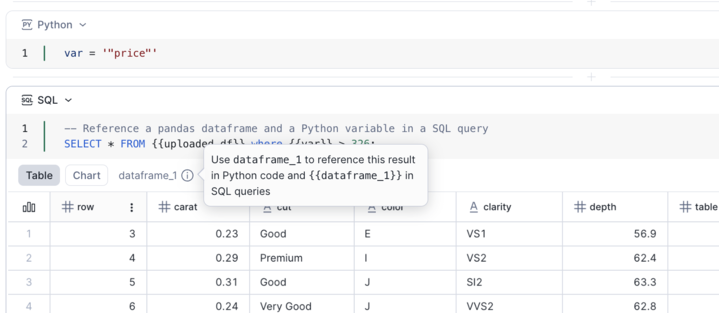
引用 SQL 单元格结果¶
每个 SQL 单元格会将其结果公开为名为 dataframe_x 的 Pandas DataFrame 指针。
在 SQL 中,可使用双花括号引用它:
{{dataframe_1}}。在 Python 中,可直接将其作为 Pandas DataFrame 引用:
dataframe_1。
引用 Python 变量¶
在 SQL 查询中引用 Python 变量时,请将变量放在双花括号内。例如:
在 SQL 中引用 Python 变量时,同样支持 DataFrame 变量。
示例工作流程¶
Python 单元格
SQL 单元格引用 Python 变量
SQL 单元格引用 SQL 单元格结果
SQL 单元格的结果会提供名为 dataframe_1 的 DataFrame 指针。您可以在另一个 SQL 查询中引用它:
交互式数据网格¶
数据网格支持:
滚动
搜索
筛选
排序
无需代码即可创建图表
内置图表生成器¶
在工作区的各编辑界面中,为数据操作和可视化提供一致的用户体验。
小地图与单元格状态¶
小地图会根据 Markdown 标题生成目录,并显示每个单元格的会话状态,包括正在运行、已成功、失败及已修改。
全局搜索和替换¶
您可以在当前笔记本的所有单元格中搜索关键字。如果要编辑特定单元格,请按 esc 首先退出该单元格的编辑模式。
要在当前笔记本的所有单元格中搜索关键字,请执行以下操作:
要搜索关键字,请在小地图中选择 Search,或使用键盘快捷键 CTRL + F。
显示所有单元格中的匹配关键字。(可选)您可以使用 Replace next 或 Replace all 将搜索词替换为所需值。
笔记本内核¶
只要笔记本服务处于 RUNNING 状态,笔记本内核就会保持活动,从而允许关键的长时间运行任务(例如 ML 训练和数据工程作业)连续执行。
不影响内核执行的操作:
浏览其他页面
在 Snowsight 的其他位置工作
关闭浏览器
关闭计算机
您可以通过 Connected 下拉菜单关闭或重启内核。
备注
使用 Shut down kernel 或 Restart kernel 将清除内存中的变量,但会保留任何用户安装的包。如果您想要一个仅包含预装包的纯净环境,则必须重新启动服务,或创建一个新服务并连接到该服务。
如果笔记本服务被暂停,笔记本内核也会随之关闭。有关详细信息,请参阅 设置计算。
单元格输出¶
在工作区(包括私有工作区和共享工作区)的笔记本中,单元格输出内容仅对执行该笔记本的用户可见。
单元格输出不会保存到
.ipynb文件中。要导出和共享输出,请选择 Export as HTML。对于工作区中的交互式会话,可以从每个笔记本文件右上角的省略号菜单访问 Export as HTML。对于定时运行的笔记本,可以在每次历史执行的结果页面中访问该选项。导出的 HTML 文件具有以下行为:
每个单元格代码和输出的折叠状态会被保留。
表和 DataFrames 上限为 1,000 行,且默认为 Table 视图。您可以切换到 Chart 并在 HTML 文件中进行配置。
Jupyter 魔法¶
工作区中的笔记本运行 IPython(交互式 Python)内核,并提供标准 Jupyter 单元格和行魔法命令。运行 %lsmagic 可查看可用的魔法命令。
例如,您可以使用 %run magic 命令调用另一个笔记本:
在
notebook_a的 Python 单元格中,调用%run path/to/notebook_b.ipynb。此操作将在同一个 Python 进程中以notebook_a形式执行notebook_b。对于
notebook_b中用于渲染notebook_a单元格结果的变量和 Pandas DataFrames,请确保使用显式打印。例如:print(var)或display(df)。
开发者工具¶
开发者工具包括 Terminal、Scratchpad 和 Variables Explorer。这些工具允许您探索数据和笔记本环境并与之交互。
要访问开发者工具,请在笔记本顶部的控制栏中,选择 <icon>:ui:Tools。
必须连接到笔记本服务才能使用开发者工具。切换到其他服务会重启工具。
使用终端¶
终端允许您在笔记本的容器环境中运行任何 shell 命令:
安装依赖项 –
pip install、pip list,或检查已安装的包。管理文件 –
ls、pwd、导航目录和查看文件。运行并行作业
监控计算资源使用情况
安装并运行 htop 以实现实时监控计算资源使用情况的示例:
使用 Scratchpad¶
Scratchpad 是一个用于快速实验的探索空间(例如,实验代码、想法、计算或注释),无需担心结构或润色。在 Scratchpad 中执行的命令不会更改笔记本文件。
您可以在 Scratchpad 中执行以下操作:
快速临时查询 – 测试 SQL,而不会向笔记本添加单元格。
数据探索 – 验证表内容、架构或运行探索性查询。
调试 – 在将数据或查询片段添加到笔记本单元格之前先验证数据或测试查询片段。
一次性操作 – 运行不需要保存的命令(例如 SHOW GRANTS 或 DESCRIBE TABLE)。
结果在您工作时保持可见,但不会与笔记本一起保存。
使用 Variables Explorer¶
Variables Explorer 是一个可视化工具,可用于在交互工作时检查会话中当前加载的变量。它显示了每个变量的 Name、Type、Shape 和 Preview。当单元格完成运行时,变量会更新。