Cortex AI 函数:文档¶
Snowflake 提供由 AI 驱动的高级文档智能功能,作为 Cortex AI 函数。这些函数可帮助您处理、解析、分类和提取各种文档类型的信息,以支持分析、自动化和智能应用,所有操作均使用简单的 SQL。文档函数可帮助您完成以下任务:
- 解析文档,将非结构化文本和布局转换为结构化、可搜索、可分析的内容。
- 从文档中 提取结构化信息(实体、表或字段)。
- 对文档类型进行分类,以支持下游工作流程和分析。
Cortex 文档处理函数可以组合使用,以构建检索增强生成 (RAG) 管道、智能搜索与聊天机器人系统,以及大规模文档分析。下图展示了 Cortex 文档处理函数如何形成可组合框架,可混合匹配组件以构建定制化解决方案。
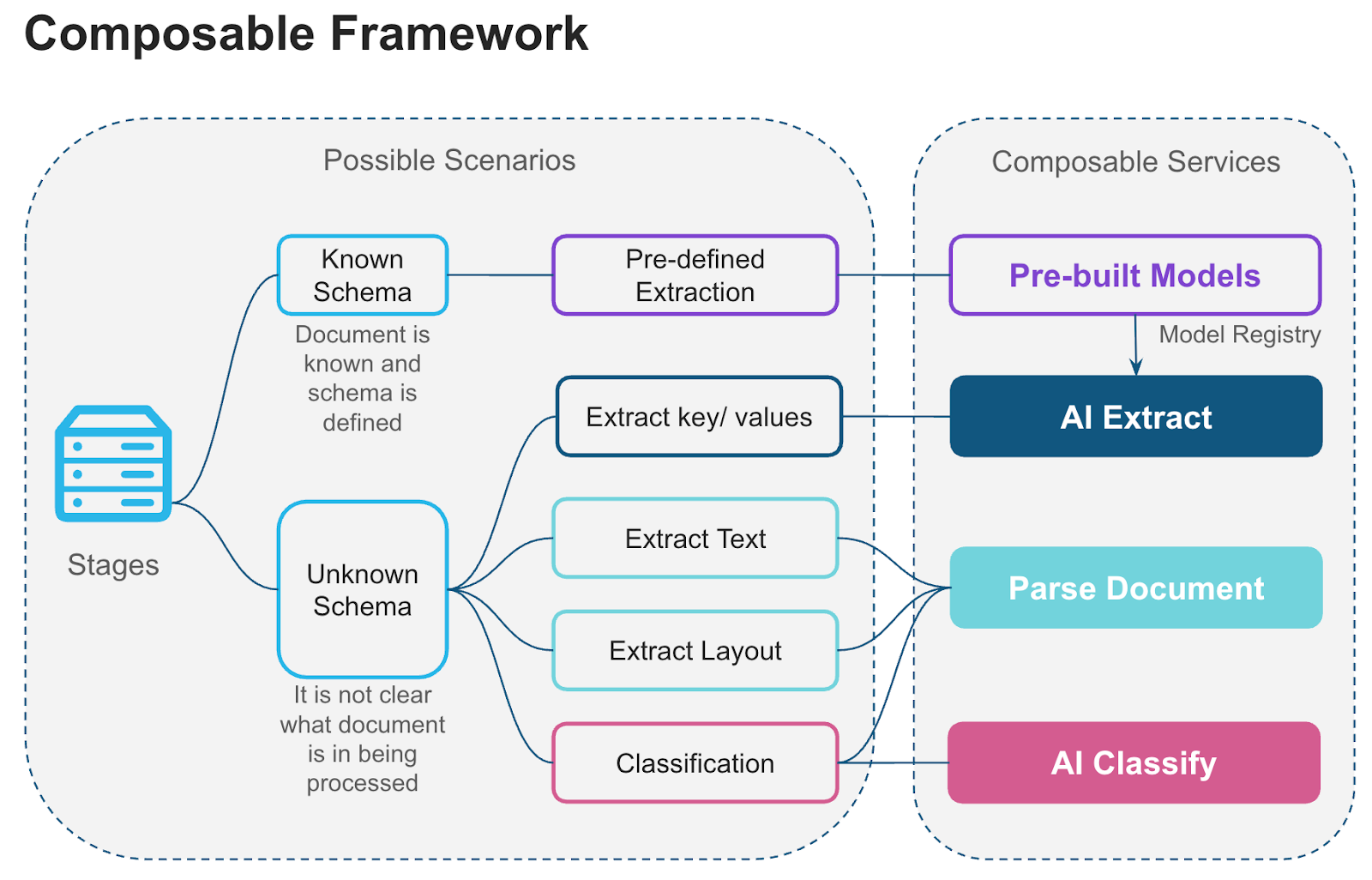
文档函数
核心 Cortex AI 文档处理函数包括:
- AI_PARSE_DOCUMENT: Converts digital-native or scanned documents into rich text while preserving layout and context. Optionally extracts images from documents. Ideal for semantic search, RAG pipelines, and summarization workflows. Works well with document analysis that requires understanding the entire document content.
- AI_EXTRACT: Provides high-quality structured extraction of information from documents. Understands text, tables, checkboxes, handwriting, and other visual elements. Specializes in extracting structured data based on a schema.
- AI_COMPLETE: The most general-purpose AI Function, AI_COMPLETE generates text completions based on a prompt you provide, and so can be used for a wide variety of tasks involving extracting or transforming text from documents. An advantage of AI_COMPLETE is the ability to choose a model.
以下文本处理 AI 函数可用于进一步分析或转换从文档中提取的文本。
- AI_SENTIMENT: Analyzes the sentiment of text content.
- AI_TRANSLATE: Translates text content between languages.
- SUMMARIZE: Generates concise summaries of text content.
用例
用于文档处理的 Cortex AI 函数旨在协同或单独使用,以解决各种用例,并且非常适合以下两种用例:
为聊天机器人和企业搜索服务构建 RAG 管道¶
由 AI_PARSE_DOCUMENT 处理的文档可由 Cortex Search 服务编制索引,该服务可充当检索增强生成 (RAG) 引擎,以改进语言模型对用户查询的响应。在这种情况下,您可以使用 Cortex Search Service 查找与查询相关的文档,然后将这些文档作为提示的一部分传递给 AI_COMPLETE,以生成更具上下文相关性的响应。
构建文档处理管道以简化工作流程和分析
Cortex 文档处理 AI 函数可帮助您使用模块化组件构建智能、灵活且可扩展的文档处理管道。此类管道可引入各种格式的文档并将其转换为可操作的数据,从而允许您构建如下工作流程:
- Schema based extraction: Apply a natural language schema to extract entities – ranging from single entities to complex tabular data – from a set of documents
- 针对文档的问答:使用自然语言就文档进行提问。
- 文本和布局提取:获取文档文本(带或不带布局)以提取实体、生成摘要并使用其他 AI 函数进行分析。
- Classification: Determine the document type (e.g., “invoice,” “contract,” “report”) when ingesting data to route each type to an appropriate processing workflow.
- Build a model registry to share custom extraction and classification models: A model registry stores document extraction models fine-tuned for custom use cases specific to your organization. Reusing these models across teams saves time and effort.