向量嵌入
嵌入 是指将高维数据(如非结构化文本)简化为维数较少的表示形式(如向量)。现代深度学习技术可以从文本和图像等非结构化数据创建向量嵌入(即结构化的数字表示形式),同时在这些数据产生的向量几何中保留相似性和相异性的语义概念。
下图是自然语言文本的向量嵌入和几何相似性的简化示例。在实践中,神经网络产生的嵌入向量具有数百甚至数千个维度,而不是这里所示的两个维度,但概念是相同的。语义相似的文本产生“指向”相同的大致方向的向量。
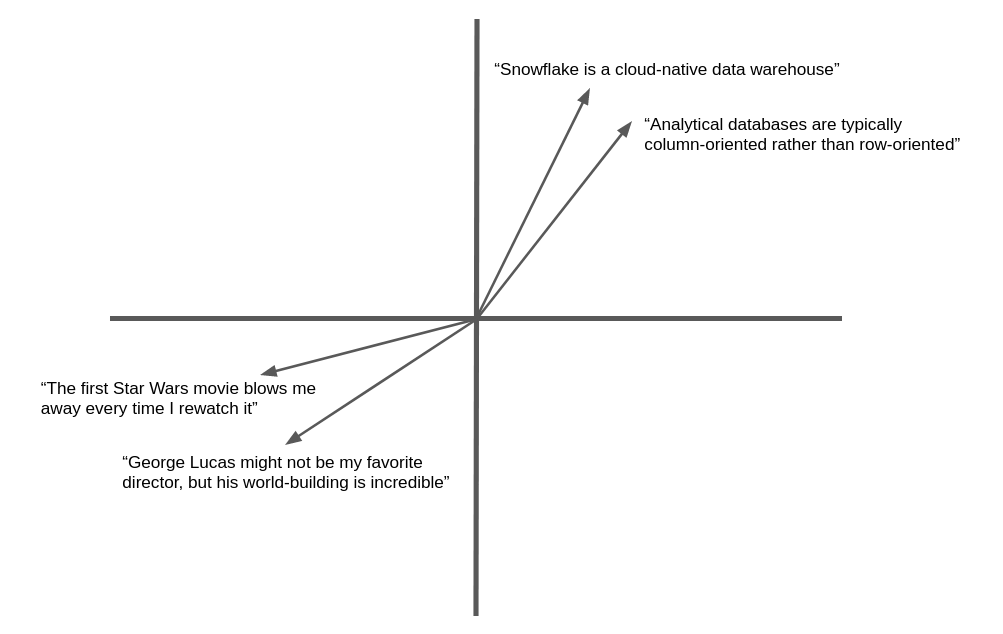
许多应用场景可以从查找与目标相似的文本或图像的功能中受益。例如,当新的支持工单记录到服务台时,支持团队可以从查找已解决的类似工单的功能中受益。在此应用场景中使用嵌入向量的好处是,它超越了关键字匹配而进化到语义相似性,因此,即使相关记录未确切包含相同的单词,也能找到这些记录。
Snowflake Cortex offers the EMBED_TEXT_768 and EMBED_TEXT_1024 functions and several Vector functions to compare them for various applications.
文本嵌入模型
Snowflake offers the following text embedding models. See below for more details.
| Model name | Output dimensions | Context window | Language support |
|---|---|---|---|
| snowflake-arctic-embed-m-v1.5 | 768 | 512 | English-only |
| snowflake-arctic-embed-m | 768 | 512 | English-only |
| snowflake-arctic-embed-l-v2.0 | 1024 | 512 | Multilingual |
Supported models might have different costs.
关于向量相似性函数
The measurement of similarity between vectors is a fundamental operation in semantic comparison. Snowflake Cortex provides four vector similarity functions: VECTOR_INNER_PRODUCT, VECTOR_L1_distance, VECTOR_L2_DISTANCE, and VECTOR_COSINE_SIMILARITY. To learn more about these functions, see Vector functions.
有关语法和用法的详细信息,请参阅每个函数的参考页面:
示例
以下示例使用向量相似性函数。
This SQL example uses the VECTOR_INNER_PRODUCT function to determine which vectors in the table
are closest to each other between columns a and b:
This SQL example calls the VECTOR_COSINE_SIMILARITY function to find the vector closes to [1,2,3]:
Snowflake Python Connector¶
这些示例展示了如何将 VECTOR 数据类型和向量相似性函数与 Python Connector 一起使用。
Note
Snowflake Python Connector 版本 3.6 中引入了对 VECTOR 类型的支持。
Snowpark Python¶
这些示例展示了如何将 VECTOR 数据类型和向量相似性函数与 Snowpark Python 库一起使用。
Note
- Snowpark Python 版本 1.11 中引入了对 VECTOR 类型的支持。
- The Snowpark Python library does not support the VECTOR_COSINE_SIMILARITY function.
从文本创建向量嵌入
To create a vector embedding from a piece of text, you can use the EMBED_TEXT_768 (SNOWFLAKE.CORTEX) or EMBED_TEXT_1024 (SNOWFLAKE.CORTEX) functions, depending on the output dimensions of the model. This function returns the vector embedding for a given English-language text. This vector can be used with the vector comparison functions to determine the semantic similarity of two documents.
Tip
You can use other embedding models through Snowpark Container Services. For more information, see Embed Text Container Service (https://github.com/Snowflake-Labs/sfguide-text-embedding-snowpark-container-service).
Important
EMBED_TEXT_768 and EMBED_TEXT_1024 are Cortex LLM Functions, so their usage is governed by the same access controls as the other Cortex LLM Functions. For instructions on accessing these functions, see the Cortex LLM Functions Required Privileges.
用例示例
本部分介绍如何使用嵌入、向量相似性函数和 VECTOR 数据类型来实现常见用例,如向量相似性搜索和检索增强生成 (RAG)。
向量相似性搜索
要实施对语义相似文档的搜索,首先存储要搜索的文档的嵌入。在添加或编辑文档时保持嵌入是最新的。
In this example, the documents are call center issues logged by support representatives. The issue is stored in a column
called issue_text in the table issues. The following SQL creates a new vector column to hold the
embeddings of the issues.
要执行搜索,请创建搜索词或目标文档的嵌入,然后使用向量相似性函数找到具有类似嵌入的文档。使用 ORDER BY 和 LIMIT 子句选择前 k 个匹配的文档,也可以选择使用 WHERE 条件指定最小相似性。
一般来说,对向量相似性函数的调用应出现在 SELECT 子句中,而不是 WHERE 子句中。这样一来,只会对 WHERE 子句指定的行调用该函数,从而可能基于其他一些准则限制查询,而不是对表中的所有行进行操作。要在 WHERE 子句中测试相似性值,请在 SELECT 子句中为 VECTOR_COSINE_SIMILARITY 调用定义列别名,并在 WHERE 子句的条件中使用该别名。
此示例查找过去 90 天内最多五个匹配搜索词的问题,并假设与搜索词的余弦相似度至少为 0.7。
成本注意事项
Snowflake Cortex LLM 函数(包括 EMBED_TEXT_768 和 EMBED_TEXT_1024)根据处理的词元数产生计算成本。
Note
词元是 Snowflake Cortex LLM 函数处理的最小文本单位,大约等于四个字符的文本。原始输入或输出文本与词元的等价性可能因模型而异。
- 对于 EMBED_TEXT_768 和 EMBED_TEXT_1024 函数,仅将输入词元计入可计费总额。
- 向量相似性函数不会产生基于词元的成本。
For more information about billing of Cortex LLM Functions, see Cortex LLM Functions Cost Considerations. For general information about compute costs, see Understanding compute cost.