Snowpark Migration Accelerator:精选报告¶
Snowpark Migration Accelerator (SMA) 会通过分析详细数据生成全面的评估报告。下一节列出了这些可用报告。
评估结果,包括所有元素的详细清单,可在 以下页面的电子表格 中找到。
详细报告¶
危险
自 Spark Conversion Core V2.43.0 起,DetailedReport.html 报告已被弃用,不再受支持。
备注
本页解释了详细报告的每个部分,如文档文件所示。
SMA 详细报告是主要的分析报告,提供跨多个部分的全面信息。
评估报告包含以下部分及其描述:
详细报告的第一页简要概述了 Snowpark Migration Accelerator (SMA) 工具。

本页包含以下小节:
“执行摘要”部分显示:
您在 项目创建 设置中的组织名称和电子邮件地址
每次 SMA 执行的唯一识别码(此 ID 在整个清单部分均有引用)
执行的时间戳
SMA 和 Snowpark API 的版本详情
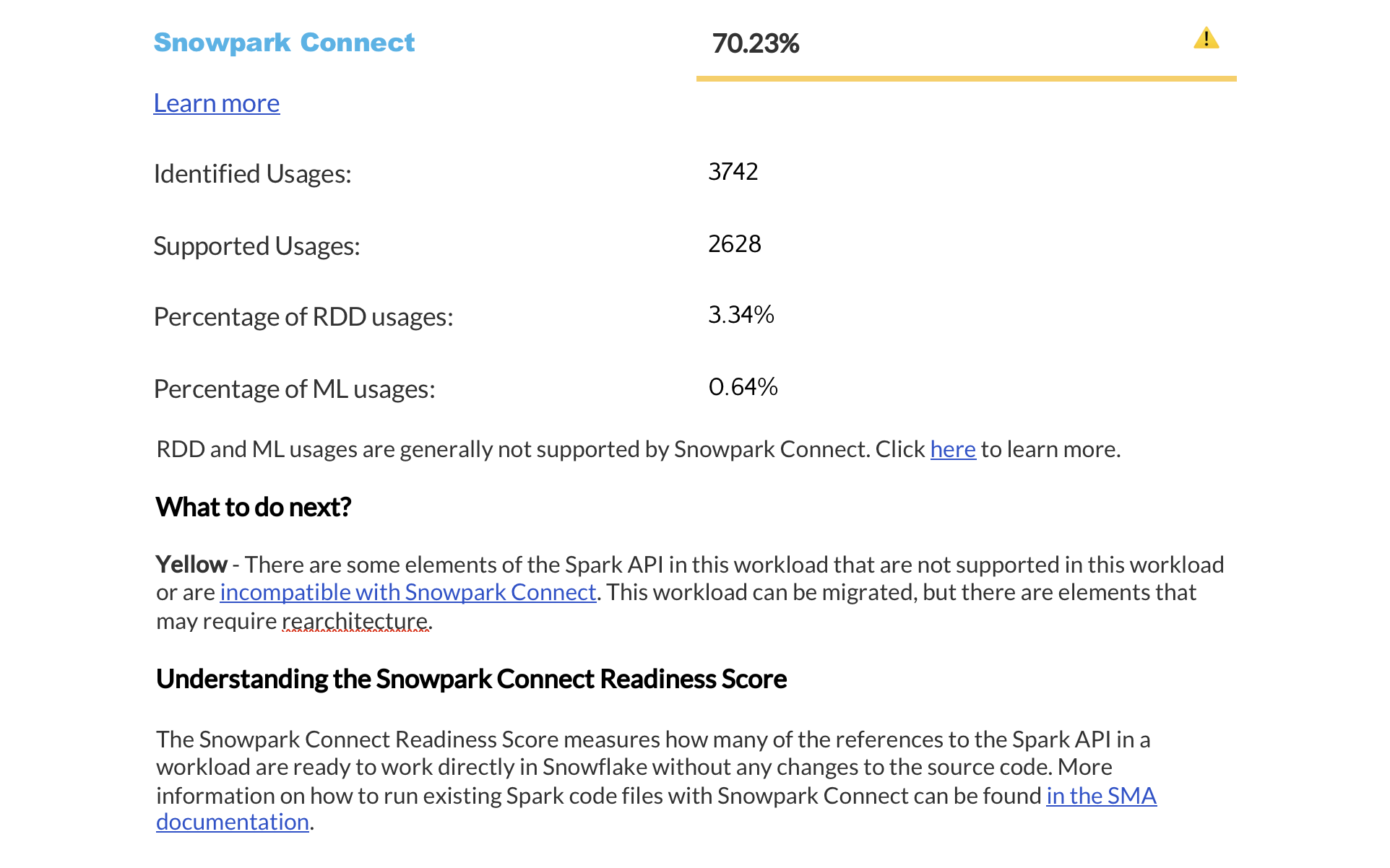
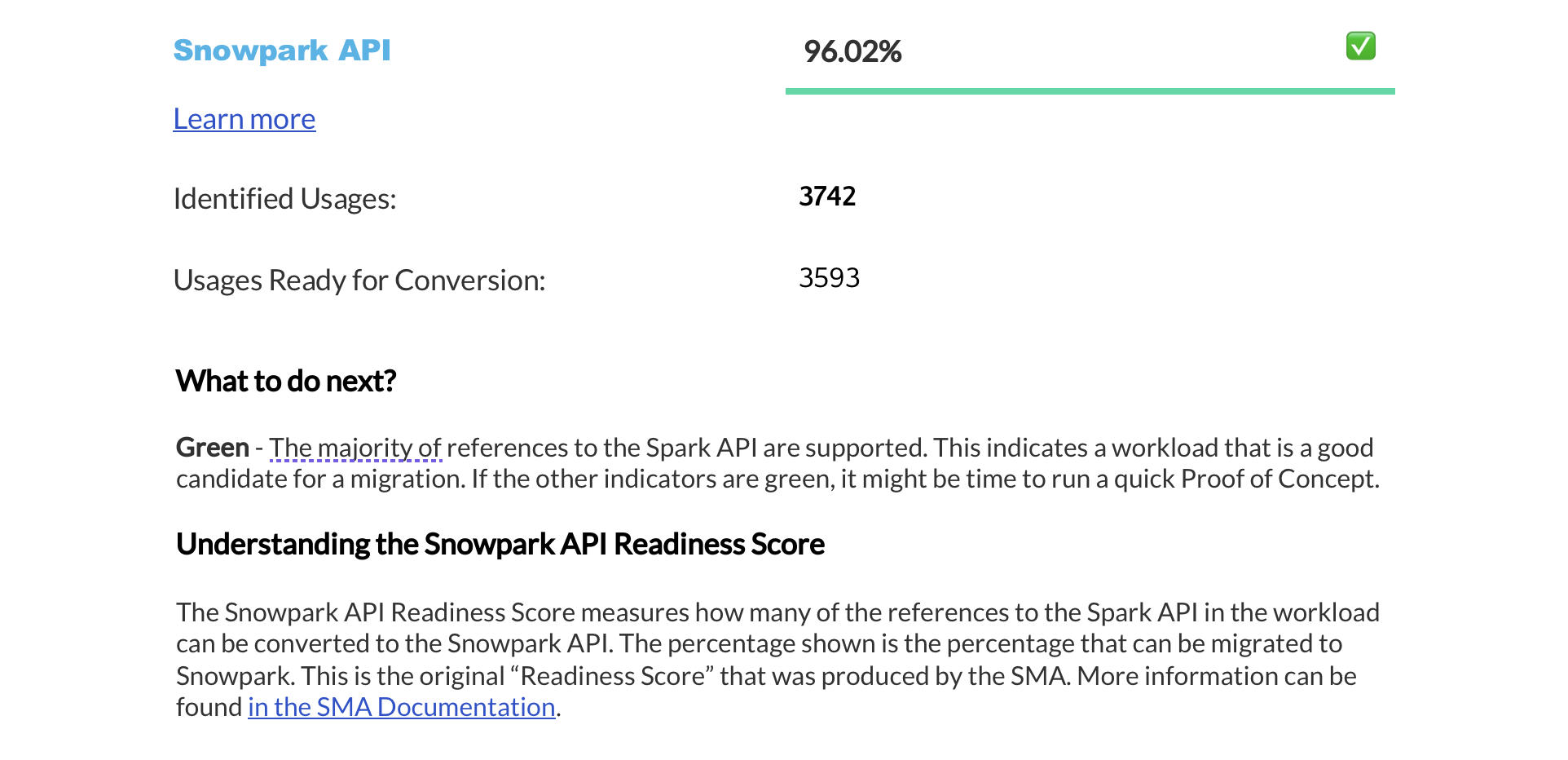
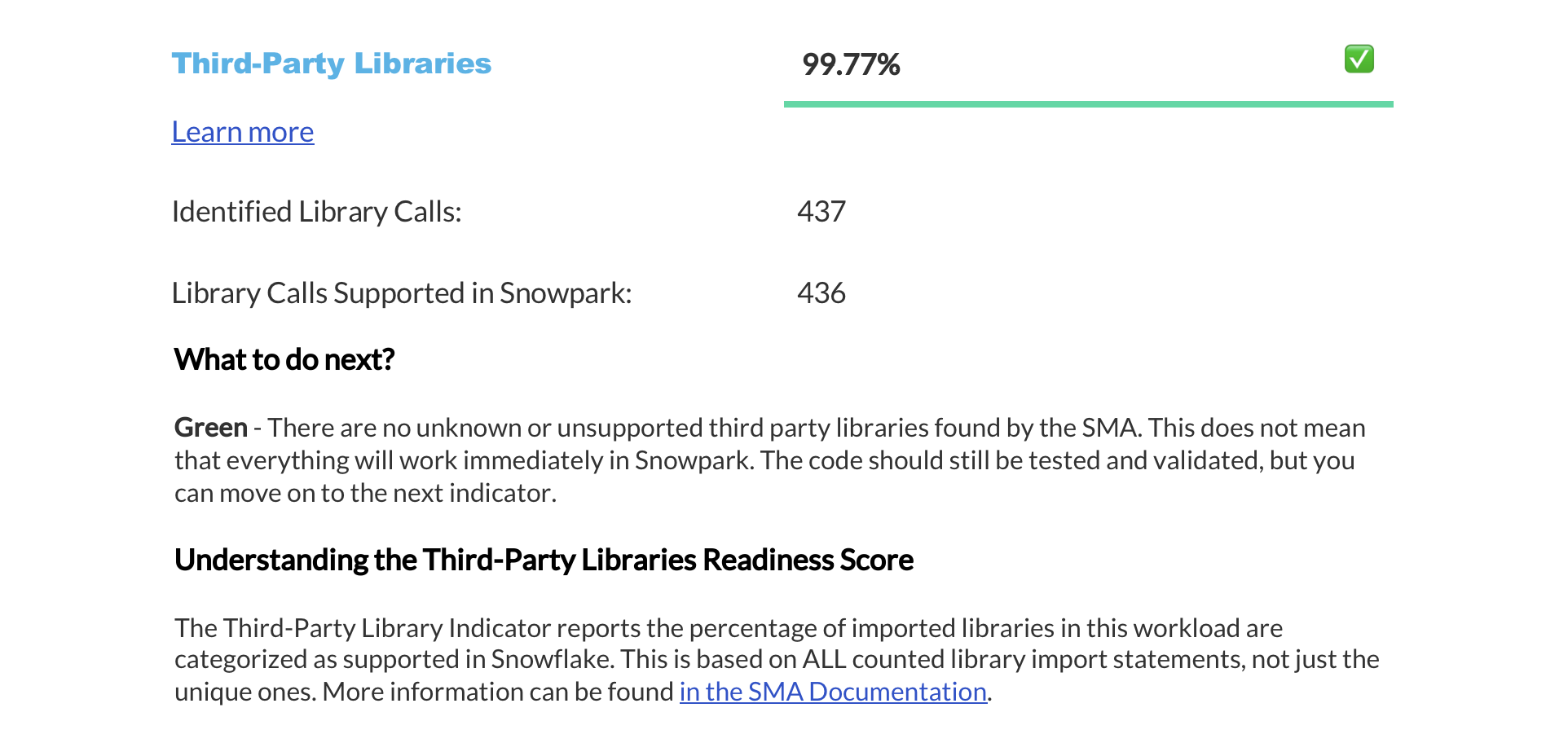
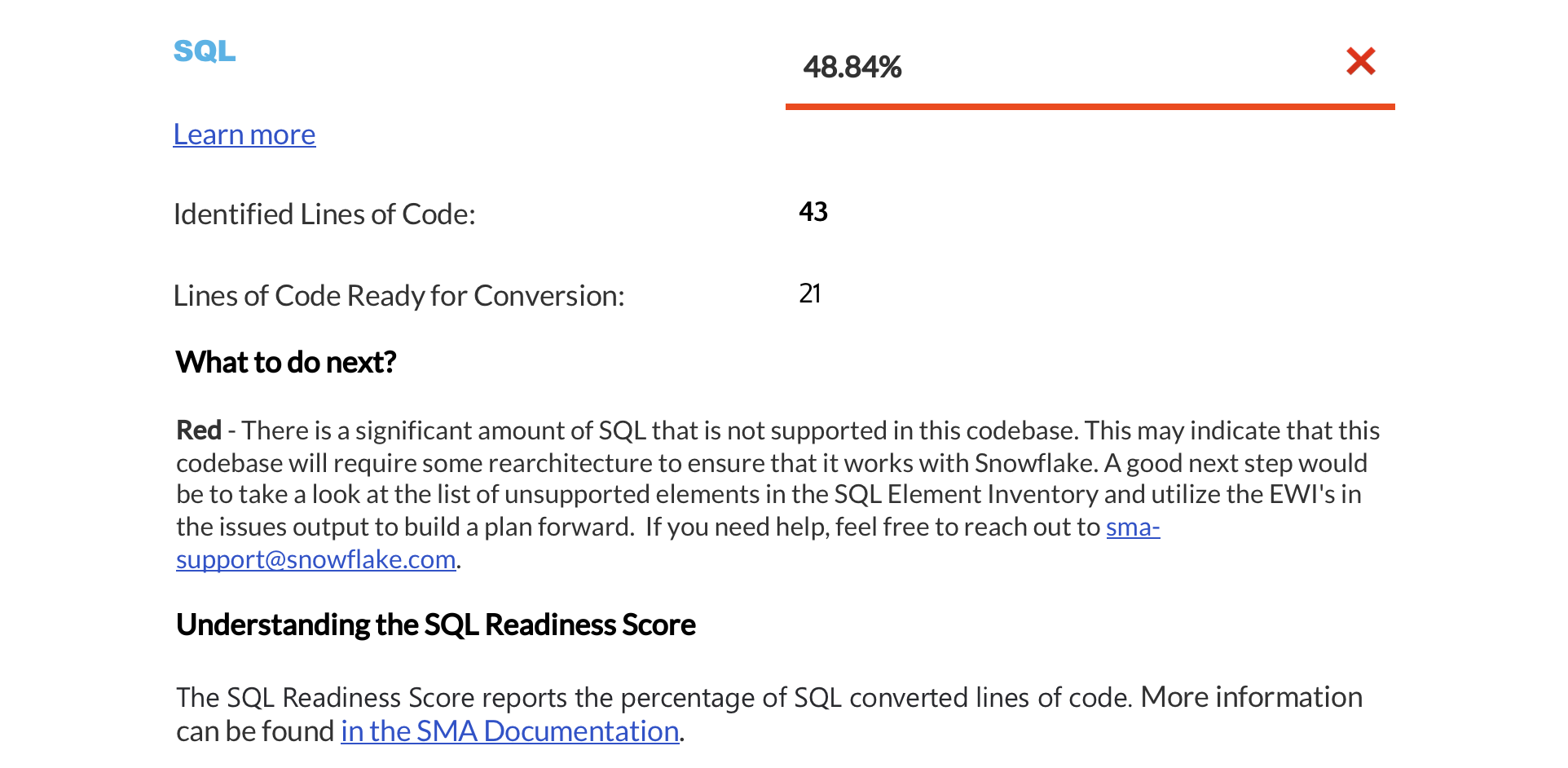
就绪度分数摘要¶
The next page displays a summary of readiness scores. It includes scores for Spark API and Third-Party libraries, along with guidance on how to interpret them. These scores help you understand how well-prepared your codebase is for migration to Snowflake.

本部分提供有关每个就绪度分数的详细信息。
文件摘要¶
文件摘要部分从下一页开始。本部分可能跨越多个页面,具体取决于在此工具执行期间处理了多少不同的文件类型。
该信息也可见于 应用程序中提供的评估摘要。

文件类型摘要:显示已识别技术的细分,包括每种技术类型的文件数量、它们的总代码行数以及它们在所有分析文件中所占的百分比。
文件扩展名摘要:显示每个已识别文件扩展名的统计信息,包括带有该扩展名的文件数量、它们的总代码行数以及它们在所有分析文件中所占的百分比。

代码文件大小分析:按大小类别(“T 恤”尺码)显示代码文件的分布情况。每个大小类别显示文件数量及其占总代码库的百分比。
笔记本语言统计信息:按编程语言提供所有已扫描笔记本中代码行和单元格的细分。
笔记本大小分类(按语言):根据其总代码行数按大小对每个笔记本文件进行分类。笔记本类型(Python、Scala 或 SQL)由所使用的主要语言决定。尺码类别:
XS:少于 50 行
S:50-200 行
M:200-500 行
L:500-1,000 行
XL:1,000 行以上
Spark API 摘要¶
Spark API 摘要提供了“就绪度分数”部分中显示的就绪度分数的详细分析。本部分包含四个表:
包含 Spark API 引用的文件列表
受支持和不受支持功能的明细表
按 Spark API 类别排列的就绪度分数
按映射状态排列的就绪度分数
我们将解释支持和不支持哪些 Spark API 引用。以下是这些术语的含义:
Supported:Snowpark Migration Accelerator (SMA) 可以自动将此 API 元素转换为 Snowpark API 或提供已知的替代方案。
不支持:Snowpark Migration Accelerator (SMA) 无法自动将此 API 元素转换为 Snowpark API。这并不意味着无法进行转换,但需要手动干预。

带有 Spark 引用的文件:下表显示了工作负载中按技术类型分类的 Spark 技术使用情况明细。
具有 Spark 支持状态的文件:此表按技术类型显示源代码中支持和不支持的 Spark 功能的数量。


Spark API 使用摘要:该表显示了 Python 和 Scala 支持和不支持的 Spark API 函数数量。该表按 API 类别组织,包括 Spark API 就绪度分数,该分数与“就绪度分数”部分中显示的分数相匹配。
Spark API 使用支持类别:按支持状态划分的代码中使用 Spark API 函数的次数明细。有关每个支持类别的详细描述,请参阅 Spark 引用类别页面。
Pandas API 使用摘要¶
备注
Pandas API 使用摘要仅适用于包含 Python 文件的执行。
Pandas API 摘要提供了对 Pandas API 的引用列表,类似于之前显示的 Spark API 摘要。

使用 Pandas 的文件:显示整个工作负载中每种技术中引用的 Pandas 数量明细。
Pandas API 使用摘要:源代码中使用的 Pandas 库函数的详细列表,按使用频率排序。
导入参考摘要¶
“导入分析”部分显示导入到您的代码库的所有外部依赖关系。这包括用于所有文件的第三方库和其他外部组件。请注意,从您自己的代码库中的文件导入的内容未显示在此表中。

该表显示了 Python 包信息以及以下详细信息:
导入的包名称
Snowpark 的 Anaconda 发行版是否支持每个包
每个包在导入中出现的次数
包含每次导入的文件百分比
请注意,虽然“百分比”列总数等于 100%,但单个百分比的总和可能超过 100%,因为文件通常包含多个包导入。
SQL 参考摘要¶

按文件类型划分的 SQL 使用情况:此表根据不同技术对 SQL 使用情况进行了分类,显示了工作负载中发现的 SQL 文件和 SQL 单元的总数。
按支持状态划分的 SQL 使用情况:此表根据 SQL 元素在 Snowflake 中是否具有等效功能来组织 SQL 元素。
Snowpark Migration Accelerator (SMA) 问题摘要¶
每当检测到代码中存在的警告、转换错误或解析错误时,Snowpark Migration Accelerator (SMA) 都会创建问题报告。解决这些问题对于使用 SMA 成功完成代码迁移至关重要。
有关理解和分析问题的详细指南,请参阅文档的 问题分析部分。
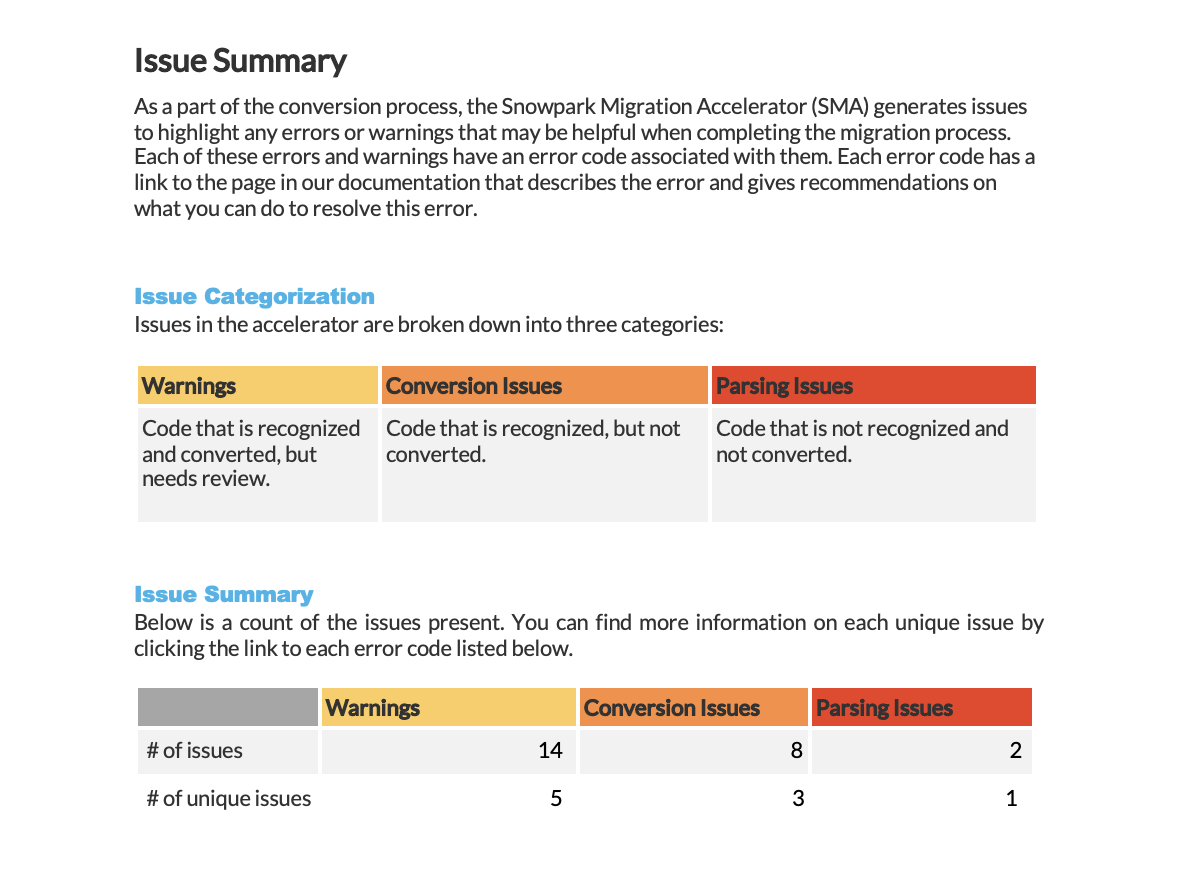
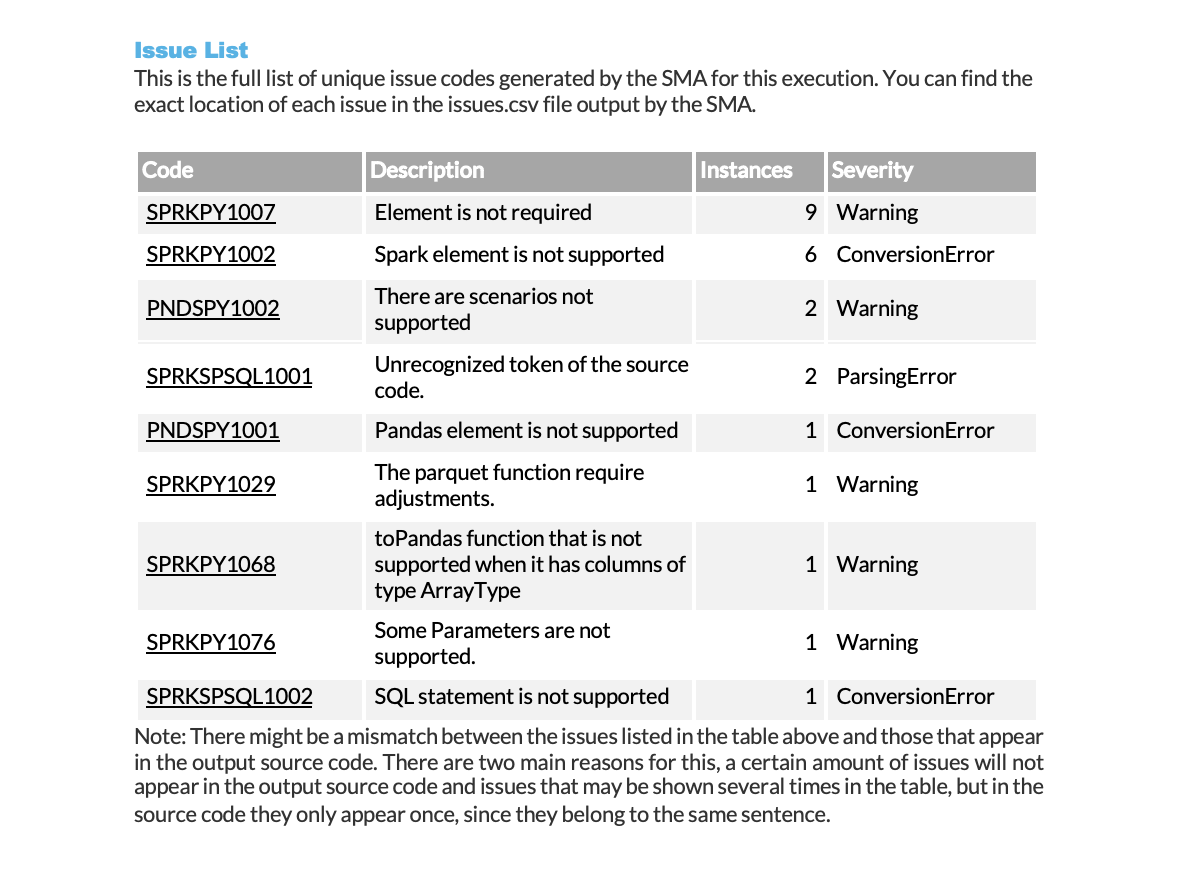
摘要显示了每个问题,其中包含以下信息:
问题代码(带有指向详细文档的链接)
工作负载中的出现次数
严重性级别
该报告显示三个严重性级别(警告、转换错误和解析错误)以及按每个级别组织的摘要。
使用迁移工具时,请遵循以下优先级来处理不同类型的问题:
首先解决解析错误,因为这些错误需要立即处理
通过编程解决方案解决转换错误
在整个迁移过程中监控和跟踪警告
附录
附录 A 提供了所有映射状态类别的详细描述。

这份综合报告包含从 Snowpark Migration Accelerator (SMA) 生成的 清单文件 中收集的详细信息。
有关该报告的详细信息,请通过 sma-support@snowflake.com 与 Snowpark Migration Accelerator (SMA) 团队联系。
危险
摘要报告 功能已移除,从 Spark Conversion Core V2.43.0 开始不再提供
SMA 会生成多个输出报告,其中包括结果中的详细电子表格。