Snowpark Migration Accelerator:了解评估摘要¶
运行评估后,您可以在“评估摘要报告”中查看初始结果和摘要。要访问此报告,请点击 查看结果 按钮。
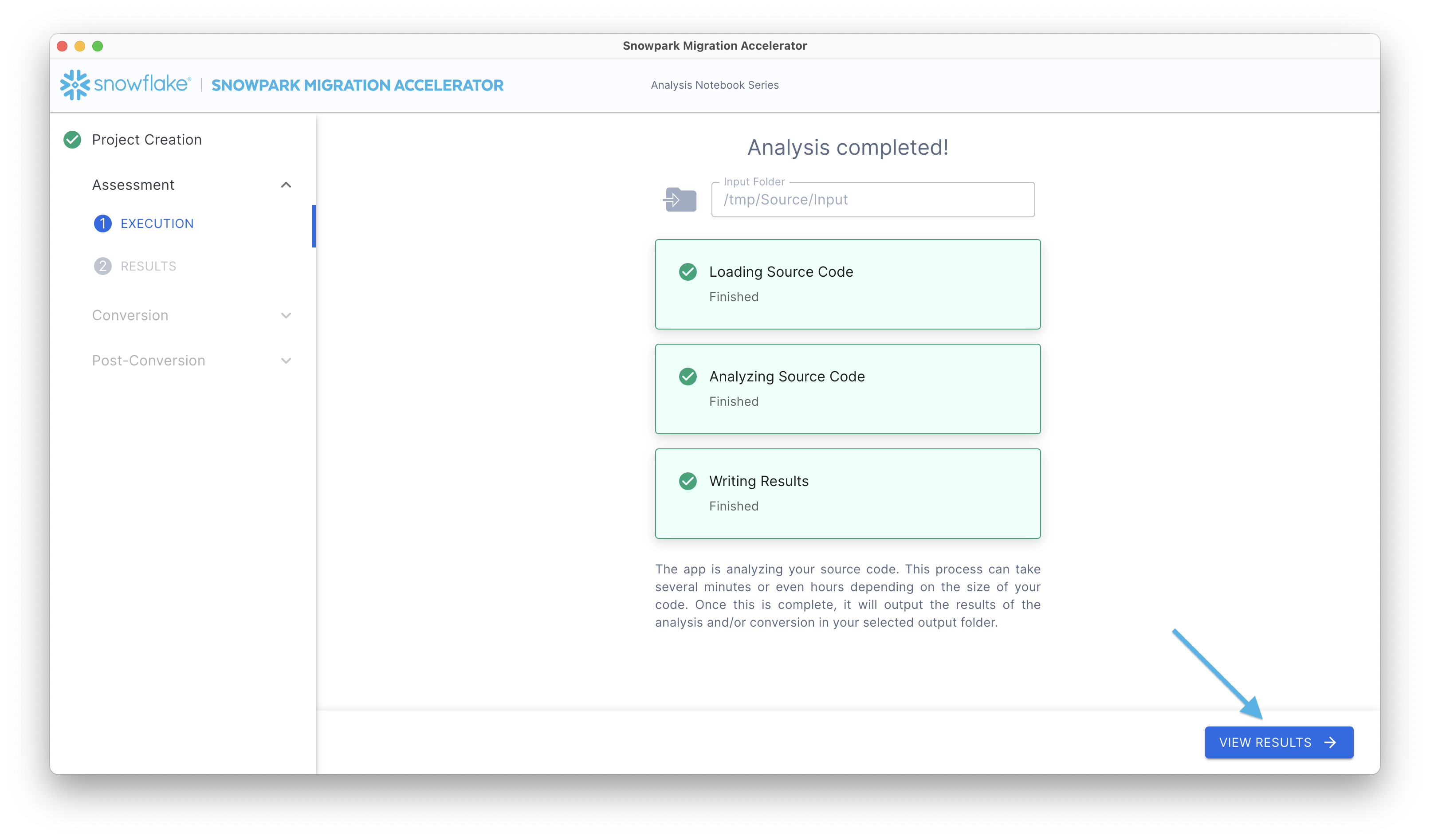
这将显示您的评估报告。请记住,此报告汇总了 SMA 执行期间在 输出报告 文件夹中创建的库存文件中的信息。要进行全面分析,请查看输出目录中的 详细报告。
该应用程序的“评估结果”部分包含多个组件,下文将详细说明这些组件。
标准评估摘要¶
摘要将如下所示:
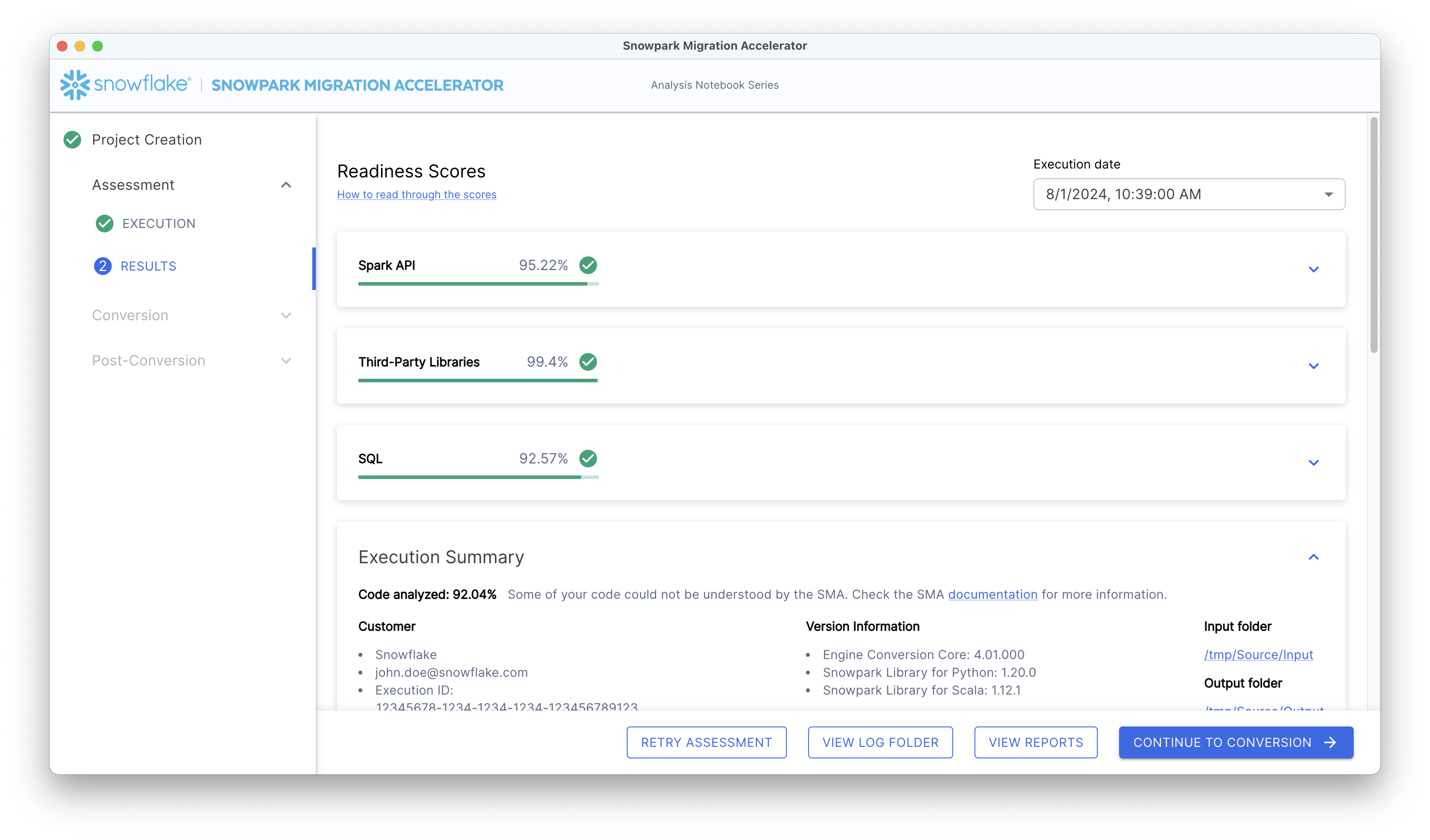
在报告的右上角,有一个日期下拉菜单,显示分析的运行时间。如果您已在同一个项目中多次执行加速器,则下拉菜单将显示多个日期。这些日期仅对应于您当前打开的项目的执行情况。
Snowpark Connect Readiness Score¶
The Snowpark Connect Readiness Score will look something like this:
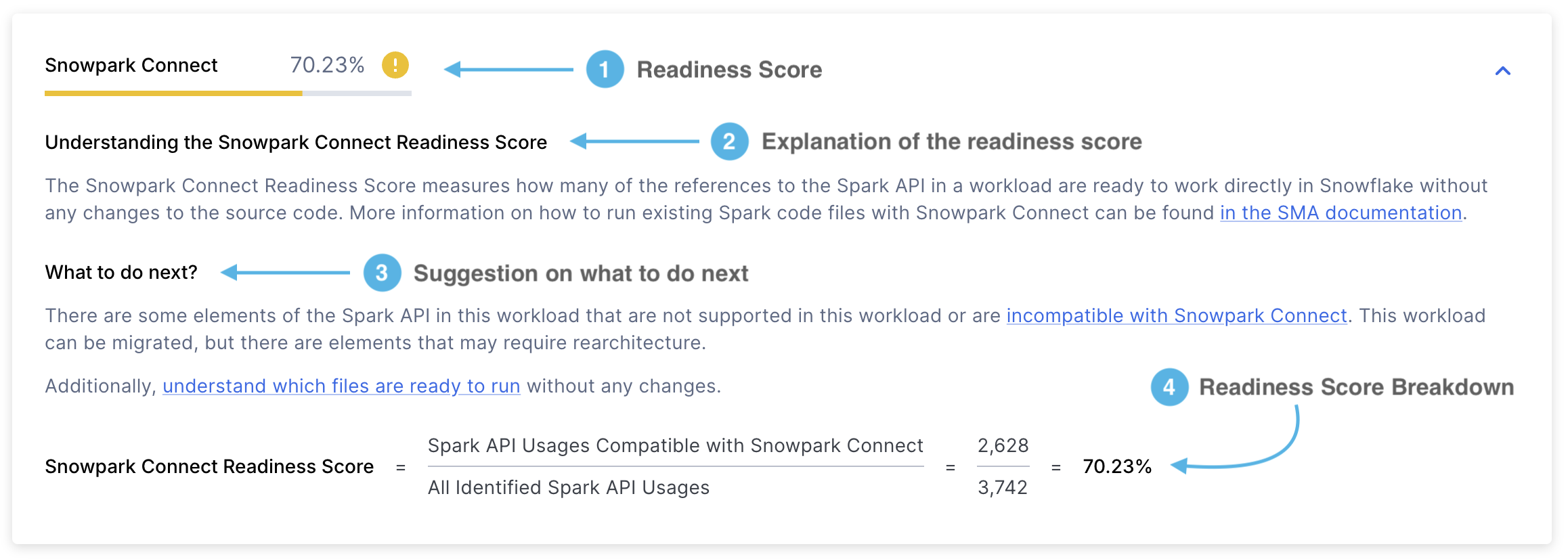
Readiness Score - It will show you the readiness score you obtained. The Snowpark Connect readiness score indicates the proportion of Spark API references that are supported by Snowpark Connect. This score is calculated by dividing the number of supported Spark API references by the total Spark API references. You can learn more about this score in the Snowpark Connect Readiness Score section.
Score Explanation - An explanation of what the Snowpark Connect Readiness score is and how to interpret it.
Next Steps - Depending on the readiness score obtained, the SMA will advise you on what actions you should take before proceeding to the next step.
Score Breakdown - A detailed explanation of how the Snowpark Connect Readiness Score was calculated. In this case, it will show you the number of Spark API references supported by Snowpark Connect divided by the total number of Spark API references.
Supported Usages refers to the number of Spark API references in a workload that are supported by Snowpark Connect. In contrast, identified usages represents the total count of Spark API references found within that workload.
Spark API 就绪度分数¶
该报告包括多个项目,就绪度分数是最重要的指标。
让我们详细研究每个部分:

就绪度分数 – Spark API 就绪度分数 是 SMA 用来评估代码迁移就绪度的主要指标。该分数表示可以转换为 Snowpark API 的 Spark API 引用的百分比。虽然这个分数很有用,但它只考虑了 Spark API 引用,没有考虑第三方库或其他因素。因此,可将其用作初步评估,而不是完整评估。
此分数的计算方法是将可转换 Spark API 引用的数量除以代码中找到的 Spark API 引用总数。例如,如果分数显示 3541/3746,则表示在总共 3746 个引用中,可以转换 3541 个引用。分数越高表示与 Snowpark API 的兼容性越好。您可以在详细报告的第一页上找到这个分数。
Score Explanation - This section provides details about what the Spark API Readiness score means and how to interpret your results.
Next Steps - Depending on the readiness score obtained, the SMA will advise you on what actions you should take before proceeding to the next step.
Score Breakdown - This section shows how your score was calculated using two key metrics:
可转换用量:可以转换为 Snowpark 的 Spark API 引用(函数、元素或导入语句)数量
已识别用量:在您的代码中找到的 Spark API 引用总数
第三方库就绪度分数¶
第三方库就绪度分数将以以下格式显示:
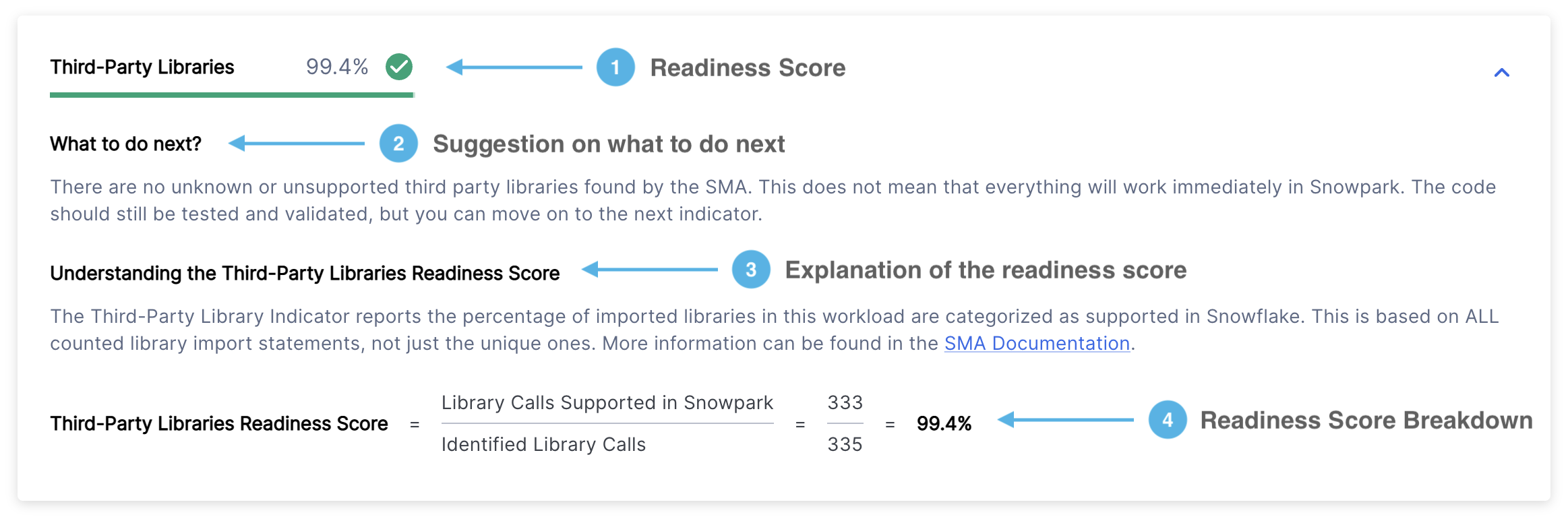
就绪度分数 – 显示您的就绪度分数及其类别(绿色、黄色或红色)。第三方库就绪度分数显示 Snowflake 支持您导入的库的百分比。有关更多详细信息,请参阅 第三方 API 就绪度分数 部分。
Next Steps - Depending on the readiness score obtained, the SMA will advise you on what actions you should take before proceeding to the next step.
分数说明 – 描述第三方库就绪度分数的含义以及如何解释您的结果。
分数明细 – 显示您的第三方库就绪度分数如何使用以下公式计算得出:(Snowpark 支持的库调用次数)÷(已识别的库调用总数)
其中:
“Snowpark 支持的库调用”是指 Snowpark 可以使用的库
“已识别的库调用”是指在您的代码中找到的所有第三方库调用,包括 Spark 和非 Spark 库,无论是否支持
SQL 就绪度分数¶
SQL 就绪度分数将以以下格式显示:
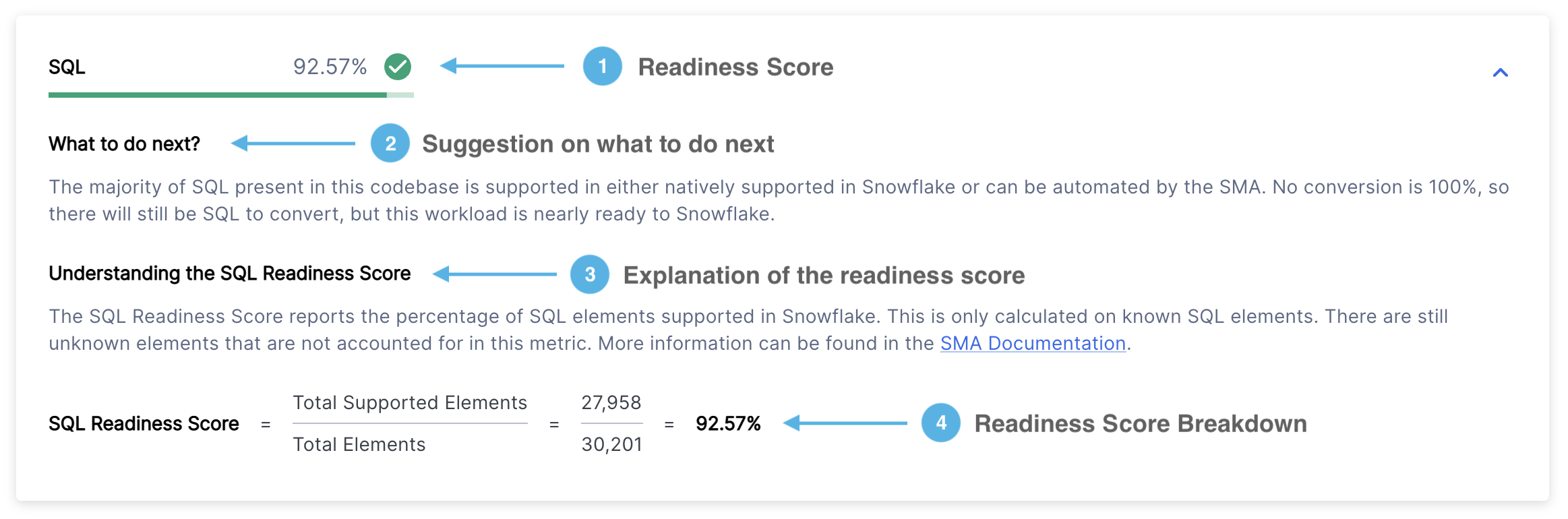
就绪度分数 – 显示您的就绪度分数及其类别(绿色、黄色或红色)。该分数表示您的代码中有多少个 SQL 元素可以成功转换为 Snowflake SQL。有关更多详细信息,请参阅 SQL 就绪度分数 部分。
后续步骤 – 根据您的就绪度分数,SMA 会就在继续之前应执行的操作提供建议。
分数说明 – 清晰解释 SQL 就绪度分数以及如何解读您的结果。
分数明细 – 显示您的 SQL 就绪度分数的详细计算结果,计算方法为:(支持的元素数量)÷(元素总数)。
Spark API 使用情况¶
危险
自版本 2.0.2 起,Spark API 使用情况部分已被弃用。您现在可以找到:
详细报告 中的 Spark API 使用情况摘要
Spark API 使用情况清单 中所有 Spark API 使用实例的完整列表
该报告包含三个主要部分,以选项卡形式显示:
总体使用情况分类
Spark API 使用情况分类
按状态划分的 Spark API 使用情况
我们将在下面详细研究每个部分。
总体使用情况分类¶
此选项卡显示一个包含三行的表格,其中显示:
支持的操作
不支持的操作
总体使用情况统计信息

以下部分提供了其他详细信息:
使用次数 – 您的代码中引用 Spark API 函数的总次数。每次引用都被归类为支持或不支持,总数显示在底部。
至少使用 1 次的文件 – 包含至少一个 Spark API 引用的文件数量。如果此数字小于您的文件总数,则表示某些文件根本不使用 Spark API。
所有文件的百分比 – 显示文件的哪一部分使用 Spark API。计算方法是将使用 Spark API 的文件数除以代码文件总数(以百分比表示)。
Spark API 使用情况分类¶
此选项卡显示在您的代码库中检测到的不同类型的 Spark 引用。它显示了总体就绪度分数(与页面顶部显示的分数相同),并按类别详细列出了该分数。

您可以在 Spark 引用类别 部分找到所有可用的分类。
按状态划分的 Spark API 使用情况¶
最后一个选项卡显示按映射状态组织的分类细分。

SMA 工具使用七种主要映射状态,用于指示 Spark 代码转换为 Snowpark 的顺畅程度。有关这些状态的详细信息,请参阅 Spark 引用类别 部分。
导入调用¶
危险
自版本 2.0.2 起,导入调用 部分已移除。您现在可以找到:
详细报告 中的导入语句摘要
[导入使用情况清单] (output-reports/sma-inventories.md) 中所有导入调用的完整列表
“导入调用”部分显示代码库中常用的外部库导入。请注意,Spark API 导入已在“Spark API”部分中单独介绍,因此本部分不包含相关内容。

此表包含以下信息:
该报告显示以下信息:
一个包含 5 行的表显示:
最常导入的 3 个 Python 库
汇总所有剩余包的“其他”行
显示所有导入总和的“总计”行
“在 Snowpark 中支持”列,用以指示每个库是否包含在 Snowflake 的 Snowpark 支持的包列表 (https://repo.anaconda.com/pkgs/snowflake/) 中。
“导入次数”列,显示每个库在所有文件中导入的次数。
“文件覆盖范围”列,显示包含每个库至少一次导入的文件百分比。例如:
如果“sys”在导入语句中出现 29 次,但仅在 28.16% 的文件中使用,则表明它通常在每个使用它的文件中导入一次。
“其他”类别可能显示在 100% 的文件中导入 56 次。
有关每个文件的详细导入信息,请参阅 输出报告 中的 ImportUsagesInventory.csv 文件。
文件摘要¶
摘要报告包含多个表,这些表显示了按文件类型和大小组织的指标。这些指标可用于深入了解代码库的容量,并帮助估计迁移项目所需的工作量。
Snowpark Migration Accelerator 会分析源代码库中的所有文件,包括代码和非代码文件。您可以在 files.csv 报告中找到有关扫描文件的详细信息。
文件摘要包含多个部分。让我们详细研究每个部分。
文件类型摘要¶
文件类型摘要显示在扫描的代码存储库中找到的所有文件扩展名的列表。

列出的文件扩展名指示 SMA 可以分析哪些类型的代码文件。您在每个文件扩展名中可找到以下信息:
代码行 – 具有此扩展名的所有文件中的可执行代码行总数。此计数不包括注释和空行。
文件数量 – 使用此扩展名找到的文件总数。
占文件总数的百分比 – 带有此扩展名的文件在项目中的所有文件中所占的百分比。
要分析您的工作负载,您可以轻松确定它是否主要由脚本文件(例如 Python 或 R)、笔记本文件(如 Jupyter 笔记本)或 SQL 文件组成。此信息有助于确定项目中代码文件的主要类型。
按语言划分的笔记本大小¶
该工具会评估代码库中的笔记本,并根据它们包含的代码行数为它们分配“T 恤”尺寸(S、M、L、XL)。这种尺寸有助于估计每个笔记本的复杂性和范围。

笔记本的大小根据每个笔记本中使用的主要编程语言进行分类。
按语言划分的笔记本统计数据¶
此表按编程语言显示了所有笔记本中代码行和单元格的总数。

这些笔记本按其中使用的主要编程语言进行组织。
代码文件内容¶
运行 SMA 时,选项卡名称将根据您的源语言而变更:
对于 Python 源文件,该选项卡将显示“Python File Content”
对于 Scala 源文件,该选项卡将显示“Scala File Content”
此行显示了有多少文件包含 Spark API 引用。“Spark 使用情况”行显示:
使用 Spark APIs 的文件数量
这些文件在分析的代码库文件总数中所占的百分比

此指标有助于确定不包含 Spark API 引用的文件百分比。较低的百分比表明许多代码文件缺乏 Spark 依赖关系,这可能意味着迁移工作量可能小于最初估计值。
代码文件大小¶
“File Sizing”选项卡的名称根据您的源语言而变更:
对于 Python 源文件,它显示为“Python File Sizing”
对于 Scala 源文件,它显示为“Scala File Sizing”
代码库文件使用“T 恤”大小(S、M、L、XL)进行分类。每种大小都有在“大小”列中描述的特定标准。该表还显示了所有 Python 文件中属于每个大小类别的百分比。

了解代码库中的文件大小分布有助于评估工作负载的复杂性。较高比例的小文件通常表示工作负载更简单、复杂程度较低。
问题摘要¶
问题摘要提供有关代码扫描期间发现的潜在问题的重要信息。从评估过渡到转换时,您将看到在代码库中检测到的 EWIs(错误、警告和问题)列表。有关这些问题的详细说明,请参阅文档中的“问题分析”部分。
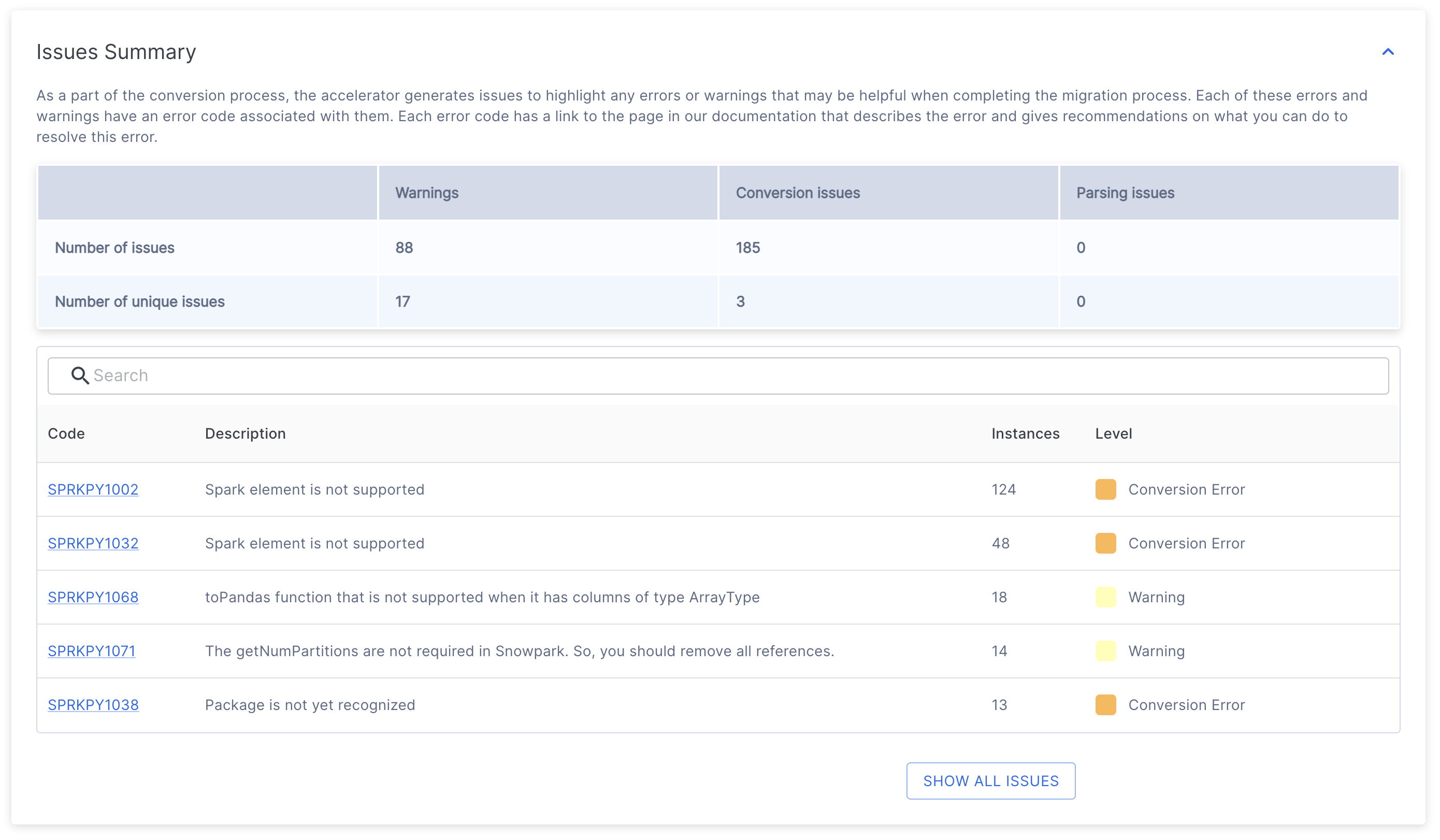
在问题摘要的顶部,您会看到一个表,其中概述了所有已发现的问题。

该表包含两行。
“问题数量”代表每个类别中找到的所有问题代码的总数。
“独特问题数量”表示在每个类别中发现的不同错误代码的数量。
这些问题分为三个主要类别:
警告 表明源平台和目标平台之间的潜在差异,可能不需要立即采取措施,但应在测试期间考虑这些差异。其中可能包括针对边缘用例的细微行为差异,或者关于相较于原平台外观变化的通知。
转换问题 突出显示了无法转换或需要额外配置才能在目标平台上正常运行的元素。
当工具无法解释特定的代码元素时,就会出现 解析问题。这些都是需要立即关注的关键问题,通常是由未编译的源代码或错误的代码提取引起的。如果您认为源代码正确但仍收到解析错误,则可能是由于 SMA 中无法识别的模式所致。在这种情况下,请 报告问题,并包括有问题的源代码部分。
该表汇总了每个项目的总数。
在此表下方,您将找到唯一问题代码及其描述的列表。
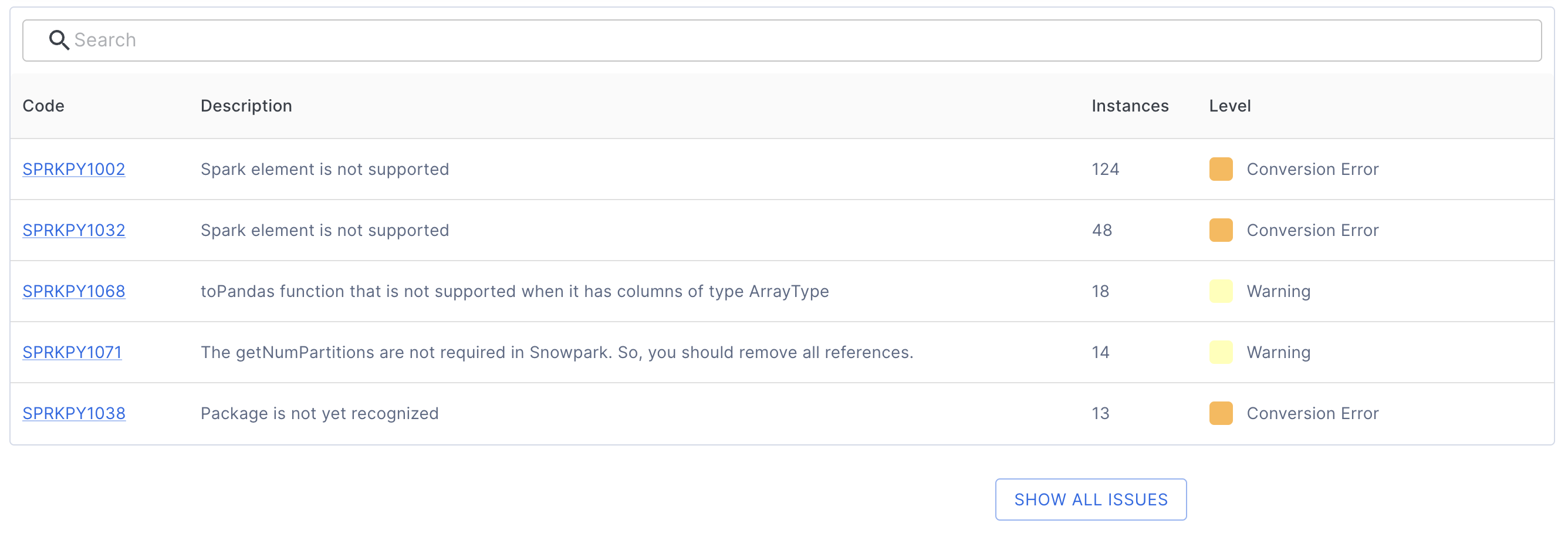
每个问题代码条目都提供:
唯一的问题标识符
问题描述
出现次数
严重性级别(警告、转换错误或解析错误)
您可以点击任何问题代码来查看详细文档,其中包括:
问题的完整描述
示例代码
推荐的解决方案
例如,点击上面显示的第一个问题代码 (SPRKPY1002) 将带您进入其专用文档页面。
默认情况下,该表仅显示前 5 个问题。要查看所有问题,请单击表格下方的 SHOW ALL ISSUES 按钮。您也可以使用表格上方的搜索栏来查找特定问题。
在评估模式中,了解剩余的转换工作至关重要。您可以在 报告文件夹 的问题清单中找到有关每个问题及其位置的详细信息。
执行摘要¶
执行摘要全面概述了该工具的最新分析。它包括:
代码分析分数
用户详细信息
唯一执行 ID
SMA 和 Snowpark API 的版本信息
在 项目创建 期间指定的项目文件夹位置

附录¶
附录包含其他参考信息,可以帮助您更好地理解 SMA 工具生成的输出。

本指南包含有关使用 Snowpark Migration Accelerator (SMA) 的一般参考信息。虽然内容可能会定期更新,但它侧重于 SMA 的通用用法,而不是有关特定代码库的详细信息。
这是大多数用户在运行 Snowpark Migration Accelerator (SMA) 时会看到的内容。如果您使用的是旧版本,则可能会改为看到简短评估摘要,如下所示。
简短评估摘要[已弃用]¶
如果您的就绪度分数较低,则迁移摘要可能如下所示:

此摘要包含以下信息:
执行日期:显示何时执行分析。您可以查看此项目先前执行的任何结果。
结果:根据 就绪度分数 表明您的工作负载是否适合迁移。就绪度分数是初步评估工具,不能保证迁移成功。
输入文件夹:分析的源文件的位置。
输出文件夹:存储分析报告和转换后的代码文件的位置。
文件总数:分析的文件数。
执行时间:分析过程的持续时间。
已识别的 Spark 引用:在您的代码中找到的 Spark API 调用次数。
Python(或 Scala)文件数量:指定编程语言中的源代码文件数。
后续步骤¶
该应用程序提供了几个附加功能,可以通过下图所示的界面访问这些功能。
重试评估 – 您可以通过点击“Assessment Results”页面上的 Retry Assessment 按钮再次运行评估。这在您更改源代码并希望查看更新的结果时非常有用。
查看日志文件夹 – 打开包含评估执行日志的文件夹。这些文本文件提供有关评估过程的详细信息,对于评估失败时的故障排除至关重要。如果您需要技术支持,可能需要共享这些日志。
查看报告 – 打开包含评估输出报告的文件夹。其中包括详细的评估报告、Spark 引用清单以及对源代码库的其他分析。本文档详细说明了每种报告类型。
继续转换 – 虽然这似乎是下一个合乎逻辑的步骤,但在继续之前仔细审查评估结果非常重要。请注意,运行转换需要访问码。有关更多信息,请参阅 本文档的转换部分.
以下页面提供有关该工具每次运行时生成的报告的详细信息。