Snowflake Container Runtime¶
概述¶
The Snowflake Container Runtime is a set of preconfigured customizable environments built for machine learning on Snowpark Container Services, covering interactive experimentation and batch ML workloads such as model training, hyperparameter tuning, batch inference and fine tuning. They include the most popular machine learning and deep learning frameworks. Used with Snowflake notebooks, they provide an end-to-end ML experience.
执行环境¶
The Container Runtime provides an environment populated with packages and libraries that support a wide variety of ML development tasks inside Snowflake. In addition to the pre-installed packages, you can import packages from external sources like public PyPI repositories, or internally-hosted package repositories that provide a list of packages approved for use inside your organization.
Executions of your custom Python ML workloads and supported training APIs occur within Snowpark Container Services, which offers the ability to run on CPU or GPU compute pools. When using the Snowflake ML APIs, the Container Runtime distributes the processing across available resources.
Container Runtimes are versioned, allowing you to select specific runtime environments, pin your workloads to a specific version, and migrate to updated container runtime environments at your own pace.
分布式处理¶
Snowflake ML 建模和数据加载 APIs 建立在 Snowflake ML 的分布式处理框架之上,通过充分利用可用的计算能力来最大程度地提高资源利用率。默认情况下,该框架在多 GPU 节点上使用所有 GPUs,与开源的包相比,性能显著提高,并缩短了整体运行时间。
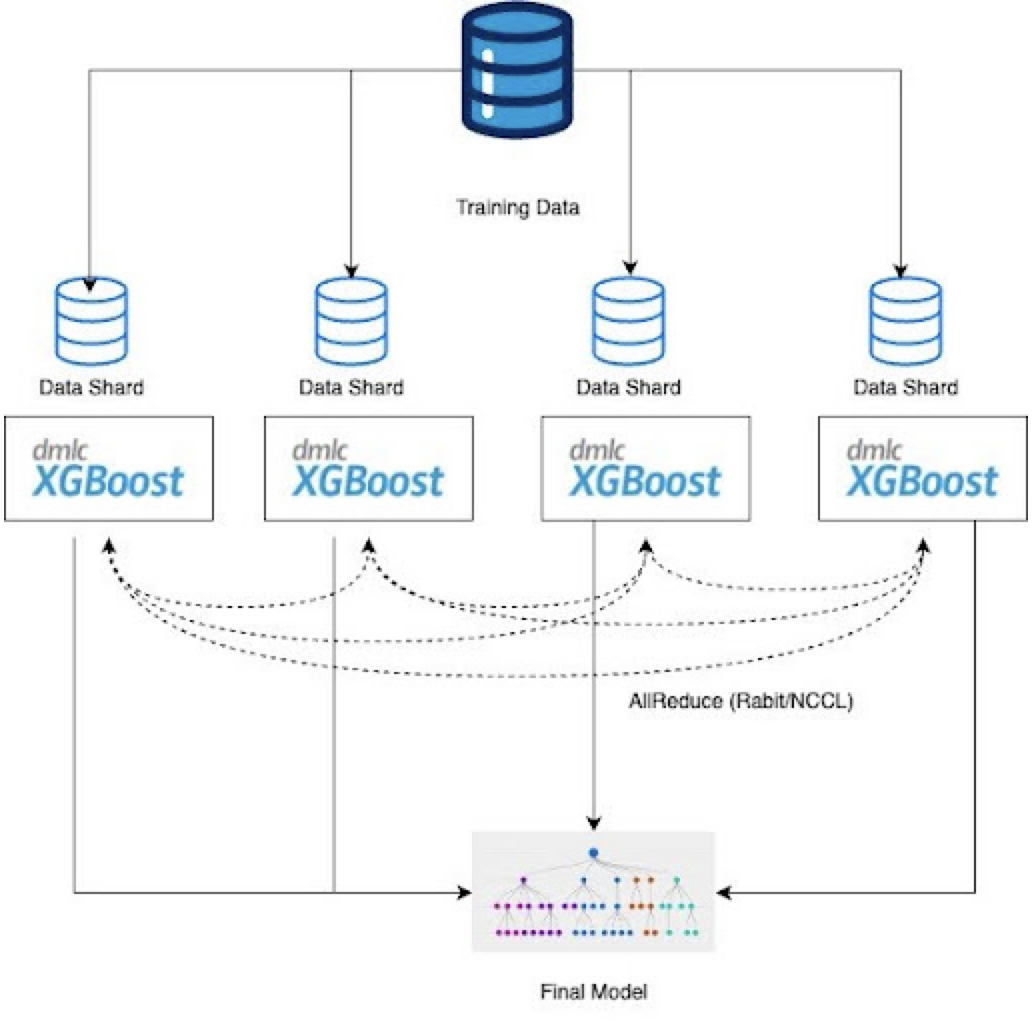
机器学习工作负载(包括数据加载)在 Snowflake 管理的计算环境中执行。该框架允许根据当前任务的具体要求动态扩展资源,例如训练模型或加载数据。每个任务的资源数量(包括 GPU 和内存分配)可通过提供的 APIs 轻松配置。
优化的数据加载¶
容器运行时提供了一系列数据连接器 APIs,支持将 Snowflake 数据源(包括表、DataFrames 和 Datasets)连接到流行的 ML 框架(例如 PyTorch 和 TensorFlow),充分利用多个核心或 GPUs。一旦加载,数据可以使用开源包或任何 Snowflake ML APIs(包括下面所述的分布式版本)进行处理。这些 APIs 可以在 snowflake.ml.data 命名空间中找到。
The snowflake.ml.data.data_connector.DataConnector class connects Snowpark DataFrames or Snowflake ML Datasets to
TensorFlow or PyTorch DataSets or Pandas DataFrames. Instantiate a connector using one of the following class methods:
DataConnector.from_dataframe: Accepts a Snowpark DataFrame.
DataConnector.from_dataset: Accepts a Snowflake ML Dataset, specified by name and version.
DataConnector.from_sources: Accepts list of sources, each of which can be a DataFrame or a Dataset.
您实例化了连接器(例如,调用实例 data_connector)之后,请调用以下方法以生成所需类型的输出。
data_connector.to_tf_dataset:返回适合与 TensorFlow 一起使用的 TensorFlow 数据集。data_connector.to_torch_dataset:返回适合与 PyTorch 一起使用的 PyTorch 数据集。
有关这些 APIs 的更多信息,请参阅 Snowflake ML API 参考。
使用开源构建¶
凭借预先填充热门 ML 包的基础 CPU 和 GPU 图像以及灵活性,以使用 pip 安装其他库,用户可以在 Snowflake Notebooks 中使用熟悉和创新的开源框架,而无需将数据移出 Snowflake。您可以将用于数据加载、训练和超参数优化的 Snowflake 分布式 APIs 与热门 OSS 包的熟悉 APIs 结合使用,只需对接口进行小型更改以允许扩展配置,从而扩展处理。
以下代码演示如何使用这些 APIs 创建 XGBoost 分类器:
CPU 容器运行时的包与 GPU 容器运行时的包不同。以下章节列出了每个容器运行时中可用的包。
Snowflake Container Runtime packages¶
The full list of available packages in Snowflake Container Runtime is maintained as part of the Container Runtime Release Notes.
优化的训练¶
Container Runtime offers a set of distributed training APIs, including distributed versions of LightGBM, PyTorch,
and XGBoost, that take full advantage of the available resources in the container environment. These are found in the
snowflake.ml.modeling.distributors namespace. The APIs of the distributed classes are similar to those of the
standard versions.
有关这些 APIs 的更多信息,请参阅 API 参考。
XGBoost¶
The primary XGBoost class is snowflake.ml.modeling.distributors.xgboost.XGBEstimator. Related classes include:
snowflake.ml.modeling.distributors.xgboost.XGBScalingConfig
For an example of working with this API, see the XGBoost on GPU (https://github.com/Snowflake-Labs/sfguide-getting-started-with-container-runtime-apis/blob/main/XGBoost_on_GPU_Quickstart.ipynb) example notebook in the Snowflake Container Runtime GitHub repository.
LightGBM¶
The primary LightGBM class is snowflake.ml.modeling.distributors.lightgbm.LightGBMEstimator. Related classes include:
snowflake.ml.modeling.distributors.lightgbm.LightGBMScalingConfig
For an example of working with this API, see the LightGBM on GPU (https://github.com/Snowflake-Labs/sfguide-getting-started-with-container-runtime-apis/blob/main/LightGBM_on_GPU_Quickstart.ipynb) example notebook in the Snowflake Container Runtime GitHub repository.
PyTorch¶
主要 PyTorch 类是 snowflake.ml.modeling.distributors.pytorch.PyTorchDistributor。相关的类和函数包括:
snowflake.ml.modeling.distributors.pytorch.WorkerResourceConfigsnowflake.ml.modeling.distributors.pytorch.PyTorchScalingConfigsnowflake.ml.modeling.distributors.pytorch.Contextsnowflake.ml.modeling.distributors.pytorch.get_context
For an example of working with this API, see the PyTorch on GPU (https://github.com/Snowflake-Labs/sfguide-getting-started-with-container-runtime-apis/blob/main/PyTorch_on_GPU_Quickstart.ipynb) example notebook in the Snowflake Container Runtime GitHub repository.
后续步骤¶
To try a Snowflake Notebook using Container Runtime, see Notebooks on Container Runtime.