Snowpark Migration Accelerator:就绪度分数¶
Snowpark Migration Accelerator (SMA) 会评估您的代码并生成详细的评估数据。为了使这些信息更易于访问,SMA 会计算就绪度分数,以衡量您的代码迁移到 Snowflake 的难易程度。这些分数充当兼容性指标 – 分数越高,您的代码与 Snowflake 平台的兼容性越强。您只需运行 SMA 工具即可获得这些分数。
SMA 生成以下就绪度分数:
就绪度分数表示代码与 Snowflake 的兼容性,而不是还有多少工作要做。即使就绪度分数很高,其余不兼容的代码可能仍需要大量努力才能迁移。要准确估计迁移所需的工作,请查看完整的评估报告。如果您在制定迁移计划或估算所需工作量方面需要帮助,请 联系 我们的团队。
等级¶
Snowpark Migration Accelerator (SMA) 使用类似于交通信号灯的颜色编码评分系统:
红色 – 检测到严重问题。立即停止并解决问题,因为它会严重影响迁移过程或阻碍准确的代码分析。在继续操作之前,请遵循提供的操作步骤。
黄色 – 检测到警告。仔细查看操作步骤,了解对迁移的潜在影响。了解其中的含义之后,您可以继续下一步。
绿色 – 未检测到重大问题。尽管这表明没有明显的迁移障碍,但代码可能仍需要调整。查看操作步骤并继续迁移过程。
如何解读分数¶
对于每个分数,您将获得:
数值
状态指示灯(如前所述,红色、黄色或绿色)
建议的下一步操作
我们强烈建议您执行以下操作:
按顺序查看分数 – 当您遇到红色分数时,立即调查并解决该问题
查看每个分数的所有建议操作 – 查看所有结果的建议后续步骤,包括绿色分数,因为它们包含重要的操作项目
我们来看看系统中目前提供的就绪度分数。
Snowpark API Readiness Score¶
The Snowpark Migration Accelerator (SMA) generates a Snowpark API Readiness Score, which indicates how ready your code is for migration. It's important to note that this score only evaluates the usage of Spark API components and does not assess other elements such as third-party libraries or external dependencies in your code.
当 SMA 分析代码时,它会识别所有 Spark API 引用,包括导入语句和函数调用。这些引用记录在 Spark API 使用情况清单 中,您可以在本地输出目录中找到该清单。根据 Spark 引用类别,每种引用都归类为“支持”或“不支持”。就绪度分数的计算公式是:支持的引用数除以代码中找到的引用总数。

该分数以百分比显示,用于指示 Snowflake 对代码中 Spark API 引用的支持程度。百分比越高,意味着与 Snowflake 的兼容性越好。您可以在应用程序的 详细报告 和 评估摘要 部分中查看该分数。
此处显示的就绪度分数是 SMA 生成的原始分数。对于仅显示一个就绪度分数的较新 SMA 版本,该分数专门用于衡量 Spark API 兼容性。
Snowpark API Readiness Levels¶
根据计算得出的分数,结果将归为三种类别之一:绿色、黄色或红色。应用程序和输出报告将根据您的分数类别提供具体建议。
The Snowpark API Readiness Score will be assigned one of these levels:
绿色:支持大多数 Spark API 引用,这使得该工作负载成为迁移的有力候选对象。如果其他指标也为绿色,请考虑继续进行概念验证。
黄色:不支持某些 Spark API 引用,这将需要额外的迁移工作量。后续步骤应包括创建不支持的项目清单和估算所需的转换工作量。
Snowpark Connect Readiness Score¶
The Snowpark Connect Readiness Score measures the percentage of Spark API references in your codebase that are supported by Snowpark Connect. This score provides an assessment of your existing Spark API code's readiness for execution within the Snowpark Connect environment.
How It's Calculated¶
During its execution, the SMA scans your codebase to identify all references to the Spark API. Examples of such references include import statements, function calls, and class instantiations. All discovered references are then logged in the Spark API Usages Inventory. This inventory is generated as a file in your local output directory. For every reference listed in the inventory, the SMA populates the IsSnowparkConnectToolSupported column, setting it to True if the API usage is supported by Snowpark Connect, or False if it is not.
To calculate the readiness score, the SMA takes all of the supported references and divides them by the total references found in the codebase:
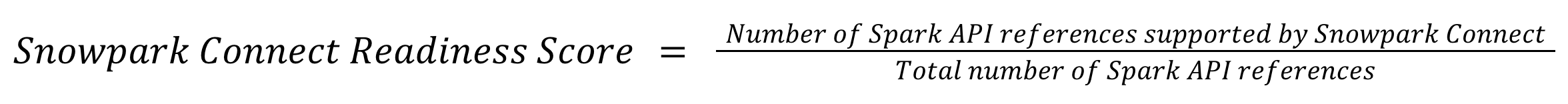
For example, if your codebase has 100 Spark API references and 90 of them are supported by Snowpark Connect, your Snowpark Connect Readiness Score would be 90%.
A higher percentage for the Snowpark Connect Readiness Score indicates a greater degree of compatibility with Snowpark Connect, suggesting that a larger portion of your Spark code aligns with functionalities supported by Snowpark Connect.
Readiness Levels¶
The compatibility analysis yields a readiness score, which is categorized into one of three distinct levels: Green, Yellow, or Red. Both the application's assessment summary and the generated detailed report will display this readiness level, accompanied by specific guidance tailored to the findings:
Green - This workload is highly compatible with Snowpark Connect as the majority of references to the Spark API are supported without any code changes. Files that are fully compatible can be run immediately, though some files will still require issue resolution.
A good next step would be to try to run some of the files in Snowflake. View the reports generated by the SMA and select a file that might be ready to run with Snowpark Connect.
Yellow - There are some elements of the Spark API in this workload that are not supported in Snowpark Connect or are incompatible with Snowpark Connect for Spark. This workload may still be able to run with Snowpark Connect, but there are elements that will require issue resolution or even re-architecture.
The recommended next step would be to evaluate if code conversion makes more sense. You can do this by converting this workload to the Snowpark API, and reviewing the Snowpark API Readiness Score. You can also dive deeper into this workload's compatibility with Snowpark Connect by viewing the reports generated by the SMA. You can explore the compatibility with Snowpark by understanding which files may be ready to run and working through the Spark elements that have issues that need resolution.
Red - This workload has a significant number of references to the Spark API that are not supported in Snowpark Connect. However, this workload may still be a good candidate for conversion to the Snowpark API. The recommended next step would be to convert this workload, and take a look at the Snowpark API Readiness Score. If you need help, feel free to reach out to sma-support@snowflake.com.
If you would still like to further explore the compatibility with Snowpark Connect, you can view the reports generated by the SMA. A good place to start would be to understand which files may be ready to run.
第三方 API 就绪度分数¶
第三方就绪度分数显示了多少导入的库可用于 Snowflake。为更好地理解该分数,我们首先解释下我们所说的“第三方”的含义:
第三方库:任何非由 Snowflake(或 Snowflake 中的 Snowpark)开发、维护或控制的包或库。
就绪度分数表示与 Snowflake 兼容的外部库和包的百分比。对于 Python 代码,兼容性意味着包可通过 Snowpark 中的 Anaconda 包集合 获得。对于 Scala 或 Java 代码,兼容性意味着包已包含在 Snowpark 的核心功能中。
就绪度分数的计算公式是:支持的第三方库导入数除以代码中第三方库导入总数。

有关就绪度分数的重要信息:
Snowpark 支持的第三方库:这包括 Snowpark 支持的所有库(包括 org.apache.spark)
第三方库调用总数:代码中所有第三方库调用的总和,包括 Spark 库和非 Spark 库,无论它们是否受 Snowpark 支持。
只有导入使用情况清单中标记为“ThirdPartyLib”的导入才会计算在内。内部依赖项和代码库内部的导入不包括在内。
此指标会计算调用总数,而不是唯一的库引用。例如,如果代码总共有 100 次库调用,其中有 80 次调用不受支持的库,20 次调用受支持的库,则支持分数将为 20%。这显示了代码中支持的库与不支持的库的实际使用频率,而不是唯一库引用的比例。
第三方 API 就绪级别¶
根据计算得出的分数,结果将归为三种类别之一:绿色、黄色或红色。应用程序和输出报告将根据您的分数类别提供具体建议。
第三方 API 就绪度分数将被分配以下级别之一:
绿色 – 代码库使用 Snowflake 完全支持的 Python 库。无需额外配置。
黄色 – 代码库包含至少一个 Snowpark 目前不支持的 Python 包或库。您可以使用 第三方包文档 中描述的几种方法添加不支持的第三方包。要识别不支持的包,请查看 SMA 生成的 导入使用情况清单。然后,分析如何在代码中使用这些包,并计划在 Snowflake 中实现它们。
红色 – 代码库严重依赖 Snowpark 不支持的包或库。这可能意味着要么在整个代码中广泛使用单个不支持的库,要么在代码库的不同部分使用多个不支持的库。要了解影响,必须对这些导入声明进行全面评估。如需包支持方面的指导或帮助,请联系 sma-support@snowflake.com。
SQL 就绪度分数¶
SQL 就绪度分数表明源代码中可以使用 Snowpark Migration Accelerator (SMA) 自动转换为 Snowflake SQL 的 SQL 元素的百分比。分数越高意味着可以自动转换的代码越多,迁移过程也就会变得更轻松、更快捷。
就绪度分数的计算公式是:可以转换的 SQL 元素数除以源代码中找到的 SQL 元素总数。

SQL 就绪度分数级别¶
SQL 就绪度分数将被分配以下级别之一:
绿色 – 此代码库中的大多数 SQL 要么由 Snowflake 直接支持,要么可以由 SMA 自动转换。虽然没有任何转换是完美的,但这种工作负载只需要极少的手动调整即可完成 Snowflake 迁移。
黄色 – 此代码库中的某些 SQL 元素不受 Snowflake 支持,需要额外的工作量才能进行迁移。查看 SQL 元素清单中是否存在不支持的功能,并检查问题输出中的 EWI 以制定行动计划。您可能需要对代码进行细微调整或局部重新设计某些组件。
红色 – 此代码库中的大部分 SQL 与 Snowflake 不兼容,这表明可能需要进行大幅重新设计。要继续,请查看 SQL元素清单中是否存在不支持的功能,并检查问题输出中的 EWI 以制定迁移策略。如需帮助,请联系 sma-support@snowflake.com。
尽管就绪度分数提供了宝贵的见解,但它们不应是决定工作负载迁移就绪度的唯一因素。除这些分数外,还要考虑迁移计划的多个方面,因为它们是初步评估,而不是完整的评估。如果您发现任何就绪度指标有待改进或工具中未准确表示,请 告诉我们。SMA 团队不断努力增强并完善这些就绪度衡量。