Snowpipe Streaming¶
Snowpipe Streaming 是 Snowflake 的服务,用于将流数据连续、低延迟地直接加载到 Snowflake 中。它支持近乎实时的数据引入和分析,这对于及时的洞察和即时的运营响应至关重要。来自不同流式数据源的大量数据可在几秒钟内进行查询和分析。
Snowpipe Streaming 的价值¶
实时数据可用性:与传统的批量加载方法不同,在数据到达时引入数据,支持实时仪表板、实时分析和欺诈检测等用例。
高效流式工作负载:利用 Snowflake Ingest SDKs 将行直接写入表中,绕过中间云存储。这种直接方法减少了延迟并简化了引入架构。
简化的数据管道:为来自应用程序事件、IoT 传感器、变更数据捕获 (CDC) 流和消息队列(例如 Apache Kafka)等数据源的持续数据管道提供了一种简化的方法。
无服务器且可扩展:作为一种无服务器产品,它会根据引入负载自动扩展计算资源,从而无需对引入任务进行手动仓库管理。
流处理的成本效益:对流式引入进行了计费优化,与频繁的小批量 COPY 操作相比,可能为高容量、低延迟数据流提供更具成本效益的解决方案。
借助 Snowpipe Streaming,可以在 Snowflake 数据云上构建实时数据应用程序,以便根据最新可用数据做出决策。
Snowpipe Streaming 实现¶
Snowpipe Streaming 提供两种不同的实现方式,以满足不同的数据引入需求和性能预期:采用高性能架构的 Snowpipe Streaming(预览版)和采用经典架构的 Snowpipe Streaming:
采用高性能架构的 Snowpipe Streaming(预览版)
Snowflake 设计了这种下一代实现,旨在显著提高吞吐量、优化流处理性能并提供可预测的成本模型,为高级数据流处理功能奠定基础。
主要特征:
SDK: Utilizes the new snowpipe-streaming SDK (https://repo1.maven.org/maven2/com/snowflake/snowpipe-streaming/).
定价:采用透明、基于吞吐量的定价(按未压缩数据量每 GB 计算 credit)。
数据流管理:利用 PIPE 对象来管理数据流并在引入时启用轻量级转换。针对此 PIPE 对象对通道进行开启。
引入:提供 REST API,以通过 PIPE 进行直接的、轻量级数据引入。
架构验证:根据 PIPE 中定义的架构在引入期间在服务器端执行。
性能:专为显著提高吞吐量和提高所引入数据的查询效率而设计。
我们鼓励您探索这种先进的架构,尤其适用于新的流处理项目。
-
这是最初的、正式发布的实现,为已建立的数据管道提供了可靠的解决方案。
主要特征:
SDK: Utilizes the snowflake-ingest-sdk (https://mvnrepository.com/artifact/net.snowflake/snowflake-ingest-sdk).
Data flow management: Does not use the PIPE object concept for streaming ingestion. Channels are configured and opened directly against target tables.
定价:基于用于引入的无服务器计算资源和活跃客户端连接数量的组合。
选择您的实施方案¶
在选择实施方案时,请考虑您的眼前需求和长期数据策略:
新的流处理项目:建议评估 Snowpipe Streaming 高性能架构(预览版),因为其前瞻性设计、更好的性能、可扩展性和成本可预测性。
性能要求:高性能架构旨在尽可能提高吞吐量和优化实时性能。
定价偏好:高性能架构提供了清晰的、基于吞吐量的定价,而经典架构则根据无服务器计算使用量和客户端连接进行计费。
现有设置:使用经典架构的现有应用程序可以继续运行。对于未来的扩展或重新设计,可以考虑迁移到高性能架构或整合高性能架构。
功能集和管理:高性能架构中的 PIPE 对象引入了经典架构所不具备的增强管理和转换功能。
Snowpipe Streaming 与 Snowpipe 的对比¶
Snowpipe Streaming 旨在补充 Snowpipe,而不是取而代之。在流处理场景中使用 Snowpipe Streaming API 时,数据会通过行(例如 Apache Kafka 主题)进行流传输,而非写入到文件。API 适用于引入工作流程,该工作流程包括生成或接收记录的现有自定义 Java 应用程序。WIth API,无需创建文件即可将数据加载到 Snowflake 表中,并且 API 可以在数据可用时自动连续地将数据流加载到 Snowflake 中。
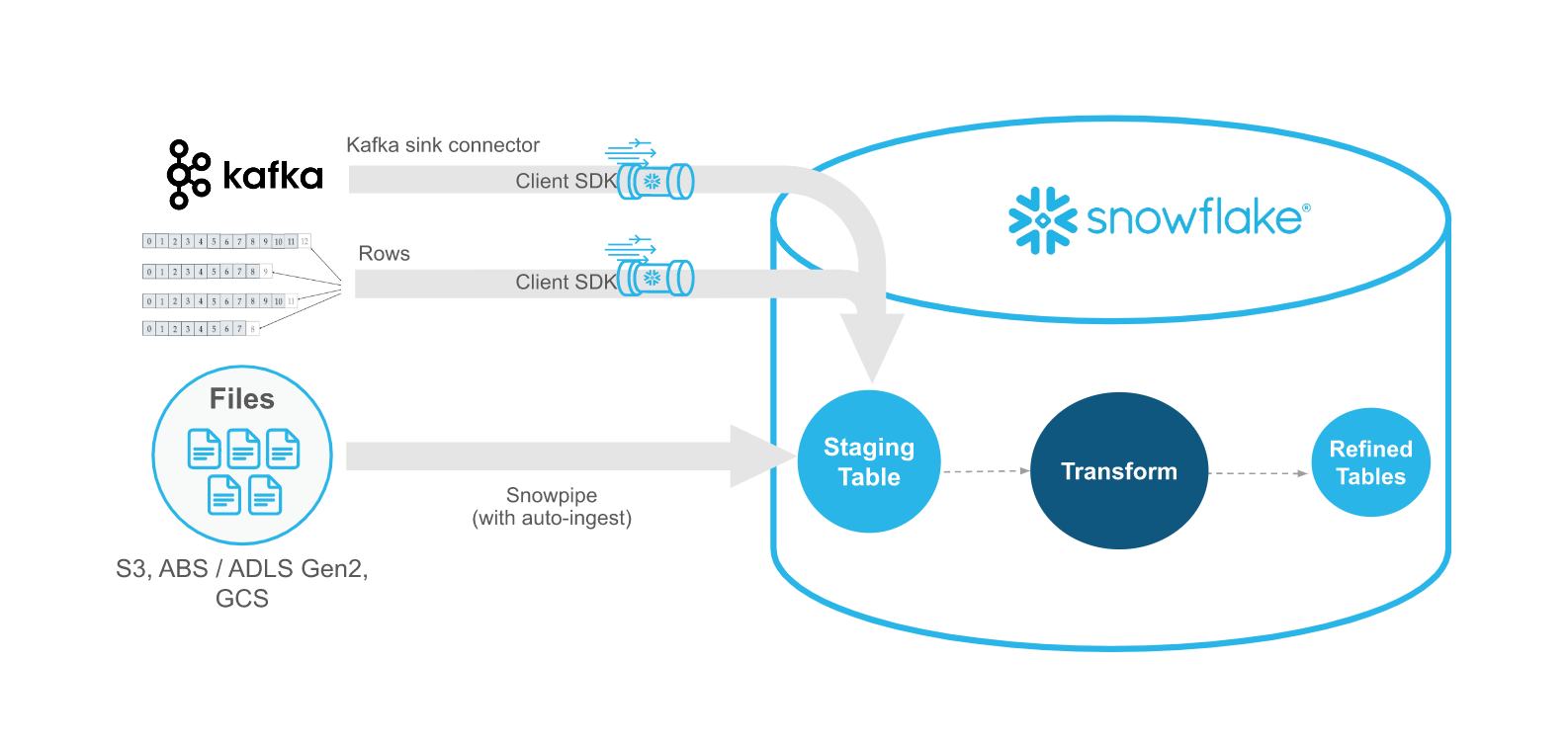
下表描述了 Snowpipe Streaming 与 Snowpipe 之间的区别:
类别 |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
待加载数据的形式 |
行 |
文件。如果您的现有数据管道在 Blob 存储中生成文件,则建议使用 Snowpipe,而非 API。 |
第三方软件要求 |
Snowflake Ingest SDK 的自定义 Java 应用程序代码包装程序 |
无 |
数据排序 |
各通道内的有序插入 |
不支持。在从文件加载数据时,Snowpipe 可按照与云存储中文件创建时间戳不同的顺序进行加载。 |
加载历史记录 |
加载历史记录会记录在 SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY 视图 (Account Usage) 之中 |
加载 COPY_HISTORY (Account Usage) 和 COPY_HISTORY 函数 (Information Schema) 中记录的历史记录 |
管道对象 |
经典架构不需要管道对象:API 直接将记录写入到目标表中。高性能架构需要管道对象。 |
需要一个管道对象,用于将暂存文件数据排入队列,并加载到目标表中。 |
软件要求¶
SDKs¶
Specific SDKs facilitate interaction with the Snowpipe Streaming service. You can download the SDKs from the Maven Central Repository. The following lists show the requirements, which vary depending on the Snowpipe Streaming architecture that you use:
适用于采用高性能架构的 Snowpark Streaming:
SDK:使用新的 snowpipe-streaming SDK (https://repo1.maven.org/maven2/com/snowflake/snowpipe-streaming/)。
Java 版本:需要 Java 11 或更高版本。
适用于 Snowpipe Streaming Classic:
SDK:使用 snowflake-ingest-sdk (https://mvnrepository.com/artifact/net.snowflake/snowflake-ingest-sdk) 版本 4.X 或更高版本。
Java 版本:需要 Java 8 或更高版本。
其他先决条件:必须为 Java 8 环境安装 Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files。
重要
该 SDK 会对 Snowflake 进行 REST API 调用。您可能需要调整网络防火墙规则以允许连接。
自定义客户端应用程序¶
API 需要自定义 Java 应用程序接口,该接口可以抽取成行的数据并处理发生的错误。必须确保应用程序持续运行并能从故障中恢复。对于给定的一批行,API 支持与 ON_ERROR = CONTINUE | SKIP_BATCH | ABORT 同等的处理。
CONTINUE:继续加载可接受的数据行,并返回所有错误。SKIP_BATCH:如果在整批行中遇到任何错误,则跳过加载并返回所有错误。:code:`ABORT`(默认设置):中止整批行,并在遇到第一个错误时抛出异常。
对于 Snowpipe Streaming Classic,应用程序使用 insertRow`(单行)或 :code:`insertRows`(行集)方法的响应进行架构验证。有关高性能架构的错误处理,请参阅 :doc:`错误处理 </user-guide/snowpipe-streaming-high-performance-error-handling>。
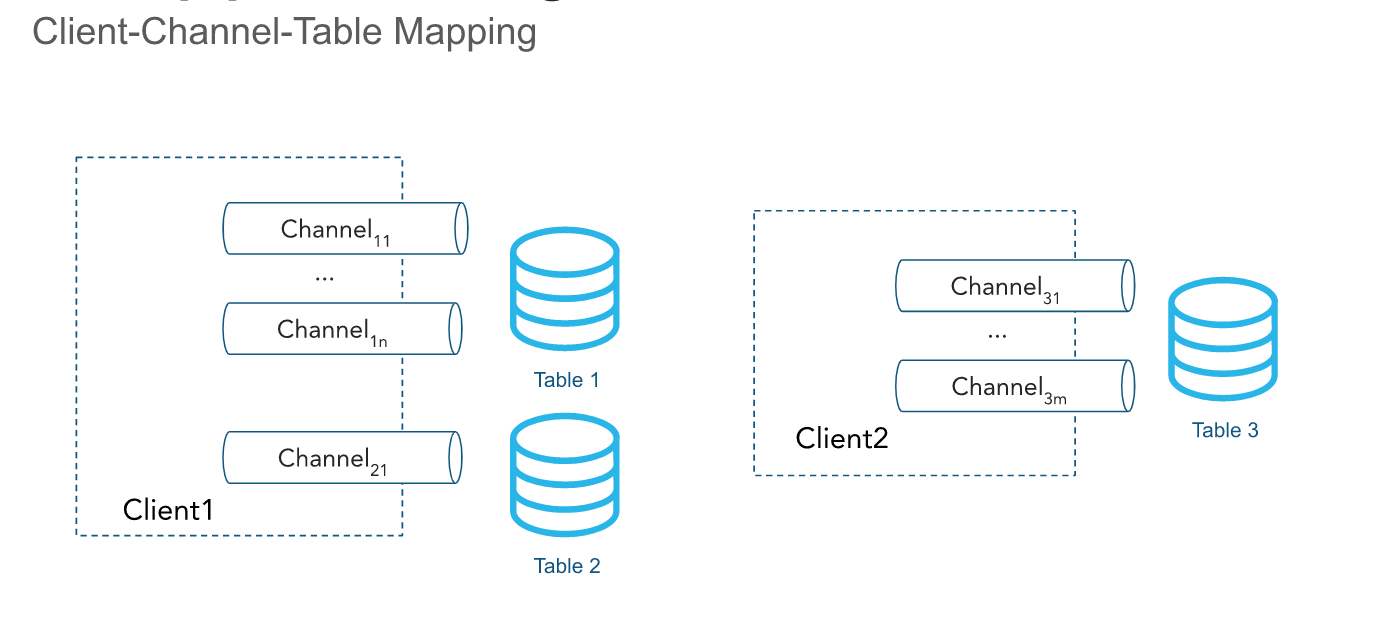
通道¶
API 通过一个或多个 通道 引入行。通道表示与 Snowflake 的逻辑、指定流处理连接,用于将数据加载到表中。一个通道精确映射到 Snowflake 中的一个表;但多个通道可以指向同一个表。Client SDK 可以为多个表打开多个通道;但 SDK 无法跨账户打开通道。行的顺序及其相应的偏移令牌会在通道内保留,但不会跨指向同一个表的多个通道保留。
在客户端主动插入数据时,通道应长期存在,并且由于保留了偏移令牌,应该加以重复使用。默认情况下,通道内的数据每 1 秒自动刷新一次,并且不需要关闭通道。有关更多信息,请参阅 延迟。
当不再需要通道和相关的偏移元数据时,您可以使用 DropChannelRequest API 永久删除通道。有两种方法可以删除通道:
关闭时删除通道。在删除通道之前,通道内的数据会自动刷新。
盲目删除通道。不建议这样做,因为盲目删除通道会丢弃任何待处理的数据,并可能会使任何已打开的通道失效。
您可以运行 SHOW CHANNELS 命令,列出您有访问权限的通道。有关更多信息,请参阅 SHOW CHANNELS。
备注
不活动的通道及其偏移令牌会在 30 天后自动删除。
偏移令牌¶
偏移令牌 是一个字符串,客户端可以在其行提交方法请求(例如,对于单行或多行)中包含该字符串,以跟踪每个通道的引入进度。使用的具体方法是适用于经典架构的 insertRow 或 insertRows,以及适用于高性能架构的 appendRow 或 appendRows。在通道创建时,此令牌将初始化为 NULL,并会在具有所提供的偏移令牌的行通过异步过程提交到 Snowflake 时更新。客户端可以定期提出 getLatestCommittedOffsetToken 方法请求,以获取特定通道的最新提交偏移令牌,并使用该令牌来推断引入进度。请注意,Snowflake 不 使用此令牌来执行重复数据删除;但客户端可以使用此令牌,通过自定义代码来执行重复数据删除。
在客户端重新打开一个通道时,将会返回最新的持久偏移令牌。客户端可使用令牌重置其在数据源中的位置,以避免发送两次相同的数据。请注意,在通道重新打开事件发生时,Snowflake 中缓存的任何数据都将被丢弃,以避免提交这些数据。
您可以使用最新提交的偏移令牌来执行以下常见用例:
跟踪引入进度
将特定偏移与最新提交的偏移令牌进行比较,确认特定偏移是否已提交
推进源偏移,并清除已提交的数据
启用重复数据删除并确保确切传送一次数据
例如,Kafka Connector 可从主题读取偏移令牌,例如 <partition>:<offset>,或者仅为 :code:`<offset>`(如果分区编码在通道名称中)。考虑以下情景:
Kafka Connector 联机并在 Kafka 主题
T中打开了对应于Partition 1的通道,通道名称为T:P1。该连接器开始从 Kafka 分区读取记录。
该连接器调用 API,发出一条
insertRows方法请求,使用与记录关联的偏移作为偏移令牌。例如,偏移令牌可以是
10,代表 Kafka 分区中的第十条记录。连接器定期发出
getLatestCommittedOffsetToken方法请求,确定引入进度。
如果 Kafka Connector 崩溃,可完成以下过程,以恢复从 Kafka 分区的正确偏移位置读取记录。
Kafka Connector 重新联机,并使用与之前相同的名称重新打开通道。
连接器调用 API,发出一条
getLatestCommittedOffsetToken方法请求,以获取分区最新提交的偏移。例如,假设最新的持久偏移令牌是
20。连接器使用 Kafka 读取 APIs,重置与偏移加 1(本例中为
21)相对应的游标。连接器恢复读取记录。读取游标在重新定位成功后不会检索到重复数据。
在另一个示例中,应用程序从目录读取日志,并使用 Snowpipe Streaming Client SDK 将这些日志导出到 Snowflake。您可以构建一个日志导出应用程序,以执行以下操作:
列出日志目录中的文件。
假设日志记录框架生成可按字典顺序排序的日志文件,并且在此排序中,新的日志文件位于末尾。
逐行读取日志文件并调用 API,发出
insertRows方法请求,在请求中使用与日志文件名、行数或字节位置相对应的偏移令牌。例如,偏移令牌可能是
messages_1.log:20,其中的messages_1.log是日志文件的名称,20是行号。
如果应用程序崩溃或需要重新启动,它将调用 API,发出 getLatestCommittedOffsetToken 方法请求,检索与上次导出的日志文件和行相对应的偏移令牌。根据之前的例子,这可能是 messages_1.log:20。随后应用程序将打开 messages_1.log 并寻找 21 行,以防止同一日志行被引入两次。
备注
偏移令牌信息可能会丢失。偏移令牌链接到一个通道对象,如果 30 天内未使用该通道执行新的引入,该通道将自动清除。为了防止偏移令牌丢失,请考虑维护单独的偏移,并按需重置通道的偏移令牌。
offsetToken 和 continuationToken 的角色¶
offsetToken 和 continuationToken 都用于确保数据精确传输一次,但它们的用途不同,由不同的系统管理。主要区别在于谁控制令牌的价值及其使用范围。
continuationToken(only applies to the high-performance architecture):该令牌由 Snowflake 管理,对于维持单个连续流式传输会话的状态至关重要。当客户端使用
Append RowsAPI 发送数据时,Snowflake 返回continuationToken。客户端必须在下一个请求中使用此令牌,以确保以正确的顺序连续接收数据。Snowflake 使用令牌来检测和防止 SDK 重试时出现重复数据。offsetToken(applies to both the classic and high-performance architectures):该令牌是用户定义的标识符,允许从外部源确切传送一次。Snowflake 不会将此令牌用于自己的内部操作或防止重新引入。相反,Snowflake 仅存储这个值。外部系统(如 Kafka 连接器)有责任从 Snowflake 读取 offsetToken 并使用它来跟踪自己的引入进度,避免在需要重放外部流时发送重复的数据。
关于确切传送一次数据的最佳实践¶
实现确切传送一次数据可能并不容易,在自定义代码中遵守以下原则至关重要:
为了确保适当地从异常、故障或崩溃中恢复,您必须始终重新打开通道,并使用最新提交的偏移令牌重新启动引入。
应用程序可能会维护自己的偏移,但使用 Snowflake 提供的、最新提交的偏移令牌作为事实来源,并相应地重置自己的偏移,这一点至关重要。
唯一应将自己的偏移视为事实来源的情况是,Snowflake 的偏移令牌设置为或重置为 NULL。NULL 偏移令牌通常意味着以下情况之一:
这是一个新通道,因此尚未设置偏移令牌。
目标表已丢弃并重新创建,因此该通道视为新通道。
30 日内未通过通道执行任何引入活动,因此通道被自动清理,偏移令牌信息丢失。
如有必要,可根据最新提交的偏移令牌定期清除已提交的源数据,并推进您自己的偏移。
如果在 Snowpipe Streaming 通道处于活动状态时修改了表架构,则必须重新打开通道。 Snowflake Kafka Connector 会自动处理此场景,但如果您直接使用Snowflake Ingest SDK,则必须自行重新打开通道。
如需进一步了解带有 Snowpipe Streaming 的 Kafka Connector 如何实现确切传送一次数据,请参阅 Exactly-once 语义。
将数据加载到 Apache Iceberg™ 表中¶
借助 Snowflake Ingest SDK 3.0.0 及更高版本,Snowpipe Streaming 可以将数据引入 Snowflake 管理的 Apache Iceberg 表中。Snowpipe Streaming Ingest Java SDK 支持加载到标准 Snowflake 表( 非Iceberg)和 Iceberg 表。
有关更多信息,请参阅 将 Snowpipe Streaming Classic 与 Apache Iceberg™ 表结合使用。
延迟¶
Snowpipe Streaming 每秒自动刷新一次通道内的数据。您无需关闭通道即可刷新数据。
在 Snowflake Ingest SDK 2.0.4 及更高版本中,您可以使用 MAX_CLIENT_LAG 选项配置延迟。
对于标准 Snowflake 表(非 Iceberg),默认
MAX_CLIENT_LAG为 1 秒。对于 Iceberg 表(由 Snowflake Ingest SDK 3.0.0 及更高版本提供支持),默认
MAX_CLIENT_LAG为 30 秒。
最大延迟时间可以设置为 10 分钟。 有关更多信息,请参阅 MAX_CLIENT_LAG (https://javadoc.io/doc/net.snowflake/snowflake-ingest-sdk/latest/net/snowflake/ingest/utils/ParameterProvider.html#MAX_CLIENT_LAG) 和 推荐的 Snowpipe Streams 延迟配置。
请注意,Snowpipe Streaming 的 Kafka Connector 有自己的缓冲区。达到 Kafka 缓冲区刷新时间后,数据将通过 Snowpipe Streaming 按一秒的延迟发送到 Snowflake。有关更多信息,请参阅 buffer.flush.time。
迁移到经典架构中的优化文件¶
API 将通道中的行写入云存储中的 blob,然后提交到目标表。在初始情况下,写入目标表的流数据以临时中间文件格式存储。在此暂存区,该表被视为“混合表”,因为分区数据使用本机文件与中间文件的混合形式存储。一个自动后台进程根据需要,将数据从活动中间文件迁移到针对查询和 DML 操作而优化的本机文件。
在经典架构中复制¶
Snowpipe Streaming 支持 Snowpipe Streaming 填充的 Snowflake 表及其关联的通道偏移从不同 区域、跨 云平台 的源账户到目标账户的 复制和故障转移。
高性能架构不支持复制。
有关更多信息,请参阅 复制和 Snowpipe 流。
仅限插入操作¶
API 目前仅限于插入行。要修改、删除或合并数据,请将“原始”记录写入一个或多个临时表。若要合并、连接或转换数据,请使用 :doc:` 连续数据管道 </user-guide/data-pipelines-intro>` 将修改后的数据插入目标报告表。
类和接口¶
有关经典架构的类和接口的文档,请参阅 Snowflake Ingest SDK API (https://javadoc.io/doc/net.snowflake/snowflake-ingest-sdk/latest/overview-summary.html)。
有关经典架构和高性能架构之间的区别,请参阅 API 区别。
支持的 Java 数据类型¶
下表汇总了支持将哪些 Java 数据类型引入到 Snowflake 列:
Snowflake 列类型 |
允许的 Java 数据类型 |
|---|---|
|
|
|
|
|
|
|
|
|
请参阅 布尔转换详细信息。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所需访问权限¶
调用 Snowpipe Streaming API 需要具有以下权限的角色:
对象 |
权限 |
|---|---|
表 |
OWNERSHIP 或至少 INSERT 和 EVOLVE SCHEMA(仅当将 Kafka Connector 的架构演化与 Snowpipe Streaming 结合使用时才需要) |
数据库 |
USAGE |
架构 |
USAGE |
管道 |
OPERATE(仅适用于高性能架构) |
限制¶
对于 Snowpipe Streaming Classic,请注意以下限制:
Snowpipe Streaming Classic 不支持增加数据库对象的最大大小限制(VARCHAR、VARIANT、ARRAY 和 OBJECT 为 128 MB,而 BINARY、GEOGRAPHY 和 GEOMETRY 为 64 MB),这是 2025_03 行为变更捆绑包 的一部分。
故障安全不支持包含 Snowpipe Streaming Classic 引入的数据的表。对于此类表,无法使用故障安全进行恢复,因为该表上的故障安全操作完全失败。
Snowpipe Streaming 仅支持使用 256 位 AES 密钥进行数据加密。
如果在 Snowpipe Streaming 正插入到的同一个表上也启用了 自动群集,则文件迁移的计算成本可能会降低。有关更多信息,请参阅 Snowpipe Streaming Classic 最佳实践。
不支持以下对象或类型:
GEOGRAPHY 和 GEOMETRY 数据类型
带有排序规则的列
TEMPORARY 表
每个表的通道总数不能超过 10000。我们建议在需要时重复使用通道。如果您需要为每个表打开超过 10000 个通道,请联系 Snowflake 支持部门。
与经典架构相比,高性能架构还有其他注意事项和限制。有关更多信息,请参阅 高性能架构限制。