Create hybrid tables¶
This topic provides an overview on creating hybrid tables in Snowflake.
Note
To create a hybrid table, you must have a running warehouse that is specified as the current warehouse for your session. Errors may occur if no running warehouse is specified when you create a hybrid table. For more information, see Working with Warehouses.
CREATE HYBRID TABLE options¶
You can create a hybrid table by using one of the following methods.
-
CREATE HYBRID TABLE. The following example creates a hybrid table with a required PRIMARY KEY constraint, inserts some rows, deletes a row, and queries the table:
-
CREATE HYBRID TABLE … AS SELECT (CTAS) or CREATE HYBRID TABLE … LIKE. For example:
Loading data¶
Note
Because the primary storage for hybrid tables is a row store, hybrid tables typically have a larger storage footprint than standard tables. The main reason for the difference is that columnar data for standard tables often achieves higher rates of compression. For details about storage costs, see Evaluate cost for hybrid tables.
Optimized bulk loads¶
You can bulk load data into hybrid tables by copying either from a data stage or from other tables. The optimized bulk loading path supports CTAS (for new tables), COPY INTO <table>, and all variants of INSERT except INSERT ALL. It accelerates loading whether the hybrid table is empty or already contains data.
You can check the Statistics information in Snowsight query profiles to see whether the bulk-load fast path was used. Number of rows inserted is referred to as the Number of rows bulk loaded when the fast path is used. For example, this CTAS operation bulk loaded 200000 rows into a new table:
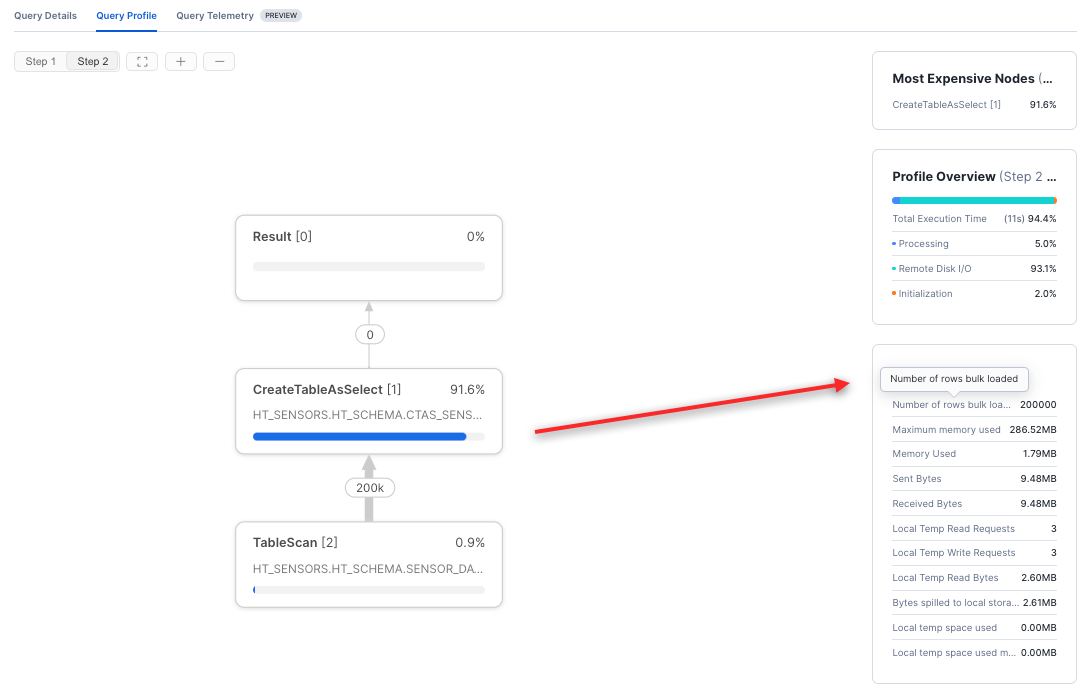
For more information about query profiles, see Analyze query profiles for hybrid tables and Monitor query activity with Query History.
Attention
CTAS commands do not support FOREIGN KEY constraints. If your hybrid table requires FOREIGN KEY constraints, use COPY or INSERT INTO … SELECT to load the table.
Note
Other methods of loading data into Snowflake tables (for example, Snowpipe) are not currently supported.
Index-building errors during loads¶
Index sizes are limited in width. When building indexes on columns in a hybrid table, especially
indexes on a large number of columns, any command that loads the table
(including CTAS, COPY, or INSERT INTO … SELECT) might return the following error. In this case, the table
contains an index named IDX_HT100_COLS:
This error occurs because row-based storage imposes a limit on the size of the data (and metadata) that can be stored per record. To reduce the record size, try creating the table without specifying larger columns, such as wide VARCHAR columns, as indexed columns. You can also try creating indexes on fewer columns.
You can also try using INCLUDE columns on secondary indexes when you create a hybrid table or an index on a hybrid table. For more information, see INCLUDE columns.