Snowpark Migration Accelerator:评估输出 – 报告文件夹¶
A complete set of output files and reports will be generated when you use the Snowpark Migration Accelerator (SMA). To see the full list of generated files and reports, refer to the Output Reports section of this documentation.
The assessment generates .csv files that can be opened with any spreadsheet software. The detailed report provides a summary of these files and serves as a starting point for evaluating the results. While we'll examine some key .csv files to understand the migration requirements, we won't cover all of them. For a complete list of inventory files generated by the Snowpark Migration Accelerator (SMA), refer to the SMA Inventories section of this documentation.
要查看报告,请点击屏幕底部的“VIEW REPORTS”按钮。这会将您的文件资源管理器打开至包含报告的目录中。
让我们来看看我们可以从“详细报告”中收集哪些信息。
备注
The version of the detailed report and other inventories shown on this page may differ from what you see when running SMA. The report shown here reflects the tool version available when this walkthrough was created. If you notice significant differences or issues in your results, contact the SMA team at sma-support@snowflake.com or report an issue in the tool. You can also use the SMA tool to report documentation issues.
详细报告¶
The Detailed Report (.docx) provides a comprehensive summary of the information found in the inventory files. This report is essential for evaluating how well-suited your codebase is for Snowpark migration. While a complete description of the report's contents is available in the detailed documentation, this guide focuses on three key aspects:
需要审查的重要元素
它们对就绪度分数的影响
如何解释结果
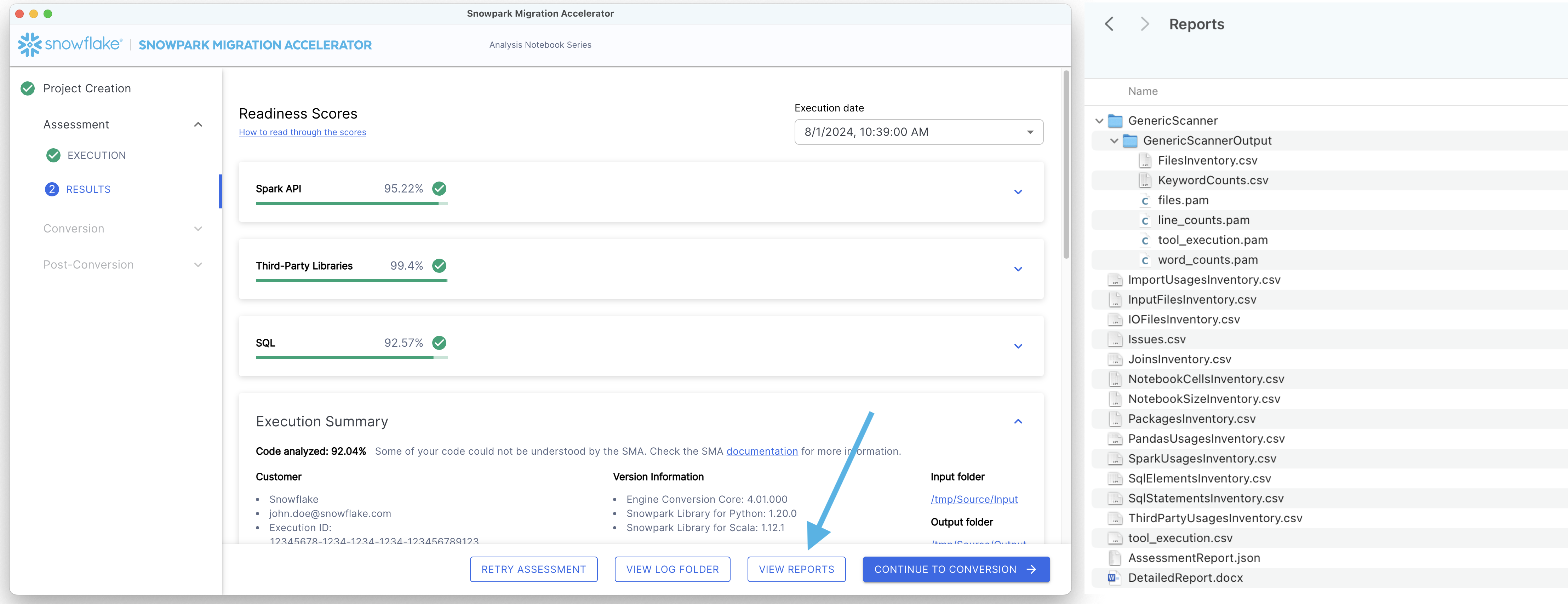
查看报告中提供的所有就绪度分数,以了解您的迁移准备状态。
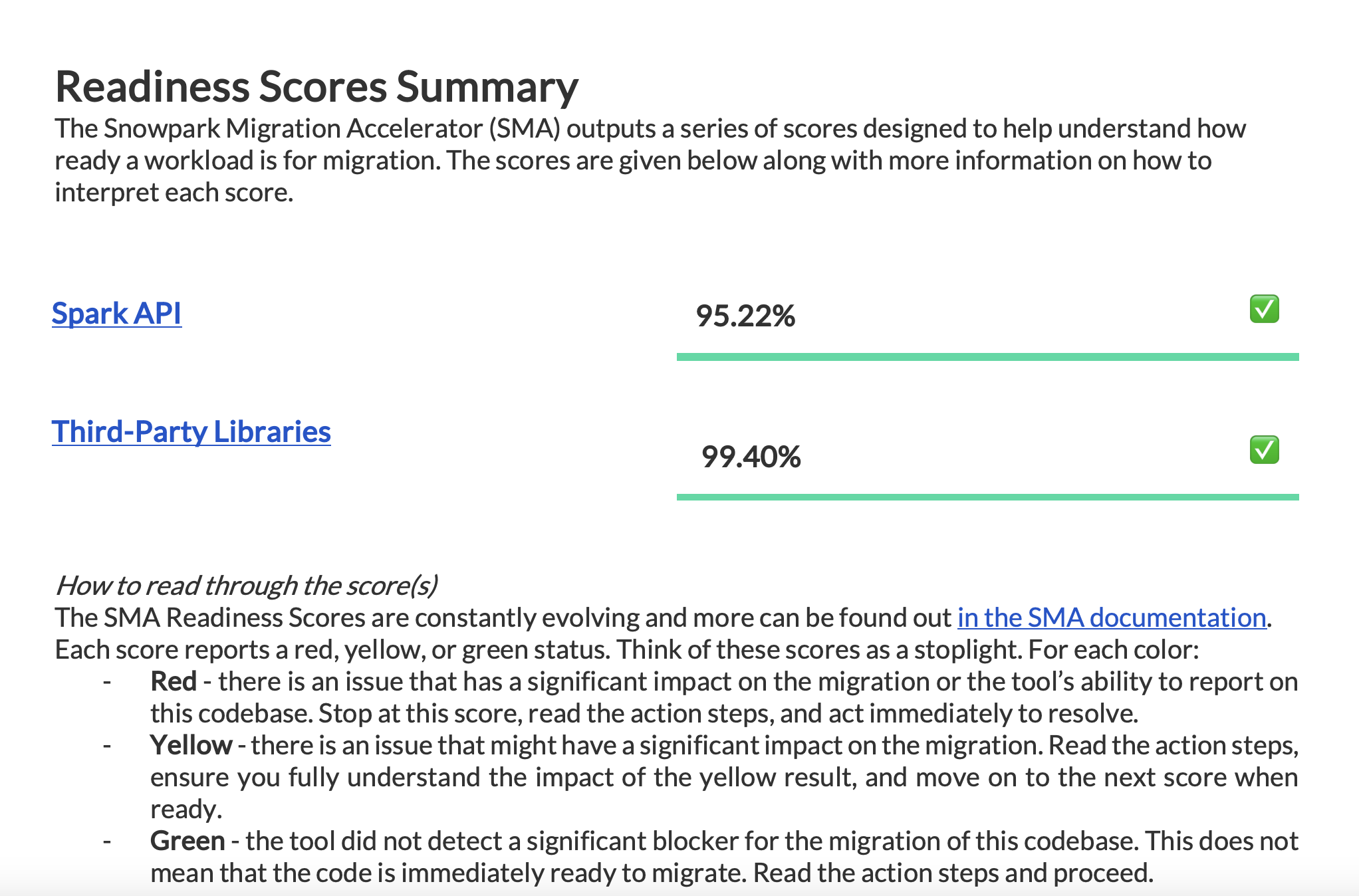
Spark API 就绪度分数¶
Let's clarify what the Spark API Readiness score means and how it's calculated. This score is the main readiness indicator produced by the Snowpark Migration Accelerator (SMA). It's important to note that this score only considers Spark API usage and doesn't account for third-party libraries or other factors in your code. While this limitation means the score might not tell the complete story, it still serves as a useful starting point for your migration assessment. For more information about third-party library compatibility, refer to the Third Party API Readiness section.
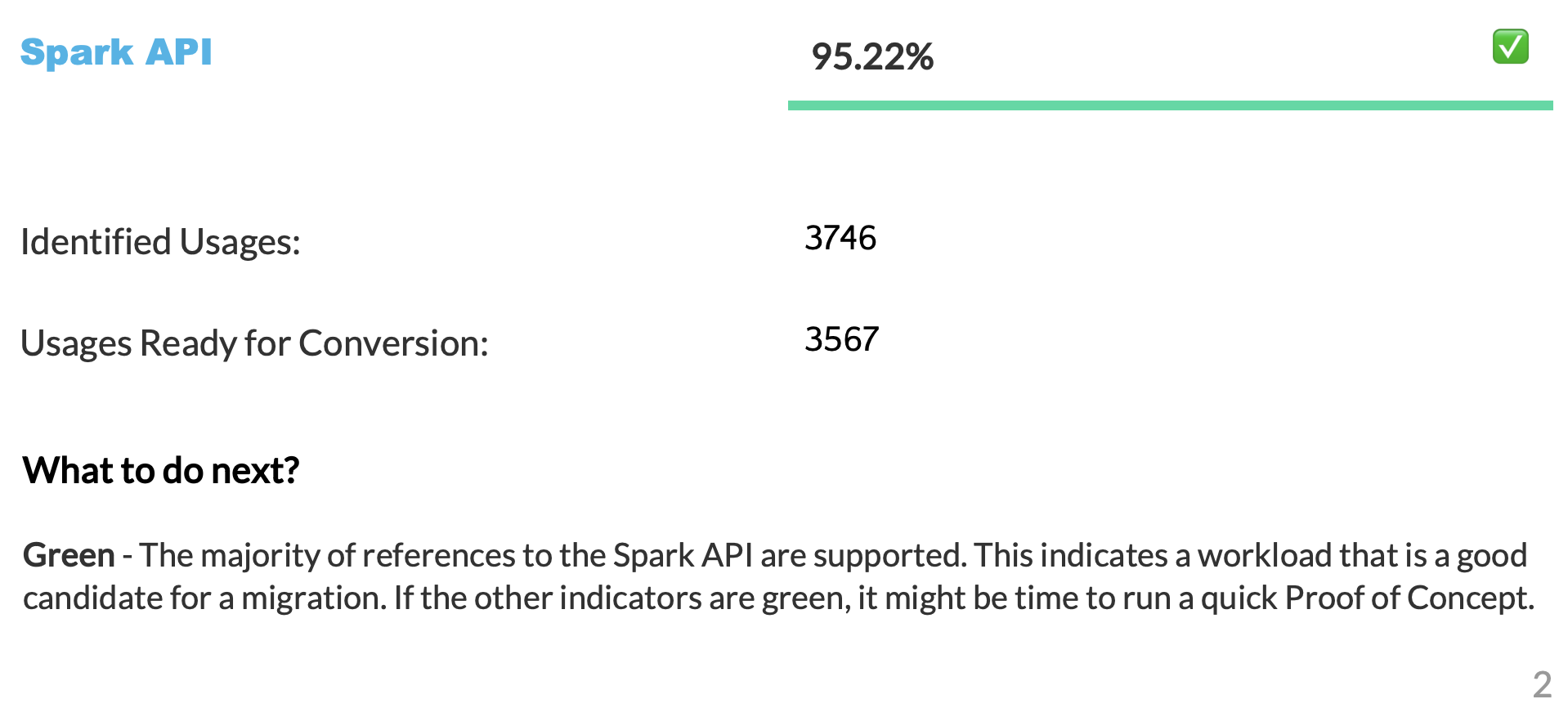
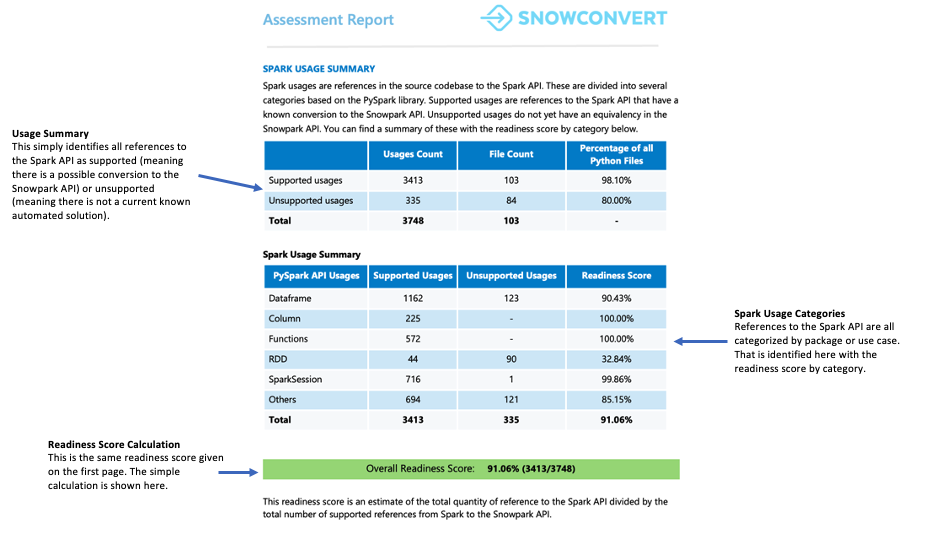
“转换分数”表示可以自动转换为 Snowpark API 的 Spark API 引用与代码中找到的 Spark API 引用总数的比值。在这种情况下,可以转换 3746 个引用中的 3541 个。分数越高表示可以自动迁移到 Snowpark 的代码越多。虽然仍可手动调整未转换的代码,使其与 Snowpark 配合使用,但这一分数能可靠地表明您的工作负载是否适合自动迁移。
第三方库就绪度分数¶
第三方库就绪度分数可帮助您了解代码中使用了哪些外部 APIs。该分数清晰地概述了代码库中的所有外部依赖关系。
“Summary”页面¶
“摘要”页面显示您的就绪度分数,并概述您的执行结果。
需要注意的事项 查看就绪度分数,以评估您的代码库在将 Spark API 引用转换为 Snowpark API 引用方面的准备情况。高就绪度分数表明 Spark 代码非常适合迁移到 Snowpark。
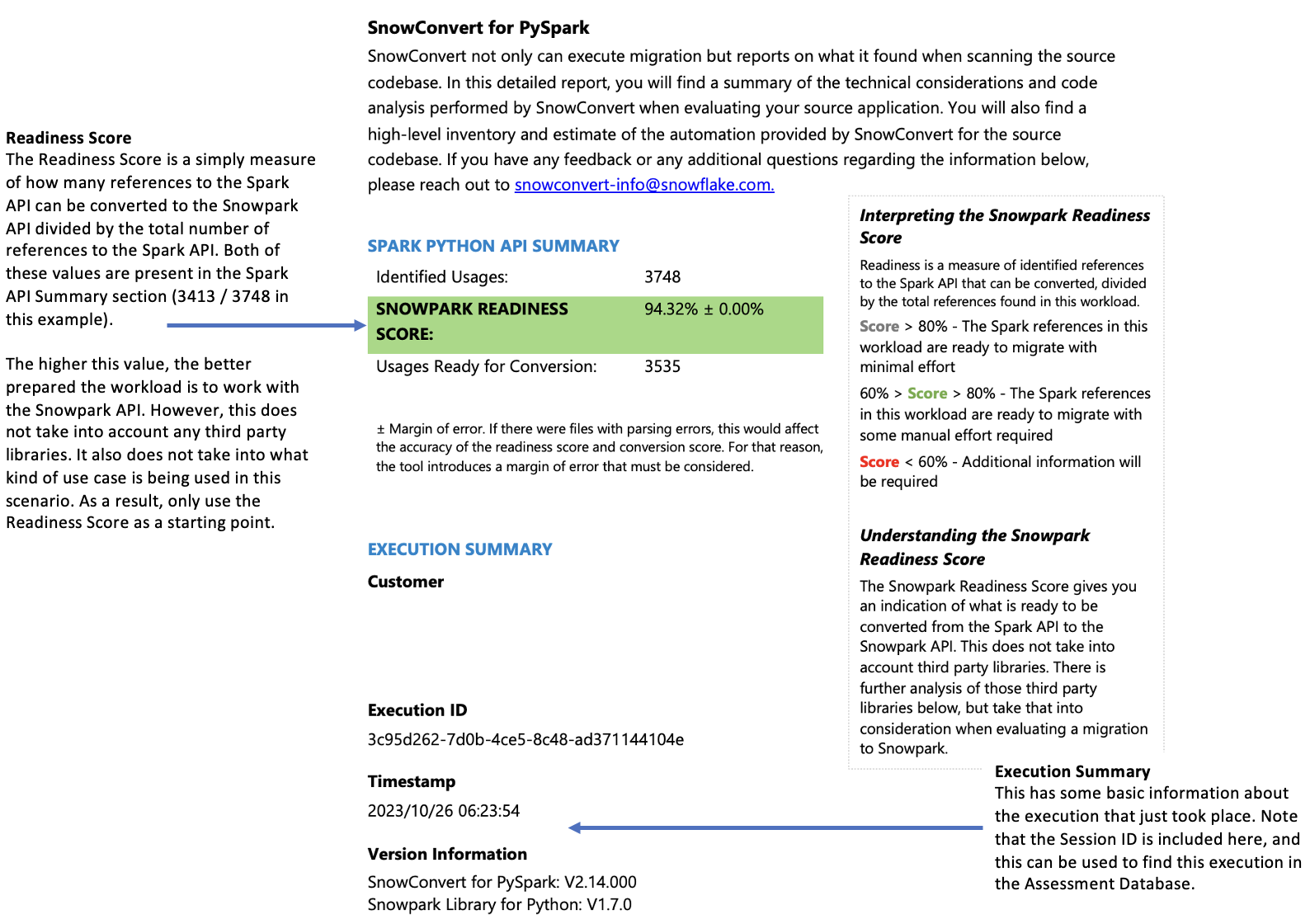
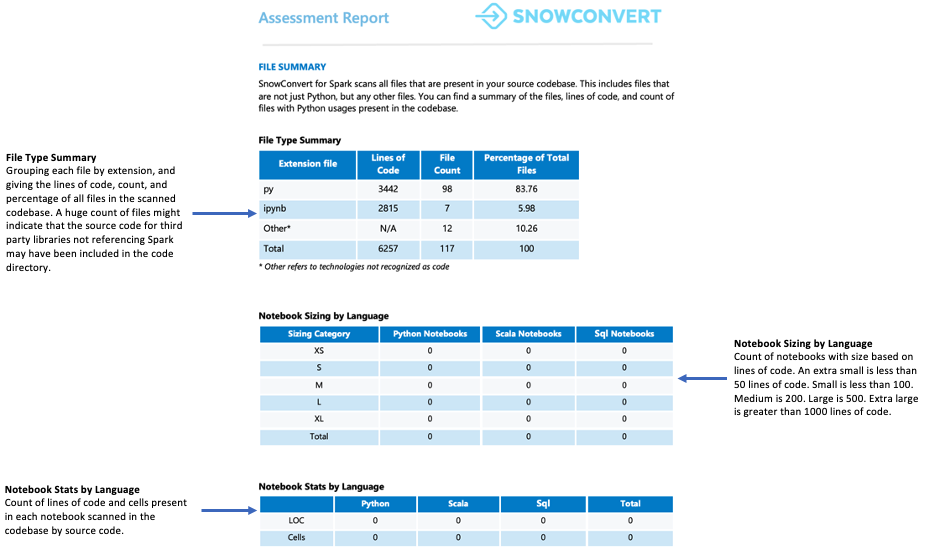
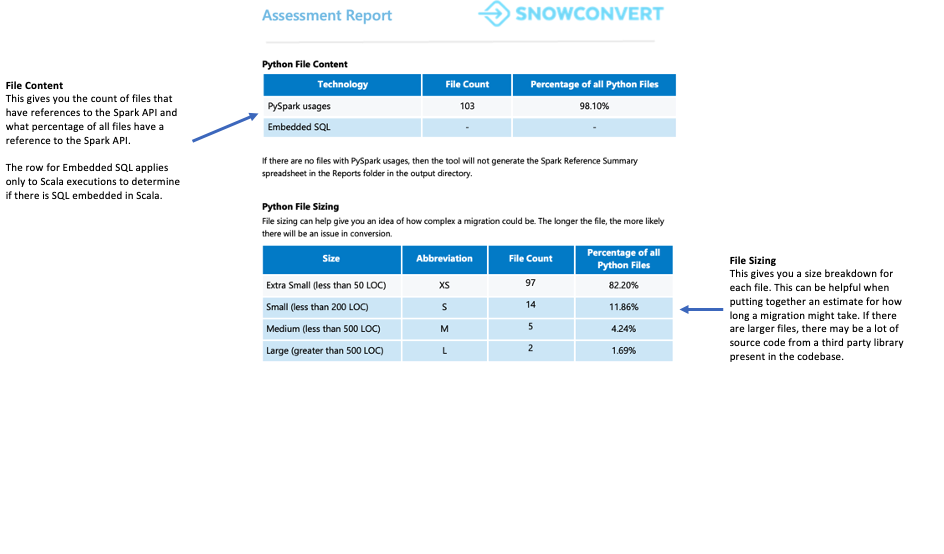
文件摘要¶
文件摘要概述了您的代码库,包括:
每个文件扩展名的代码总行数
笔记本单元格信息(若分析了笔记本)
包含嵌入式 SQL 查询的文件数
您应该注意什么?
文件的数量和内容。当您发现很多文件但只有少数文件包含 Spark API 引用时,这可能意味着:
该应用程序最低限度地使用 Spark(可能仅用于数据提取和加载)
源代码包括外部库依赖关系
该用例需要进一步调查以了解如何使用 Spark
无论哪种情况,在继续操作之前都必须彻底分析用例。
Spark 使用摘要¶
“Spark 使用摘要”详细介绍了您代码中的 Spark API 引用,并确定了哪些引用可以转换为 Snowpark API。摘要将这些引用分为不同的类型,包括 DataFrame 操作、列操作、SparkSession 调用和其他 API 函数。
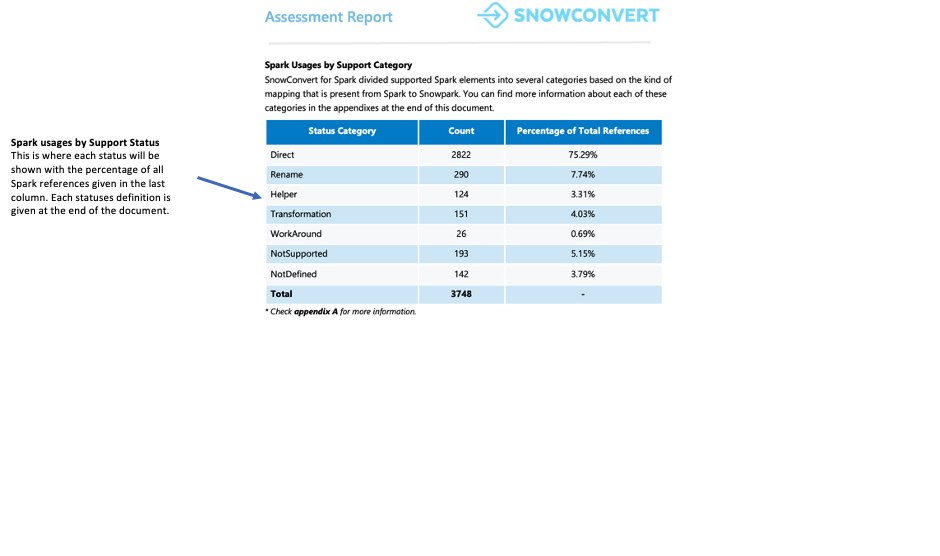
每种引用都分为七种支持状态之一。这些状态指示 Snowpark 中是否以及如何支持引用。这些状态的详细定义可见报告附录。
Direct:该函数同时存在于 PySpark 和 Snowpark 中,无需更改即可使用。
Rename:该函数存在于两个框架中,但需要在 Snowpark 中更改名称。
Helper:该函数需要在 Snowpark 中进行少量修改,可以通过创建等效辅助函数来解决。
Transformation:需要使用不同方法或多个步骤在 Snowpark 中完全重建该函数才能获得相同的结果。
Workaround:该函数无法自动转换,但有文档记录在案的手动解决方案可用。
NotSupported:该函数无法转换,因为 Snowflake 无等效功能。该工具将在代码中添加错误消息。
NotDefined:PySpark 元素尚未包含在转换工具的数据库中,将在未来的更新中添加。
您应该注意什么?
就绪度分数显示在本节中。您可以查看有多少代码引用需要替代方案,有多少需要直接翻译。如果您的代码需要许多替代方案、帮助辅助和转换,我们建议使用 Snowpark Migration Accelerator (SMA) 来帮助高效迁移代码库。
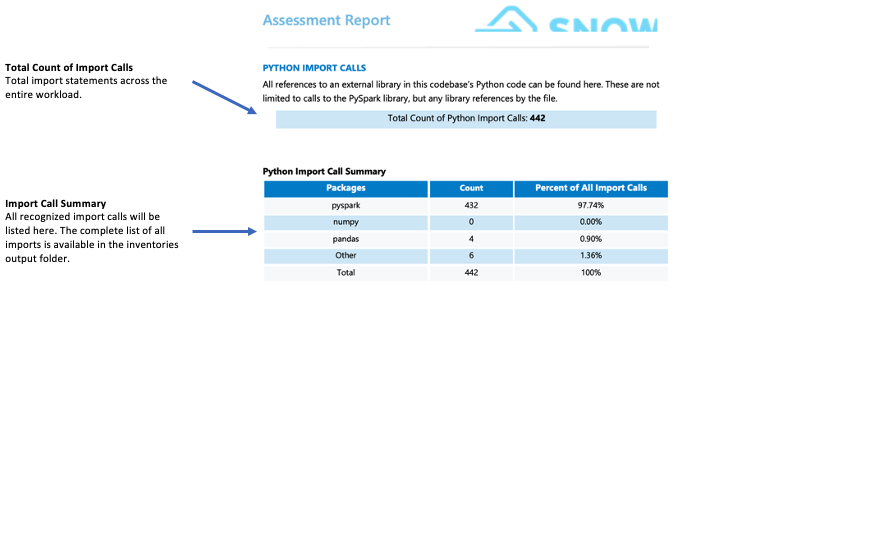
导入调用:¶
SMA tracks each package or library import as an individual import call. Common and recognized import calls are displayed in the import summary section of the detailed report page. All import calls are recorded in both the local output inventories folder and the assessment database. Note that these import calls have not yet been classified as supported or unsupported in Snowflake.
您应该注意什么?
Snowflake 不支持的第三方库可能会显著影响您的迁移就绪情况。如果您的代码导入 mllib、streaming 等库或图表、子流程或 smtplib 等第三方库,则可能会面临迁移挑战。虽然这些库的存在不会自动导致迁移不可行,但它需要对您的用例进行更深入的分析。在这种情况下,我们建议咨询 WLS 团队进行详细评估。
Snowpark Migration Accelerator 问题摘要¶
本节概述了工作负载迁移期间可能出现的潜在问题和错误。虽然其他地方也提供了有关不可转换元素的详细信息,但在转换过程的初始阶段,本节内容尤为重要。
需要注意的常见问题
要查找未转换或已知替代方案的元素,请查看本地清单文件夹中的 Spark 引用清单。您可以通过查询数据库将这些元素与现有映射进行比较。

摘要:¶
就绪度分数表明您的代码库为 Snowpark 迁移做准备的程度。分数高于 80% 表示您的代码已准备就绪,可以进行迁移。如果您的分数低于 60%,则在继续操作之前,您需要对代码进行额外修改。
对于该工作负载,分数超过 90%,这表明迁移兼容性极佳。
下一个指标是 大小。有大量代码但很少引用 Spark API 的工作负载可能表明对第三方库的严重依赖。即使项目的就绪度分数较低,如果项目仅包含大约 100 行代码或 5 个 Spark API 引用,无论使用什么自动化工具,都可以快速手动转换。
对于这种工作负载,大小合理且易于处理。该代码库包含 100 多个文件,其中 Spark API 引用少于 5,000 行,代码行数低于 10,000 行。这些文件中约有 98% 包含 Spark API 引用,这表明大多数 Python 代码都与 Spark 相关。
要检查的第三个指标是 导入库。导入语句清单有助于确定代码使用了哪些外部包。如果代码严重依赖第三方库,则可能需要额外分析。如果存在大量外部依赖关系,请咨询工作负载服务 (WLS) 团队,以更好地了解如何使用这些库。
在此示例中,我们引用了一些第三方库,但它们都与机器学习、流式处理或其他在 Snowpark 中难以实现的复杂库无关。
由于此工作负载适合迁移到 Snowpark,因此请继续执行 Spark 迁移过程的下一步。