Snowpark Migration Accelerator: 再次运行 SMA¶
为演示该工具的局限性,我们将分析一个不太适合的工作负载。我们将在一个可能不是理想迁移候选的代码库上运行该工具。
在第二个代码库上运行工具¶
您可以使用以下任一一个方法重新运行该工具:
关闭并重新打开 Snowpark Migration Accelerator (SMA)。您可以打开之前创建的项目,也可以创建一个新项目。
点击应用程序窗口底部的“RETRY ASSESSMENT”按钮,如下图所示。
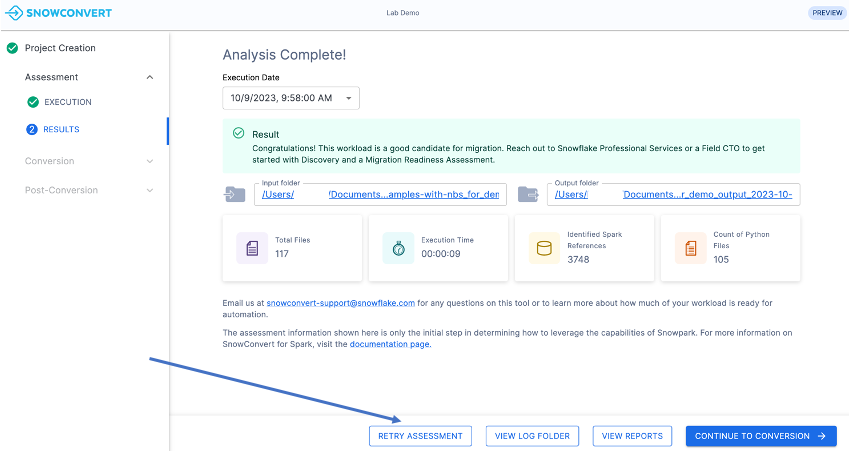
在本次实验中,选择第一个方法。退出 SMA 应用程序,并重复之前“运行工具”部分中的步骤。这次,在选择输入文件夹时,选择包含“needs_more_analysis”代码库的目录。
重复相同的步骤后,您将返回到“Analysis Complete”页面。这一次,您将在结果面板中看到一条不同的消息。
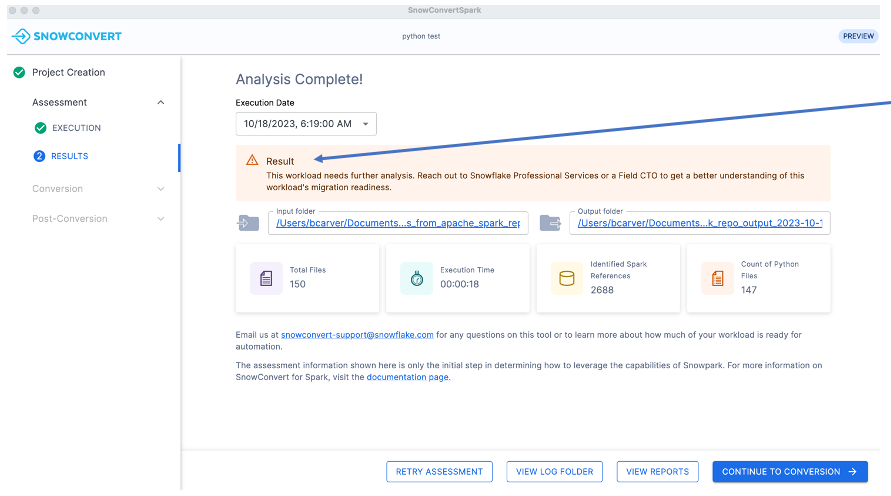
就绪度分数较低(低于 60%)时不会自动取消工作负载的迁移资格。需进行进一步的分析才能做出恰当的评估。这与我们之前的示例类似,在做出最终决定前,还需评估其他几个因素。
注意事项¶
在查看“needs more analysis”结果时,请记住我们在先前评估成功迁移时关注的三个关键因素:就绪度分数、代码库大小和第三方导入。对于需要进一步分析的案例,我们将研究一下这几个因素。
可能无法分析的代码:¶
如果您看到大量解析错误(工具无法理解输入代码),则您的就绪度分数可能会较低。尽管这可能意味着代码包含不熟悉的模式,但更有可能的是导出的代码存在问题或代码在原平台中就是无效的。
该工具会以多种方式显示精度信息。最简单的方法是在报告首页的摘要部分中查看误差幅度。
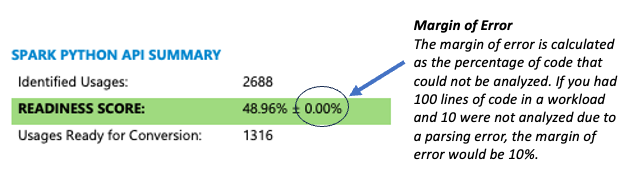
如果解析错误的百分比很高(高于 5%),请执行以下步骤:
确认源代码能在原平台上正确运行
联系 Snowpark Migration Accelerator 团队,确定解析错误的原因
要检查您的代码中是否存在解析问题,请查看报告末尾的“Snowpark Migration Accelerator Issue Summary”。请特别注意错误代码 SPRKPY1001。如果此错误出现在超过 5% 的文件中,则表示部分代码无法解析。首先,请确认这些有问题的代码能否在原平台运行。如能运行,请联系 Snowpark Migration Accelerator 团队寻求帮助。
不支持的 Spark 库¶
低分表示您的代码库包含 Snowpark 尚不支持的函数。如果您看到许多 Spark ML、MLlib 或流式处理函数实例,请特别注意,因为这些是代码中机器学习和流式处理操作的关键指标。目前,Snowpark 对这些功能的支持有限,这可能会影响您的迁移计划。
大小¶
低迁移分数可能并不总是表示迁移很复杂。要结合您代码库的上下文进行分析。例如,如果您的分数为 20%,但在 100 行代码中只有五行参考,那说明这是一个小型、可管理的项目,可以毫不费力地手动迁移。
如果您的代码库很大(超过 10 万行代码),但只有少量 Spark 参考,那说明部分代码可能不需要迁移。这可能包括您组织创建的自定义库。在这种情况下,需进一步分析来确定哪些代码需要转换。
在此示例中,项目大小是可管理的。该项目包含 150 个文件,其中大多数包含 Spark API 参考,且代码总行数不到 1,000 行。
摘要¶
在此示例中,就绪度分数较低是因为广泛使用了 Spark 的 ml、mllib 和流媒体库,而不是因为第三方库的问题或代码库规模过大造成的。鉴于问题的复杂性,我们建议:
联系 sma-support@snowflake.com 寻求指导
在 Snowflake 社区论坛的 Spark Migration 主题 (https://community.snowflake.com/s/topic/0TO3r000000bskWGAQ/spark-migrations) 下发布问题
这些资源将帮助您更好地了解特定工作负载中所面临的挑战。