使用 Query Acceleration Service¶
Query Acceleration Service (QAS) 可以加速仓库中的部分查询工作负载。当为仓库启用此功能时,此功能可以通过减少异常查询的影响来提高整体仓库性能,异常查询是比典型查询使用更多资源的查询。Query Acceleration Service 通过将查询处理工作的一部分卸载到由服务提供的共享计算资源来实现这一点。
可能受益于 Query Acceleration Service 的工作负载类型示例包括:
临时分析。
每个查询的数据量不可预测的工作负载。
具有大型扫描和选择性筛选器的查询。
Query Acceleration Service 可以通过并行执行更多工作并减少扫描和筛选所花费的挂钟时间,从而更有效地处理这些类型的工作负载。
备注
Query Acceleration Service 取决于服务器的可用性。因此,性能改进可能会随着时间的推移而波动。
QAS 可以加速的 SQL 命令¶
Query Acceleration Service 支持以下 SQL 命令:
SELECT
INSERT
CREATE TABLE AS SELECT (CTAS)
COPY INTO <table>
在受支持的 SQL 命令中,如果命令符合加速条件,则 QAS 可以加速整个查询或查询中的子查询或子句。
启用 Query Acceleration¶
要启用查询加速服务,请使用 CREATE WAREHOUSE 或 ALTER WAREHOUSE 命令指定子句 ENABLE_QUERY_ACCELERATION = TRUE。
示例¶
以下示例为名为 my_wh 的新仓库以及最初在 QAS 关闭状态下创建的名为 my_other_wh 的仓库启用查询加速服务:
运行 SHOW WAREHOUSES 命令以显示有关 my_wh 仓库的详细信息。以下查询使用 竖线操作符 (->>) 仅返回 SHOW 输出中与 QAS 处理相关的列的信息:
Query Acceleration Service 可以提高仓库的 credit 消耗率。最大比例因子可以帮助限制消耗速率。要了解如何指定 QUERY_ACCELERATION_MAX_SCALE_FACTOR 属性,请参阅 调整比例因子。您可以使用 CREATE WAREHOUSE 和 ALTER WAREHOUSE 命令执行此操作。
QUERY_ACCELERATION_ELIGIBLE 视图和 SYSTEM$ESTIMATE_QUERY_ACCELERATION 函数在为仓库确定适当的比例因子时可能很有用。有关详细信息,请参阅 确定可能受益于 Query Acceleration 的查询和仓库 (本主题内容)。
确定可能受益于 Query Acceleration 的查询和仓库¶
To identify the queries or warehouses that might benefit from the query acceleration service, you can query the QUERY_ACCELERATION_ELIGIBLE view. You can also use the SYSTEM$ESTIMATE_QUERY_ACCELERATION function to assess whether a specific query is eligible for acceleration.
符合条件的查询¶
一般来说,查询是符合条件的,因为它们有一部分查询计划可以使用 QAS 计算资源并行运行。这些查询符合以下模式:
使用聚合或选择性筛选器进行大型扫描。
Snowflake doesn't have a specific cutoff for what constitutes a "large enough" scan to be eligible. The threshold for eligibility depends on a variety of factors, including the query plan and warehouse size. Snowflake only marks a query as eligible if there is high confidence that the query would be accelerated if QAS was enabled. Over time, Snowflake is expanding the query patterns that are eligible for acceleration. For example, formerly QAS didn't accelerate queries with a LIMIT clause and no ORDER BY clause, but now Snowflake automatically determines whether such queries can benefit from QAS.
查询不符合条件的常见原因¶
某些查询不符合 Query Acceleration 的条件。以下是无法加速查询的常见原因:
There aren't enough partitions in the scan. If there aren't enough partitions to scan, the benefits of query acceleration are offset by the latency in acquiring resources for the query acceleration service.
即使查询具有筛选器,筛选器的选择性也可能不够。或者,如果查询具有与 GROUP BY 的聚合,则 GROUP BY 表达式的基数可能过高,不符合条件。
The query includes a LIMIT clause that prevents acceleration. QAS automatically determines which queries with LIMIT clauses (including those without ORDER BY) can be accelerated.
使用 SYSTEM$ESTIMATE_QUERY_ACCELERATION 函数确定查询¶
SYSTEM$ESTIMATE_QUERY_ACCELERATION 函数可以帮助确定先前执行的查询是否可能受益于 Query Acceleration Service。如果查询符合 Query Acceleration 条件,则该函数返回不同 Query Acceleration 比例因子 的估计查询执行时间。
示例¶
执行以下语句可帮助确定 Query Acceleration 是否可能有利于特定查询:
In this example, the query is eligible for the query acceleration service. The result value includes estimated
query times using the service. The ineligibleReason property is empty.
以下示例显示不符合 Query Acceleration Service 条件的查询的结果:
The statement above produces the following output. The estimated query times are blank.
The ineligibleReason property reports why the query didn't use QAS.
使用 QUERY_ACCELERATION_ELIGIBLE 视图确定查询和仓库¶
Query the QUERY_ACCELERATION_ELIGIBLE view to identify the queries and warehouses that might benefit the most from the query acceleration service. For each query, the view includes the amount of query execution time that is eligible for the query acceleration service.
示例¶
备注
这些示例假定 ACCOUNTADMIN 角色(或被授予了共享 SNOWFLAKE 数据库 :ref:` IMPORTED PRIVILEGES <label-enabling_usage_for_other_roles>` 的角色)正在使用。如果未使用,请在运行示例中的查询之前执行以下命令:
根据符合加速条件的查询执行时间量,确定过去一周可能从服务中获益最多的查询:
确定过去一周中可能从特定仓库 mywh 的服务中获益最多的查询:
确定过去一周内符合 Query Acceleration Service 条件的查询最多的仓库:
确定上周符合 Query Acceleration Service 条件的时间最长的仓库:
确定仓库 mywh 的 Query Acceleration Service 在过去一周的上限 比例因子:
确定仓库 mywh 的 Query Acceleration Service 在过去一周的比例因子分布:
调整比例因子¶
比例因子是一种 成本控制 机制,它允许您设置仓库可以为 Query Acceleration 租用的计算资源量的上限。此值用作基于仓库大小和成本的乘数。
例如,假设您将中型仓库的比例因子设置为 5。这意味着:
该仓库可以租用高达中型仓库 5 倍大小的计算资源。
由于中型仓库的成本为 每小时 4 个 credit,因此租赁这些资源的成本可能高达每小时 20 个 credit(每个仓库 4 个 credit x 其大小的 5 倍)。
小技巧
比例因子将应用于整个仓库,无论是单集群还是多集群仓库皆适用。如果您将 QAS 用于多集群仓库,请考虑增加比例因子。这样一来,所有仓库集群都可以利用 QAS 优化。
无论同时有多少查询使用 Query Acceleration Service,成本都是相同的。Query Acceleration Service 仅在使用时按秒计费。这些 credit 与仓库使用量分开计费。
并非所有查询都需要比例因子提供的全套资源。服务请求的资源量取决于有多少查询符合加速条件,以及将处理多少数据来回答相应查询。无论比例因子值或请求的资源量如何,用于 Query Acceleration 的可用计算资源量都受到服务中资源的可用性和其他并发请求的数量的约束。Query Acceleration Service 仅使用所需的资源以及执行查询时可用的资源。
如果未显式设置比例因子,则默认值为 8。将比例因子设置为 0 可以消除上限限制,并允许查询根据需要租用尽可能多的资源来为查询提供服务。
示例¶
下面的示例修改名为 my_wh 的仓库,以启用最大比例因子为 0 的 Query Acceleration Service。
监控 Query Acceleration Service 使用情况¶
This section describes how to monitor the usage of the query acceleration service. By monitoring, you can understand the performance impact, identify which queries benefit most from acceleration, and assess the overall effectiveness of the feature. Doing so can help you manage your costs and optimize your workloads.
使用 Web 界面监控 Query Acceleration 使用情况¶
启用 Query Acceleration Service 之后,您可以在 Query Profile 选项卡 中查看 Profile Overview 面板,以了解查询加速结果的效果。
下面的屏幕截图显示了为整个查询显示的统计信息的示例。如果对查询中的多个操作进行了加速,则会在此视图中汇总结果,以便您可以查看 Query Acceleration Service 完成的工作总量。
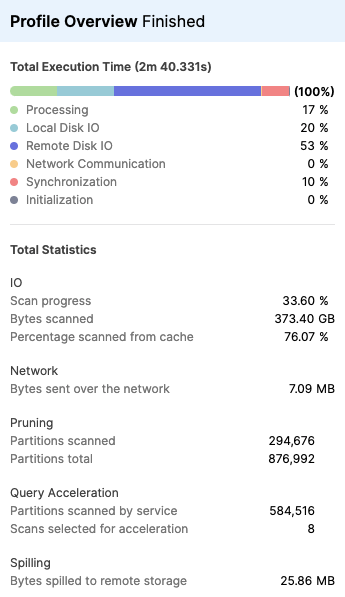
Profile Overview 面板的 Query Acceleration 部分包括以下统计数据:
服务扫描的分区数 – 为扫描而卸载到 Query Acceleration Service 的文件数。
为加速选择的扫描次数 – 正在加速的表扫描次数。
在操作员详细信息(请参阅 统计信息)中,点击操作员以查看详细信息。以下屏幕截图显示了为 TableScan 操作显示的统计信息的示例:
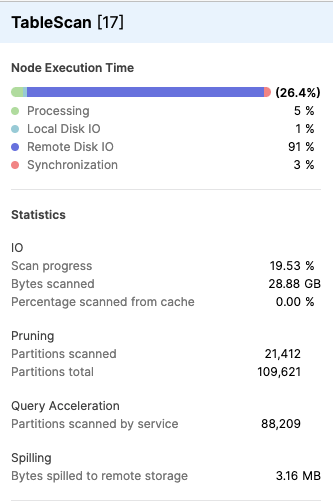
TableScan 详细信息面板的 Query Acceleration 部分包括以下统计信息:
服务扫描的分区数 – 为扫描而卸载到 Query Acceleration Service 的文件数。
使用 Account Usage QUERY_HISTORY 视图监控 Query Acceleration 使用情况¶
要查看 Query Acceleration 对查询的影响,可以使用 QUERY_HISTORY 视图 中的以下列。
QUERY_ACCELERATION_BYTES_SCANNED
QUERY_ACCELERATION_PARTITIONS_SCANNED
QUERY_ACCELERATION_UPPER_LIMIT_SCALE_FACTOR
您可以使用这些列来确定从 Query Acceleration Service 中受益的查询。对于每个查询,您还可以确定 Query Acceleration Service 扫描的分区和字节总数。
有关这些列中每一列的说明,请参阅 QUERY_HISTORY 视图。
备注
对于给定的查询,使用 Query Acceleration Service 时 QUERY_ACCELERATION_BYTES_SCANNED 和 BYTES_SCANNED 列的总和可能大于不使用该服务时的总和。列 QUERY_ACCELERATION_PARTITIONS_SCANNED 和 PARTITIONS_SCANNED 的总和也是如此。
字节和分区数量的增加是由于服务生成的中间结果,以促进 Query Acceleration。
例如,要查找 Query Acceleration Service 在过去 24 小时内扫描的字节数最多的查询:
要查找 Query Acceleration Service 在过去 24 小时内扫描的分区数最多的查询:
Query Acceleration Service 成本¶
Query Acceleration 消耗 credit,因为它使用 无服务器计算资源 来执行符合条件的查询的部分。
Query Acceleration 与 Snowflake 中的其他无服务器功能一样,按秒为所使用的计算资源付费。要了解 Query Acceleration Service 每个计算小时使用了多少 credit,请参阅 `Snowflake 服务使用表 `_ 中的“无服务器功能 credit 表”。
Viewing billing information in Snowsight¶
If you have Query Acceleration enabled for your account, use the Cost Management page in Snowsight to view billing information for the Query Acceleration Service.
To see Query Acceleration Service spending, complete the following steps:
Sign in to Snowsight.
In the navigation menu, select Admin » Cost management.
Select the Consumption tab.
Select Query Acceleration from the Service Type drop-down.
Snowsight displays the Query Acceleration Service spending for your account.
使用 Account Usage QUERY_ACCELERATION_HISTORY 视图查看计费¶
您可以在 Account Usage QUERY_ACCELERATION_HISTORY 视图 中查看计费数据。
示例¶
此查询返回您的账户中每个仓库月初至今用于 Query Acceleration Service 的 Credit 总数:
使用 Organization Usage QUERY_ACCELERATION_HISTORY 视图查看计费¶
您可以在 Organization Usage QUERY_ACCELERATION_HISTORY 视图 中查看组织中所有账户的 Query Acceleration Service 的计费数据。
示例¶
此查询返回每个账户中每个仓库月初至今用于 Query Acceleration Service 的总 credit:
使用 QUERY_ACCELERATION_HISTORY 函数查看计费¶
您还可以使用 Information Schema QUERY_ACCELERATION_HISTORY 函数查看计费数据。
示例¶
以下示例使用 QUERY_ACCELERATION_HISTORY 函数返回有关此服务在过去 12 小时内加速的查询的信息:
评估成本和性能¶
本节包括示例查询,这些查询可能有助于您评估启用 Query Acceleration Service 前后的查询性能和成本。
查看仓库和 Query Acceleration Service 成本¶
下面的查询计算特定仓库的仓库和 Query Acceleration Service 的成本。您可以在为仓库启用 Query Acceleration Service 后执行此查询,以比较启用 Query Acceleration 前后的成本。查询的日期范围从首次使用 Query Acceleration Service credit 前 8 周开始,到最后一次产生 Query Acceleration Service 费用后 8 周(或截至当前日期)。
备注
如果仓库属性和工作负载在启用 Query Acceleration Service 之前和之后相同,则此查询对于评估服务成本非常有用。
仅当仓库中存在用于加速查询的 Credit 使用量时,此查询才返回结果。
此示例查询返回仓库和 my_warehouse 的 Query Acceleration Service 成本:
查看查询性能¶
此查询返回给定仓库的符合 Query Acceleration 条件的查询的平均执行时间。查询的日期范围从首次使用 Query Acceleration Service credit 前 8 周开始,到最后一次产生 Query Acceleration Service 费用后 8 周(或截至当前日期)。这些结果可能有助于您评估启用 Query Acceleration Service 后平均查询性能的变化。
备注
如果仓库工作负载在启用 Query Acceleration Service 之前和之后保持不变,则此查询对于评估查询性能最有用。
如果仓库工作负载保持稳定,
num_execs列中的值应该保持一致。如果查询结果的
num_execs列中的值急剧增加或减少,则此查询的结果可能对查询性能评估没有用处。
此示例查询按天返回查询执行时间,并计算仓库 my_warehouse 中符合加速条件的查询的前一周的 7 天平均值:
该语句的输出包括以下列:
列 |
描述 |
|---|---|
EXEC_DATE |
查询执行日期。 |
AVG_EXEC_TIME_7DAYS |
前 7 天(含 EXEC_DATE)的平均执行时间。 |
AVG_EXEC_TIME |
平均查询执行时间。 |
QAS_ACCEL_FLAG |
如果加速了任何查询,则为 1;如果没有加速查询,则为 NULL。 |
NUM_EXECS |
加速的查询次数。 |
EXEC_TIME |
所有符合 Query Acceleration 条件的查询的总执行时间。 |
小技巧
When the query acceleration service (QAS) is enabled, Snowflake writes a small amount of data to remote storage
for each eligible query, even if QAS isn't used for that query. Therefore, don't be concerned by a nonzero
value for bytes_spilled_to_remote_storage in the QUERY_HISTORY view when QAS is enabled.
与搜索优化兼容¶
Query Acceleration 和 搜索优化 可以协同工作以优化查询性能。首先,搜索优化可以剪切查询不需要的 微分区。然后,对于 符合条件的查询,Query Acceleration 可以将其余部分工作分流到服务提供的共享计算资源。
这两种服务所加速的查询性能因工作负载和可用资源而异。