Cortex Analyst 语义模型规范¶
为什么使用语义模型?¶
Cortex Analyst 允许用户使用自然语言查询 Snowflake 数据。但是,业务用户经常使用与架构不兼容的语言。虽然用户在问题中指定了领域特定的业务术语,但基础数据通常使用技术缩写词进行存储。例如,“CUST”通常代表客户。这种脱节,再加上架构缺乏语义上下文,使 Cortex Analyst 难以提供准确的答案。
语义模型将业务术语映射到数据库架构并添加上下文含义。例如,当用户询问“上个月总收入”时,语义模型可以将“收入”定义为净收入,将“上个月”定义为上一个日历月。此映射有助于 Cortex Analyst 了解用户的意图并提供准确的答案。
备注
语义模型被视为 元数据。
关键概念¶
备注
在本主题中,数据库工件称为“物理”对象,而语义模型工件称为“逻辑”对象。
语义模型的结构和概念与数据库架构中的相似,但语义模型使您可以提供有关数据的更多语义信息。
语义层概念¶
定义逻辑语义层的结构和概念与定义物理数据库层的结构和概念类似。以下是语义层的概念类型:
逻辑表级
模型级
其他上下文
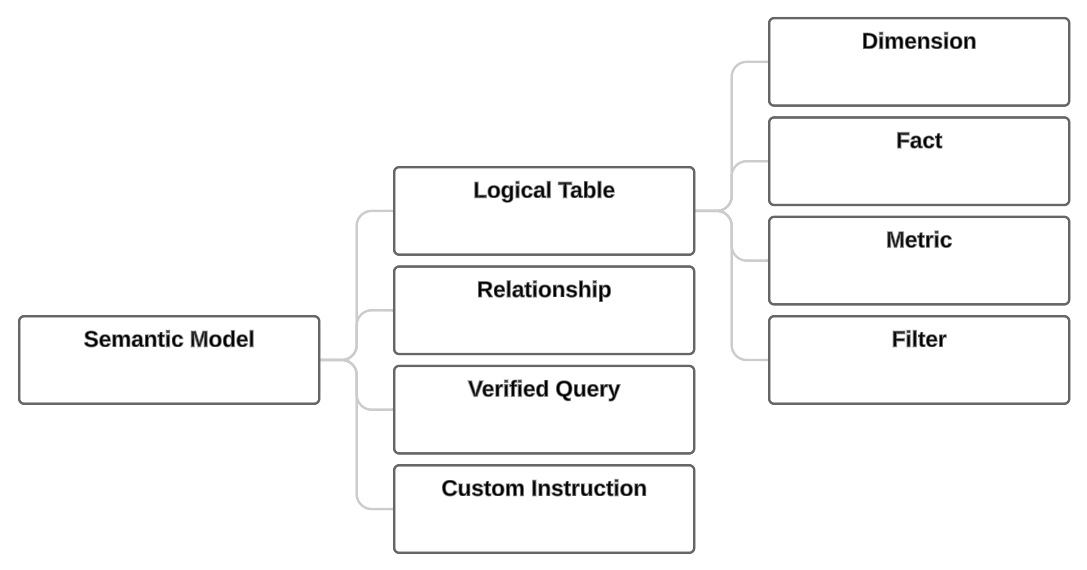
逻辑表级概念¶
逻辑表 是 Snowflake 语义模型的基本概念。它表示物理数据库表或视图。它通常对应于业务实体(如客户、订单或供应商)或维度(如位置或时间)。逻辑表中的每一行通常表示实体的唯一实例,例如客户 ID。
逻辑表包含以下类型的列:
事实(有关业务事件的定量数据)
维度(人员、内容、位置和方式)
时间(事件发生的时间)
与逻辑表关联的筛选器,以允许将查询结果限制为特定数据子集。
您可以使用其他逻辑对象的聚合或组合来定义指标。
以下示例使用 TPC-H 架构 (https://www.tpc.org/TPC_Documents_Current_Versions/pdf/TPC-H_v3.0.1.pdf),其中包括 LINEITEM 事实表。对于完整的 YAML 实现,请下载 snow_tpch 文件。

以下所有逻辑表级示例都属于 order_lineitems 逻辑表。
tables:
- name: order_lineitems
description: >
The order line items table contains detailed information about each item within an
order, including quantities, pricing, and dates.
base_table:
database: SNOWFLAKE_SAMPLE_DATA
schema: TPCH_SF1
table: LINEITEM
primary_key:
columns:
- order_key
- order_lineitem_number
维度表示为事实提供上下文的分类数据,例如产品、客户或位置信息。维度通常包含描述性文本值,例如产品名称或客户地址。它们用于筛选、分组和标记分析和报表中的事实。
dimensions:
- name: customer_location
synonyms:
- "customer region"
- "customer area"
description: Customer location, combining nation and region names.
expr: CONCAT(nation.N_NAME, ', ', region.R_NAME)
data_type: TEXT
unique: false
cortex_search_service:
service: customer_location_search
literal_column: <string>
database: temp
schema: service
is_enum: false
时间维度 为分析不同时期的事实提供了时间上下文。它支持跟踪特定时间间隔(日期、月、年)的指标,并支持趋势识别和周期间比较等分析。
time_dimensions:
- name: shipment_duration
synonyms:
- "shipping time"
- "shipment time"
description: The time it takes for items to be shipped.
expr: DATEDIFF(day, lineitem.L_SHIPDATE, lineitem.L_RECEIPTDATE)
data_type: NUMBER
unique: false
事实 是可衡量的定量数据,为分析提供上下文。事实表示与业务流程相关的数值,例如销售额、成本或数量。事实是未聚合的行级概念。
# Fact columns in the logical table.
facts:
- name: net_revenue
synonyms:
- "revenue after discount"
- "net sales"
description: Net revenue after applying discounts.
expr: lineitem.L_EXTENDEDPRICE * (1 - lineitem.L_DISCOUNT)
data_type: NUMBER
For semantic views, facts can be made private (accessible in the semantic view, but
not by end users) by setting the access_modifier field to private_access. By default, facts are public (accessible by
users).
筛选器 是一种条件,根据时间段、位置或类别等标准将查询结果限制为特定数据子集。
- name: north_america
synonyms:
- "NA"
- "North America region"
description: >
Filter to restrict data to orders from North America.
comments: Used for analysis focusing on North American customers.
expr: nation.N_NAME IN ('Canada', 'Mexico', 'United States')
指标 是一种可量化的业务绩效衡量标准,通过 SQL 公式表达。您可以将指标用作报告和仪表板中的关键绩效指标 (KPIs)。您可以计算两种指标:
常规指标 对事实列的值进行汇总(使用 SUM 或 AVG 等函数)。
Derived metrics are calculated from existing metrics, using arithmetic operations such as addition or division. Derived metrics are supported only in semantic views.
在最精细的级别定义指标,以便在更高的级别进行聚合。例如,在行项目级别定义 total_revenue,以允许按客户、供应商或区域进行汇总。
以下示例展示了两种常规指标计算:一种简单的计算和一种比较复杂的计算。这些在 table 定义内部定义,因此它们的作用域为该逻辑表。
metrics:
# Simple metric referencing objects from the same logical table
- name: total_revenue
expr: SUM(lineitem.l_extendedprice * (1 - lineitem.l_discount))
# Complex metric referencing objects from multiple logical tables.
# The relationships between tables have been defined below.
- name: total_profit_margin
description: >
The profit margin from orders. This metric is not additive
and should always be calculated directly from the base tables.
expr: (SUM(order_lineitems.net_revenue) -
SUM(part_suppliers.part_supplier_cost * order_lineitems.lineitem_quantity))
/ SUM(order_lineitems.net_revenue)
小技巧
For semantic views, metrics can be made private (accessible in the semantic view, but not by end users) by setting the
access_modifier field to private_access. By default, metrics are public (accessible by users).
允许的引用¶
Expressions for dimensions, facts, filters, or regular table-scoped metrics can reference:
来自其自己的基表的物理列
同一逻辑表内的逻辑列
来自语义模型中其他逻辑表的逻辑列
For semantic views, derived metrics can reference metrics defined in any logical table in the semantic view or other derived metrics.
备注
表达式不能引用其他物理表中的物理列。
模型级概念¶
关系通过共享键上的联接来连接逻辑表。例如,通过 customer_id 列上的联接,客户和订单表之间可能存在关系。您可以使用联接来分析具有客户属性的订单数据。
relationships:
# Relationship between orders and lineitems
- name: order_lineitems_to_orders
left_table: order_lineitems
right_table: orders
relationship_columns:
- left_column: order_key
right_column: order_key
# For semantic views, do not specify
# join_type or relationship_type.
join_type: left_outer
relationship_type: many_to_one
# Relationship between lineitems and partsuppliers
- name: order_lineitems_to_part_suppliers
left_table: order_lineitems
right_table: part_suppliers
# The relationship requires equality of multiple columns from each table
relationship_columns:
- left_column: part_key
right_column: part_key
- left_column: supplier_key
right_column: supplier_key
# For semantic views, do not specify
# join_type or relationship_type.
join_type: left_outer
relationship_type: many_to_one
验证查询存储库 (VQR) 是已验证为正确的问题和相应 SQL 查询的集合。您可以使用查询来帮助提高 Cortex Analyst 的结果的准确性。
您可以使用 Cortex Analyst 中的自定义指令,以便更好地控制 Cortex Analyst 的 SQL 查询生成。在自定义说明中,您向 LLM 提供业务的唯一上下文。
Cortex Analyst 语义模型在 YAML (https://yaml.org/spec/) 中指定。模型提供了必要的语义信息,从而高精度地回答自然语言问题。
YAML 格式¶
YAML 在人类可读性和精度之间取得平衡。业务用户可以理解它,而数据工程师和分析师可以清楚地定义技术概念。
Cortex Analyst 语义模型的一般语法为:
# Name and description of the semantic model.
name: <name>
description: <string>
comments: <string>
# Logical table-level concepts
# A semantic model can contain one or more logical tables.
tables:
# A logical table on top of a base table.
- name: <name>
description: <string>
# The fully qualified name of the base table.
base_table:
database: <database>
schema: <schema>
table: <base table name>
# Dimension columns in the logical table.
dimensions:
- name: <name>
synonyms: <array of strings>
description: <string>
expr: <SQL expression>
data_type: <data type>
unique: <boolean>
cortex_search_service:
service: <string>
literal_column: <string>
database: <string>
schema: <string>
is_enum: <boolean>
# Time dimension columns in the logical table.
time_dimensions:
- name: <name>
synonyms: <array of strings>
description: <string>
expr: <SQL expression>
data_type: <data type>
unique: <boolean>
# Fact columns in the logical table.
facts:
- name: <name>
synonyms: <array of strings>
description: <string>
access_modifier: < public_access | private_access > # Supported only for semantic views.
# Default is public_access.
expr: <SQL expression>
data_type: <data type>
# Regular metrics scoped to the logical table.
metrics:
- name: <name>
synonyms: <array of strings>
description: <string>
access_modifier: < public_access | private_access > # Supported only for semantic views.
# Default is public_access.
expr: <SQL expression>
# Commonly used filters over the logical table.
filters:
- name: <name>
synonyms: <array of strings>
description: <string>
expr: <SQL expression>
# Model-level concepts
# Relationships between logical tables
relationships:
- name: <string>
left_table: <table>
right_table: <table>
relationship_columns:
- left_column: <column>
right_column: <column>
- left_column: <column>
right_column: <column>
# For semantic views, do not specify
# join_type or relationship_type.
join_type: <left_outer | inner>
relationship_type: < one_to_one | many_to_one >
# Derived metrics scoped to the semantic view.
# Derived metrics are supported only for semantic views.
metrics:
- name: <name>
synonyms: <array of strings>
description: <string>
access_modifier: < public_access | private_access > # Default is public_access
expr: <SQL expression>
# Additional context concepts
# Verified queries with example questions and queries that answer them
verified_queries:
- name: # A descriptive name of the query.
question: # The natural language question that this query answers.
verified_at: # Optional: Time (in seconds since the UNIX epoch, January 1, 1970) when the query was verified.
verified_by: # Optional: Name of the person who verified the query.
use_as_onboarding_question: # Optional: Marks this question as an onboarding question for the end user.
sql: # The SQL query for answering the question
有关示例规范,请参阅 snow_tpch.yaml 文件。
Create a semantic view using the AI-assisted model generator¶
Use the AI-assisted generator to create a semantic model that combines semantic information from multiple sources. For more information about the AI-assisted generator, see Using the AI-assisted generator to create a semantic view.
To create the model, complete the following steps:
Sign in to Snowsight.
In the navigation menu, select AI & ML » Cortex Analyst.
In the title bar, select Create new » Create new Semantic Model.
Select a location to store the semantic model after creation.
- Enter a name for the semantic model.
This name automatically populates the File name field.
For Description, specify information about the semantic model.
Optional: Enter a different file name.
Select Next.
Optional: To provide context, for SQL Queries, provide example questions and their respective SQL queries that you want to use as part of the model.
备注
The AI-assisted generator runs EXPLAIN on these queries, so these queries should return actual data. If they do not, Snowflake doesn't guarantee proper performance.
For Select tables, provide the data source that you're using to create the semantic model. You must provide at least one table or view. There's no limit on the tables or views that you can specify, but we recommend not using more than 10 for the semantic model.
Select Next.
For Select columns, select the columns that you're using to create the semantic model. You can select all the columns or specific columns. For performance reasons, we recommend not using more than 50 columns.
Select whether you want to add sample values from each column to the semantic model.
Sample values help improve the accuracy of Cortex Analyst's results.
Select whether you want to add AI-generated descriptions for tables and columns to the semantic model.
The AI-generated descriptions are based on the column names and sample values.
Select Create and save.
You can view the progress of the model generation, including details about the steps that the model generator is taking, on the semantic model page. The process can take a few minutes.
To make further modifications, edit the model by either using Snowsight or editing the YAML file directly.
Cortex Analyst automatically generates suggestions to improve the semantic model after creation. Cortex Analyst uses the query history accessible by the role used to create the semantic model to generate both relationships and verified query suggestions. It might take some time for the suggestions to appear. After the suggestions appear, you can review them and apply them to the model as needed.
打开现有语义模型¶
创建语义模型后,可以在 Snowsight 中打开。要打开语义模型,请执行以下操作:
Sign in to Snowsight.
In the navigation menu, select AI & ML » Cortex Analyst.
On the Semantic models tab, select the database, schema, and stage where the semantic model was saved.
From the list of semantic models, select the semantic model that you want to open.
选择 Open。
备注
If you don't see your semantic model within your stage, try refreshing the list of models, not the page.
创建语义模型的提示¶
按业务领域或主题组织 YAML 文件
根据特定的业务域或主题来组织 YAML 文件,保持范围明确。例如,分别为销售分析和营销分析创建单独的语义模型。
根据目标受众、预期问题或 KPIs 以及所需数据来定制用例。定义明确的用例可带来更丰富的语义模型和更有效的数据检索。
从最终用户的角度思考
确定用户可能就相关主题提出的关键问题,并仅包含回答这些问题所需的表和列。
使用与最终用户所用的词汇相似的名称和同义词。
在描述字段中包含重要的详细信息,使其对第一次在此数据集上编写查询的人们有所帮助,例如 DATETIME 列的时区。
捕捉复杂计算
将更困难或特定于业务的查询纳入表达式中。
使用宽表而不是长表
如果您有一个包含“指标”和“值”列的表,请将表扁平化,使每个指标成为一列。这种方法为模型的每个指标提供了更多的语义信息。
查看自动生成的描述
如果您使用的是 语义模型生成器 (https://github.com/Snowflake-Labs/semantic-model-generator),它会尝试自动生成表和列的描述。请务必仔细查看这些描述,确保其合理且具有相关性;根据需要进行修改。
从简单开始,逐渐扩展
范围设置恰到好处的语义文件可确保结果具有更高的精度和准确性。从少量的表和列开始,逐步扩展语义模型 YAML,以涵盖更多种类的问题。请记住,YAML 的构建是一个持续的过程。
包含经过验证的查询
已验证的查询存储库 (VQR) 是一组由简单的英语问题和对应查询组成的集合,可以帮助提高结果的准确性和可信度。
已知限制¶
Cortex Analyst imposes a 2 MB size limit on the semantic model or semantic view to restrict the size of API inputs.
规范¶
本部分包含前面部分中描述的关键概念的详细规范。
语义模型¶
一个语义模型表示一组表。该模型包含表的描述,每个表都包含对表的具体方面的描述。模型中描述的每个表都映射到 Snowflake 中的一个物理基表。
它有以下字段:
必填
name此语义模型的描述性名称。
必须是唯一的,并遵循 未加引号的标识符要求。它也不能与 Snowflake 保留的关键字 冲突。
可选
这些字段不是必需字段,但应尽可能包含这些字段。
description该语义模型的描述,包括其用于何种分析的详细信息。
tables此语义模型中的逻辑表列表。
relationships逻辑表之间的联接列表。
逻辑表¶
您可以将逻辑表视为物理数据库表或视图的视图。它有以下字段:
必填
name此表的描述性名称。
必须是唯一的,并遵循 未加引号的标识符要求。它也不能与 Snowflake 保留的关键字 冲突。
base_table数据库中底层基表的完全限定名称。
可选
这些字段不是必需字段,但应尽可能包含这些字段。
synonyms用于指代此表的其他术语/短语的列表。在逻辑表的同义词中,它必须是唯一的。
description对于此表的描述。
primary_key此表的主键列。如果要定义关系,则为必需。
dimensions此表中的维度列列表。
time_dimensions此表中的时间维度列列表。
facts此表中事实列的列表。
metrics此表中指标的列表。
filters此表上的预定义筛选器(如果有)。
维度¶
维度描述了诸如状态、用户类型、平台等分类值。它有以下字段:
必填
name此维度的描述性名称。
必须是唯一的,并遵循 未加引号的标识符要求。它也不能与 Snowflake 保留的关键字 冲突。
expr此维度的 SQL 表达式。这可能是对物理列的引用,或者是包含底层基表中一列或多列的 SQL 表达式。
data_type此维度的数据类型。有关 Snowflake 中所有数据类型的概述,请参阅 SQL 数据类型参考。请注意,目前不支持
VARIANT、OBJECT、GEOGRAPHY和ARRAY。
可选
这些字段不是必需字段,但应尽可能包含这些字段。
synonyms用于指代此维度的其他术语/短语的列表。在这个语义模型的所有同义词中,必须是唯一的。
description关于此维度的简要描述,包括其包含哪些数据。
unique一个布尔值,表示此维度具有唯一值。
sample_values此列的示例值(如果有)。可以添加任何可能在用户问题中被引用的值。
is_enum布尔值。如果为
True,则sample_values字段中的值将被视为可能值的完整列表,模型仅在筛选该列时从这些值中进行选择。cortex_search_service指定要用于此维度的 Cortex Search 服务。它有以下字段:
service:Cortex Search 服务的名称。literal_column:(可选)Cortex Search 服务中包含字面量值的列。database:(可选)Cortex Search 服务所在的数据库。默认为base_table的数据库。schema:(可选)Cortex Search 服务所在的架构。默认为base_table的架构。
cortex_search_servicereplaces thecortex_search_service_namefield, which could only specify the name.cortex_search_service_namehas been deprecated.
时间维度¶
时间维度描述的是时间值,例如销售日期、创建时间和年份。它有以下字段:
必填
name此时间维度的描述性名称。
必须是唯一的,并遵循 未加引号的标识符要求。它也不能与 Snowflake 保留的关键字 冲突。
expr此列的 SQL 表达式。这可能是对物理列的引用,或者是包含底层基表中一列或多列的 SQL 表达式。
data_type此时间维度的数据类型。有关 Snowflake 中所有数据类型的概述,请参阅 SQL 数据类型参考。请注意,目前不支持
VARIANT、OBJECT、GEOGRAPHY和ARRAY。
可选
这些字段不是必需字段,但应尽可能包含这些字段。
synonyms用于指代此时间维度的其他术语/短语的列表。在这个语义模型的所有同义词中,必须是唯一的。
description关于此维度的简要描述,包括其包含哪些数据。请提供相应信息,帮助人们使用此表编写查询。例如,对于 DATETIME 列,请指定数据的时区。
unique:一个布尔值,表示此列具有唯一值。
sample_values:此列的示例值(如果有)。可以添加任何可能在用户问题中被引用的值。此字段是可选字段。
事实¶
A fact describes numerical values, such as revenue, impressions, and salary. Facts used to be called measures in earlier releases of Cortex Analyst. Facts are backward compatible with measures. Facts have the following fields:
必填
name此事实的描述性名称。
必须是唯一的,并遵循 未加引号的标识符要求。它也不能与 Snowflake 保留的关键字 冲突。
expr此 SQL 表达式可以引用同一逻辑表的基本物理表中的物理列,也可以引用该逻辑表中的逻辑列(事实、维度或时间维度)。
data_type此事实的数据类型。有关 Snowflake 中所有数据类型的概述,请参阅 SQL 数据类型参考。请注意,目前不支持
VARIANT、OBJECT、GEOGRAPHY和ARRAY。
可选
The following fields are not required, but should be included whenever possible.
synonyms用于指代此度量值的其他术语/短语的列表。在这个语义模型的所有同义词中,必须是唯一的。
description关于此度量值的简要描述,包括此列包含哪些数据。
unique一个布尔值,表示此列具有唯一值。
sample_values此列的示例值(如果有)。可以添加任何可能在用户问题中被引用的值。
以下字段是可选字段。如果未包含,则默认为 public_access。
access_modifierSupported only for semantic views. The possible values are
public_accessandprivate_access. If this is set toprivate_access, the fact is accessible in the semantic view, but not by end users.
筛选器¶
筛选器表示用于筛选的 SQL 表达式。它有以下字段:
必填
name此筛选器的描述性名称。
expr此筛选器的 SQL 表达式,引用逻辑列。
可选
这些字段不是必需字段,但应尽可能包含这些字段。
synonyms用于指代此筛选器的其他术语/短语的列表。在这个语义模型的所有同义词中,必须是唯一的。
description关于此筛选器的简要描述,包括此筛选器通常用途的详细信息。
指标¶
A metric describes quantifiable measures of business performance, such as total revenue, average order value, or customer count. Metrics can be regular metrics or derived metrics.
常规指标 的作用域为逻辑表,可以引用同一逻辑表中的逻辑列(事实、维度或时间维度),也可以引用语义模型内其他逻辑表中的逻辑列。在语义模型中,
metric元素位于table元素中。 常规指标使用聚合函数和窗口函数来计算表的总体值。Derived metrics (which are supported only for semantic views) are scoped to the semantic view and provide a way of combining other metrics. In the semantic model, the
metricelement is inside thesemantic_modelelement. You can refer only to other metrics (including other derived metrics) in the metric's expression.
Metrics have the following fields.
必填
nameA descriptive name for this metric. This name deterines whether it is a regular metric.
必须是唯一的,并遵循 未加引号的标识符要求。它也不能与 Snowflake 保留的关键字 冲突。
expr此列的 SQL 表达式。表达式的格式取决于指标是常规指标还是派生指标。
Regular metrics, which are scoped to a table, reference a logical column (fact, dimension, or time dimension) in the same logical table or a logical column from another logical table in the semantic model and use aggregate or window functions to calculate overall values.
派生指标是标量表达式,可以引用常规指标或其他派生指标。
可选
The following fields are not required, but should be included whenever possible.
synonymsA list of other terms/phrases used to refer to this metric. Each synonym must be unique across all synonyms in the semantic model.
description此指标的简要说明,包括此列包含的数据。
sample_values此列的示例值(如果有)。可以添加任何可能在用户问题中被引用的值。
以下字段是可选字段。如果未包含,则默认为 public_access。
access_modifierSupported only for semantic views. The possible values are
public_accessorprivate_access. If this is set toprivate_access, the metric is accessible in the semantic view, but not by end users.
基表¶
基表用于表示完全限定的表名称。这是逻辑表映射到的物理表。它有以下字段:
必填
database数据库的名称。
schema架构的名称。
table表的名称。
主键¶
主键表示唯一表示表的每行的列。如果在关系中使用表,则主键是必需的。它有以下字段:
必填
columns唯一表示表的维度列的列表。
关系¶
定义逻辑表之间的联接关系。为了确保正确的联接功能,必须为关系涉及的表定义主键。它具有以下字段:
必填
name关系的唯一标识符。
left_table先前在 YAML 文件中定义的逻辑表名称。对于多对一关系,左表应该是关系的多个方面,以获得出色性能。
right_table先前在 YAML 文件中定义的逻辑表名称。对于多对一关系,右表必须是关系的一个方面,以获得出色性能。
relationship_columns表示联接路径的每个左表和右表中相等列的列表。
join_typeleft_outer或inner。Do not specify this for semantic views.
relationship_typemany_to_one或one_to_one。Do not specify this for semantic views. Instead, use unique or primary keys in the logical tables to indicate that the relationship should be many-to-one or one-to-one.
经过验证的查询¶
请参阅 Cortex Analyst 验证查询存储库,了解 YAML 文件中此节的用途和结构。
自定义指令¶
For information about custom instructions, see Cortex Analyst 中的自定义指令.