Notebooks on Container Runtime¶
概述¶
You can run Snowflake Notebooks on Container Runtime. Container Runtime is powered by Snowpark Container Services, giving you a flexible container infrastructure that supports building and operationalizing a wide variety of workflows entirely within Snowflake. Container Runtime provides software and hardware options to support advanced data science and machine learning workloads. Compared to virtual warehouses, Container Runtime provides a more flexible compute environment where you can install packages from multiple sources and select compute resources, including GPU machine types, while still running SQL queries on warehouses for optimal performance.
This document describes some considerations for using notebooks on Snowflake Container Runtime. You can also try the Getting Started with Snowflake Notebook Container Runtime (https://quickstarts.snowflake.com/guide/notebook-container-runtime/) quickstart to learn more about using the Container Runtime in your development.
先决条件¶
Before you start using Snowflake Notebooks on Container Runtime, the ACCOUNTADMIN role must complete the notebook setup steps for creating the necessary resources and granting privileges to those resources. For detailed steps, see 管理员设置.
Create a notebook on Container Runtime¶
When you create a notebook on Container Runtime, you choose a warehouse, runtime, and compute pool to provide the resources to run your notebook. The runtime you choose gives you access to different Python packages based on your use case. Different warehouse sizes or compute pools have different cost and performance implications. All of these settings can be changed later if needed.
备注
具有 ACCOUNTADMIN、ORGADMIN 或 SECURITYADMIN 角色的用户无法直接在容器运行时中创建或拥有笔记本。这些角色创建或直接拥有的笔记本将无法运行。然而,如果笔记本被一个角色拥有,而该角色继承了 ACCOUNTADMIN、ORGADMIN 或 SECURITYADMIN 角色的权限,例如 PUBLIC 角色,那么您可以使用这些角色来运行该笔记本。
要创建在容器运行时中运行的 Snowflake 笔记本,请按照以下步骤操作:
Sign in to Snowsight.
In the navigation menu, select Projects » Notebooks.
选择 + Notebook。
输入笔记本的名称。
选择在其中存储笔记本的数据库和架构。创建笔记本后,这些内容便无法更改。
备注
数据库和架构仅用于存储您的笔记本。您可以从您的笔记本中查询您角色可以访问的任何数据库和架构。
为 Runtime 选择 Run on container。
从 CPU 或 GPU 选项中选择 Runtime version。
- 选择 Compute pool。
Snowflake 自动在每个账户中预置两个 计算池,用于运行笔记本:SYSTEM_COMPUTE_POOL_CPU 和 SYSTEM_COMPUTE_POOL_GPU。
更改所选仓库以用于运行 SQL 和 Snowpark 查询。
要创建和打开笔记本,请选择 Create。
Runtime version:
提供两种类型的运行时版本类型:CPU 和 GPU。每个运行时图像包含一组由 Snowflake 验证和集成的基础 Python 包和版本。所有运行时图像支持使用 Snowpark Python、Snowflake ML 和 Streamlit 进行数据分析、建模和训练。
要从公共存储库安装额外的包,您可以使用 pip。需要一个外部访问集成 (EAI),以便 Snowflake Notebooks 从外部端点安装包。要配置 EAIs,请参阅 为 Snowflake Notebooks 设置外部访问。然而,如果包已经是基础镜像的一部分,那么您无法通过使用 pip install 安装不同版本来更改包的版本。要查看预安装的包列表,请从笔记本的单元格中运行以下命令:
Compute pool:
计算池为您的笔记本内核和 Python 代码提供计算资源。使用较小的基于 CPU 的计算池开始入门,并选择内存更大、基于 GPU 的计算池,以优化计算机视觉或 LLMs/VLMs 等密集型 GPU 使用场景。
请注意,每个计算节点每次仅限于为每个用户运行一个笔记本。在为笔记本创建计算池时,应将 MAX_NODES 参数设置为大于 1 的值。有关示例,请参阅 计算资源。有关 Snowpark Container Services 计算池的更多详细信息,请参阅 Snowpark Container Services:使用计算池。
当笔记本电脑未被使用时,请考虑将其关闭以释放节点资源。您可以通过在连接下拉菜单中选择 End session 来关闭笔记本。
如果笔记本在容器运行时中运行,则角色需要对计算池(而不是在笔记本仓库中)拥有 USAGE 权限。计算池是由 Snowflake 管理的基于 CPU 或 GPU 的虚拟机。创建计算池时,需要将 MAX_NODES 参数设置为大于 1,因为每个笔记本需要一个完整的节点来运行。有关信息,请参阅 Snowpark Container Services:使用计算池。
您可以查看您的资源利用率。有关更多信息,请参阅 关于旧版 Snowflake 笔记本。
备注
在 AWS上,运行于 GPU 计算池的笔记本默认采用高性能 NVMe存储作为启动设备。
在容器运行时中运行笔记本¶
在创建笔记本后,您可以通过添加和运行单元格立即开始运行代码。有关添加单元格的信息,请参阅 在 Snowflake Notebooks 中开发和运行代码。
导入更多包¶
除了预安装的包以便让您的笔记本启动和运行外,您还可以从已设置外部访问的公共源安装包。您还可以使用存储在暂存区或专用存储库中的包。您需要使用 ACCOUNTADMIN 角色或可以创建外部访问集成 (EAIs) 的角色来设置并授予您访问特定外部端点的权限。使用 ALTER NOTEBOOK 命令在您的笔记本上启用外部访问。授权后,您会在 Notebook settings 中看到 EAIs。在开始从外部通道安装之前,请切换 EAIs。有关说明,请参阅 使用外部访问权限和密钥配置笔记本。
以下示例在代码单元格中使用 pip install 安装外部包:
更新笔记本设置¶
您可以随时在 Notebook settings 中更新设置,例如使用哪个计算池或仓库,可以通过右上角的  笔记本操作 菜单访问。
笔记本操作 菜单访问。
您可以在 Notebook settings 中更新的设置之一是空闲超时设置。空闲超时的默认值为 1 小时,您可以将其设置为最长 72 小时。要在 SQL 中设置此项,请使用 CREATE NOTEBOOK 或 ALTER NOTEBOOK 命令来设置笔记本的 IDLE_AUTO_SHUTDOWN_TIME_SECONDS 属性。
安装专用包¶
Pip 支持从具有 基本身份验证 (https://pip.pypa.io/en/stable/topics/authentication/#basic-http-authentication) 的私有源安装软件包,例如 JFrog Artifactory。配置笔记本以进行外部访问集成 (EAI),以便它可以访问存储库。
创建网络规则以指定您要访问的存储库。例如,此网络规则指定了一个 JFrog 存储库:
Create a secret that represents credentials required to authenticate with the external network location.
创建一个外部访问集成,以允许访问存储库:
Associate the external access integration and secret with the notebook.
要访问外部访问配置,请选择笔记本右上角的 |vertical-ellipsis|(Notebook actions 菜单)。
选择 Notebook settings,然后选择 External access 选项卡。
选择 EAI 以连接到存储库。
笔记本重新启动。
笔记本重新启动后,您可以从存储库安装:
使用专用连接安装专用包¶
如果您的专用包存储库需要专用连接,请按照以下步骤配置账户。如果您需要帮助,可以与您的账户管理员协调以设置网络规则。
按照 使用专用连接的网络出口 中的步骤,使用专用连接设置网络出口。
Create a secret that represents credentials required to authenticate with the external network location.
从第 1 步,使用网络规则创建一个 EAI。例如:
Associate the external access integration and secret with the notebook.
要访问外部访问配置,请选择笔记本右上角的 |vertical-ellipsis|(Notebook actions 菜单)。
选择 Notebook settings,然后选择 External access 选项卡。
选择 EAI 以连接到您的专用存储库。
笔记本重新启动。
在笔记本重新启动后,您可以提供存储库的
--index-url:
运行 ML 工作负载¶
容器运行时的笔记本非常适合运行 ML 工作负载,例如模型训练和参数调整。运行时预安装了常见的 ML 包。设置好外部集成访问后,您可以使用 !pip install 安装所需的任何其他包。
为获得最佳体验,建议使用 OSS 库开发模型,或导入包含 OSS 组件的笔记本。容器运行时已优化 APIs,例如:
用于更快的数据引入的
DataConnector用于可扩展的模型拟合的分布式训练 APIs
分布式超参数优化 APIs,从而有效利用所有可用资源。
有关更多信息,请参阅 Snowflake Container Runtime。
备注
由于运行时预安装了许多软件包,因此更改任何版本都需要重新启动内核。有关更多信息,请参阅 Explore Legacy Notebooks。
使用 OSS ML 库¶
以下示例使用一个 OSS ML 库,xgboost,并且有一个活跃的 Snowpark 会话,以便直接将数据提取到内存中进行训练:
限制¶
容器运行时笔记本会话启动后,它可以运行长达 7 天而不会中断。若在七天后遇到预定的 SPCS 服务维护事件,该服务可能会中断并关闭。笔记本空闲时间设置仍然适用。有关 SPCS 服务维护的详细信息,请参阅 计算池维护。
成本和计费注意事项¶
在容器运行时中运行笔记本时,可能会产生 仓库计算 和 SPCS 计算成本。在 Snowflake Notebooks 中,仓库不仅是执行查询所必需的,也是支持某些前端功能所必需的。例如,使用计算池执行 Python 时,可能仍需要一个仓库来呈现输出或处理交互式组件。
Snowflake Notebooks 依靠虚拟仓库来高效运行 SQL 和 Snowpark 查询。因此,在 Python 单元格中执行 SQL 单元格或 Snowpark 下推查询时,可能会产生仓库计算成本。
下图显示了在一个笔记本中,SQL、Snowpark 和 Python 单元格的计算发生在何处:
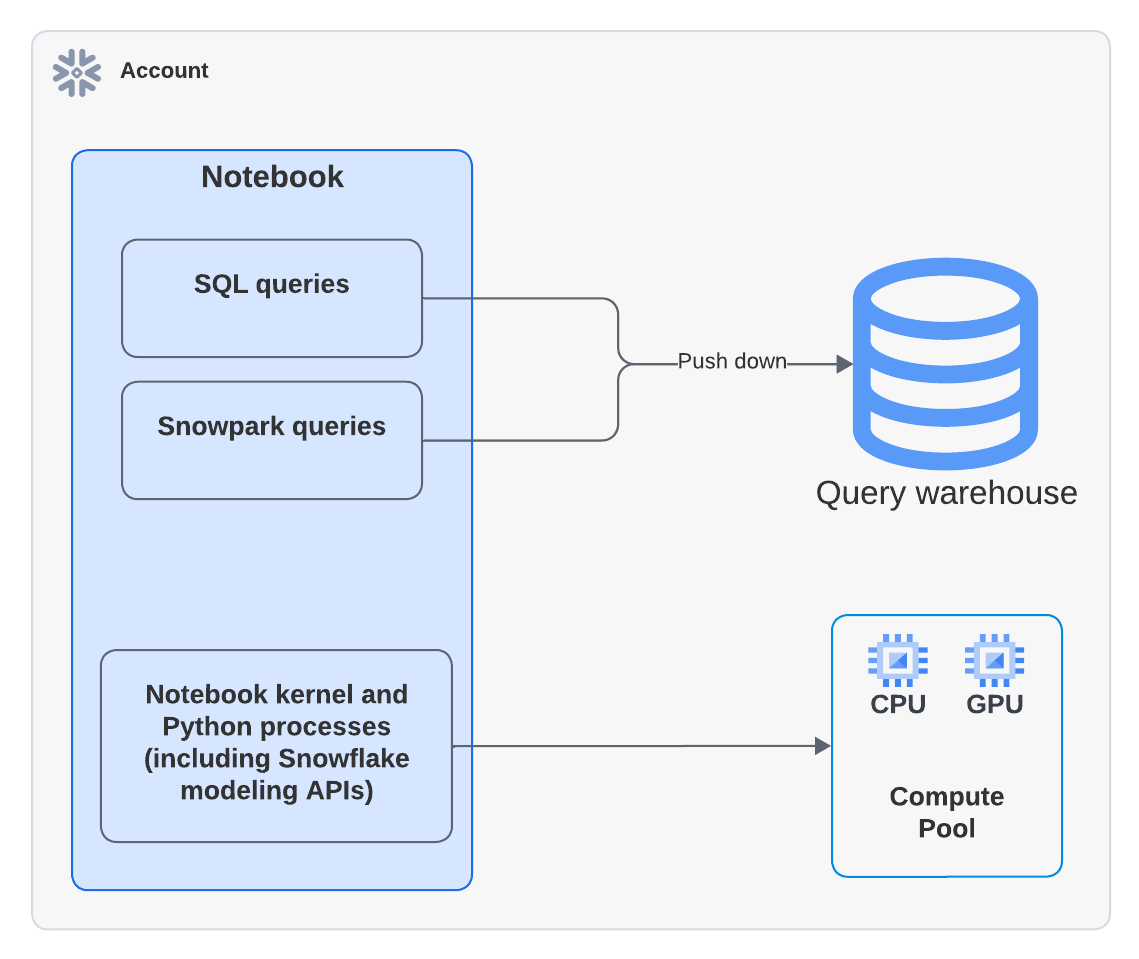
备注
当您执行使用计算池的笔记本时,Python 代码将在计算池上运行。但您可能会在 Query History 中看到使用一个仓库来运行 EXECUTE NOTEBOOK 命令的活动。这是符合预期的行为。仓库会短暂地用于初始化执行环境,但不会耗用任何仓库 Credit。所有代码执行均由计算池处理。
例如,以下 Python 示例使用 xgboost (https://xgboost.readthedocs.io/en/stable/) 库。数据被拉入容器中,并完全在 Snowpark Container Services 中进行处理。
要了解关于仓库成本的更多信息,请参阅 仓库概述。