Snowpark Migration Accelerator:运行该工具¶
现已安装好 Snowpark Migration Accelerator (SMA) 并准备好代码库,您可以开始执行过程了。如果 SMA 应用程序仍处于开启状态,则返回该应用程序;若已关闭,则将其启动。
项目设置¶
When you first open the SMA, the project page is shown.
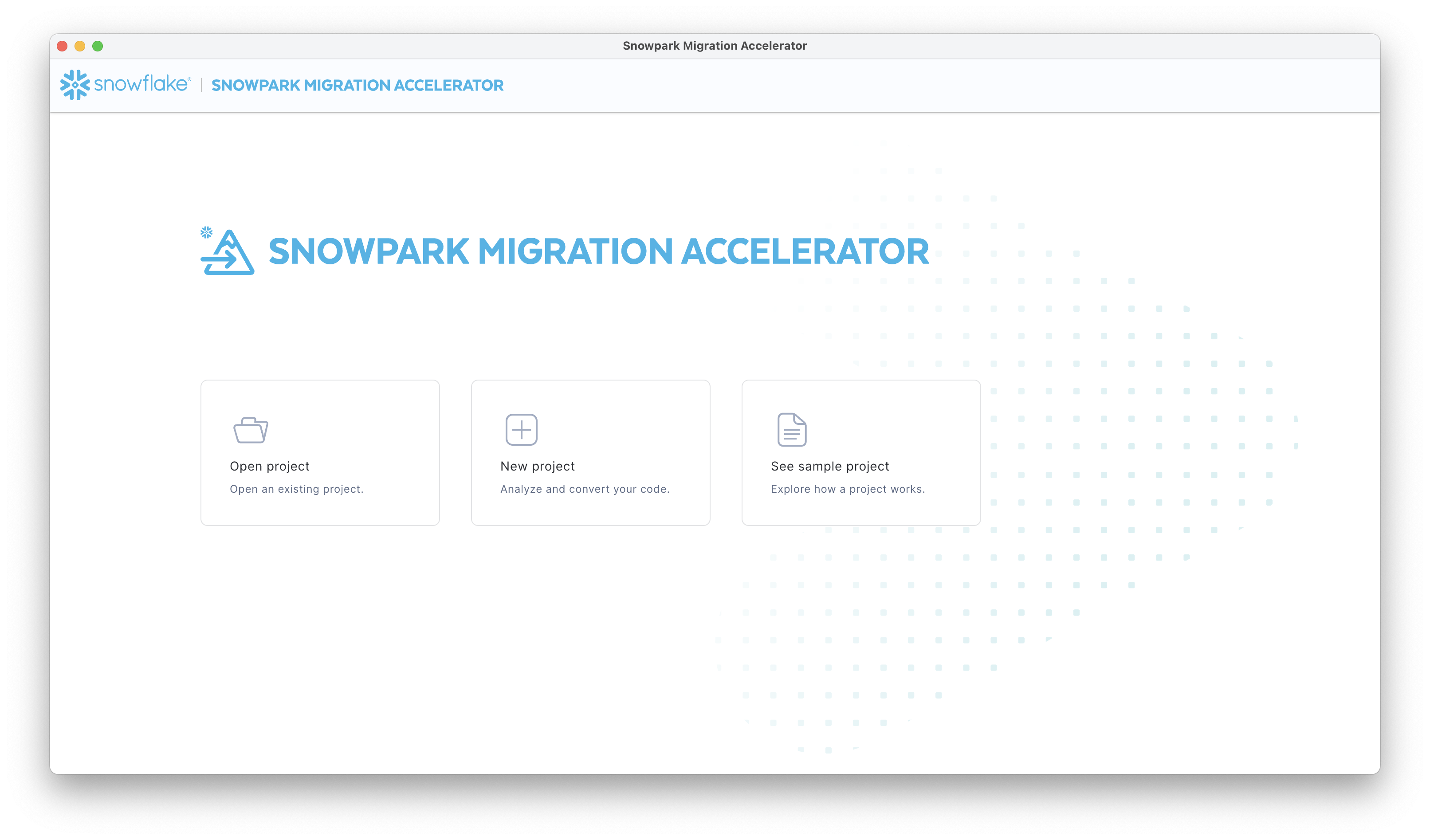
从菜单中选择“New Project”开始。如果您已为此演练创建了一个项目,则可通过选择“Open Project”来访问该项目。
The "Project Creation" page allows you to create a new project file, which is essential for both assessment and code conversion tasks in SMA. The project file (with a .snowct extension) is stored in your selected output directory and keeps track of all your SMA executions. If you want to link multiple executions together, you can reopen an existing project file. All project information is saved both on your local machine and in the shared database. For more details about projects, see the "project" file.
All fields shown are required for configuring the assessment tool and managing the project after running the analysis.
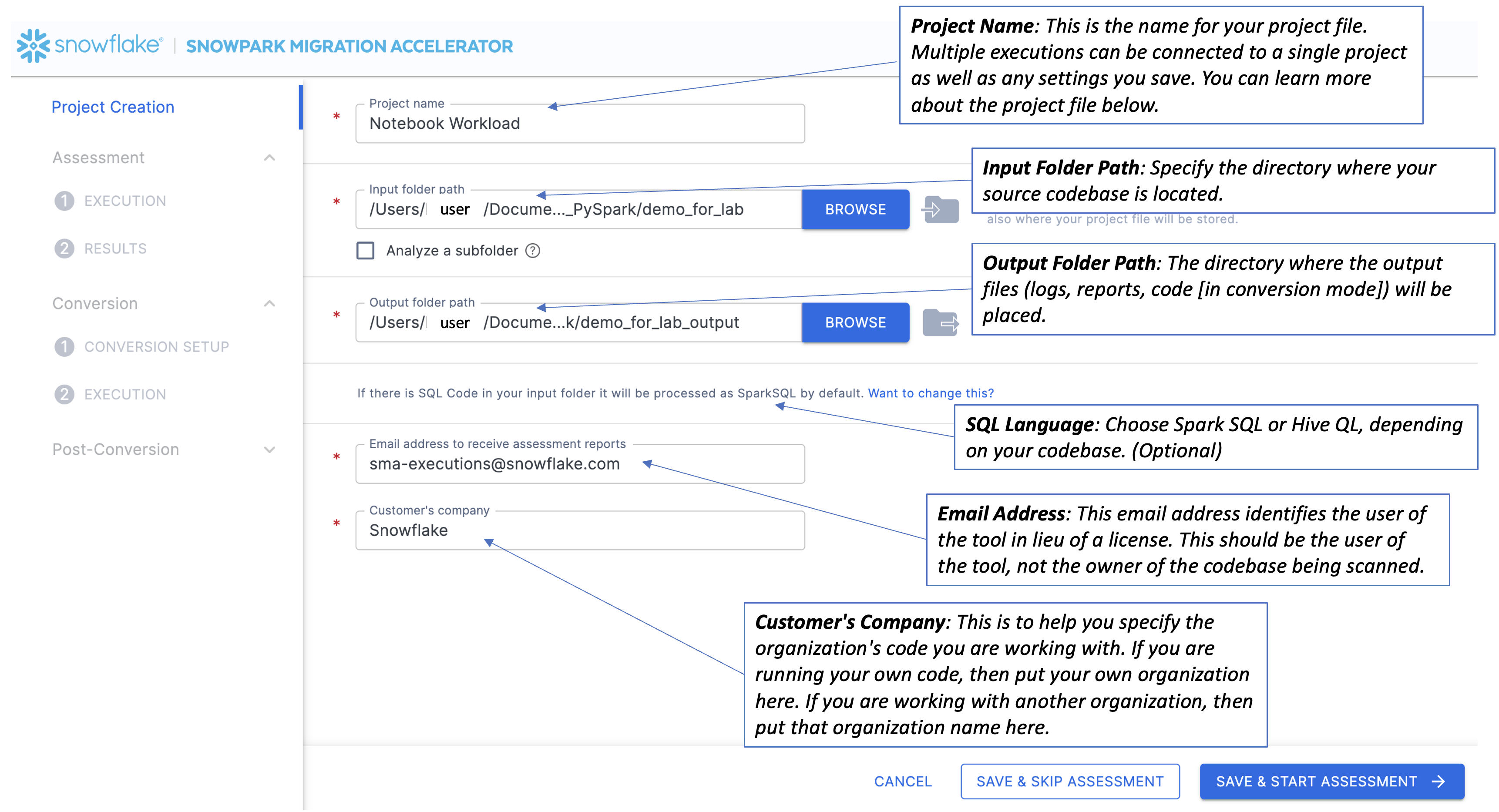
Project name: This is the name for your project file. Multiple executions can be connected to a single project as well as any settings you save. You can learn more about the project file below.
Email address: This email address identifies the user of the tool. This should be the user of the tool, not the owner of the codebase being scanned.
Company name: This is to help you specify the organization's code you are working with. If you are running your own code, then put your own organization here. If you are working with another organization, then put that organization name here.
Input folder: Specify the directory where your source codebase is located.
Output folder: The directory where the output files (logs, reports, code) will be placed.
For this walkthrough, we will use the "Spark Data Engineering Examples" codebase. You can find it in the sample codebases section. Follow these steps:
下载并解压缩代码库
找到包含所有文件的根目录(这将是您的输入目录)
选择您喜欢的任何项目名称
选择输出目录(工具会建议一个默认目录,但您也可以自行更改)
Before starting the assessment, make sure your input directory contains the correct source code files with the proper file extensions, as explained in the code preparation section.
When you are ready to begin, click Save to save your project.
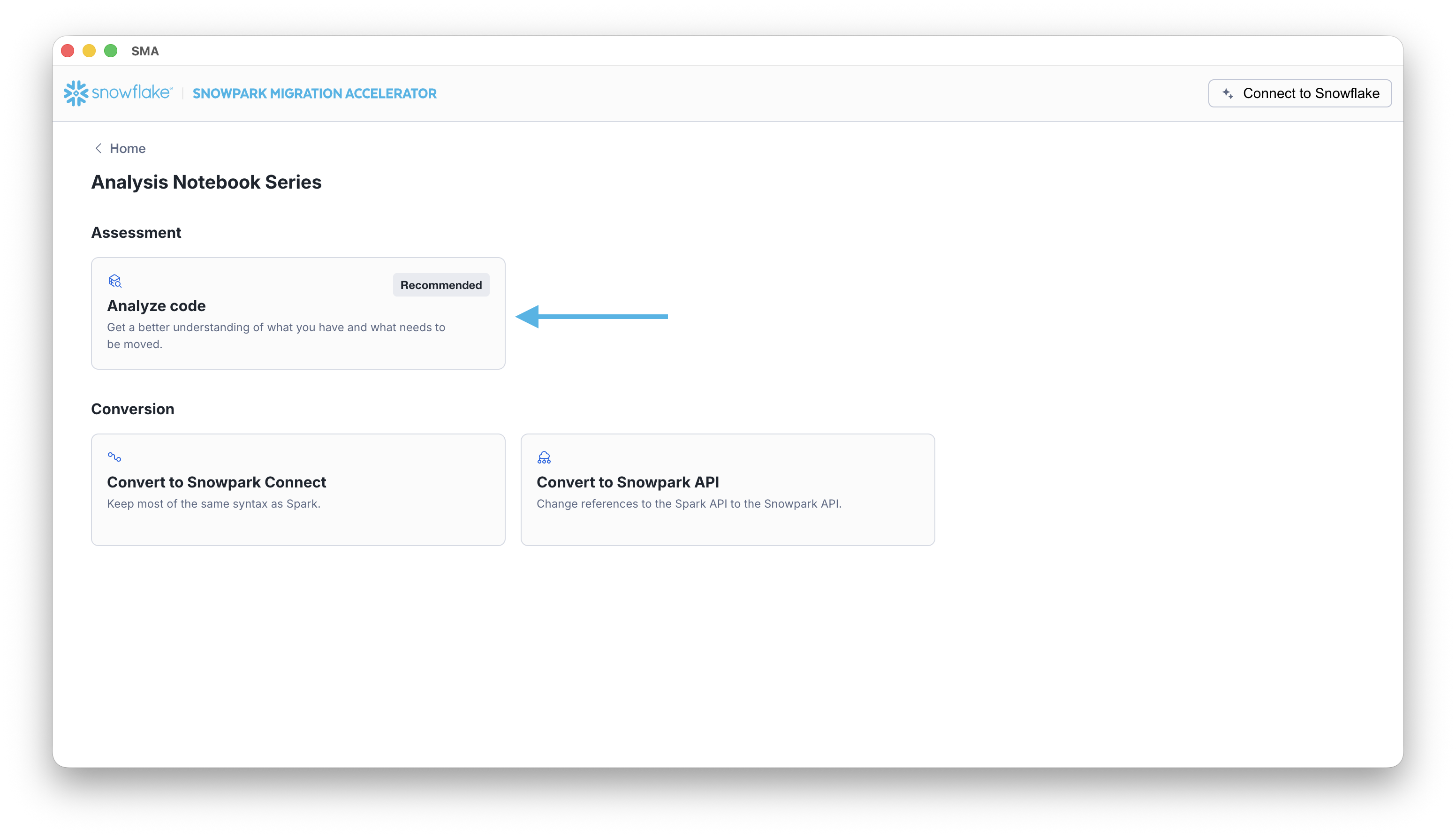
After you save, the SMA takes you to the project home page. Select the Code Process tile to start the guided assessment or conversion workflow:
执行和评估输出¶
当您开始评估过程后,SMA 会按以下三个步骤分析源代码:
首先,它会进行基础扫描,以创建代码库中所有文件和关键字的清单。
然后,根据您的源语言解析代码,并创建表示代码功能的语义模型。
Finally, it uses this model to generate detailed information, including the Spark Reference Inventory and Import Library Analysis. It also produces the converted code.
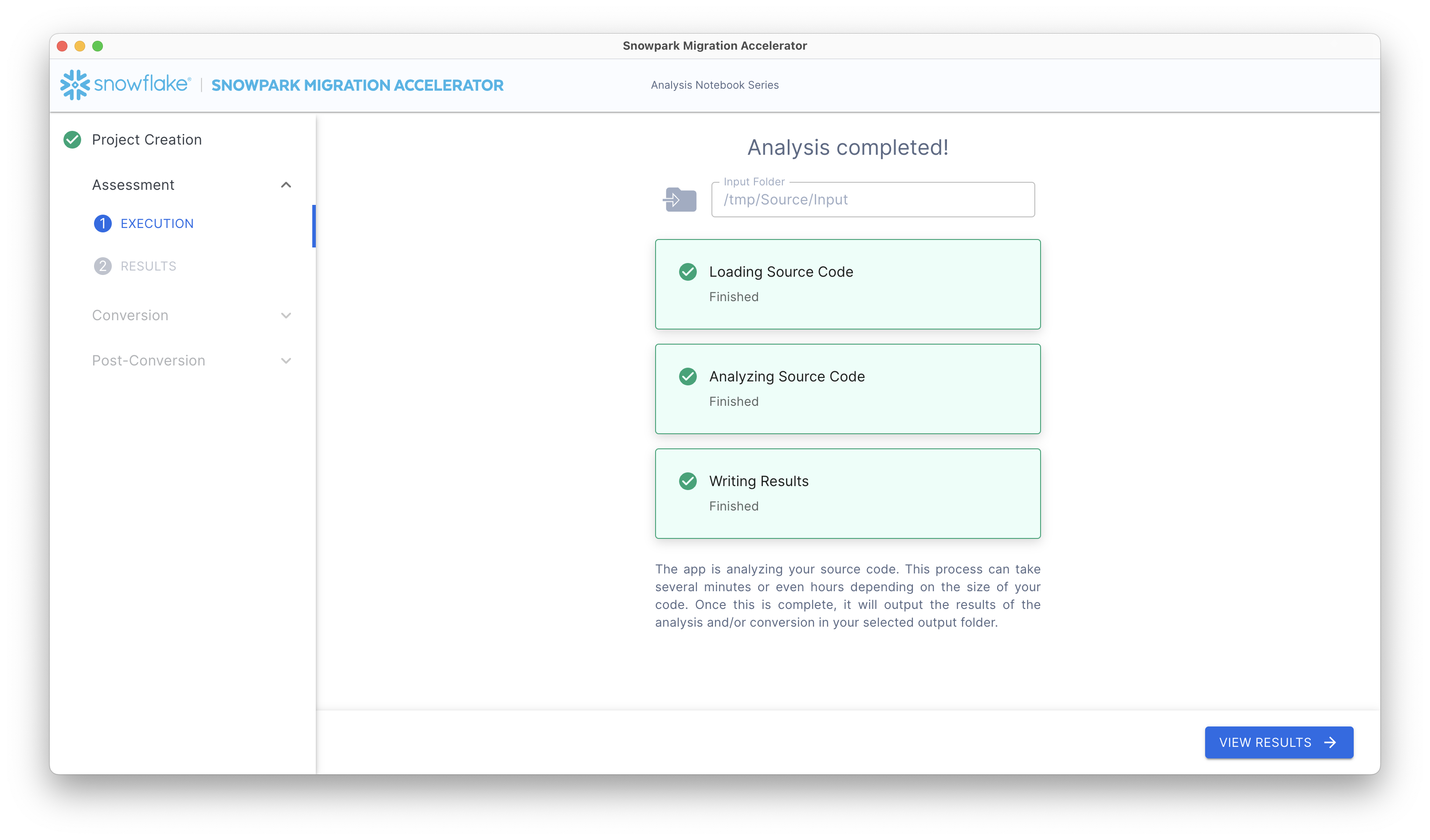
在此过程中,您将在屏幕上看到三个进度指示项:
Loading Source Code
Analyzing Source Code
Writing Results
每当某一步骤完成时,对应的指示灯将亮起。
After the analysis is complete, the SMA automatically shows the Assessment Results page where you can see the analysis output.