异常检测(Snowflake ML 函数)¶
概述
异常检测是识别数据中异常值的过程。异常检测功能可让您训练一个模型,以检测时间序列数据中的异常值。异常值(偏离预期范围的数据点)可能会对从数据派生得出的统计数据和模型产生巨大影响。因此,发现和移除异常值有助于提高结果质量。
Note
异常检测是 Snowflake 由机器学习提供支持的业务分析工具套件的一部分。
在没有明显原因的情况下,检测异常值也可用于查明流程中问题或偏差的根源。例如:
- 确定日志记录管道何时开始出现问题。
- 确定 Snowflake 计算成本高于预期的日期。
异常检测适用于单序列或多序列数据。多序列数据表示事件的多个独立线程。例如,如果存在多个商店的销售数据,则可以通过单个模型根据商店标识符分别查看每个商店的销售额。
数据必须包含:
- 时间戳列。
- 目标列,代表每个时间戳下的某些相关数量。
Note
Ideally, the training data for an Anomaly Detection model has time steps at equally spaced intervals (for example, daily). However, model training can handle real-world data that has missing, duplicate, or misaligned time steps. For more information, see Dealing with real-world data in Time-Series Forecasting.
To detect outliers in time-series data, use the Snowflake built-in class ANOMALY_DETECTION (SNOWFLAKE.ML), and follow these steps:
- Create an anomaly detection object, passing in a reference to the training data.
此对象会根据您提供的训练数据拟合模型。该模型是一个架构级对象。
- Using this anomaly detection model object, call the <model_name>!DETECT_ANOMALIES method to detect anomalies, passing in a reference to the data to analyze.
该方法使用模型来识别数据中的异常值。
Anomaly detection is closely related to Forecasting. An anomaly detection model produces a forecast for the same time period as the data you’re checking for anomalies, then compares the actual data to the forecast to identify outliers.
关于异常检测的算法
The anomaly detection algorithm is powered by a gradient boosting machine (GBM). Like an ARIMA model, it uses a differencing transformation to model data with a non-stationary trend and uses auto-regressive lags of the historical target data as model variables.
此外,该算法使用历史目标数据的滚动平均值来帮助预测趋势,并使用时间戳数据自动生成循环日历变量(例如星期几和一年中的一周)。
您可以仅使用历史目标值和时间戳数据拟合模型,也可以加入可能影响目标值的外生数据(变量)。外生变量可以是数值或分类值,也可以是 NULL (不会删除包含 NULLs 外生变量的行)。
在对分类变量进行训练时,该算法不依赖单次编码,因此可以使用多维度(高基数)的分类数据。
如果模型包含外生变量,则在将来检测异常时,必须在时间戳处为这些变量提供值。适当的外生变量包括天气数据(温度、降雨量)、公司特定信息(历史和计划的公司假期、广告活动、活动时间表),或者您认为可能有助于预测目标变量的任何其他外部因素。
也可以选择使用单独的布尔列将单个历史行标记为异常或非异常。
预测区间 是上限和下限内的估算值范围,其中特定数据的百分比可能会下降。例如,值 0.99 表示 99% 的数据可能出现在区间内。异常检测模型会将超出预测区间的任何数据标识为异常。您可以指定预测区间或使用默认值 0.99。您可能希望将此值设置为高度接近于 1.0;如 0.9999 甚至更接近的值。
Important
Snowflake 可能会不时改进异常检测算法。此类改进通过 Snowflake 的常规发布流程推出。您无法恢复到该功能的先前版本,但使用先前版本创建的模型会继续使用该版本进行异常检测。
限制
- You cannot choose or adjust the anomaly detection algorithm. In particular, the algorithm does not provide parameters to override trend, seasonality, or seasonal amplitudes; these are inferred from the data.
- The minimum number of rows for the main anomaly detection algorithm is 12 per time series. For time series with between 2 and 11 observations, anomaly detection produces a “naive” result in which all predicted values are equal to the last observed target value. For the labeled anomaly detection case, the number of observations used is the number of rows where the label column is false.
- 可接受的最小数据粒度为一秒。(时间戳之间的间隔不得短于一秒。)
- The minimum granularity of seasonal components is one minute. (The function cannot detect cyclic patterns at smaller time deltas.)
- The “season length” of autoregressive features is tied to the input frequency (24 for hourly data, 7 for daily data, and so on).
- Anomaly detection models, once trained, are immutable. You cannot update existing models with new data; you must train an entirely new model. Models do not support versioning. Generally, you should retrain models on a regular cadence, such as once a day, once a week, or once a month, depending on how frequently you receive new data, to help the model keep up with changing trends.
- This feature only detects anomalies in the test data; it cannot detect anomalies in the training data. Furthermore, timestamps in the test data must all be greater than timestamps in the training data. Ensure that the training data covers a typical period free of actual outliers, or label known outliers in a Boolean column.
- 您无法克隆模型或跨角色或账户共享模型。克隆架构或数据库时,将会跳过模型对象。
- You cannot replicate an instance of the ANOMALY_DETECTION class.
异常检测准备工作
在使用异常检测之前,您必须:
- Select a virtual warehouse in which to train and run your models.
- Grant the privileges to create anomaly detection objects.
You might also want to modify your search path to include SNOWFLAKE.ML.
选择虚拟仓库
A Snowflake virtual warehouse provides the compute resources for training and using your machine learning models for this feature. This section provides general guidance on selecting the best size and type of warehouse for this purpose, focusing on the training step (the most time-consuming and memory-intensive part of the process).
单序列数据训练
For models trained on single-series data, you should choose the warehouse type based on the size of your training data. Standard warehouses are subject to a lower Snowpark memory limit, and are more appropriate for training jobs with fewer rows or exogenous features. If your training data does not contain any exogenous features, you can train on a standard warehouse if the dataset has 5 million rows or less. If your training data uses 5 or more exogenous features, then the maximum row count is lower. Otherwise, Snowflake suggests using a Snowpark-optimized warehouse for larger training jobs.
In general, for single-series data, a larger warehouse size does not result in a faster training time or higher memory limits.
As a rough rule of thumb, training time is proportional to the number of rows in your time series. For example, on a XS
standard warehouse, with evaluation turned off (CONFIG_OBJECT => {'evaluate': False}), training on a
100,000-row dataset takes about 60 seconds, while training on a 1,000,000-row dataset takes about 125 seconds. With
evaluation turned on, training time increases roughly linearly by the number of splits used.
为了获得最佳性能,Snowflake 建议使用没有其他并发工作负载的专用仓库来训练模型。
多序列数据训练
与单序列数据一样,我们建议根据最大时间序列中的行数选择仓库类型。如果最大时间序列包含的行数超过 500 万行,则训练作业可能会超出标准仓库的内存限制。
与单系列数据不同,多系列数据在较大的仓库规模上训练速度要快得多。以下数据点可以指导您进行选择。同样,所有这些时间都是在关闭评估的情况下完成的。
| 仓库类型和大小 | 时间序列数 | 每个时间序列的行数 | 训练时间(秒) |
|---|---|---|---|
| Standard XS | 1 | 100,000 | 60 秒 |
| Standard XS | 10 | 100,000 | 204 秒 |
| Standard XS | 100 | 100,000 | 720 秒 |
| Standard XL | 10 | 100,000 | 104 秒 |
| Standard XL | 100 | 100,000 | 211 秒 |
| Standard XL | 1000 | 100,000 | 840 秒 |
| Snowpark 优化型 XL | 10 | 100,000 | 65 秒 |
| Snowpark 优化型 XL | 100 | 100,000 | 293 秒 |
| Snowpark 优化型 XL | 1000 | 100,000 | 831 秒 |
检测异常
无论仓库规模如何,推理步骤大约需要 1 秒来处理所输入数据集中的 100 行。
授予创建异常检测对象的权限
训练异常检测模型会生成架构级对象。因此,用于创建模型的角色必须对将在其中创建模型的架构具有 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 权限,以便允许模型存储在相应位置。此权限类似于其他架构权限,如 CREATE TABLE 或 CREATE VIEW。
Snowflake recommends that you create a role named analyst to be used by people who need to detect anomalies.
In the following example, the admin role is the owner of the schema admin_db.admin_schema. The
analyst role needs to create models in this schema.
To use this schema, a user assumes the role analyst:
If the analyst role has CREATE SCHEMA privileges in database analyst_db, the role can create a new schema
analyst_db.analyst_schema and create anomaly detection models in that schema:
To revoke a role’s model creation privilege on the schema, use REVOKE <privileges> … FROM ROLE:
为示例设置数据
以下部分中的示例使用示例数据集,该数据集包含不同商店中商品的每日销售额以及每日天气数据(湿度和温度)。该数据集还包含一个列,用于指示当天是否为假日。
- Execute the following statements to create a table named
historical_sales_datathat contains the training data for the model:
- Execute the following statements to create a table named
new_sales_datathat contains the data to analyze:
训练、使用、查看、删除和更新模型
Use to create and train a model. The model is trained on the dataset you provide.
See ANOMALY_DETECTION (SNOWFLAKE.ML) for complete details about the SNOWFLAKE.ML.ANOMALY_DETECTION constructor. For examples of creating a model, see 检测异常.
Note
SNOWFLAKE.ML.ANOMALY_DETECTION runs using limited privileges, so by default it does not have access to your data. You must therefore pass tables and views as references, which pass along the caller’s privileges. You can also provide a query reference instead of a reference to a table or a view.
To create this reference, you can use the TABLE keyword with the table name, view name, or query, or you can call the SYSTEM$REFERENCE or SYSTEM$QUERY_REFERENCE function.
To detect anomalies, call the model’s method:
To select columns from the tabular output of the method, you can call the method in the FROM clause:
To view a list of your models, use the command:
To remove a model, use the command:
To update a model, delete it and train a new one. Models are immutable and cannot be updated in place.
检测异常
以下部分演示如何使用异常检测来检测异常值。这些部分提供了针对单个时间序列、多个时间序列、有和没有外生变量的情况、用户定义的预测区间以及受监督(已标记)方法检测异常的示例。
为单个时间序列检测异常(无监督)
要检测数据中的异常情况,请执行以下操作:
- 使用历史数据训练异常检测模型。
- Use the trained anomaly detection model to detect anomalies in historical or projected data. The timestamps in the test data must chronologically follow the timestamps in the training data. You need at least 2 data points to train a model, at least 12 for non-naive results, and at least 60 for non-linear results.
See ANOMALY_DETECTION (SNOWFLAKE.ML) for information on the parameters used in creating and using a model.
训练异常检测模型
To create an anomaly detection model object, execute the command.
For example, suppose that you want to analyze the sales for jackets in the store with the store_id of 1:
-
创建视图或设计查询,返回用于训练异常检测模型的数据。
For this example, execute the CREATE VIEW command to create a view named
view_with_training_datathat contains the date and sales information: -
创建异常检测对象,并使用该视图中的数据训练其模型。
For this example, execute the command to create an anomaly detection object named
basic_model. Pass in the following arguments:This example passes in a reference to a view as the INPUT_DATA argument. The example uses the TABLE keyword to create the reference. As an alternative, you can call SYSTEM$REFERENCE to create the reference.
标签列的目的是告诉模型哪些行已知存在异常。由于此示例使用无监督训练,因此无需使用标签列。传递一个空字符串作为标签列的名称。
Tip
If you don’t want to create a view for the INPUT_DATA argument, you can pass in a reference to a query that uses a SELECT statement that serves as an inline view.
您可以使用 TABLE 关键字来创建此查询引用。例如:
用反斜杠来转义任何单引号和其他特殊字符。
As an alternative to using the TABLE keyword, you can call SYSTEM$QUERY_REFERENCE to create the query reference.
如果命令执行成功,则会显示一条消息,表明已成功创建异常检测实例:
使用异常检测模型检测异常
Creating the anomaly detection object trains the model and stores it in the schema. To use the anomaly detection object to detect anomalies, call the method of the object. For example:
-
创建视图或设计查询,以便返回数据进行分析。
For this example, execute the CREATE VIEW command to create a view named
view_with_data_to_analyzethat contains the date and sales information: -
Using the object for the anomaly detection model (in this example,
basic_model, which you created earlier), call the method:The method returns a table that includes rows for the data currently in the view
view_with_data_to_analyzealong with the prediction of the detector. For a description of the columns in this table, see Returns.
输出
为了便于阅读,对结果进行了四舍五入。
To save your results directly to a table, use CREATE TABLE … AS SELECT … and call the DETECT_ANOMALIES method in the FROM clause:
As shown in the example above, when calling the method, omit the CALL command. Instead, put the call in parentheses, preceded by the TABLE keyword.
使用标记数据训练异常检测模型
在前面的示例中,模型的结果似乎不准确。这可能是因为:
- 异常检测模型是使用非常少的输入数据上训练的。
- A larger number of jackets (30) were sold on 2020-01-03. This skewed the predictions upward and increased the size of the prediction interval.
若要提高异常检测模型的准确性,可以包含更多训练数据或标记训练数据(监督训练)。标记的训练数据具有一个附加的布尔列,用于指示每行是否存在已知异常。标记可以帮助异常检测模型避免过度拟合训练数据中的已知异常。
To include labeled data in the training data, specify the column containing the label in the LABEL_COLNAME constructor argument of the command. For example:
-
创建视图或设计查询,以返回包含训练数据的标签。
For this example, execute the CREATE VIEW command to create a view named
view_with_labeled_datathat contains the labels in a column namedlabel: -
为异常检测模型创建一个对象,利用该视图中的数据训练模型。
For this example, execute the command to create an anomaly detection object named
model_trained_with_labeled_data. The following statement creates the anomaly detection object: -
Using this new anomaly detection model, call the method, passing in the same arguments that you used in 为单个时间序列检测异常(无监督):
The method returns a table that includes rows for the data currently in the view
view_with_data_to_analyzealong with the prediction of the detector. For a description of the columns in this table, see Returns.
输出
为了便于阅读,对结果进行了四舍五入。
指定异常检测的预测间隔
You can detect anomalies with varying levels of sensitivity. To specify the percentage of observations to classify as
anomalies, create an OBJECT that contains configuration settings for , and set the
prediction_interval key to the percentage of the observations that should be marked as anomalies.
To construct this object, you can use either an object constant or the OBJECT_CONSTRUCT function.
Then, when calling the method, pass in this object as the CONFIG_OBJECT argument.
默认情况下,与 prediction_interval 键关联的值设置为 0.99,这意味着大约 1% 的数据会被标记为异常。您可以指定一个介于 0 和 1 之间的值:
- To mark fewer observations as anomalies, specify a higher value for
prediction_interval. - To mark more observations as anomalies, reduce the
prediction_intervalvalue.
The following example configures anomaly detection to be more strict by setting the prediction_interval to 0.995. The example also
uses the model trained on labeled data (that you set up in 使用标记数据训练异常检测模型) with the view
that contains the data to analyze (that you set up in 为单个时间序列检测异常(无监督)).
This statement produces a table that includes rows for the data currently in the view view_with_data_to_analyze. Each row
includes a column with the prediction of the detector. You can see that the result
of this model is more accurate than the unlabeled example.
输出
为了便于阅读,对结果进行了四舍五入。
包括用于分析的其他列
You can include additional columns in the data (for example, temperature, weather, is_black_friday) in the data for training
and analysis, if these columns can help you improve the identification of true anomalies.
要包含用于分析的新列,请执行以下操作:
- For the training data, create a view or design a query that includes the new columns, and create a new anomaly detection object, passing in a reference to that view or query.
- For the data to analyze, create a view or design a query that includes the new columns, and pass a reference to that view or query to the method.
异常检测模型会自动检测并使用其他列。
Note
You must provide a view or query with the same set of additional columns when executing the command and when calling the method. If there is a mismatch between the columns in the training data passed to the command and the columns in the data for analysis passed to the function, an error occurs.
For example, suppose that you want to add the columns temperature, humidity, and holiday:
-
创建视图或设计查询,以返回包含这些附加列的训练数据。
For this example, execute the CREATE VIEW command to create a view named
view_with_training_data_extra_columns: -
为异常检测模型创建一个对象,利用该视图中的数据训练模型。
For this example, execute the command to create an anomaly detection object named
model_with_additional_columns, passing in a reference to the new view: -
创建视图或设计查询以返回要使用这些附加列进行分析的数据。
For this example, execute the CREATE VIEW command to create a view named
view_with_data_for_analysis_extra_columns: -
Using this new anomaly detection object, call the method, passing in the new view:
This statement produces a table that includes rows for the data currently in the view
view_with_data_for_analysis_extra_columnsalong with the prediction of the detector. The format of the output is the same as the format of the output shown for the commands that you ran earlier.
输出
为了便于阅读,对结果进行了四舍五入。
检测多个序列中的异常
前面的部分提供了检测单个序列异常的示例。这些示例标记了在一家商店(商店 ID 1)中,一种类型的商品(夹克)的销售异常情况。要同时为多个时间序列检测异常(例如,商品和商店的多个组合)检测异常,请执行以下操作:
- For the training data, create a view or design a query that includes a column that identifies the series, and create a new anomaly detection object, passing in a reference to that view or query and specifying the name of the series column for the SERIES_COLNAME argument.
- For the data to analyze, create a view or design a query that includes the column that identifies the series. Call the method, passing in a reference to that view or query and specifying the name of the series column for the SERIES_COLNAME argument.
For example, suppose that you want to use the combination of the store_id and item columns to identify the series:
-
创建视图或设计查询以返回包含序列列的训练数据。
For this example, execute the CREATE VIEW command to create a view named
view_with_training_data_multiple_seriesthat contains a column namedstore_itemthat identifies the series as a combination of store ID and item: -
创建异常检测对象,并使用该视图中的数据训练模型。
For this example, execute the command to create an anomaly detection object named
model_for_multiple_series, passing in a reference to the new view and specifyingstore_itemfor the SERIES_COLNAME argument: -
创建视图或设计查询,以返回要使用序列列进行分析的数据。
For this example, execute the CREATE VIEW command to create a view named
view_with_data_for_analysis_multiple_seriesthat contains a column namedstore_itemfor the series: -
Using this new anomaly detection object, call the method, passing in the new view and specifying
store_itemfor the SERIES_COLNAME argument:This statement produces a table that includes rows for the data currently in the view
view_with_data_for_analysis_multiple_seriesalong with the prediction of the detector. The output includes the column that identifies the series.
输出
为了便于阅读,对结果进行了四舍五入。
可视化异常并解释结果
Use Snowsight to review and visualize the results of anomaly detection. In Snowsight, when you call the method, the results are displayed in a table under the worksheet.

To visualize the results, you can use the chart feature in Snowsight.
-
After calling the method, select Charts above the results table.
-
In the Data section on the right side of the chart:
- Select the Y column, and under Aggregation, select None.
- Select the TS column, and under Bucketing, select None.
-
Add the LOWER_BOUND and UPPER_BOUND columns, and under Aggregation, select None.
-
To display the initial visualization, select Chart.

-
Select Add Column on the right side of the page, and select the columns you want to visualize:
- LOWER_BOUND
- UPPER_BOUND
- IS_ANOMALY
结果:
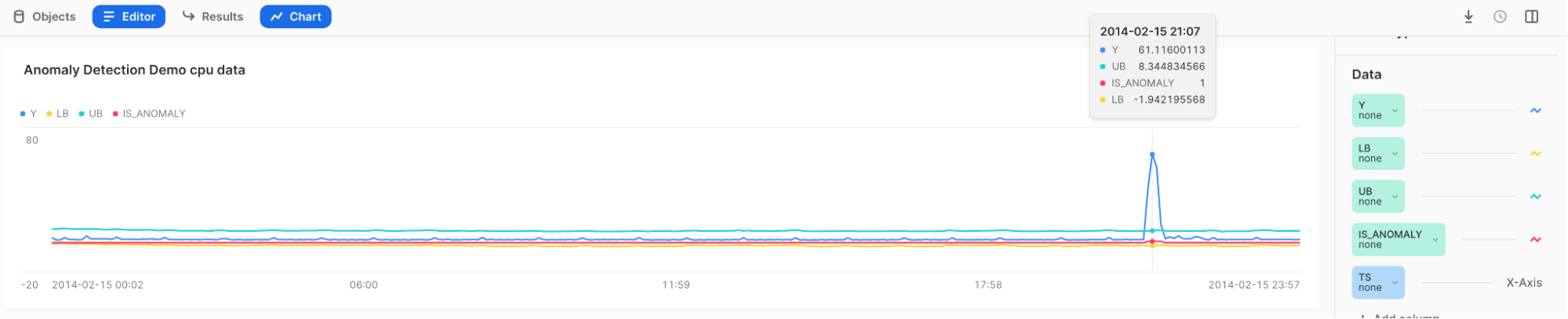
- Hover over the high spike to see that Y lies outside of the upper bound and is tagged with a 1 in the IS_ANOMALY field.
Tip
To better understand your results, try Top Insights.
通过 Snowflake 任务和警报自动进行异常检测¶
通过使用 Snowflake 任务或警报中的异常检测功能,可以创建自动异常检测管道,用于重新训练模型和监控数据中的异常情况。
使用 Snowflake 任务进行重复训练¶
You can update your model to reflect the most up-to-date data using Snowflake Tasks.
To create a task that refreshes the anomaly detection object every hour, run following statement, replacing your_warehouse_name with your warehouse name:
新创建的任务默认处于暂停状态。
To resume the task, execute the ALTER TASK … RESUME command:
To pause the task, execute the ALTER TASK … SUSPEND command:
使用 Snowflake Task 进行监控¶
您还可以使用 Snowflake 任务以给定频率监控数据。
首先,创建表来保存异常检测结果:
Create a task to store the results of a recurring anomaly detection operation in the table.
This example sets the WAREHOUSE parameter to snowhouse. You can replace that with
your own warehouse:
To resume the task, execute the ALTER TASK … RESUME command:
anomaly_res_table then contains all the results for each task run.
To pause the task, execute the ALTER TASK … SUSPEND command:
使用 Snowflake 警报进行监控¶
You can also use Snowflake Alerts to monitor your data at a given frequency and send you email with detected anomalies. The following statements create an alert that detects anomalies every minute. First you define a stored procedure to detect anomalies, then create an alert that uses that stored procedure.
Note
You must set up email integration to send mail from a stored procedure; see Notifications in Snowflake.
To start or resume the alert, execute the ALTER ALERT … RESUME command:
To pause the alert, execute the ALTER ALERT … SUSPEND command:
了解特征的重要性
异常检测模型可以解释模型中使用的所有特征的相对重要性,包括您选择的任何外生变量、自动生成的时间特征(例如星期几或一年中的某周)以及目标变量(例如滚动平均值和自动回归滞后)的转换。这些信息有助于了解真正影响数据的要素。
The Returns the relative feature importance for each feature used by the model. method counts the number of times the model’s trees used each feature to make a decision. These feature importance scores are then normalized to values between 0 and 1 so that their sum is 1. The resulting scores represent an approximate ranking of the features in your trained model.
得分接近的特征具有相似的重要性。对于极其简单的序列(例如,目标列的值为常数),所有特征重要性得分可能为零。
使用彼此非常相似的多个特征可能会降低这些特征的重要性得分。例如,如果一个特征是 已售商品数量,另一个特征是 库存商品数量,则这些值可能是相关的,因为您销售的商品不能超过您拥有的商品,并且您尝试管理库存,因此您的库存不会多于销售的库存。如果两个特征相同,则模型在做出决策时可能会将它们视为可互换的,从而导致特征重要性分数是仅包含一个特征时这些分数的一半。
Feature importance also reports lag features. During training, the model infers the frequency (hourly, daily, or weekly)
of your training data. The feature lagx (e.g. lag24) is the value of the target variable x time units ago.
For example, if your data is inferred to be hourly, lag24 represents your target variable 24 hours ago.
All other transformations of your target variable (rolling averages, etc.) are summarized as
aggregated_endogenous_features in the results table.
限制
- 不能选择用于计算特征重要性的技术。
- Feature importance scores can be helpful for gaining intuition about which features are important to your model’s accuracy, but the actual values should be considered estimates.
示例
To understand the relative importance of your features to your model, train a model, and then call Returns the relative feature importance for each feature used by the model.. In this example, you first create random data with two exogenous variables: one that is random and therefore unlikely to be very important to your model, and one that is a copy of your target and therefore likely to be more important to your model.
执行以下语句以生成数据,利用其训练模型,并获取特征的重要性:
输出
由于此示例使用随机数据,因此不要期望输出与此数据完全匹配。
检查训练日志
When you train multiple series with CONFIG_OBJECT => {'ON_ERROR': 'SKIP'}, individual time series models can
fail to train without the overall training process failing. To understand which time series failed and why, call
<model_instance>!SHOW_TRAINING_LOGS.
示例
输出
成本注意事项
For details on costs for using ML functions, see Cost Considerations in the ML functions overview.