使用 Query History 监控查询活动¶
要监控账户中的查询活动,您可以使用:
Snowsight 中的 Query History 和 Grouped Query History 页面。
SNOWFLAKE 数据库的 ACCOUNT_USAGE 架构中的 QUERY_HISTORY 视图 和 AGGREGATE_QUERY_HISTORY 视图。
INFORMATION_SCHEMA 中表函数的 QUERY_HISTORY 系列。
借助 Snowsight 中的 Query History 页面,您可以执行以下操作:
监控用户在您的账户中执行的单个查询或分组查询。
查看有关查询的详细信息,包括性能数据。在某些情况下,查询详细信息不可用。
在查询配置文件中浏览已执行查询的每个步骤。
通过 Query History 页面,您可以浏览过去 14 天内 Snowflake 账户中执行的查询。
在工作表中,您可以查看已在该工作表中运行的查询的查询历史记录。请参阅 查看查询历史记录。
在 Snowsight 中查看 Query History¶
要在 Snowsight 中访问 Query History 页面,请执行以下操作:
Sign in to Snowsight.
In the navigation menu, select Monitoring » Query History.
前往 Individual Queries 或 Grouped Queries。有关分组查询的更多信息,请参阅 在 Snowsight 中使用分组查询历史记录视图。
对于 Individual Queries,请 筛选视图 以查看最相关和最准确的结果。
如果列表顶部出现 Load More 按钮,则表示有更多可用结果可加载。您可以通过选择 Load More 或滚动到列表底部来提取下一组结果。
查看 Query History 时所需的权限¶
您可以随时查看已运行的查询的历史记录。
要查看其他查询的历史记录,您的活动角色会影响您可以在 Query History 中看到的其他内容:
如果您的活动角色是 ACCOUNTADMIN 角色,您可以查看账户的所有查询历史记录。
如果您的活动角色获得针对仓库的 MONITOR 或 OPERATE 权限,您可以查看使用该仓库的其他用户运行的查询。
If your active role is granted the GOVERNANCE_VIEWER database role for the SNOWFLAKE database, it is sufficient for querying the ACCOUNT_USAGE views directly with SQL, and it also allows you to view Grouped Queries in the Query History. However, this role alone does not grant the ability to see Individual Queries by other users in Snowsight. To view all user queries (both grouped and individual), your role must be ACCOUNTADMIN or be granted IMPORTED PRIVILEGES on the SNOWFLAKE database. Alternatively, the following two privileges can replace the IMPORTED PRIVILEGES:
如果您的活动角色获得针对 SNOWFLAKE 数据库的 READER_USAGE_VIEWER 数据库角色,您可以查看与账户关联的阅读者账户中所有用户的查询历史记录。请参阅 SNOWFLAKE 数据库角色。
使用 Query History 时的注意事项¶
在查看账户的 Query History 时,请注意以下事项:
由于针对 会话 的数据保留策略,超过 7 天前执行的查询的详细信息不包含 User 信息。您可以使用用户筛选器来检索单个用户运行的查询。请参阅 筛选查询历史记录。
对于因语法或解析错误而失败的查询,您会看到
<redacted>,而不是已执行的 SQL 语句。如果您获得具有适当权限的角色,则可以设置 ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR 参数以查看完整的查询文本。筛选器以及 Started 和 End Time 列使用您当前的时区。您无法更改此设置。为对话设置 TIMEZONE 参数不会更改使用的时区。
筛选查询历史记录¶
您可以按以下方法筛选查询历史记录列表:
查询的状态,例如,用于识别长时间运行的查询、失败的查询和排队的查询。
执行查询的用户,包括:
All,以查看您有权查看其查询历史记录的所有用户。
您登录时使用的用户身份(默认)
您账户中的单个 Snowflake 用户(如果您的角色可以查看其他用户的查询历史记录)。
运行查询的时间段,最多 14 天。
其他筛选器,包括以下内容:
SQL Text,例如,用于查看使用特定语句的查询,例如 GROUP BY。
Query ID,以查看特定查询的详细信息。
Warehouse,以查看使用特定仓库运行的查询。
Statement Type,以查看使用特定类型语句的查询,例如 DELETE、UPDATE、INSERT 或 SELECT。
Duration,例如,用于特别识别长时间运行的查询。
Session ID,以查看在特定 Snowflake 会话期间运行的查询。
Query Tag,以查看带有通过 QUERY_TAG 会话参数设置的特定查询标签的查询。
Parameterized Query Hash,以显示根据筛选器中指定的参数化查询哈希 ID 分组的查询。有关更多信息,请参阅 使用参数化查询的哈希值 (query_parameterized_hash)。
Client generated statements,以查看由客户端、驱动程序或库(包括 Web 界面)运行的内部查询。例如,每当用户在 Snowsight 中导航到 Warehouses 时,Snowflake 都会在后台执行 SHOW WAREHOUSES 语句。启用此筛选器后,该语句将可见。您的账户不会因客户端生成的语句而产生费用。
Queries executed by user tasks,以查看用户任务执行的 SQL 语句或调用的存储过程。
Show replication refresh history,以查看用于对远程区域和账户执行 复制 刷新任务的查询。
如果您想查看近乎实时的结果,请启用 Auto Refresh。启用 Auto Refresh 后,表每十秒刷新一次。
默认情况下,您可以在 Queries 表中查看以下列:
SQL Text,已执行语句的文本(始终显示)。
Query ID,查询的 ID(始终显示)。
Status,已执行语句的状态(始终显示)。
User,以查看执行语句的用户名。
Warehouse,以查看用于执行语句的仓库。
Duration,以查看执行语句所花费的时间长度。
Started,以查看语句开始运行的时间。
如果有更多结果,则无法对表进行排序。如果在对表排序后选择列表顶部的 Load More,新结果将追加到数据末尾,排序顺序将不再适用。
要查看更具体的信息,您可以选择 Columns,在表中添加或删除列,例如:
All,以显示所有列。
User,以显示运行了语句的用户。
Warehouse,以显示用于运行语句的仓库的名称。
Warehouse Size,以显示用于运行语句的仓库的大小。
Duration,以显示语句运行所需的时间。
Started,以显示语句的开始时间。
End Time,以显示语句的结束时间。
Session ID,以显示执行语句的会话的 ID。
Client Driver,以显示用于执行语句的客户端、驱动程序或库的名称和版本。Snowsight 中运行的语句显示
Go 1.1.5。Bytes Scanned,以显示在查询处理过程中扫描的字节数。
Rows,以显示语句返回的行数。
Query Tag,以显示为查询设置的查询标签。
Parameterized Query Hash,以显示根据筛选器中指定的参数化查询哈希 ID 分组的查询。有关更多信息,请参阅 使用参数化查询的哈希值 (query_parameterized_hash)。
Incident,以显示包含事件执行状态的语句的详细信息,用于故障排除或调试目的。
要查看有关查询的其他详细信息,请在表中选择一个查询以打开 Query Details。
在 Snowsight 中使用分组查询历史记录视图¶
您可以在 Snowsight 中使用 Grouped Query History 视图监控关键和频繁运行的查询的使用情况和性能。此图形视图基于 AGGREGATE_QUERY_HISTORY 视图 中记录的信息。执行的查询按 参数化查询哈希 ID 分组。您可以监控一段时间内的关键统计信息,并深入到属于每个组的个别查询。
尽管此视图包括针对 Snowflake 的所有查询,但对于监控和分析在高吞吐量下重复执行少量不同语句的 Unistore 工作负载 而言特别有用。对于涉及 混合表 的工作负载,通过查看个别查询来监控性能具有挑战性。
例如,您的工作负载可能由数千个非常相似的点查找查询和插入组成,这些查询和插入仅因用户 ID 而异,运行速度极快,而且重复的速度使它们无法单独分析。当您要回答类似以下问题时,这些操作的汇总视图是必不可少的:
在我的账户或工作负载中,哪些分组查询(或 参数化查询)消耗的总时间或资源最多?
随着时间的推移,参数化查询的性能是否发生了重大变化?
参数化查询会遇到什么样的问题?锁定?排队?编译时间很长?
参数化查询成功或失败的频率是多少?不到百分之一的时间,还是更长?
如何使用分组查询历史记录¶
要在 Snowsight 中访问 Grouped Query History,请执行以下操作:
Sign in to Snowsight.
In the navigation menu, select Monitoring » Query History » Grouped Queries. The page shows you queries grouped by their common parameterized query hash ID.
备注
个别查询不会立即显示在 Grouped Queries 列表中。根据 AGGREGATE_QUERY_HISTORY 视图中的记录更新列表的延迟可能长达 180 分钟(3 小时),但填充列表的速度通常要快得多。
选择任何分组查询以查看该参数化查询哈希的性能统计信息。Snowsight 显示执行的查询总次数、失败的查询次数、延迟(p50、p90、p99)和每分钟的执行次数。页面底部显示了作为该哈希一部分运行的一些示例个别查询;您可以选择每个查询以查看其特定详细信息。
For example, during the last day, about 540 queries ran in this group, with a total duration of about 3 hours:

In the Parameterized query hash view, you can filter queries by status, such as Failed or
Successful. In both the Grouped Queries view and the Parameterized query hash
view, you can filter by a date range, by user, and by warehouse. The date range is limited to a maximum
of the last 14 days of grouped query history. You can't retrieve information about queries that were
executed more than 14 days ago.
Note that some warehouses are internal warehouses managed by Snowflake, and those warehouses don't appear in the Warehouse filter. Similarly, the SYSTEM user does not appear in the User filter.
As an alternative to using filters, you can run aggregate queries that return filtered results. See also the AGGREGATE_QUERY_HISTORY 视图.
Individual Queries list¶
Alternatively, you can look at Individual Queries. This view doesn't reflect all of the queries run by Unistore workloads, given the sheer volume of queries that can be created against hybrid tables. For more information about this behavior, see the hybrid tables section of the 使用说明. Snowflake recommends that all users with Unistore workloads start by monitoring the Grouped Queries view.
查看分组查询历史记录时所需的权限¶
用户可以随时查看他们已运行的查询的历史记录。用户的活动角色会影响哪些其他查询可见。如果符合以下条件之一,您可以同时查看 Grouped Queries 和 Individual Queries:
您的活动角色是 ACCOUNTADMIN。
您的活动角色已被授予 SNOWFLAKE 数据库的 IMPORTED PRIVILEGES(请参阅 允许其他角色使用 SNOWFLAKE 数据库中的架构)。
您具有 GOVERNANCE_VIEWER 数据库角色。
如果您没有其中任何角色或权限,则只能看到 Individual Queries。有关访问权限的更多信息,请参阅 使用 Query History 监控查询活动。
查看特定查询的详细信息和配置文件¶
当您在 Query History 中选择查询时,您可以查看查询的详细信息和配置文件。
通过 Snowflake Native App 编辑的查询配置文件数据¶
在以下上下文中,Snowflake Native App Framework 编辑 查询配置文件 中的信息:
在安装或升级应用程序时运行的查询。
源自应用程序所拥有的存储过程的查询。
包含应用程序所拥有的非安全视图或函数的查询。
对于以上任何类型的查询,Snowsight 都会将查询配置文件数据合并到单个空节点中,而不是显示完整的查询配置文件树。
查看查询详细信息¶
要查看特定查询的详细信息,并查看成功查询的结果,请打开查询的 Query Details。
您可以查看 Details,了解有关查询执行的信息,包括:
查询的状态。
查询开始时,采用用户的当地时区。
查询结束时,采用用户的当地时区。
用于运行查询的仓库的大小。
查询的持续时间。
查询 ID。
查询的查询标签(如果存在)。
驱动程序状态。有关更多详细信息,请参阅 View the Snowflake client version。
用于提交查询的客户端、驱动程序或库的名称和版本。例如,
Go 1.1.5代表使用 Snowsight 运行的查询。会话 ID。
您可以查看用于运行查询的仓库,以及运行 Query Details 选项卡上面列出的查询的用户。
查看 SQL Text 部分以获取查询的实际文本。您可以将鼠标悬停在 SQL 文本上,以打开工作表中的语句或复制该语句。如果查询失败,您可以查看错误详细信息。
Results 部分显示查询的结果。您只能查看前 10,000 行结果,并且只有运行查询的用户才能查看结果。选择 Export Results,将完整的结果集导出为 CSV 格式的文件。
查看查询配置文件¶
Query Profile 选项卡允许您浏览查询执行计划,并了解有关每个执行步骤的详细内容。
查询配置文件是用于了解查询机制的强大工具。每当您需要了解有关特定查询的性能或行为的更多信息时,都可以使用它。它旨在帮助您发现 SQL 查询表达式中的典型错误,以识别潜在的性能瓶颈和改进机会。
本节简要概述了如何导航和适用查询配置文件。
界面 |
描述 |
|---|---|
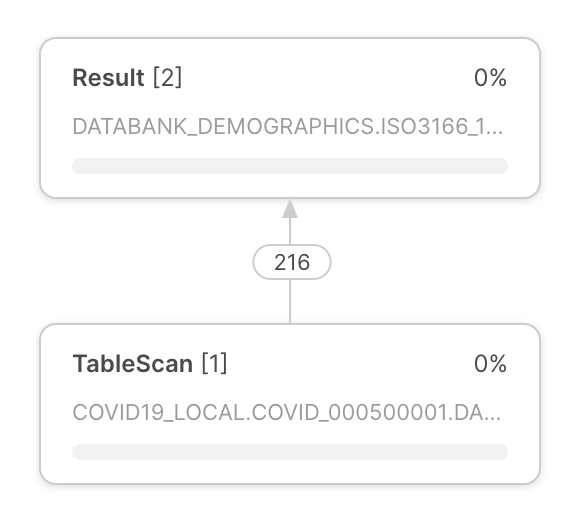
查询执行计划 |
查询执行计划显示在查询配置文件的中心。 查询执行计划由运算符节点组成,运算符节点表示行集运算符。 运算符节点之间的箭头表示从一个运算符输出并输入另一个运算符的行集。 |
运算符节点 |
每个运算符节点包括以下内容:
|

查询配置文件导航 |
在查询配置文件的左上角,使用按钮执行以下操作:
备注 仅当分步执行查询时,才会显示步骤。 |

信息窗格 |
查询配置文件提供各种信息窗格。窗格会显示在查询执行计划中。显示的窗格取决于查询执行计划的重点。 查询配置文件包括以下信息窗格:
要详细了解窗格提供的信息,请参阅 查询配置文件参考。 |
通过 Snowflake Native App 编辑的查询历史记录数据¶
For queries related to a Snowflake Native App, the query_text and error_message fields are redacted
from the query history in the following contexts:
安装或升级应用程序时运行的查询。
源自应用程序拥有的存储过程的子作业的查询。
在每种情况下,Snowsight 中查询历史记录的单元格显示空白。
查询配置文件参考¶
本部分介绍每个信息窗格中可以显示的所有项目。信息窗格的确切内容取决于查询执行计划的上下文。
配置文件概述¶
该窗格提供有关哪些处理任务占用了查询时间的信息。执行时间提供有关查询处理期间“时间花费在何处”的信息。花费的时间可以分为以下几类:
Processing – CPU 在数据处理上花费的时间。
Local Disk IO – 本地磁盘访问阻止处理的时间。
Remote Disk IO – 远程磁盘访问阻止处理的时间。
Network Communication – 处理等待网络数据传输的时间。
Synchronization – 参与进程之间的各种同步活动。
Initialization – 设置查询处理所花费的时间。
Hybrid Table Requests Throttling --- 节流请求 以读写存储在混合表中的数据所花费的时间。
查询见解¶
如果存在影响查询执行性能的条件,此窗格会提供有关这些条件的见解。每项见解都包含一条消息,其中解释了查询性能可能受到的影响,并为后续步骤提供了一般性建议。
有关信息,请参阅 使用查询见解提高性能。
备注
您还可以通过查询 QUERY_INSIGHTS 视图 来访问这些见解。
统计信息¶
详细信息窗格中所提供的信息的主要来源是各种统计信息,这些统计信息分为以下部分:
IO – 有关查询期间执行的输入输出操作的信息:
扫描进度 – 到目前为止为给定表扫描的数据百分比。
扫描的字节数 – 到目前为止扫描的字节数。
从缓存扫描的百分比 – 从本地磁盘缓存扫描的数据所占的百分比。
写入的字节数 – 写入的字节数(例如,加载到表中时)。
写入结果的字节数 – 写入结果对象的字节数。例如,
select * from . . .将生成一组表格格式的结果,表示所选内容中的每个字段。通常,结果对象表示作为查询结果生成的任何内容,写入结果的字节数 表示返回结果的大小。从结果读取的字节数 – 从结果对象读取的字节数。
扫描的外部字节数 – 从外部对象(例如暂存区)读取的字节数。
DML – 数据操作语言 (DML) 查询的统计信息:
插入的行数 – 插入到表(或多个表)中的行数。
更新的行数 – 表中更新的行数。
删除的行数 – 从表中删除的行数。
卸载的行数 – 数据导出期间卸载的行数。
Pruning – 有关表修剪效果的信息:
已扫描的分区 – 目前为止扫描的分区数。
分区总数 – 给定表中的分区总数。
Spilling – 关于在中间结果无法完全放入内存的运算中磁盘使用情况信息:
溢出到本地存储的字节数 – 溢出到本地磁盘的数据量。
溢出到远程存储的字节数 – 溢出到远程磁盘的数据量。
Network – 网络通信:
通过网络发送的字节数 – 通过网络发送的数据量。
External Functions – 有关外部函数调用的信息:
对于 SQL 语句调用的每个外部函数,显示以下统计信息。如果同一 SQL 语句多次调用同一函数,则会汇总统计信息。
总调用次数 – 调用外部函数的次数。(这可能与 SQL 语句文本中的外部函数调用次数不同,原因可能是行被划分为的批次数量、重试次数[如果存在暂时性的网络问题]等)
发送的行数 – 发送到外部函数的行数。
接收的行数 – 从外部函数接收的行数。
发送的字节数(x-区域)– 发送到外部函数的字节数。如果标签包含“(x-区域)”,则数据将会跨区域发送(可能会影响计费)。
接收的字节数(x-区域)– 从外部函数接收的字节数。如果标签包含“(x-区域)”,则数据将会跨区域发送(可能会影响计费)。
由于暂时性错误而重试 – 由于暂时性错误而重试的次数。
每次调用的平均延迟 – Snowflake 发送数据和接收返回数据之间的每次调用花费的平均时间。
HTTP 4xx 错误 – 返回 4xx 状态代码的 HTTP 请求总数。
HTTP 5xx 错误 – 返回 5xx 状态代码的 HTTP 请求总数。
每次成功调用的延迟(平均)– 成功 HTTP 请求的平均延迟。
平均限制延迟开销 – 由限制 (HTTP 429) 产生的减速导致的,每个成功请求的平均开销。
由于限制而重试的批次 – 由于 HTTP 429 错误而重试的批次数。
每次成功调用的延迟 (P50) – 成功 HTTP 请求的第 50 个百分位延迟。在所有成功请求中,有 50% 的请求完成时间少于此时间。
每次成功调用的延迟 (P90) – 成功 HTTP 请求的第 90 个百分位延迟。在所有成功请求中,有 90% 的请求完成时间少于此时间。
每次成功调用的延迟 (P95) – 成功 HTTP 请求的第 95 个百分位延迟。在所有成功请求中,有 95% 的请求完成时间少于此时间。
每次成功调用的延迟 (P99) – 成功 HTTP 请求的第 99 个百分位延迟。在所有成功请求中,有 99% 的请求完成时间少于此时间。
Extension Functions – 有关调用扩展函数的信息:
Java UDF 处理程序加载时间 – Java UDF 处理程序的加载时间长短。
Java UDF 处理程序调用总数 – Java UDF 处理程序的调用次数。
Java UDF 处理程序执行时间上限 – 执行 Java UDF 处理程序的最长时间。
平均 Java UDF 处理程序执行时间 – 执行 Java UDF 处理程序的平均时间。
Java UDTF process() 调用数 – Java UDTF 过程方法 的调用次数。
Java UDTF process() 执行时间 – 执行 Java UDTF 过程的时间长短。
Java UDTF process() 平均执行时间 – 执行 Java UDTF 过程的平均时间。
Java UDTF 的构造函数调用数 – Java UDTF 构造函数 的调用次数。
Java UDTF 的构造函数执行时间 – 执行 Java UDTF 构造函数的时间长短。
Java UDTF 的构造函数平均执行时间 – 执行 Java UDTF 构造函数的平均时间。
Java UDTF endPartition() 调用数 – 调用 Java UDTF endPartition 方法 的次数。
Java UDTF endPartition() 执行时间 – 执行 Java UDTF endPartition 方法的时间长短。
Java UDTF endPartition() 平均执行时间 – 执行 Java UDTF endPartition 方法的平均时间。
Java UDF 依赖项下载时间上限 – 下载 Java UDF 依赖项的最长时间。
JVM 内存使用量上限 – JVM 报告的峰值内存使用量。
Java UDF 内联代码编译时间(以毫秒为单位)– Java UDF 内联代码的编译时间。
Python UDF 处理程序调用总数 – Python UDF 处理程序的调用次数。
Python UDF 处理程序总执行时间 – Python UDF 处理程序的总执行时间。
Python UDF 处理程序平均执行时间 – 执行 Python UDF 处理程序的平均时间。
Python 沙盒内存使用量上限 – Python 沙盒环境的内存使用量峰值。
Python 环境创建平均时间:下载和安装包 – 创建 Python 环境的平均时间,包括下载和安装包。
Conda 求解器时间 – 运行 Conda 求解器对 Python 包求解的时间长短。
Conda 环境创建时间 – 创建 Python 环境的时间长短。
Python UDF 初始化时间 – 初始化 Python UDF 的时间长短。
为 UDFs 读取的外部文件字节数 – 为 UDFs 读取的外部文件字节数。
为 UDFs 访问的外部文件数 – 为 UDFs 访问的外部文件数。
如果字段的值(例如“由于暂时性错误而重试”)为零,则不会显示该字段。
最昂贵的节点¶
该窗格列出了持续时间占查询执行总计时间的 1% 或更长时间的所有节点(如果查询是在多个处理步骤中执行的,则为所显示查询步骤的执行时间)。该窗格按执行时间降序列出节点,使用户能够根据执行时间快速找到成本最高的运算符节点。
属性¶
以下各部分提供了最常见的运算符类型及其属性的列表:
数据访问和运算符生成¶
- TableScan:
表示对单个表的访问。属性:
完整的表名称 – 已扫描表的完全限定名称
表别名 – 使用的表别名(如果存在)
列 – 已扫描列的列表
提取的变体路径 – 从 VARIANT 列中提取的路径列表
扫描模式 - ROW_BASED 或 COLUMN_BASED(仅对 混合表扫描 显示)
访问谓词 - 表扫描期间应用的查询条件
- IndexScan:
表示对混合表上 二级索引 的访问。属性:
完整的表名称 - 包含索引的已扫描表的完全限定名称
列 – 已扫描索引列的列表
扫描模式 - ROW_BASED 或 COLUMN_BASED
访问谓词 - 索引扫描期间应用的查询条件
完整的索引名称 - 已扫描索引的完全限定名称
- ValuesClause:
随 VALUES 子句提供的值列表。属性:
值数 – 生成值数。
值 – 生成值列表。
- 生成器:
使用
TABLE(GENERATOR(...))结构生成记录。属性:rowCount – 所提供的 rowCount 参数。
timeLimit – 所提供的 timeLimit 参数。
- ExternalScan:
表示对存储在暂存区对象中的数据的访问。可以是直接从暂存区扫描数据的查询的一部分,也可以是数据加载操作(即 COPY 语句)的一部分。
属性:
暂存区名称 – 读取数据来源暂存区的名称。
暂存区类型 – 暂存区的类型(例如 TABLE STAGE)。
- InternalObject:
表示对内部数据对象(例如 Information Schema 表或上一个查询的结果)的访问。属性:
对象名称 – 访问对象的名称或类型。
数据处理运算符¶
- 筛选器:
表示筛选记录的操作。属性:
筛选条件 – 用于执行筛选的条件。
- 联接:
在给定条件下组合两个输入。属性:
连接类型 – 联接类型(例如 INNER、LEFT OUTER 等)。
相等连接条件 – 对于使用相同基础条件的联接,此条件列出了用于联接元素的表达式。
附加联接条件 – 某些联接使用包含基于非相同的谓词的条件。这些联接列在此处。
备注
非相同的联接谓词可能会导致处理速度明显变慢,应尽可能避免使用。
- 汇总:
对输入进行分组并计算聚合函数。可以表示 SQL 结构,例如 GROUP BY 和 SELECT DISTINCT 等。属性:
分组键 – 如果使用 GROUP BY,则列出分组所依据的表达式。
聚合函数 – 每个汇总组已计算的函数列表,例如 SUM。
- GroupingSets:
表示 GROUPING SETS、ROLLUP 和 CUBE 等结构。属性:
分组密钥集 – 分组集列表
聚合函数 – 每个组已计算的函数列表,例如 SUM。
- WindowFunction:
计算窗口函数。属性:
窗口函数 – 已计算窗口函数的列表。
- 排序:
对给定表达式的输入进行排序。属性:
排序键 – 定义排序顺序的表达式。
- SortWithLimit:
排序后生成输入序列的一部分,通常是 SQL 中的
ORDER BY ... LIMIT ... OFFSET ...构造的结果。属性:
排序键 – 定义排序顺序的表达式。
行数 – 生成的行数。
偏移 – 生成的元组在已排列序列中的发出位置。
- 展平:
处理 VARIANT 记录,可能在指定路径上展平记录。属性:
输入 – 用于展平数据的输入表达式。
- JoinFilter:
特殊筛选操作,用于移除识别为可能不符合查询计划中进一步联接条件的元组。属性:
原始联接 ID – 用于标识可筛选掉的元组的联接。
- UnionAll:
连接两个输入。属性:无。
- ExternalFunction:
表示外部函数执行的处理。
DML 运算符¶
- 插入:
通过 INSERT 或 COPY 操作将记录添加到表中。属性:
输入表达式 – 插入了哪些表达式。
表名称 – 记录添加到的表的名称。
- 删除:
从表中移除记录。属性:
表名称 – 从中删除记录的表的名称。
- 更新:
更新表中的记录。属性:
表名称 – 更新的表的名称。
- 合并:
对表执行 MERGE 操作。属性:
完整的表名称 – 更新的表的名称。
- 卸载:
表示将数据从表导出到暂存区中的文件的 COPY 操作。属性:
位置 – 保存数据的暂存区的名称。
元数据运算符¶
某些查询包含的步骤是纯元数据/目录操作,而不是数据处理操作。这些步骤由单个运算符组成。一些例子包括:
- DDL 和事务命令:
用于创建或修改对象、会话、事务等。通常,这些查询不由虚拟仓库处理,并且最终会生成与匹配 SQL 语句对应的单步配置文件。例如:
CREATE DATABASE | SCHEMA | ...
ALTER DATABASE | SCHEMA | TABLE | SESSION | ...
DROP DATABASE | SCHEMA | TABLE | ...
COMMIT
- 表创建命令:
用于创建表的 DDL 命令。例如:
CREATE TABLE
与其他 DDL 命令类似,这些查询会生成单步配置文件;但是,它们也可以是多步骤配置文件的一部分,例如在 CTAS 语句中使用时。例如:
CREATE TABLE ...AS SELECT ...
- 查询结果重用:
重用上一个查询结果的查询。
- 基于元数据的结果:
纯粹根据元数据计算结果,不访问任何数据的查询。这些查询不由虚拟仓库处理。例如:
SELECT COUNT(*) FROM ...
SELECT CURRENT_DATABASE()
其他运算符¶
- 结果:
返回查询结果。属性:
表达式列表 – 生成的表达式。
查询配置文件识别的常见查询问题¶
本部分描述一些可以使用查询配置文件识别和解决的问题。
“爆炸”联接¶
SQL 用户常犯的错误之一是在不提供联接条件的情况下联接表(导致“笛卡尔积”),或者提供一个表中的记录与另一个表中的多个记录匹配的条件。对于此类查询,Join 运算符生成的元组明显多于消耗的元组数量(通常为数量级)。
这可以通过查看 Join 运算符生成的记录数量来观察,Join 运算符消耗大量时间通常也会反映这一点。
UNION(无 ALL)¶
在 SQL 中,可以将两组数据与 UNION 或 UNION ALL 结构组合在一起。它们之间的区别在于,UNION ALL 只是简单地连接输入,而 UNION 在执行同样操作的同时,也会消除重复数据。
一个常见的错误是在 UNION ALL 的语义足够时使用 UNION。这些查询在查询配置文件中显示为 UnionAll 运算符,顶部附带一个额外的 Aggregate 运算符(用来消除重复数据)。
查询太大而无法放入内存¶
对于某些操作(例如,对大型数据集进行重复数据消除),用于执行操作的服务器的可用内存量可能不足以保存中间结果。因此,查询处理引擎会开始将数据 溢出 到本地磁盘。如果本地磁盘空间不足,则溢出的数据将保存到远程磁盘。
这种溢出可能会对查询性能产生深远影响(尤其是在因为溢出而使用远程磁盘时)。为了缓解这种情况,我们建议:
使用更大的仓库(有效地增加操作的可用内存/本地磁盘空间),以及/或者
以较小的批次处理数据。
修剪效率低下¶
Snowflake 会收集有关数据的丰富统计信息,从而根据查询筛选器避免读取表中不必要的部分。但是,要使此设置生效,需要将数据存储顺序与查询筛选器属性相关联。
通过比较 TableScan 运算符中的 扫描分区 和 分区总数 统计信息,可以观察到修剪的效率。如果前者只是后者的一小部分,说明修剪是有效的。如果情况不是这样,则表明修剪没有效果。
当然,修剪只能对实际筛选掉大量数据的查询有所帮助。如果修剪统计信息未显示数据减少,但 TableScan 上面有一个 Filter 运算符可以筛选掉许多记录,则这可能表明其他数据组织对此查询有益。
有关修剪的更多信息,请参阅 了解 Snowflake 表结构。