混合表¶
混合表是一种 Snowflake 表类型,它使用基于索引的随机读写进行了优化,实现低延迟和高吞吐量。混合表提供基于行的存储引擎,支持行锁定以实现高并发。混合表还强制实施唯一参照完整性约束,这对于事务性工作负载至关重要。您可以将混合表与其他 Snowflake 表和功能一起使用,支持 Unistore 工作负载,将事务性和分析性数据汇集到一个平台中。
可能受益于混合表的用例包括:
应用程序和工作流的元数据,例如,维护引入工作流的状态,该工作流需要数千个并行处理器对单个表进行高并发更新。
通过 API 或用户界面为预计算汇总提供低延迟服务。
具有关系数据模型的轻量级事务性应用程序。
小技巧
在创建和使用混合表之前,您应该熟悉一些 不支持的功能和限制。
架构¶
混合表无缝集成到现有的 Snowflake 架构中。客户连接到相同的 Snowflake 数据库服务。查询在云服务层中进行编译和优化,并在与标准表相同的查询引擎和虚拟仓库中执行。这一架构有几个主要优点:
Snowflake 平台功能开箱即可支持与混合表搭配使用,例如数据治理。
您可以运行混合操作和分析查询的混合工作负载。
您可以将混合表与其他 Snowflake 表联接起来;查询将在同一查询引擎中以原生和高效的方式执行。不需要联合。
您可以跨混合表和其他 Snowflake 表执行原子事务。无需自行编排两阶段提交。
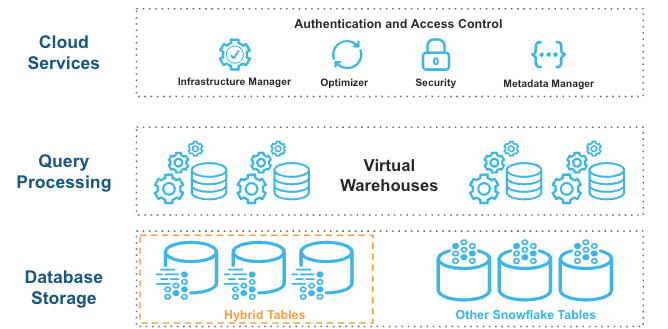
混合表利用行存储作为主要数据存储来提供出色的操作查询性能。当您写入混合表时,数据将直接写入行存储。数据被异步复制到对象存储中,以便在不影响持续运行工作负载的情况下为大型扫描提供更好的性能和工作负载隔离。为提供更好的分析查询性能,一些数据也可能以列式格式缓存在您的仓库中。您只需对逻辑混合表执行 SQL 语句,Snowflake 查询优化器就会决定从哪里读取数据,以便提供最佳性能。您可以获得一致的数据视图,无需担心底层基础设施。
备注
由于混合表的主存储是行存储,因此混合表的存储占用空间通常比标准表大。造成差异的主要原因是标准表的列数据通常可实现更高的压缩率。有关存储费用的详细信息,请参阅 评估混合表的成本。
功能¶
混合表提供了一些其他 Snowflake 表类型不支持的附加功能。
功能 |
混合表 |
标准表 |
|---|---|---|
主数据布局 |
以行为导向,带有次级列式存储 |
列式 微分区 |
锁定 |
行级 |
分区或表 |
PRIMARY KEY 约束 |
必需,已强制执行 |
可选,未强制执行 |
FOREIGN KEY 约束 |
可选、已强制执行(参照完整性) |
可选,未强制执行 |
UNIQUE 约束 |
可选(PRIMARY KEY 除外),已强制执行 |
可选,未强制执行 |
NOT NULL 约束 |
可选(PRIMARY KEY 除外),已强制执行 |
可选,已强制执行 |
索引 |
支持高性能;写入时同步更新 |
搜索优化服务对列进行索引,以提高点查找性能;已异步批量更新/维护 |
当约束条件保护列不以某些方式更新时,该约束条件被 强制执行。例如,声明为 NOT NULL 的列不能包含 NULL 值。尝试将 NULL 值复制或插入到 NOT NULL 列时,总是导致错误。
对于混合表,不能在 PRIMARY KEY、FOREIGN KEY 和 UNIQUE 约束条件上设置 NOT ENFORCED 属性。设置该属性会导致“invalid constraint property”错误。有关约束规则的更多信息,请参阅 混合表的约束。
当表中的一个或多个列必须具有这样的约束条件时,约束条件则是 必需的,仅对混合表的 PRIMARY KEY 约束条件有效。
何时使用混合表¶
虽然您应该期待 Snowflake 标准表在大型分析查询中提供更好的性能,但混合表可以在短期运行的操作查询上更快地提供结果。混合表为许多工作负载提供高并发性和低延迟。以下类型的查询最有可能从混合表受益:
基于索引的随机点读取,检索少量记录,如客户对象
高并发随机写入,包括插入、更新和合并:
应用程序通常混合使用混合表和标准表,每种表类型中存储不同的数据集。例如,您可能会出于分析目的经常批量加载、扫描和汇总一些数据,以及每次访问一行的其他数据,以高并发性在 ID 列上进行筛选。您可以根据工作负载的需求,在单个数据库中混合使用标准表和混合表。