识别与模式匹配的行序列¶
简介¶
在某些情况下,您可能需要识别与模式匹配的表行序列。例如,您可能需要执行以下操作:
确定在打开支持票据或进行购买之前,哪些用户遵循了您的网站上的特定页面和操作序列。
查找价格在一段时间内出现 V 形或 W 形恢复的股票。
在传感器数据中,查找可能指明即将发生系统故障的模式。
要识别与特定模式匹配的行序列,请使用 FROM 子句的 MATCH_RECOGNIZE 分子句。
备注
您不能在 递归 通用表表达式 (CTE) 中使用 MATCH_RECOGNIZE 子句。
用于识别行序列的简单示例¶
例如,假设一个表包含有关股票价格的数据。每行包含每个股票代码在特定日期的收盘价。此表包含以下列:
列名称 |
描述 |
|---|---|
|
收盘价的日期。 |
|
当日的收盘价。 |
假设您要检测一种模式,其中股价先跌后涨,在股价图中形成“V”形。
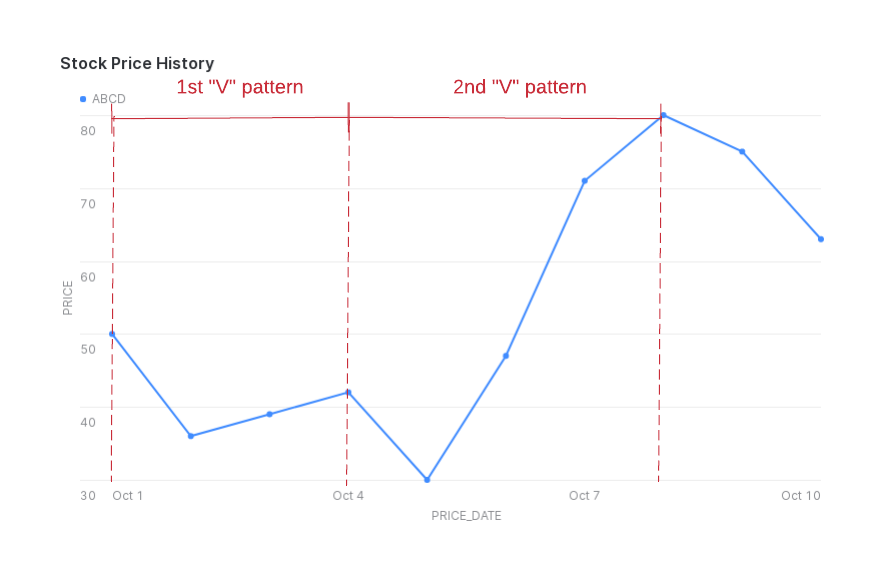
(此示例未考虑股票价格没有每天都变的情况。)
在此示例中,对于给定的股票代码,您希望查找 price 列中的值先减后增的行序列。
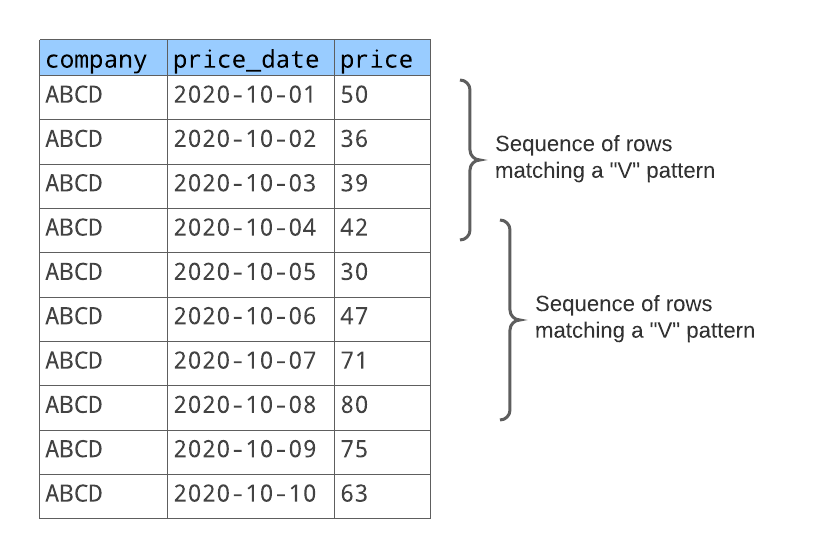
对于匹配此模式的每个行序列,您希望返回以下内容:
用于标识序列(第一个匹配序列、第二个匹配序列等)的数字。
股价下跌前的日期。
股价上涨的最后一天。
处于“V”模式中的天数。
股价下跌的天数。
股价上涨的天数。
下图说明了返回数据获取的“V”模式内的价格下跌 (NUM_DECREASES) 和上涨 (NUM_INCREASES)。请注意,ROWS_IN_SEQUENCE 包含未计入 NUM_DECREASES 或 NUM_INCREASES 的初始行。
要生成此输出,可以使用如下所示的 MATCH_RECOGNIZE 子句。
如上所示, MATCH_RECOGNIZE 子句由许多分子句组成,每个分子句都有不同的用途(例如,指定要匹配的模式、指定要返回的数据等)。
接下来的部分将介绍此示例中的每个分子句。
为此示例设置数据¶
要设置此示例中使用的数据,请运行以下 SQL 语句:
第 1 步:指定行的顺序和分组¶
在识别行序列时,第一步是定义要搜索的行的分组和排序顺序。对于在公司股价中寻找“V”模式的示例:
这些行应按公司分组,因为您希望在给定公司的价格中找到一种模式。
在每组行(给定公司的价格)中,行应按日期升序排序。
在 MATCH_RECOGNIZE 子句中,使用 PARTITION BY 和 ORDER BY 分子句指定行的分组和顺序。例如:
第 2 步:定义要匹配的模式¶
接下来,确定与要查找的行序列匹配的模式。
要指定此模式,您使用类似于 正则表达式 (link removed) 的内容。在正则表达式中,组合使用字面量和元字符来指定要在字符串中匹配的模式。
例如,要查找包含以下内容的字符序列:
任意单个字符,后跟
一个或多个大写字母,后跟
一个或多个小写字母
您可以使用以下与 Perl 兼容的正则表达式:
其中:
.匹配任意单个字符。[A-Z]+匹配一个或多个大写字母。[a-z]+匹配一个或多个小写字母。
+ 是一个 量词 (link removed),指定一个或多个前面的字符需要匹配。
例如,上面的正则表达式匹配类似如下的字符序列:
1Stock@SFComputing%Fn
在 MATCH_RECOGNIZE 子句中,使用类似的表达式来指定要匹配的行模式。在这种情况下,查找与“V”模式匹配的行需要查找包含以下内容的行序列:
股价下跌前的行,后跟
股价下跌处的一行或多行,后跟
股价上涨处的一行或多行
您可以将其表示为以下行模式:
行模式包含 模式变量、 量词 (类似于正则表达式中使用的量词)和 运算符。模式变量定义针对行计算的表达式。
在此行模式中:
row_before_decrease、row_with_price_decrease和row_with_price_increase是模式变量。这些模式变量的表达式应计算为:任意行(股价下跌前的行)
股价下跌处的一行
股价上涨处的一行
row_before_decrease类似于正则表达式中的.。在下面的正则表达式中,.匹配模式中第一个大写字母之前出现的任意单个字符。同样,在行模式中,
row_before_decrease匹配价格下跌的第一行之前出现的任意单个行。row_with_price_decrease和row_with_price_increase后面的+量词指定其中一行或多行必须匹配。
在 MATCH_RECOGNIZE 子句中,使用 PATTERN 分子句指定要匹配的行模式:
要指定模式变量的表达式,请使用 DEFINE 分子句:
其中:
row_before_decrease不需要在此处定义,因为它的计算结果应为任意行。row_with_price_decrease定义为价格下跌的行的表达式。row_with_price_increase定义为价格上涨的行的表达式。
要比较不同行中的价格,这些变量的定义使用 导航函数 LAG() 指定上一行的价格。
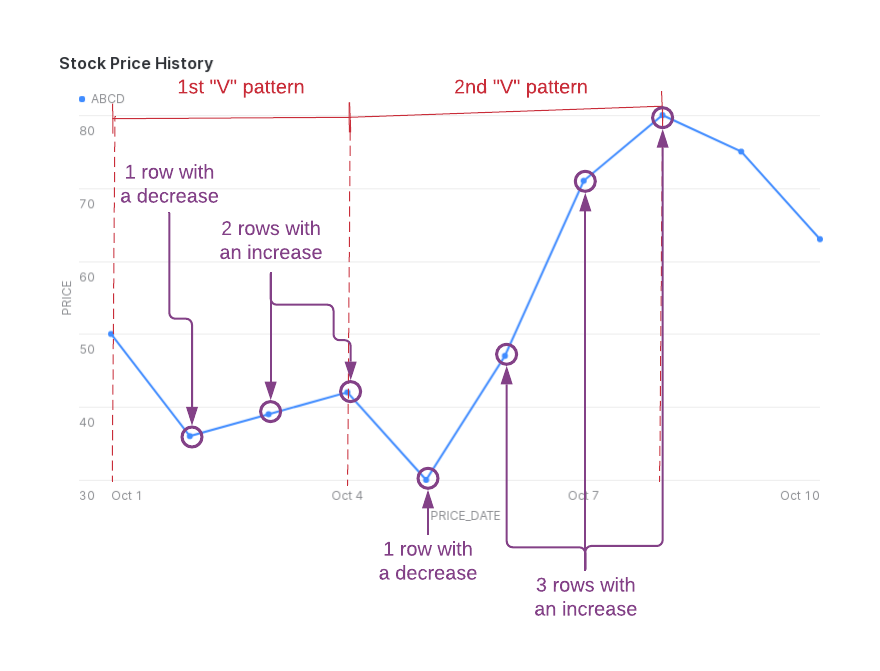
行模式匹配两个行序列,如下图所示:

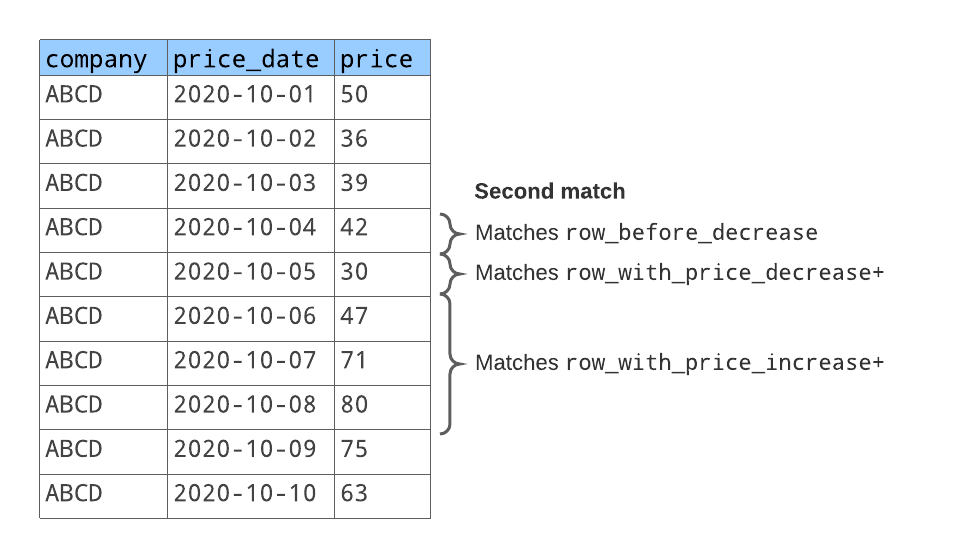
对于第一个匹配行序列:
row_before_decrease匹配股价为50的行。row_with_price_decrease匹配股价为36的下一行。row_with_price_increase匹配股价为39和42的下两行。
对于第二个匹配行序列:
row_before_decrease匹配股价为42的行。(这就是第一个匹配行序列末尾的一行。)row_with_price_decrease匹配股价为30的下一行。row_with_price_increase匹配股价为47、71和80的下三行。
第 3 步:指定要返回的行¶
MATCH_RECOGNIZE 可以返回:
汇总每个匹配序列的单行,或者
每个匹配序列中的每一行
在此示例中,您需要返回每个匹配序列的总结。使用 ONE ROW PER MATCH 分子句指定应为每个匹配序列返回一行。
第 4 步:指定要选择的度量值¶
在使用 ONE ROW PER MATCH 时, MATCH_RECOGNIZE 不返回表中的任何列(由 PARTITION BY 指定的列除外),即使 MATCH_RECOGNIZE 在 SELECT * 语句中也是如此。要指定此语句将返回的数据,必须定义 度量值。度量值是为每个匹配行序列(例如,序列的开始日期、序列的结束日期、序列中的天数等)计算的附加数据列。
使用 MEASURES 分子句指定要在输出中返回的这些附加列。用于定义度量值的一般格式为:
其中:
expression指定有关要返回的序列的信息。对于表达式,您可以将函数与表中的列和前面定义的模式变量结合使用。column_name指定将在输出中返回的列的名称。
在此示例中,您可以定义以下度量值:
用于标识序列(第一个匹配序列、第二个匹配序列等)的数字。
对于此度量值,请使用
MATCH_NUMBER()函数,该函数返回匹配项的编号。对于行 分区 的第一个匹配项,编号以1开头。如果有多个分区,则每个分区的编号都以1开头。股价下跌前的日期。
对于此度量值,请使用
FIRST()函数,该函数返回匹配序列中第一行的表达式的值。在此示例中,FIRST(price_date)返回每个匹配序列第一行中price_date列的值,即股价下跌之前的日期。股价上涨的最后一天。
对于此度量值,请使用
LAST()函数,该函数返回匹配序列中最后一行的表达式的值。处于“V”模式中的天数。
对于此度量值,请使用
COUNT(*)。由于您在度量值的定义中指定COUNT(*),因此星号 (*) 指定您要计算匹配序列中的所有行(而不是表中的所有行)。股票下跌的天数。
对于此度量值,请使用
COUNT(row_with_price_decrease.*)。星号 (.*) 前的句点指定您要计算匹配序列中与模式变量row_with_price_decrease匹配的所有行。股票上涨的天数。
对于此度量值,请使用
COUNT(row_with_price_increase.*)。
以下是用于定义上述度量值的 MEASURES 分子句:
下面显示了具有所选度量值的输出的示例:
如前所述,输出包含 company 列,因为 PARTITION BY 子句指定该列。
第 5 步:指定在何处继续查找下个匹配项¶
找到匹配行序列后, MATCH_RECOGNIZE 会继续查找下一个匹配序列。您可以指定 MATCH_RECOGNIZE 应从哪里开始搜索下一个匹配序列。
正如 匹配序列图 所示,一行可以属于多个匹配序列。在此示例中, 2020-10-04 行属于两个“V”模式。
在此示例中,要查找下一个匹配序列,您可以从价格上涨处的行开始。要在 MATCH_RECOGNIZE 子句中指定此项,请使用 AFTER MATCH SKIP:
其中, TO LAST row_with_price_increase 指定您需要从 价格上涨的最后一行 开始搜索。
对行进行分区和排序¶
在识别跨行模式时,第一步是将行按顺序排列,以便找到您的模式。例如,如果您想找到每家公司股票的股价随时间变化的模式,请执行以下操作:
按公司划分行,以便您可以搜索每个公司的股价。
按日期对每个分区中的行进行排序,以便您可以找到公司股价随时间的变化。
要对数据进行分区并指定行的顺序,请使用 MATCH_RECOGNIZE 中的 PARTITION BY 和 ORDER BY 子句。例如:
( MATCH_RECOGNIZE 的 PARTITION BY 子句在工作方式上与 窗口函数 的 PARTITION BY 分子句相同。)
分区的另一个好处是它可以利用并行处理。
定义要匹配的行模式¶
使用 MATCH_RECOGNIZE,您可以找到与模式匹配的行序列。您可以根据与特定条件匹配的行来指定此模式。
在包含不同公司的每日股价的表的示例中,假设您要查找三行的序列,其中:
在给定日,公司的股价低于 45.00。
第二天,股价至少下跌 10%。
第三天,股价至少上涨 3%。
要查找此序列,请指定与符合以下条件的三行匹配的模式:
在序列的第一行中,
price列的值必须小于 45.00。在第二行中,
price列的值必须小于或等于上一行的值的 90%。在第三行中,
price列的值必须大于或等于上一行的值的 105%。
第二行和第三行具有要求比较不同行中的列值的条件。要将一行中的值与上一行或下一行中的值进行比较,请使用函数 LAG() 或 LEAD():
LAG(column)返回上一行中column的值。LEAD(column)返回下一行中column的值。
在此示例中,您可以将三行的条件指定为:
序列中的第一行必须有
price < 45.00。第二行必须有
LAG(price) * 0.90 >= price。第三行必须有
LAG(price) * 1.05 <= price。
为这三行的序列指定模式时,请对具有不同条件的每行使用模式变量。使用 DEFINE 分子句,将每个模式变量定义为必须满足指定条件的行。以下示例为三行定义三个模式变量:
要定义模式本身,请使用 PATTERN 分子句。在此分子句中,使用正则表达式指定要匹配的模式。对于表达式的构建基块,请使用您定义的模式变量。例如,以下模式查找三行的序列:
以下 SQL 语句使用上面所示的 DEFINE 和 PATTERN 分子句:
接下来的部分将介绍如何定义与特定数量的行和出现在分区开头或结尾的行相匹配的模式。
备注
MATCH_RECOGNIZE 使用 回溯 (link removed) 来匹配模式。与其他 `使用回溯的正则表达式引擎 <https://en.wikipedia.org/wiki/Regular_expression#Implementations_and_running_times (link removed)>`_一样,要匹配的某些模式和数据组合可能需要很长时间才能执行,这可能导致高昂的计算成本。
要提高性能,请定义尽可能具体的模式:
确保每行仅匹配一个符号或少量符号
避免使用与每一行都匹配的符号(例如,不在
DEFINE子句中的符号或定义为 True 的符号)定义量词的上限(例如,
{,10}代替*)。
例如,如果没有匹配的行,以下模式可能会导致成本增加:
如果要匹配的行数有上限,您可以在量词中指定该限制以提高性能。此外,您可以查找不是 symbol1 的行(在本示例中为 not_symbol1),而不是指定要查找 symbol1 之后的 any_symbol ;
通常情况下,您应监控查询执行时间,验证查询花费的时间是否未超过预期。
结合使用量词与模式变量¶
在 PATTERN 分子句中,您使用正则表达式指定要匹配的行模式。您使用模式变量来标识序列中满足特定条件的行。
如果需要匹配满足特定条件的多行,您可以使用 量词,就像在 正则表达式 (link removed) 中一样。
例如,您可以使用量词 + 指定模式必须包含股价下跌 10% 的一行或多行,后跟股价上涨 5% 的一行或多行:
相对于分区的开头或结尾的匹配模式¶
要查找相对于分区的开头或结尾的行序列,您可以在 PATTERN 分子句中使用元字符 ^ 和 $。行模式中的这些元字符与 正则表达式中的相同元字符 (link removed) 具有类似的用途:
^表示分区的开头。$表示分区的结尾。
以下模式匹配分区开头价格大于 75.00 的股票:
请注意, ^ 和 $ 指定位置,不表示在这些位置的行(类似于正则表达式中的 ^ 和 $,指定位置,而不是在这些位置的字符)。在 PATTERN (^ GT75) 中,第一行(而不是第二行)的价格必须大于 75.00。在 PATTERN (GT75 $) 中,最后一行(不是倒数第二行)必须大于 75。
此处是采用 ^ 的完整示例。请注意,尽管在此分区的多行中 XYZ 股票的价格高于 60.00,但只有分区开头的行被视为匹配项。
此处是采用 $ 的完整示例。 请注意,尽管在此分区的多行中 ABCD 股票的价格高于 50.00,但只有分区结尾的行被视为匹配项。
指定输出行¶
使用 MATCH_RECOGNIZE 的语句可以选择要输出的行。
为每个匹配项生成一行与为每个匹配项生成所有行¶
当 MATCH_RECOGNIZE 找到匹配项时,输出可以是整个匹配项的一个汇总行,也可以是模式中每个数据点的一行。
ALL ROWS PER MATCH指定输出包括匹配项中的所有行。ONE ROW PER MATCH指定输出仅包含每个分区中每个匹配项的一行。SELECT 语句的投影子句只能使用
MATCH_RECOGNIZE的输出。实际上,这意味着 SELECT 语句只能使用MATCH_RECOGNIZE的以下分子句中的列:PARTITION BY分子句。匹配项中的所有行都来自同一分区,因此
PARTITION BY分子句表达式具有相同的值。MEASURES子句。当您使用
MATCH_RECOGNIZE ... ONE ROW PER MATCH时,MEASURES分子句不仅生成会为匹配项中的所有行返回相同值的表达式(例如MATCH_NUMBER()),还会生成可以为匹配项中的不同行返回不同值的表达式(例如MATCH_SEQUENCE_NUMBER())。如果使用的表达式可以为匹配项中的不同行返回不同的值,则输出不确定。
如果您熟悉聚合函数和
GROUP BY,下面的类比可能有助于理解ONE ROW PER MATCH:MATCH_RECOGNIZE中的PARTITION BY子句对数据进行分组,方式类似于GROUP BY对SELECT中的数据进行分组。MATCH_RECOGNIZE ... ONE ROW PER MATCH中的MEASURES子句允许聚合函数,例如COUNT(),为匹配项中的每一行返回相同的值,与MATCH_NUMBER()相同。
如果您仅使用会为匹配项中的每一行返回相同值的聚合函数和表达式,则
... ONE ROW PER MATCH的行为类似于GROUP BY和聚合函数。
默认为 ONE ROW PER MATCH。
以下示例显示了 ONE ROW PER MATCH 和 ALL ROWS PER MATCH 之间的输出差异。除 ...ROW(S) PER MATCH 子句外,这两个代码示例几乎完全相同。(在典型用法中,采用 ONE ROW PER MATCH 的 SQL 语句与采用 ALL ROWS PER MATCH 的 SQL 具有不同的 MEASURES 分子句。)
从输出中排除行¶
对于某些查询,您可能希望在输出中仅包含模式的一部分。例如,您可能希望查找股票连续多天上涨的模式,但仅显示峰值和一些汇总信息(例如,每个峰值之前价格上涨的天数)。
您可以在模式中使用 排除语法,告知 MATCH_RECOGNIZE 搜索特定模式变量,但不将其包含在输出中。要将模式变量作为要搜索的模式的一部分,但不作为输出的一部分,请使用 {- <pattern_variable> -} 表示法。
下面是一个简单的示例,显示了使用排除语法和不使用排除语法之间的区别。此示例包含两个查询,每个查询都搜索起价低于 45 美元,然后下跌,然后又上涨的股价。第一个查询不使用排除语法,因此显示所有行。第二个查询使用排除语法,不显示股价下跌的日期。
下一个示例更现实。它搜索股价连续上涨一天或多天,然后连续下跌一天或多天的模式。由于输出可能相当大,因此使用排除语法,仅显示股票上涨的第一天(如果连续上涨超过一天)和下跌的第一天(如果连续下跌超过一天)。模式如下所示:
此模式按顺序查找以下事件:
起始价格低于 45。
UP,可能紧随其后的是输出中未包含的其他内容。
DOWN,可能紧随其后的是输出中未包含的其他内容。
下面是上述模式版本在使用排除语法和不使用排除语法时的代码和输出:
返回有关匹配的信息¶
基本匹配信息¶
在许多情况下,您希望查询不仅列出包含数据的表中的信息,还列出有关找到的模式的信息。当您需要有关匹配项本身的信息时,请在 MEASURES 子句中指定该信息。
MEASURES 子句可以包括以下函数,这些函数特定于 MATCH_RECOGNIZE:
MATCH_NUMBER():每次找到匹配项时,都会为其分配一个顺序匹配号,从 1 开始。此函数返回该匹配号。MATCH_SEQUENCE_NUMBER():由于模式通常涉及多个数据点,因此您可能想知道哪个数据点与表中的每个值相关联。此函数返回匹配项中数据点的序列号。CLASSIFIER():分类器是行匹配的模式变量的名称。
下面的查询包含 MEASURES 子句,带匹配号、匹配序列号和分类器。
MEASURES 分子句可以产生比这更多的信息。有关更多详细信息,请参阅 MATCH_RECOGNIZE 参考文档。
窗口、窗口框架和导航函数¶
MATCH_RECOGNIZE 子句在行的“窗口”上运行。如果 MATCH_RECOGNIZE 包含 PARTITION 分子句,则每个 分区 是一个窗口。如果没有 PARTITION 分子句,则整个输入是一个窗口。
MATCH_RECOGNIZE 的 PATTERN 分子句按从左到右的顺序指定符号。例如:
如果将数据想象成从左到右按升序排列的行序列,您可以将 MATCH_RECOGNIZE 视为向右移动(例如,从股价示例中的最早日期到最晚日期),在每个窗口内的行中搜索模式。
MATCH_RECOGNIZE 从窗口中的第一行开始,检查该行和后续行是否与模式匹配。
在非常简单的情况下,在确定是否存在从窗口第一行开始的模式匹配后, MATCH_RECOGNIZE 向右移动一行并重复该过程,检查第二行是否是该模式出现的开头。MATCH_RECOGNIZE 继续向右移动,直至到达窗口的尽头。
(MATCH_RECOGNIZE 可以向右移动多行。例如,您可以告知 MATCH_RECOGNIZE 在当前模式结束后开始搜索下一个模式。)
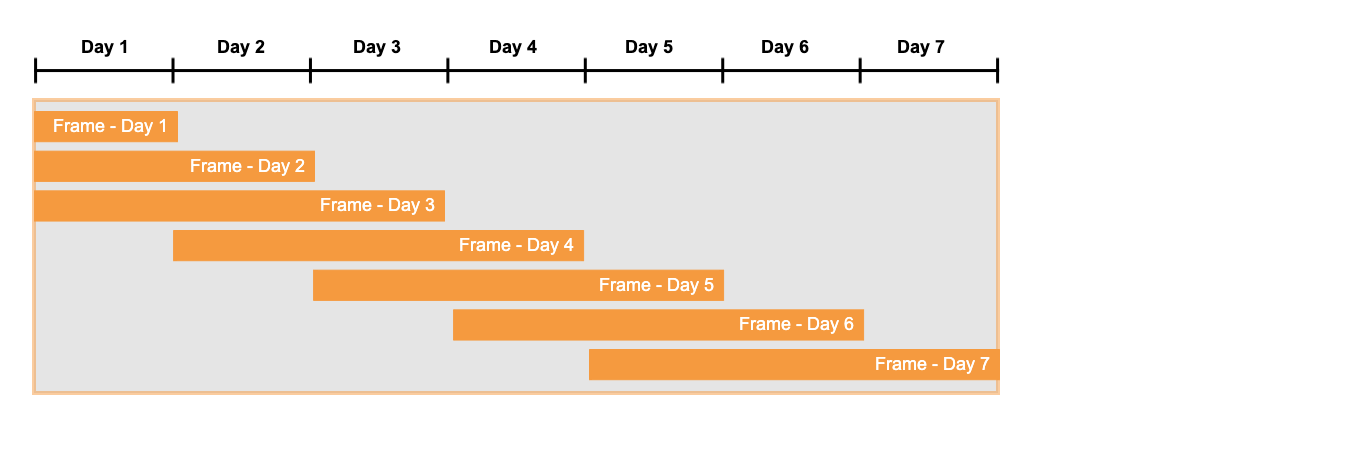
您可以粗略想象,就好像有一个“框架”在窗口内向右移动。该框架的左边缘位于当前正在检查匹配项的行系列的第一行。在找到匹配项之前,不会定义框架的右边缘;找到匹配项后,框架的右边缘是匹配项的最后一行。例如,如果搜索模式是 pattern (start down up),则与 up 匹配的行是框架右边缘之前的最后一行。
(如果未找到匹配项,则永远不会定义框架的右边缘,并且永远不会引用。)
在简单的情况下,您可以如下图所示想象一个滑动窗口框架:
您已经了解了 导航函数,例如 DEFINE 分子句(如 DEFINE down_10_percent as LAG(price) * 0.9 >= price)中使用的 LAG()。以下查询显示导航函数也可以在 MEASURES 子句中使用。在此示例中,导航函数显示包含当前匹配项的窗口框架的边缘(以及大小)。
此查询中的每个输出行都包含该行的 LAG()、 LEAD()、 FIRST() 和 LAST() 导航函数的值。窗口框架的大小是 FIRST() 与 LAST() 之间的行数,包括第一行和最后一行本身。
以下查询中的 DEFINE 和 PATTERN 子句选择包含三行的组(October 1-3、October 2-4、October 3-5 等)。
此查询的输出还说明了,对于试图引用匹配组之外(即 窗口框架 之外)的行的表达式, LAG() 和 LEAD() 函数返回 NULL。
DEFINE 子句中导航函数的规则与 MEASURES 子句中导航函数的规则略有不同。例如, PREV() 函数在 MEASURES 子句中可用,但当前在 DEFINE 子句中不可用。相反,您可以在 DEFINE 子句中使用 LAG()。MATCH_RECOGNIZE 的参考文档列出了每个 导航函数 的相应规则。
MEASURES 分子句还可以包括以下内容:
聚合函数。例如,如果模式可以匹配不同数量的行(例如,因为它匹配 1 个或多个下跌股价),那么您可能想知道匹配的总行数;您可以使用
COUNT(*)来显示这一点。对匹配中每一行中的值进行操作的常规表达式。这些可以是数学表达式、逻辑表达式等。例如,您可以查看行中的值并打印文本描述符,例如“ABOVE AVERAGE”。
请记住,如果您对行 (
ONE ROW PER MATCH) 进行分组,并且某个列对组中的不同行具有不同的值,则为该匹配项的该列选择的值不确定,并且基于该值的表达式也可能不确定。
有关 MEASURES 分子句的更多信息,请参阅 MATCH_RECOGNIZE 的参考文档。
指定下一个匹配项的搜索位置¶
默认情况下,在 MATCH_RECOGNIZE 找到匹配项后,它会在更近匹配项结束后立即开始查找下一个匹配项。例如,如果 MATCH_RECOGNIZE 在第 2、3 和 4 行中找到匹配项,则 MATCH_RECOGNIZE 将开始在第 5 行查找下一个匹配项。这样可以防止重叠匹配项。
但是,您可以选择其他起点。
请考虑以下数据:
假设您在数据中搜索模式 W (向下、向上、下上)。有三种 W 形状:
月份:1、2、3、4 和 5。
月份:3、4、5、6 和 7。
月份:5、6、7、8 和 9。
您可以使用该 SKIP 子句指定是需要所有模式,还是仅使用不重叠模式。SKIP 子句还支持其他选项。SKIP 子句在 MATCH_RECOGNIZE 中进行了更详细的介绍。
最佳实践¶
在
MATCH_RECOGNIZE子句中包含 ORDER BY 子句。请记住, ORDER BY 仅适用于
MATCH_RECOGNIZE子句。如果希望整个查询按特定顺序返回结果,请在查询的外层使用附加ORDER BY子句。
模式变量名称:
使用有意义的模式变量名称,使模式更易于理解和调试。
检查
PATTERN和DEFINE子句中模式变量名称中是否存在印刷错误。
避免对具有默认值的子句使用默认值。明确您的选择。
在扩展到完整数据集之前,使用少量数据样本测试模式。
MATCH_NUMBER()、MATCH_SEQUENCE_NUMBER()和CLASSIFIER()在调试中非常有用。请考虑在查询的外层使用
ORDER BY子句,以使用MATCH_NUMBER()和MATCH_SEQUENCE_NUMBER()强制输出按顺序排列。如果输出数据按其他顺序排列,则输出可能与模式不匹配。
避免分析错误¶
相关性与因果关系¶
相关性并不能保证因果关系。MATCH_RECOGNIZE 可以返回“假阳性”(您看到模式,但这只是巧合)。
模式匹配还可能导致“假阴性”(现实世界中存在模式,但该模式未出现在数据样本中)。
在大多数情况下,找到匹配项(例如,找到表明保险欺诈的模式)只是分析的第一步。
以下因素通常会增加假阳性的数量:
大型数据集。
搜索大量模式。
搜索简短或简单的模式。
以下因素通常会增加假阴性的数量。
小型数据集。
不搜索所有可能的相关模式。
搜索比必要更复杂的模式。
不区分顺序的模式¶
尽管大多数模式匹配都要求数据按顺序排列(例如,按时间),但也有例外。例如,如果一个人在车祸和家庭入室盗窃中都犯了保险欺诈罪,那么欺诈发生的顺序并不重要。
如果您要查找的模式不区分顺序,则可以使用“alternative”(|) 和 PERMUTE,让搜索不看重顺序。
示例¶
本部分包含其他示例。
您仍然可以在 MATCH_RECOGNIZE 中找到更多示例。
查找多日价格上涨¶
以下查询查找公司 ABCD 价格连续两天上涨的所有模式:
演示 PERMUTE 运算符¶
此示例演示模式中的 PERMUTE 运算符。在图表中搜索所有向上和向下的峰值,将价格上涨的数量限制为两个:
演示 SKIP NEXT TO ROW 选项¶
此示例演示 SKIP TO NEXT ROW 选项。此查询在每个公司的图表中搜索 W 形曲线。匹配项可以重叠。
排除语法¶
此示例显示模式中的排除语法。此模式(与上一个模式一样)搜索 W 形状,但此查询的输出不包括价格下跌。请注意,在此查询中,匹配会持续到匹配项的最后一行:
在不相邻行中搜索模式¶
在某些情况下,您可能希望在非连续行中查找模式。例如,如果要分析日志文件,则可能需要搜索致命错误之前有特定警告序列的所有模式。可能没有一种自然的方法来对行进行分区和排序,以便所有相关消息(行)都位于单个窗口中并相邻。在这种情况下,可能需要一种模式来查找特定事件,但不要求事件在数据中连续。
下面是 PATTERN 和 DEFINE 子句的示例,用于识别符合该模式的连续行或非连续行。符号 ANY_ROW 定义为 TRUE (因此它与任何行匹配)。ANY_ROW 每次出现后的 * 表示允许 ANY_ROW 在第一个警告和第二个警告之间以及第二个警告和致命错误日志消息之间出现 0 次或多次。因此,整个模式表示搜索 WARNING1,后跟任意数量的行,后跟 WARNING2,后跟任意数量的行,后跟 FATAL_ERROR。要从输出中省略不相关的行,查询使用 排除 语法({- 和 -})。
故障排除¶
使用 ONE ROW PER MATCH 并在 Select 子句中指定列时出错¶
ONE ROW PER MATCH 子句的作用类似于聚合函数。这限制了您可以使用的输出列。例如,如果您使用 ONE ROW PER MATCH 且每个匹配项包含三行不同的日期,则不能在 SELECT 子句将日期列指定为输出列,因为没有一个日期对所有三行都正确。
意外结果¶
检查
DEFINE和PATTERN子句中的印刷错误。如果
PATTERN子句中使用的模式变量名称未在DEFINE子句中定义(例如,因为DEFINE或PATTERN子句中键入的名称不正确),则不会报告错误。相反,模式变量名称只是假定每一行都为 True。查看
SKIP子句以确保其适当,例如包含或排除重叠模式。