分析时间序列数据¶
您可以使用专为分析时间序列数据而设计的功能,在 Snowflake 中分析时间序列数据。数据库管理员、数据科学家和应用程序开发者必须确保时间序列高效存储和加载,并在很多情况下汇总为完整且一致的形式,然后才能将数据提供给业务分析师和其他使用者。
联接时间序列数据¶
时间序列 由连续的观察结果组成,这些观察结果捕获了系统、流程和行为在一段时间内的变化。时间序列数据从各行各业的各种设备中收集。常见示例包括为金融应用程序收集的股票交易数据、天气观测结果、从智能工厂中传感器收集的温度读数以及数字广告中的用户点击日志。
时间序列中的单个记录通常包含以下组件:
具有一致粒度级别(毫秒、秒、分钟、小时等)的日期、时间或时间戳。
一个或多个某种测量结果或指标,通常为数字(可能揭示数据中的趋势或异常的事实)。
与测量结果关联的关注维度,例如温度读数对应的位置或给定交易的股票代码。
例如,以下天气观测结果具有开始和结束时间戳,降雨量测量结果 (0.32) 和位置信息:
从出厂设备收集的以下数据具有命名空间 (IOT)、标签 ID 或传感器 ID (3000)、设备上温度读数的时间戳、温度读数本身 (21.1673) 和“代理时间戳”,即数据随后到达数据代理的时间。例如,数据代理可能是将数据引入 Snowflake 表的 Kafka 服务器。
当读数因某种原因而发生巨大变化时,时间序列可能会显示峰值。例如,下图显示了每隔 15 秒采集的一系列温度读数,其中值在前一天稳定在 35°C 左右,之后峰值超过 40°C。

以下部分介绍如何借助能提供快速、准确结果的 SQL 函数和联接,分析和可视化大量此类数据。
如何存储时间序列数据¶
支持以下 日期时间数据类型:
DATE
TIME
TIMESTAMP(和变体,包括 TIMESTAMP_TZ)
有关加载、管理和查询使用这些数据类型的数据的信息,请参阅 使用日期和时间值。
一些常用的 SQL 函数 可用于帮助存储和查询时间序列数据。例如,您可以使用 CONVERT_TIMEZONE 将时间戳从一个时区转换为另一个时区。您可以使用 EXTRACT 和 TIMEADD 之类的函数,根据需要操作基于时间的数据。
备注
对于 TIMESTAMP_TZ 数据,Snowflake 存储给定时区的偏移,而非给定值创建时的实际时区。
为优化查询性能,用于时间序列分析的表通常按时间(有时也按传感器 ID 或类似维度)进行群集。请参阅 群集密钥和聚类表。
汇总时间序列数据¶
时间序列数据管理可能需要将大量精细粒度记录汇总为更概括的形式(这一过程有时称为“降采样”)。给定具有特定时间粒度(毫秒、秒、分钟等)的大量记录后,您可以将这些记录汇总到更粗的粒度,从而有效地生成较小的样本。
降采样很有价值,因为它缩小了数据集的大小并降低了其存储要求。较粗的粒度级别还可以减少查询执行期间的计算资源要求。进行降采样的另一个关键原因是,从分析师的角度来看,时间序列中的大量记录可能是多余的。例如,如果传感器每秒发出一次新值,但此测量值在每 60 秒的间隔内很少变化,则数据可以汇总到分钟级进行分析。
当需要将两个不同的数据集作为一个数据集进行分析,但它们具有不同的时间粒度时,会发生降采样的另一种情况。例如,工厂中的传感器 A 每 15 秒收集一次数据,但传感器 B 每 30 秒收集一次相关数据。在这种情况下,将记录汇总到 1 分钟的桶中可能是有效解决方案。每个数据集中的 IDs 和维度保持原样,但数值测量结果按通用时间间隔相加或求平均值。
降采样示例¶
您可以使用 TIME_SLICE 函数对表中存储的数据集进行降采样。此函数计算固定宽度“桶”的开始和结束时间,以便可以使用标准聚合函数(如 SUM 和 AVG)划分和汇总单个记录。
同样,DATE_TRUNC 函数会截断一系列日期或时间戳值的一部分,从而降低其粒度。以下部分将展示每个函数的示例。
使用 TIME_SLICE 降采样¶
以下示例对名为 sensor_data_ts 的表进行降采样,该表包含来自两个工厂传感器的读数,并包含 530 万行。这些读数每秒引入一次,因此 530 万行仅代表一个月的数据,每个传感器刚刚超过 250 万行。例如,您可以使用 TIME_SLICE 函数,每分钟、每小时或每天最多汇总一行。
要运行此示例,请首先创建并加载 sensor_data_ts 表;请参阅 创建 sensor_data_ts 表。以下是表中的一小部分数据:
该表包含每台设备每分钟的 60 个读数,如此查询所示:
在此降采样查询中,TIME_SLICE 函数定义一分钟桶,并返回每个桶的开始时间。AVG 函数计算每台设备每个桶的平均温度。包括 COUNT(*) 函数以供参考,仅仅为了显示归入每个时间桶的行数。
vibration 和 motor_rpm 列不包括在内,但它们可以采用与 temperature 列相同的方式汇总,或者使用不同的聚合函数。
重要
如果您自行运行此示例,输出将不完全匹配,因为 sensor_data_ts 表加载了随机生成的值。
通过使用 TIME_SLICE 函数,您可以创建更小的聚合表以进行分析,并且可以在不同级别(小时、天、周等)应用降采样过程。
使用 DATE_TRUNC 降采样¶
以下示例在 Tasty Bytes 样本数据库 (https://quickstarts.snowflake.com/guide/tasty_bytes_introduction/index.html#0) 的 raw.pos 架构中,从名为 order_header 的表中选择数据。此表包含 2.48 亿行。
order_header 表具有名为 order_ts 的 TIMESTAMP 列。查询将此列用作 DATE_TRUNC 函数的第二个实参,从而创建汇总时间序列。第一个实参指定 day 间隔。这意味着,具有小时/分钟/秒粒度的各个记录将按天汇总。
查询按两个维度划分记录:truck_id 和 location_id。avg_amount 列返回记录中每个工作日内每个订单、每辆餐车、每个位置的平均价格。
此处显示的查询将结果限制为 2022 年 1 月 1 日的前 25 行。如果您移除此日期筛选器和 LIMIT 子句,查询会将原始的 2.48 亿行降采样到大约 500,000 行。
使用窗口聚合进行滚动计算¶
通过使用窗口化聚合函数来观察指标如何随时间变化,您可以分析趋势的时间序列。窗口化聚合可用于分析较大数据集的已定义子集(“窗口”)内的数据。您可以计算数据集中每一行的滚动计算(例如移动平均值和总和),考虑当前行之前、之后或周围的一组行。这种分析与常规聚合形成对比,后者总结了整个数据集。
通过使用基于范围的窗口框架和显式偏移量,您可以对计算这些滚动聚合应用非常灵活的方法。RANGE BETWEEN 窗口框架,按时间戳或编号排序,不会被时间序列数据中可能出现的间隙所干扰。例如,在以下插图中,Day 4 数据在记录系列中缺失并不影响对三天移动窗口的聚合函数的计算。特别是,考虑到 Day 4 数据是未知的,框架 3、4 和 5 的计算是正确的。
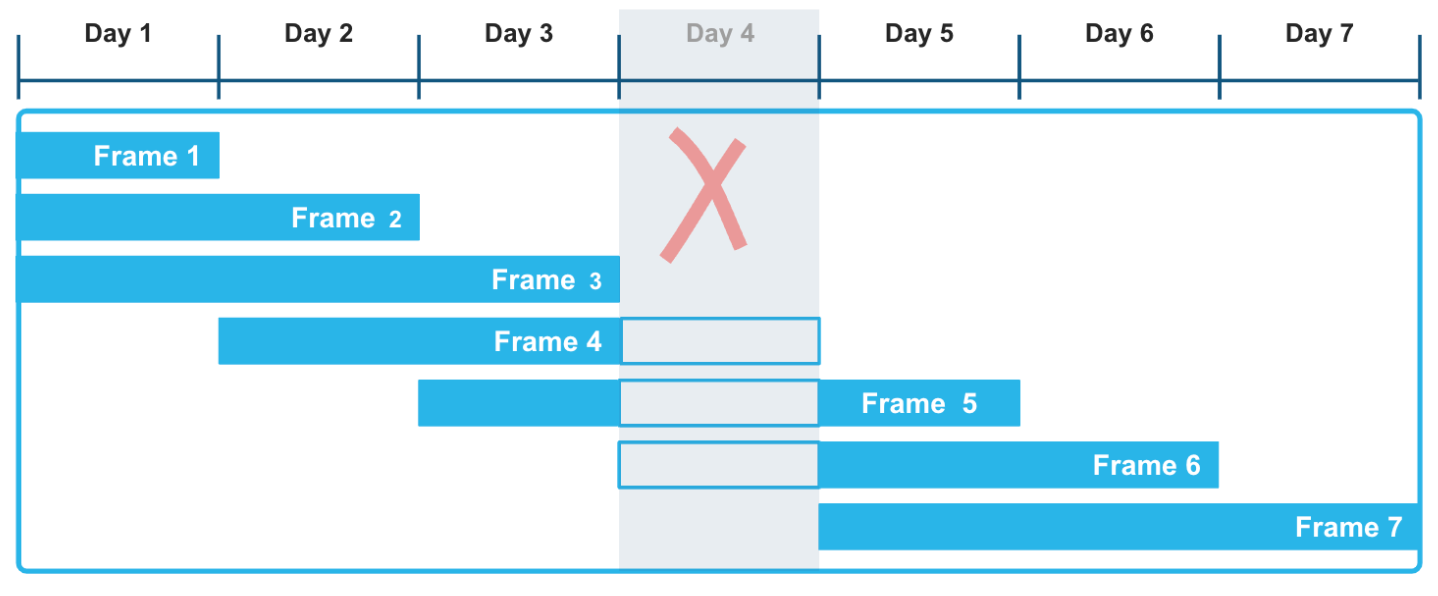
以下示例计算了天气数据的移动总和,该数据记录了不同城市和县的每小时降水量读数。您可以运行这种查询来评估各种时间序列数据集中的趋势,例如传感器和其他 IoT 设备,特别是当这些数据集已知或预计会有间隙时。
窗口函数在其框架中包括当前降水读数和 所有在当前读数之前指定时间间隔内的读数。 滚动计算基于这一灵活而合理的 范围 行,而不是确切的 行数。每个城市的第一行都有匹配的 precip 和 moving_sum_precip 值。之后,重新计算框架中每个后续行的总和。原始值波动显著,但移动总和具有很强的平滑效果。
要运行此示例,请首先遵循以下说明:创建并加载 heavy_weather 表。这个非常小的表格包含零散的每小时天气观测,存在很多间隙,包括缺失的一天。查询返回按 start_time 列排序的降水值的移动总和。窗口框架定义了当前行和当前行之前 12 小时之间的范围。因此,框架由当前行以及仅包含那些时间戳在当前行的 ORDER BY 时间戳之前 12 小时的行组成。
大贝尔城的三个 moving_sum_precip 值如下计算:
0.42 = 0.42(没有前面的行)
0.42 + 0.09 = 0.51(前两行在 12 小时窗口内)
0.07 = 0.07(没有前面的行在 12 小时窗口内)
南太浩湖的行包括以下计算,例如:
0.56 + 0.38 + 0.28 + 0.80 = 2.02 (2024 年 12 月 23 日的所有四行都在 12 小时内)
0.80 + 0.17 = 0.97(前一行在 12 小时窗口内)
其他窗口函数,例如 LEAD 和 LAG 排名函数,也常用于时间序列分析。使用 LEAD 窗口函数可查找时间序列中相对于当前数据点的下一个数据点,使用 LAG 函数可查找上一个数据点。
在 Snowsight 中可视化查询结果¶
您可以使用 Snowsight 可视化聚合查询的结果,并通过滑动窗口框架更好地了解计算的平滑效果。在查询工作表中,点击 Results 旁边的 Chart 按钮。
例如,在下面的条形图中,相较于表示原始温度的蓝线,黄线表明平均温度的趋势更加平稳。查询本身看起来是这样的:

使用 MIN_BY 和 MAX_BY 聚合函数¶
对于处理时间序列数据的 SQL 开发者来说,通常需要能够根据同一行中另一列的最小值或最大值选择一列。MIN_BY 和 MAX_BY 是便捷函数,当数据按其他列(如时间戳)排序时,函数返回表中的开始值和结束值(或最高值和最低值,或第一个值和最后一个值)。
第一个示例仅查找整个表中的最后一个(最新的) precip 值。MAX_BY 函数按其 start_time 值对所有行进行排序,然后返回“最大”开始时间的 precip 值。
要创建并加载以下示例中使用的表,请参阅 创建 heavy_weather 表。
您可以通过运行以下查询来验证此结果(并获取相关详细信息):
您可以添加 GROUP BY 子句,就此数据提出更有趣的问题。例如,以下查询查找为加利福尼亚州的每个城市观测到的最后降水量值,按 precip 值排序(从高到低)。结果按 city 分组,返回每个不同城市的最后 precip 值。
上次采集阿尔塔市的观测结果时,precip 值为 0.89,上次采集南太浩湖、大贝尔城、蒙塔古和勒贝克等城市的观测结果时,这四个位置的 precip 值为 0.07。(请注意,查询不会告诉您这些观测结果的采集时间。)
您可以使用 MIN_BY 函数,返回“相反”结果集(更早的 precip 记录与近期记录)。
联接时间序列数据¶
您可以使用 ASOF JOIN 构造,联接包含时间序列数据的表。虽然 ASOF JOIN 查询可以通过使用复合 SQL、其他类型的联接和窗口函数来模拟,但使用 ASOF JOIN 语法可以更轻松地写入(和优化)这些查询。
ASOF 联接的常见用途是分析金融交易数据。例如,交易成本分析需要“滑移”计算,衡量在决定购买股票时的报价与执行和记录交易时实际支付的价格之间的差额。ASOF JOIN 可以加快此类分析。鉴于这种联接方法的关键功能是相对于另一个时间序列来分析一个时间序列,ASOF JOIN 可用于分析任何过往的数据集。在许多此类用例中,当来自不同设备的读数具有不完全相同的时间戳时,ASOF JOIN 可用于关联数据。
假设您需要分析的时间序列数据存在于两个表中,并且每个表中的每一行都有一个时间戳。此时间戳表示记录事件的精确“截至”日期和时间。对于第一个(或左侧)表中的每一行,联接使用“匹配条件”,其中包含您指定的比较运算符,用于在第二个(或右侧)表中查找时间戳值为以下值的单行:
小于或等于左侧表中的时间戳值。
大于或等于左侧表中的时间戳值。
小于左侧表中的时间戳值。
大于左侧表中的时间戳值。
右侧的限定行是最接近的匹配项,可能时间相等、时间更早或更晚,具体取决于指定的比较运算符。
ASOF JOIN 的结果的基数始终等于左侧表的基数。如果左侧表包含 4000 万行,则 ASOF JOIN 返回 4000 万行。因此,左侧表可以视作“保留”表,右侧表视作“引用”表。
联接关于最接近的匹配项的两个表(一致性)¶
例如,在财务应用程序中,您可能有名为 quotes 的表和名为 trades 的表。一个表记录购买股票的出价历史记录,另一个表记录实际交易的历史记录。购买股票的出价发生在交易之前(或者可能在“相同”时间,具体取决于记录时间的粒度)。两个表都有时间戳,并且都有您可能想要比较的其他感兴趣的列。简单的 ASOF JOIN 查询将在每笔交易之前(及时)返回最更接近的报价。换言之,查询会询问:在我进行交易时,给定股票的价格是多少?
假设 trades 表包含三行,并且 quotes 表包含七行。当基于匹配的股票代码联接行,并比较它们的时间戳列时,单元格的背景颜色显示来自 quotes 的哪三行符合 ASOF JOIN 的资格。
TRADES 表(左侧表或“保留”表)

QUOTES 表(右侧表或“参考”表)

这个概念性示例很容易变成特定的 ASOF JOIN 查询:
ON 条件按其股票代码对匹配的行进行分组。
要运行此示例,请按如下方式创建并加载表:
有关 ASOF JOIN 查询的更多示例,请参阅 示例。
联接时间序列数据¶
Time-series analysis often requires data to have a consistent granularity with records for every interval, yet real-world data often arrives at irregular intervals or contains gaps. For instance, you might have a predominantly hourly data set but need to generate half-hour entries to align with downstream analytics, or you might already have a consistent resolution but discover gaps in the series. Snowflake gap-filling functionality provides efficient ways to apply a uniform interval to time-series data and fill any gaps.
For example, consider the following eight records, which capture weather observations for two cities in California on March 15, 2025.
Although these records have a somewhat consistent level of granularity (day, hour, minute), the intervals between the rows are inconsistent, varying between 1 and 15 minutes. If the goal is to collect data at five-minute intervals, several rows are missing.
Using the RESAMPLE clause¶
You can modify the granularity and improve the consistency of a set of rows by "upsampling" them to a specific time interval. To make this kind of change, use the RESAMPLE clause, which you define within the FROM clause of a SELECT statement. The result of a resampled data set is a larger data set that preserves all of the existing input rows and generates some number of new rows with values that fill gaps in the time series. (Note that you can also use the RESAMPLE clause to "downsample" rows into a smaller, more coarse-grained result set.)
By definition, a time series always has a column that contains a sequence of dates, timestamps, or numeric values that represent dates or times.
Resampling operates on such a column in the source table, and the required granularity must be specified with an INTERVAL value, such as
5 minutes, 30 minutes, or 1 hour.
Typically, you also define partitions that create time-series rows over certain dimensions, rather than just generating one new timestamp per interval.
The structure of a RESAMPLE query looks like this:
Columns in the rows that are generated are set to NULL, except for the columns specified in the USING and PARTITION BY clauses. The specified date, time, or numeric column and the partitioning columns have meaningful generated values.
备注
If you plan to filter your resampled data by specific values (for example, a specific device ID or location), include those columns in the PARTITION BY clause. This ensures that generated rows have real values for those columns rather than NULL values. If you filter with a WHERE clause on columns that are not in the PARTITION BY clause, the WHERE clause filters out all generated rows for those columns because they contain NULL values.
To run a simple example that uses the eight records shown earlier, start by creating and loading the following table:
Now select upsampled rows from that table, using an interval of 5 minutes:
This query preserves the original eight rows and generates three new rows, filling gaps for three time intervals, at 09:45, 10:00, and 10:05.
NULL values are inserted into the temperature, city, and county columns.
The starting point for the time series is 2025-03-15 09:45:00.000 because it is within 5 minutes of the earliest timestamp in the input data set
(2025-03-15 09:49:00.000).
If you want to remove rows that don't occur at uniform intervals (09:49 and 10:18 in this case), see RESAMPLE example that uses BUCKET_START() to filter out non-uniform rows.
Now add a PARTITION BY clause to the query:
The partitioned results are different in two ways:
Seven rows are generated, for a total of 15 rows. A row now exists for every 5-minute interval for every partition.
The partitioning columns have correctly generated
cityandcountyvalues. The only column that has NULL values in the generated rows istemperature.
You can also specify the METADATA_COLUMNS parameter in the RESAMPLE syntax to add the following columns to the result:
The
is_generatedmetadata column identifies the rows that were generated by the RESAMPLE operation and the rows that were already present.The
bucket_startmetadata column returns the value that marks the beginning of the current bucket or interval that the RESAMPLE operation produces. You can use this column to identify which interval a particular row belongs to after resampling, and you can use it to run aggregate queries on resampled data. See RESAMPLE example that uses BUCKET_START() to aggregate resampled rows.
For the complete RESAMPLE syntax, see RESAMPLE.
To store the results of a RESAMPLE query, use a CTAS statement that selects and inserts the data into a new table:
Interpolating or "gap-filling" values into a time series¶
Although you can use the RESAMPLE syntax and interpolation functions independently, they are most commonly used together to gap-fill time-series data in the scope of a single query. Having resampled your data set, you can call an interpolation function to update the other columns of interest in the newly generated rows. The interpolation process updates columns that were previously NULL, such as numeric measurements, giving them meaningful values based on values found in the preceding or following rows.
You can interpolate values by calling the INTERPOLATE_FFILL, INTERPOLATE_BFILL, and INTERPOLATE_LINEAR window functions. For example, the INTERPOLATE_FFILL function finds the previous (last) value in the time series for the column in question:
The first row returns NULL for the ffill_temp column because there is no previous row for the INTERPOLATE_FFILL function to use.
For more information about these window functions, see INTERPOLATE_BFILL, INTERPOLATE_FFILL, INTERPOLATE_LINEAR.
Upsampling, gap-filling, and storing the results in one operation¶
To simplify the whole process of gap-filling a data set, you can upsample data and interpolate values within a single query, and save the results by using a CTAS operation. For example, the following CTAS statement creates a new table that interpolates measurements into a an upsampled data set:
备注
When you use INTERPOLATE functions with resampling, the columns you specify in the OVER (PARTITION BY) clause for window functions typically match
the columns in the RESAMPLE (PARTITION BY) clause. This approach ensures that interpolation happens within the same logical partitions that were created
during resampling. In the previous example, resampling is partitioned by city and county, while the INTERPOLATE functions partition by city only.
This example works because the interpolation is happening at a coarser granularity, but you should always make sure that the partitioning strategy aligns with your data requirements.
使用 ASOF JOIN 填充数据间隙¶
备注
To use the recommended approach for gap-filling and interpolation, see 联接时间序列数据. The RESAMPLE construct and INTERPOLATE functions are preview features, and the following ASOF JOIN approach to gap-filling is included only as a potential workaround.
除通过基于时间的列的非精确匹配使两个表中的数据保持一致外,当原始数据表缺少特定日期或时间戳的行时,ASOF JOIN 可用于填充时间序列间隙。此过程称为“间隙填充”或“插值”。当由于设备故障或电源故障导致传感器读数跳过而缺失行时,您可以使用 ASOF JOIN 将生成的时间序列中的值插值到表中。缺失的行将用缺失读数的最后一个已知值填充。此值也称为“转移的最后一个观测值”(LOCF)。ASOF JOIN 查询返回一组完整的行,这些行按时间顺序排列且连续。
要为插值使用 ASOF JOIN,请执行以下步骤:
通过运行简单查询来确定表间隙。
为您需要涵盖的时间段生成完整的时间序列,并使用适当的粒度。例如,时间序列可能是特定年份的简单日期序列,或者是特定天数的每秒时间戳的更精细序列。您可以使用 SQL 或电子表格应用程序生成值列表。
对于稍后在 ASOF JOIN ON 条件中指定的每个行,时间序列还需要有意义的 ID 或维度。
编写 ASOF JOIN 查询,将值插入缺失行。生成的时间序列将是保留表,原始数据表将是引用表。
以下示例需要 sensor_data_ts 表。如果尚未创建并加载该表,请参阅 创建 sensor_data_ts 表。要模拟间隙填充操作需求,请从表中删除一些行,如下所示:
结果是一个表,该表在 3 月 7 日缺失 DEVICE2 的五行(1:16 至 1:20)。
现在,按照以下步骤完成间隙填充练习。
备注
如果您自行运行此示例,输出将不完全匹配,因为 sensor_data_ts 表加载了随机生成的值。
第 1 步:验证表是否存在间隙¶
运行以下查询以识别间隙:
此查询返回 DEVICE2 的两行:间隙前的最后一行和间隙后的第一行。
第 2 步:生成完整的时间序列以填补已知的间隙¶
要为 sensor_data_ts 表中的间隙生成具有细粒度(每秒一行)的时间序列,请创建以下表,其中包含生成的时间戳:
在此 SQL 语句中,5 是填补间隙所需的秒数。请注意,生成的行中包含设备 ID 值 (DEVICE2)。
以下查询返回五个生成的行。
第 3 步:使用 ASOF JOIN 插入值¶
现在,您可以运行 ASOF JOIN 查询,将 continuous_timestamps 与 sensor_data_ts 联接,并为 DEVICE2 的缺失行插入值。匹配条件为每个缺失行查找时间最接近的行,并且 ON 条件确保根据匹配设备 IDs 插值。
缺失行的最接近行是带 2024-03-07 00:01:16.000 时间戳的行,假设 >= 在匹配条件中指定,如此示例中所示。
INSERT 语句通过 ASOF JOIN 操作选择五行,并将它们插入 sensor_data_ts 表。
要检查插值的结果,请从 sensor_data_ts 表中选择这五行及紧随其前和其后的两行。请注意,五个插值行已为 2024-03-07 00:01:15.000 行中记录的 temperature、vibration 和 motor_rpm 列选择了相同的值。插值成功。
为时间序列数据应用基于 ML 的函数¶
您可以使用 ML 函数训练模型,对时间序列数据进行预测性分析:
预测使用历史时间序列数据对未来数据进行预测。给定记录的时间序列,其中包含过去日期和时间的实际观测值,则 ML 模型会预测未来日期和时间的观测值可能是多少。
异常检测可识别异常值,即偏离预期范围的数据点。在时间序列的上下文中,异常值是指在相似的时间间隔内比其他测量值大得多或小得多的测量值。要查找异常值,ML 函数会生成正在检查异常的同一时间段的预测,然后将预测结果与实际数据进行比较。
精辟见解在数据集中找到最重要的维度,从这些维度构建片段,然后检测这些片段中哪些对指标有影响。
备注
出于机器学习目的,时间序列中的时间戳必须表示固定的时间间隔。如有必要,您可以对 TIMESTAMP 列使用 DATE_TRUNC 或 TIME_SLICE 函数,以在训练预测模型时去除不规则性。
时间序列中的异常检测示例¶
以下示例使用只有 30 行的视图来训练异常检测模型。首先将数据生成到表中,然后基于表创建视图。视图不是必需的(您可以使用表来训练模型),但视图选项为您提供了一些灵活性,可以在不更新源数据的情况下,以不同的行计数迭代方式训练模型。
备注
如果您自行运行此示例,输出将不完全匹配,因为 sensor_data_30_rows 表加载了随机生成的值。
现在创建模型:
成功构建模型后,调用 <model_name>!DETECT_ANOMALIES 方法以检测指定测试数据集中的异常值。测试数据中的时间戳必须按时间顺序遵循训练数据中的时间戳,但训练数据和测试数据之间的时间间隔不能太大。例如,如果您有每秒的时间戳,则不要使用比训练数据早数百万秒的测试数据。
此示例使用另一个表作为测试数据,其中只有三行。这些行的时间戳与训练数据中的时间戳密切相关。
当异常检测调用完成时,它将返回类似于以下内容的输出:
TS 和 Y 列返回测试数据中的时间戳和温度值。在这个非常小的测试用例中,函数发现了一个异常 (IS_ANOMALY=True)。有关输出列的更多信息,请参阅 功能说明 中的“返回”部分。
创建 sensor_data_ts 表¶
如果要测试本部分中查询 sensor_data_ts 表的示例,您可以通过运行以下 SQL 脚本来创建和加载此表的副本。该脚本通过调用 UNIFORM、RANDOM 和 GENERATOR 函数,为传感器读数生成一个月的合成数据;因此,表副本不会返回相同的结果。读数将在相同的范围内,但它们不会相同。
创建 heavy_weather 表¶
以下脚本创建并加载 heavy_weather 表,该表用于 MAX_BY 函数的示例中。该表包含 2021 年最后一周加利福尼亚州城市的 55 行降雪降水记录。