将 Snowflake Connector for Kafka 与 Snowpipe Streaming Classic 结合使用¶
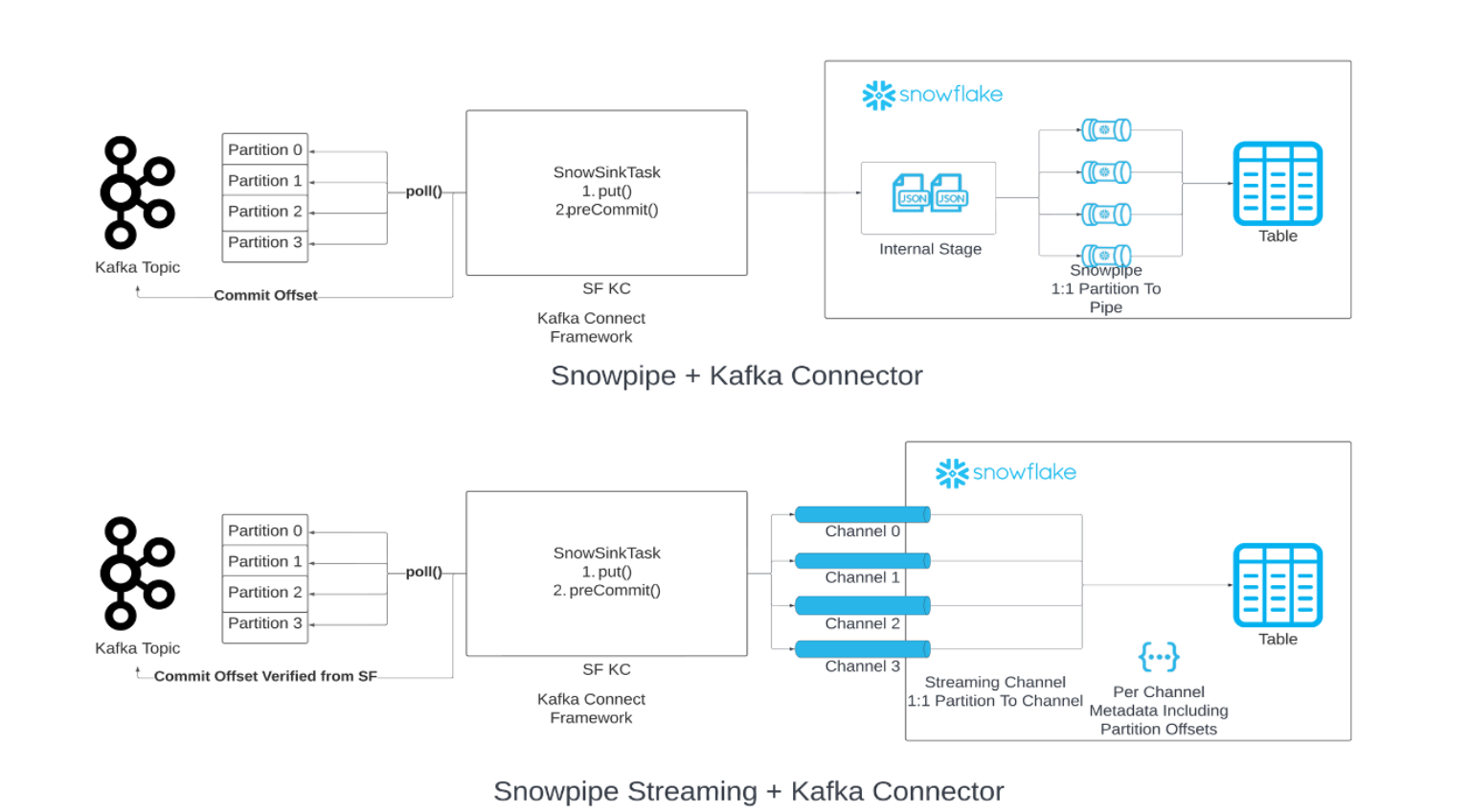
您可以将 Snowpipe替换为 Kafka 的数据加载链中的 Snowpipe Streaming。当达到指定的刷新缓冲区阈值(时间、内存或消息数)时,连接器会调用 Snowpipe Streaming API(“API”)将数据行写入 Snowflake 表,这与 Snowpipe 不同,后者会从临时暂存文件写入数据。此架构可降低加载延迟,并相应降低加载类似数据量的成本。
需要安装 Kafka Connector 的 2.0.0 版(或更高版本),才能搭配使用 Snowpipe Streaming Classic。使用 Snowpipe Streaming Classic 的 Kafka Connector 包括 Snowflake Ingest SDK,并支持将 Apache Kafka 主题中的行直接流式传输到目标表中。
本主题内容:
所需的最低版本¶
支持 Snowpipe Streaming 的最低 Kafka Connector 版本为 2.0.0。
Kafka 配置属性¶
将连接设置保存在 Kafka Connector 属性文件中。有关更多信息,请参阅 配置 Kafka Connector。
所需属性¶
在 Kafka Connector 属性文件中添加或编辑连接设置。有关更多信息,请参阅 配置 Kafka Connector。
snowflake.ingestion.methodRequired only if using the Kafka connector as the streaming ingest client. Specifies whether to use Snowpipe Streaming or standard Snowpipe to load your Kafka topic data. The supported values are as follows:
SNOWPIPE_STREAMING:code:`SNOWPIPE`(默认)
无需其他设置,即可选择后端服务来排队和加载主题数据。照常在 Kafka Connector 属性文件中配置其他属性。
snowflake.role.name将行插入表中时要使用的访问控制角色。
客户端优化属性¶
enable.streaming.client.optimization指定是否启用单客户端优化。Kafka Connector 发布版本 2.1.2 及更高版本支持此属性。默认情况下,此属性处于启用状态。
使用单客户端优化时,每个 Kafka Connector 仅为多个主题分区创建一个客户端。 此功能可以通过创建更大的文件来减少客户端运行时并降低迁移成本。
- 值:
truefalse
- 默认值:
true
请注意,在高吞吐量场景中(例如,每个连接器 50 MB/秒),启用此属性可能会导致更高的延迟或成本。建议对高吞吐量场景禁用此属性。
缓冲区和轮询属性¶
buffer.flush.time缓冲区刷新之间的秒数;每次刷新都会对缓冲记录执行插入操作。Kafka Connector 在每次刷新后调用一次 Snowpipe Streaming API。
该属性支持
buffer.flush.time的最小值为 ``1``(以秒为单位)。对于更高的平均数据流速率,我们建议您降低默认值以改善延迟。如果成本比延迟更重要,则可以增加缓冲区刷新时间。在 Kafka 内存缓冲区已满之前,请小心刷新,以避免内存不足异常。- 值:
最小值:
1最大值:无上限
- 默认值:
10
请注意,Snowpipe Streaming 每隔一秒自动刷新一次数据,这与 Kafka Connector 的缓冲区刷新时间不同。达到 Kafka 缓冲区刷新时间后,数据将通过 Snowpipe Streaming 按一秒的延迟发送到 Snowflake。有关更多信息,请参阅 Snowpipe Streaming 延迟。
buffer.count.records在引入到 Snowflake 之前,每个 Kafka 分区在内存中缓冲的记录数。
- 值:
最小值:
1最大值:无上限
- 默认值:
10000
buffer.size.bytes记录作为数据文件引入到 Snowflake 之前,每个 Kafka 分区内存中缓冲记录的累计大小(以字节为单位)。
记录在写入数据文件时被压缩。因此,缓冲区中记录的大小可能大于从记录创建的数据文件的大小。
- 值:
最小值:
1最大值:无上限
- 默认值:
20000000(20 MB)
snowflake.streaming.max.client.lag指定 Snowflake Ingest Java (https://github.com/snowflakedb/snowflake-ingest-java) 将数据刷新到 Snowflake 的频率,以秒为单位。
低值保持低延迟,但可能会导致更糟糕的查询性能,特别是在启用
snowflake.streaming.enable.single.buffer时。有关更多信息,请参阅 适用于 Snowpipe Streaming 的推荐延迟配置.- 值:
最小值:
1秒最大值:
600秒
- 默认值:
版本 3.1.1 及更高版本为
30秒,版本 3.0.0 和 3.1.0 为120秒,其他情况为1秒
snowflake.streaming.enable.single.buffer指定是否为 Snowpipe Streaming 启用单个缓冲区,以及跳过连接器内部缓冲区中的缓冲数据。
Kafka Connector 版本 2.3.1 及更高版本支持此属性。
Streaming Connector 与 Snowflake Ingest Java (https://github.com/snowflakedb/snowflake-ingest-java) 提供的内部缓冲区一起使用。将此属性设置为
true可使 Kafka Connector 跳过内部缓冲区,以实现更低的延迟。请注意,将此属性设置为
true会使buffer.flush.time和buffer.count.records变得无关。- 值:
truefalse
- 默认值:
对于 3.0.0 及更高版本,值为
true,对于其他版本,则为false
除 Kafka Connector 属性外,请注意 Kafka 使用者 max.poll.records 属性,该属性控制 Kafka 在单个轮询中返回到 Kafka Connect 的最大记录数。默认值 500 可以增加,但要注意内存约束。有关此属性的更多信息,请参阅 Kafka 包的文档:
Apache Kafka (https://kafka.apache.org/documentation/#consumerconfigs_max.poll.records)
Confluent (https://docs.confluent.io/platform/current/installation/configuration/consumer-configs.html#consumerconfigs_max.poll.records)
错误处理和 DLQ 属性¶
errors.tolerance指定如何处理 Kafka Connector 遇到的错误:
此属性支持以下值:
- 值:
NONE:遇到第一个错误时停止加载数据。ALL:忽略所有错误并继续加载数据。
- 默认值:
NONE
errors.log.enable指定是否将错误消息写入 Kafka Connect 日志文件。
此属性支持以下值:
- 值:
TRUE:写入错误消息。FALSE:不写入错误消息。
- 默认值:
FALSE
errors.deadletterqueue.topic.name指定 Kafka 中 DLQ(死信队列)主题的名称,用于将无法引入到 Snowflake 表的消息传递到 Kafka。有关更多信息,请参阅 `死信队列`_(本主题内容)。
- 值:
自定义文本字符串
- 默认值:
无
Exactly-once 语义¶
Exactly-once 语义确保 Kafka 消息的传递不会重复或丢失数据。默认情况下,此传递保证是为支持 Snowpipe Streaming 的 Kafka Connector 设置。
Kafka Connector 在分区和通道之间采用一对一映射,并使用两种不同的偏移:
使用者偏移:此偏移会跟踪使用者最近使用的偏移,并由 Kafka 管理。
偏移令牌:此偏移会跟踪 Snowflake 中最近提交的偏移,并由 Snowflake 管理。
请注意,Kafka Connector 有时不会处理缺失的偏移。Snowflake 预计所有记录的偏移量都会按顺序增加。在特定用例中,缺失的偏移会破坏 Kafka Connector。建议您使用逻辑删除记录而不是 NULL 记录。
Kafka Connector 通过实施以下最佳实践实现一次传递:
打开/重新打开通道:
打开或重新打开给定分区的通道时,Kafka Connector 将通过
getLatestCommittedOffsetTokenAPI 从 Snowflake 检索到的新提交偏移令牌用作事实来源,并相应地重置 Kafka 中的使用者偏移量。如果使用者偏移不再在数据保留期内,则会引发异常,您可以确定要采取的相应操作。
Kafka Connector 不会重置 Kafka 中的使用者偏移,并将其用作事实来源。唯一场景是 Snowflake 的偏移令牌为 NULL。在这种情况下,连接器接受 Kafka 发送的偏移,并且随后会更新偏移令牌。
处理记录:
为确保额外增加一层安全保障,防止 Kafka 中的潜在错误可能产生的非连续偏移,Snowflake 维护了一个内存中变量,用于跟踪新处理的偏移。仅在当前行的偏移等于新处理的偏移量加 1 时,Snowflake 才会接受行,从而增加了一层额外的保护,以确保引入过程是连续且准确的。
处理异常、故障、崩溃恢复:
作为恢复过程的一部分,Snowflake 始终遵循前面概述的通道打开/重新打开逻辑,方法是重新打开通道并使用新提交的偏移令牌重置使用者偏移。这样的话,Snowflake 会向 Kafka 发出信号,以通过大于新提交的偏移令牌的偏移值发送数据,从而从故障发生点恢复引入,而不会丢失数据。
实施重试机制:
为解决潜在的暂时性问题,Snowflake 会在 API 调用中加入重试机制。Snowflake 会多次重试这些 API 调用,以增加成功的几率并降低会影响引入过程的间歇性失败风险。
推进使用者偏移:
Snowflake 会定期使用新提交的偏移令牌推进使用者偏移,以确保引入过程持续与 Snowflake 中的新数据状态保持一致。
转换器¶
Snowpipe Streaming 支持许多基于社区的转换器,如以下转换器:
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverterorg.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.storage.StringConverter
其他基于社区的转换器也可能会受支持,但尚未得到验证。Snowpipe Streaming 不支持 Snowflake 转换器。
死信队列¶
带 Snowpipe Streaming 的 Kafka Connector 支持对损坏的记录或由于故障而无法成功处理的记录使用死信队列 (DLQ)。
有关监控的更多信息,请参阅 Apache Kafka 文档 (https://kafka.apache.org/documentation/#connect_monitoring)。
架构检测和架构演化¶
带有 Snowpipe Streaming 的 Kafka Connector 支持架构检测和演化。Snowflake 中表的结构可以自动定义和演化,以支持 Kafka Connector 加载的新 Snowpipe Streaming 数据的结构。要为支持 Snowpipe Streaming 的 Kafka Connector 启用架构检测和演化,请配置以下 Kafka 属性:
snowflake.ingestion.methodsnowflake.enable.schematizationschema.registry.url
有关更多信息,请参阅 Kafka Connector with Snowpipe Streaming Classic 的架构检测和演化。
预估引入延迟¶
要预估引入延迟,请使用 RECORD_METADATA 中的 SnowflakeConnectorPushTime 字段。此时间戳表示记录被推入引入 SDK 缓冲区的时间点。
有关 RECORD_METADATA 格式的详细信息,请参阅 :ref:` Kafka 主题的表架构 <label-schema_of_table_for_snowflake_kafka_connector>`。
备注
此字段 不 代表 Snowflake 表中记录可见的时间,因为它不考虑您配置的 Snowpipe Streaming 延迟。
计费和使用情况¶
有关 Snowpipe Streaming 的计费信息,请参阅 Snowpipe Streaming Classic 的成本。
限制¶
Snowpipe Streaming 限制¶
故障转移限制¶
当辅助故障转移组升级为主要故障转移组时,带有 Kafka Connector with Snowpipe Streaming 需要手动交互。Exactly-once 语义仍然保留。
如果将 enable.streaming.client.optimization 属性设置为 false,则应重新启动 Kafka Connector。重新启动连接器后,它将以新的主部署为目标。
如果将 enable.streaming.client.optimization 属性设置为 true,则连接器运行所在的主机 JVM 应先关闭再重新启动。重新启动主机 JVM 后,新启动的 Kafka Connector 将以新的主部署为目标。