成本归因¶
组织可以将使用 Snowflake 的成本分摊到组织内的逻辑单元(例如,分摊到不同的部门、环境或项目)。这种计费分摊或成本展示模式有助于进行会计核算,并能明确指出组织中可通过管控和优化来降低成本的领域。
要将成本归因于不同的组(如部门或项目),请使用以下推荐的方法:
成本归因场景类型¶
以下是最常见的成本归因场景。在这些场景中,仓库作为产生成本的资源的示例。
单个成本中心或部门专用的资源: 例如,使用对象标签将仓库与部门相关联。您可以使用这些对象标签将这些仓库产生的成本完全归因于该部门。
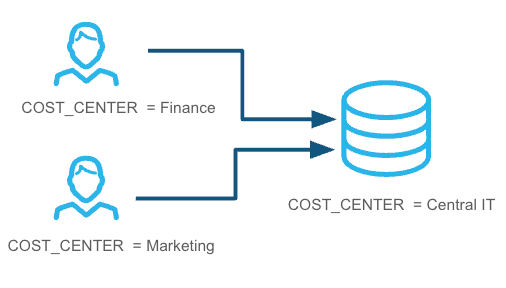
由多个部门的用户共享的资源: 例如,由不同部门的用户共享的仓库。在这种情况下,您可以使用对象标签将每个用户与部门相关联。查询成本归因于用户。通过分配给用户的对象标签,您可以按部门细分成本。
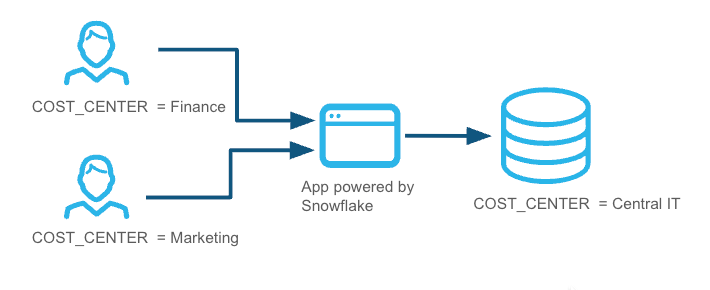
由不同部门的用户共享的应用程序或工作流: 例如,代表其用户发出查询的应用程序。在这种情况下,应用程序执行的每个查询都会获分配一个查询标签,用于标识代表其进行查询的用户的团队或成本中心。
后续章节将介绍如何在账户中设置对象标签,并提供每个成本归因场景的详细信息。
为成本归因设置对象标签¶
当设置标签来表示要用于成本归因的分组时,应确定这些分组是适用于单个账户还是多个账户。这决定了您设置标签的方式。
例如,假设您希望根据部门对成本进行归因。
如果部门使用的资源位于单个账户中,则要在该账户的数据库中创建标签。
如果部门使用的资源涉及多个账户,则要在组织的关键账户中(例如,在 组织账户 中):ref:
创建标签 <label-cost_attribute_tag_create>,并通过 复制 使这些标签在其他账户中可用。
后续章节将介绍如何创建标签、复制标签以及将标签应用于资源。
备注
这些章节中的示例使用自定义角色 tag_admin,假定该角色已获得创建和管理标签的权限。在您的组织内,您可以使用更精细的 Object Tagging 权限 来制定安全标记策略。
复制标签数据库¶
如果您的组织具有多个账户,并且希望使标签在这些其他账户中可用,则可以在主账户中(例如,在 组织账户 中):doc:设置要复制的账户 </user-guide/account-replication-config> 和 创建复制组。设置此复制组以复制包含标签的数据库。
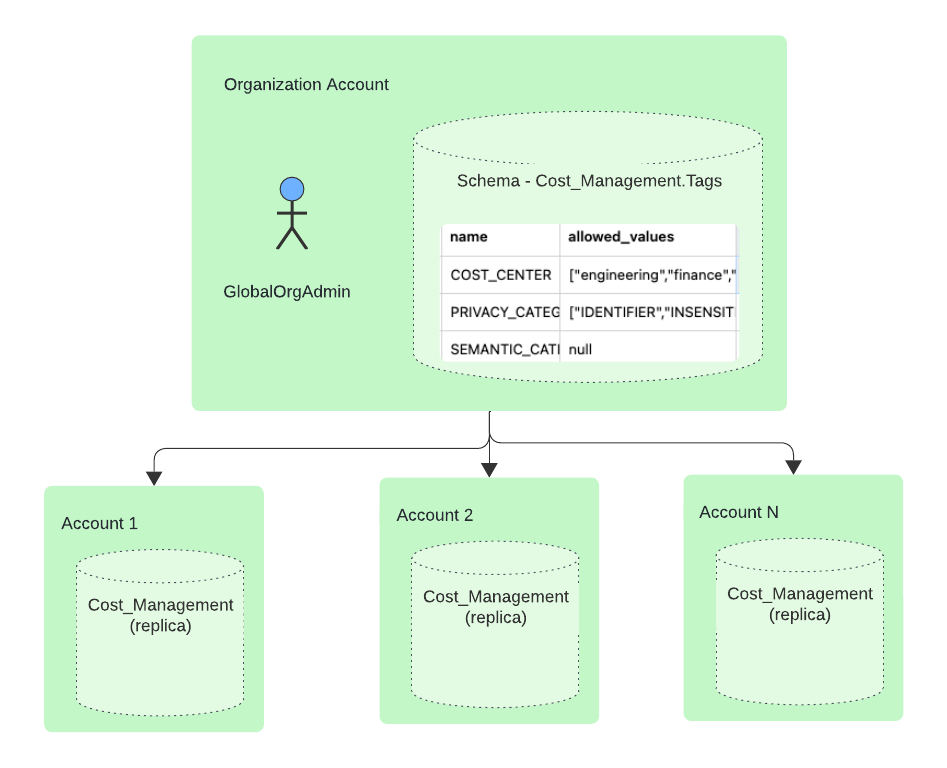
例如,要将标签复制到名为 my_org.my_account 和 my_org.my_account_2 的账户中,请在组织账户中执行以下语句:
然后,在要使标签可用的每个账户中,创建一个辅助复制组,并从主组中刷新此组:
标记资源和用户¶
创建并复制标签后,您可以使用这些标签来识别属于每个部门的仓库和用户。例如,因为销售部门同时使用 warehouse1 和 warehouse2,所以您可以为两个仓库将 cost_center 标签设置为 'SALES'。
小技巧
理想情况下,您应该具有在创建资源和用户时自动执行应用这些标签过程的工作流。
在 SQL 中按标签查看成本¶
您可以对账户内的成本或组织内各账户的成本进行归因:
对账户内的成本进行归因
您可以通过查询以下 ACCOUNT_USAGE 架构中的视图来对账户内的成本进行归因:
TAG_REFERENCES 视图:标识具有标签的对象(例如,仓库和用户)。
WAREHOUSE_METERING_HISTORY 视图:提供仓库的 Credit 使用量。
QUERY_ATTRIBUTION_HISTORY 视图:提供查询的计算成本。每查询成本是执行查询的仓库 Credit 使用量。
有关使用此视图的更多信息,请参阅 关于 QUERY_ATTRIBUTION_HISTORY 视图。
对组织内各账户的成本进行归因
在组织内,您还可以通过从 组织账户 查询 ORGANIZATION_USAGE 架构中的视图,对 仅由单个部门 使用的资源的成本进行归因。
备注
在 ORGANIZATION_USAGE 架构中,TAG_REFERENCES 视图仅在组织账户中可用。
QUERY_ATTRIBUTION_HISTORY 视图仅在账户的 ACCOUNT_USAGE 架构中可用。没有组织级别的等效视图。
后续章节将介绍如何为一些 常见的成本归因场景 归因成本:
部门不共享的资源¶
假设您要按部门对成本进行归因,并且每个部门都使用一组专用仓库。
如果用 cost_center 标签标记仓库以识别拥有仓库的部门,则可以在 object_id 和 warehouse_id 列上将 ACCOUNT_USAGE TAG_REFERENCES 视图 与 WAREHOUSE_METERING_HISTORY 视图 联接,从而按仓库获取使用情况信息,并可以使用 tag_value 列来识别拥有这些仓库的部门。
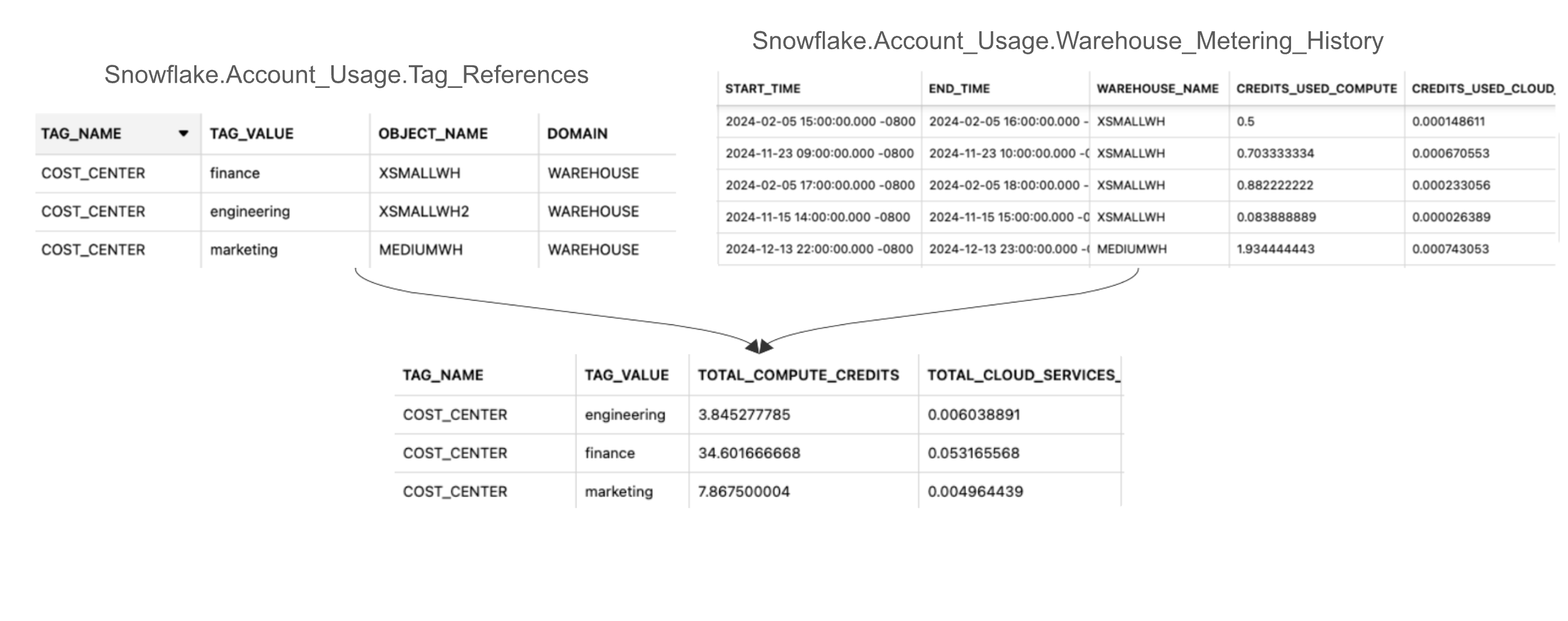
以下 SQL 语句执行此联接:
您可以运行类似的查询,使用 组织账户 的 ORGANIZATION_USAGE 架构中的视图对组织中的所有账户执行相同的归因。查询的其余部分不会更改。
不同部门的用户共享的资源¶
假设不同部门中的用户共享相同的仓库,并且您想要细分每个部门使用的 Credit。您可以使用 cost_center 标签标记用户来识别他们所属的部门,并且可以将 TAG_REFERENCES 视图 与 QUERY_ATTRIBUTION_HISTORY 视图 联接。
备注
一次只能获取一个账户的相关数据。您无法在组织内跨账户执行查询来检索相关数据。
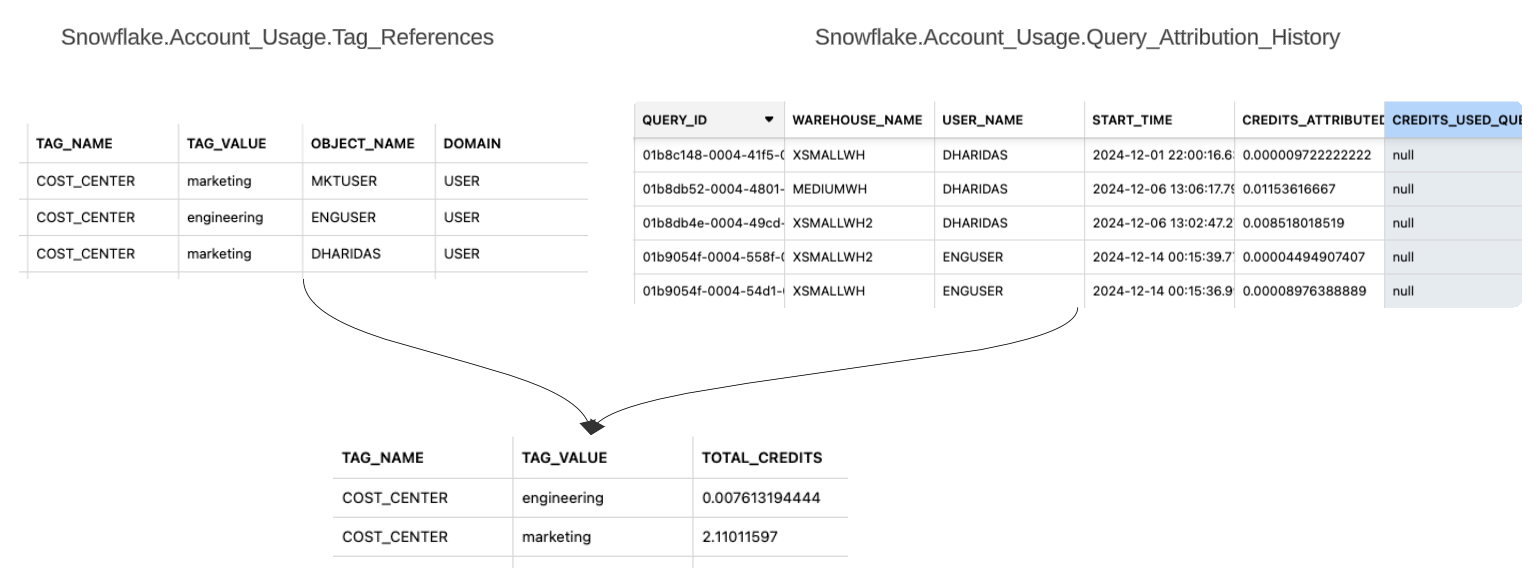
后续章节提供了 SQL 语句示例来对共享资源的成本进行归因。
计算上个月的用户查询成本¶
以下 SQL 语句计算了上个月的成本。
在此示例中,在用户中按其使用量比例 分配空闲时间。
按部门计算用户查询成本(不考虑空闲时间)¶
以下示例通过该部门中的用户执行的查询将计算成本归因于每个部门。此查询取决于具有识别其部门的标签的用户对象。
按用户计算查询成本(不考虑空闲时间)¶
以下 SQL 语句计算了过去一个月(不包括空闲时间)每位用户的成本。
需要将成本归因于不同部门的应用程序使用的资源¶
本节中的示例计算了由 Snowflake 提供支持的一个或多个应用程序的成本。
这些示例假定这些应用程序设置了查询标签,用于识别执行的所有查询的应用程序。要为会话中的查询设置查询标签,请执行 ALTER SESSION 命令。例如:
这会将 COST_CENTER=finance 标签与会话期间执行的所有后续查询相关联。
然后,您可以使用查询标签将这些查询产生的成本追溯到相应部门。
后续章节提供了使用此方法的示例。
按部门计算查询成本¶
以下示例计算了财务部门的计算 Credit 以及用于 Query Acceleration Service 的 Credit。这取决于 COST_CENTER=finance 查询标签是否应用于执行的原始查询。
请注意,成本 不包含 空闲时间。
按查询标签计算查询成本(不包括空闲时间)¶
以下示例按查询标签计算查询成本,并包括不带标签(标识为“未标记”)的查询。
按查询标签计算查询成本(包括空闲时间)¶
以下示例根据部门对仓库的使用比例,将未在每个查询成本中捕获的空闲时间分配给各个部门。
在 Snowsight 中按标签查看成本¶
可以根据具有 cost_center 标签的资源的使用情况生成报告,以将成本归因。您可以在 Snowsight 中访问相关数据。
切换到具有 :ref:` ACCOUNT_USAGE 架构访问权限 <label-enabling_usage_for_other_roles>` 的角色。
在导航菜单中,选择 Admin » Cost management。
选择 Consumption。
从 Tags 下拉列表中选择
cost_center标签。要关注特定成本中心,请从标签的值列表中选择一个值。
选择 Apply。
有关在 Snowsight 中进行筛选的更多详细信息,请参阅 按标签筛选。
关于 QUERY_ATTRIBUTION_HISTORY 视图¶
您可以使用 QUERY_ATTRIBUTION_HISTORY 视图 根据查询来归因成本。每查询成本是执行查询的仓库 Credit 使用量。此成本不包括因查询执行而产生的任何其他 Credit 使用量。例如,下列内容不包括在查询成本中:
数据传输成本
存储成本
云服务成本
无服务器功能的成本
AI 服务处理的词元的成本
对于并发执行的查询,仓库的成本归因于基于给定时间间隔内资源使用量的加权平均值的单个查询。
每查询成本不包括仓库 空闲时间。空闲时间是在仓库中没有运行查询的时间段,可以在仓库级别进行测量。
其他查询示例¶
后续章节提供了可用于成本归因的其他查询:
对相似查询进行分组¶
对于经常性或类似查询,请使用 query_hash 或:code:query_parameterized_hash 按查询对成本进行分组。
要查找当月最昂贵的经常性查询,请执行以下语句:
有关基于查询 ID 的其他查询,请参阅 示例。
对分层查询成本进行归因¶
对于发出多个层次查询的存储过程,您可以使用程序的根查询 ID 计算程序的归因查询成本。
要查找存储过程的根查询 ID,请使用 ACCESS_HISTORY 视图。例如,要查找存储过程的根查询 ID,请设置
query_id并执行以下语句:有关更多信息,请参阅 使用存储过程的祖先查询。
要计算整个程序的查询成本之和,请替换
<root_query_id>并执行以下语句: