使用 Query History 监控查询活动¶
要监控账户中的查询活动,您可以使用:
- The Query History and Grouped Query History pages in Snowsight.
- The QUERY_HISTORY view and AGGREGATE_QUERY_HISTORY view in the ACCOUNT_USAGE schema of the SNOWFLAKE database.
- The QUERY_HISTORY family of table functions in INFORMATION_SCHEMA.
With the Query History page in Snowsight, you can do the following:
- 监控用户在您的账户中执行的单个查询或分组查询。
- View details about queries, including performance data. In some cases, query details are unavailable.
- 在查询配置文件中浏览已执行查询的每个步骤。
通过 Query History 页面,您可以浏览过去 14 天内 Snowflake 账户中执行的查询。
Within a worksheet, you can see the query history for queries that have been run in that worksheet. See View query history.
在 Snowsight 中查看 Query History¶
To access the Query History page in Snowsight, do the following:
-
Sign in to Snowsight.
-
In the navigation menu, select Monitoring » Query History.
-
Go to Individual Queries or Grouped Queries. For more information about grouped queries, see 在 Snowsight 中使用分组查询历史记录视图.
-
For Individual Queries, filter your view to see the most relevant and accurate results.
If a Load More button appears at the top of the list, it means that there are more available results to load. You can fetch the next set of results by either selecting Load More or scrolling to the bottom of the list.
查看 Query History 时所需的权限¶
您可以随时查看已运行的查询的历史记录。
To view history for other queries, your active role affects what else you can see in Query History:
-
如果您的活动角色是 ACCOUNTADMIN 角色,您可以查看账户的所有查询历史记录。
-
If your active role has the MONITOR or OPERATE privilege granted on a warehouse, you can view queries run by other users that use that warehouse.
-
If your active role is granted the GOVERNANCE_VIEWER database role for the SNOWFLAKE database, it is sufficient for querying the ACCOUNT_USAGE views directly with SQL, and it also allows you to view Grouped Queries in the Query History. However, this role alone does not grant the ability to see Individual Queries by other users in Snowsight. To view all user queries (both grouped and individual), your role must be ACCOUNTADMIN or be granted IMPORTED PRIVILEGES on the SNOWFLAKE database. Alternatively, the following two privileges can replace the IMPORTED PRIVILEGES:
-
If your active role is granted the READER_USAGE_VIEWER database role for the SNOWFLAKE database, you can view the query history for all users in reader accounts associated with your account. See SNOWFLAKE database roles.
使用 Query History 时的注意事项¶
When reviewing the Query History for your account, consider the following:
- Details for queries executed more than seven days ago do not include User information due to the data retention policy for sessions. You can use the user filter to retrieve queries run by individual users. See 筛选查询历史记录.
- For queries that failed due to syntax or parsing errors, you see
<redacted>instead of the SQL statement that was executed. If you are granted a role with appropriate privileges, you can set the ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR parameter to view the full query text. - Filters and the Started and End Time columns use your current time zone. You can’t change this setting. Setting the TIMEZONE parameter for the session doesn’t change the time zone used.
筛选查询历史记录
您可以按以下方法筛选查询历史记录列表:
-
查询的状态,例如,用于识别长时间运行的查询、失败的查询和排队的查询。
-
执行查询的用户,包括:
- All, to see all users for which you have access to view query history.
- 您登录时使用的用户身份(默认)
- 您账户中的单个 Snowflake 用户(如果您的角色可以查看其他用户的查询历史记录)。
-
运行查询的时间段,最多 14 天。
-
其他筛选器,包括以下内容:
- SQL Text, for example, to view queries that use specific statements, such as GROUP BY.
- Query ID, to view details for a specific query.
- Warehouse, to view queries that were run using a specific warehouse.
- Statement Type, to view queries that used a specific type of statement, such as DELETE, UPDATE, INSERT, or SELECT.
- Duration, for example, to identify especially long-running queries.
- Session ID, to view queries run during a specific Snowflake session.
- Query Tag, to view queries with a specific query tag set through the QUERY_TAG session parameter.
- Parameterized Query Hash, to display queries grouped according to the parameterized query hash ID specified in the filter. For more information, see Using the Hash of the Parameterized Query (`query_parameterized_hash`).
- Client generated statements, to view internal queries run by a client, driver, or library, including the web interface. For example, whenever a user navigates to the Warehouses page in Snowsight, Snowflake executes a SHOW WAREHOUSES statement in the background. That statement would be visible when this filter is enabled. Your account is not billed for client-generated statements.
- Queries executed by user tasks, to view SQL statements executed or stored procedures called by user tasks.
- Show replication refresh history, to view queries used to perform replication refresh tasks to remote regions and accounts.
If you want to see near-real-time results, enable Auto Refresh. When Auto Refresh is enabled, the table refreshes every ten seconds.
You can see the following columns in the Queries table by default:
- SQL Text, the text of the executed statement (always shown).
- Query ID, the ID of the query (always shown).
- Status, the status of the executed statement (always shown).
- User, to see the username that executed a statement.
- Warehouse, to see the warehouse used to execute a statement.
- Duration, to see the length of time it took to execute a statement.
- Started, to see the time a statement started running.
If you have more results, you cannot sort the table. If you select Load More at the top of the list after sorting the table, the new results will be appended to the end of the data and the sort order will no longer apply.
To view more specific information, you can select Columns to add or remove columns from the table, such as:
- All to display all columns.
- User to display the user who ran the statement.
- Warehouse to display the name of the warehouse used to run the statement.
- Warehouse Size to display the size of the warehouse used to run the statement.
- Duration to display the time it took for the statement to run.
- Started to display the start time of the statement.
- End Time to display the end time of the statement.
- Session ID to display the ID of the session that executed the statement.
- Client Driver to display the name and version of the client, driver, or library used to execute the statement.
Statements run in Snowsight display
Go 1.1.5. - Bytes Scanned to display the number of bytes scanned during the processing of the query.
- Rows to display the number of rows returned by a statement.
- Query Tag to display the query tag set for a query.
- Parameterized Query Hash to display queries grouped according to the parameterized query hash ID specified in the filter. For more information, see Using the Hash of the Parameterized Query (`query_parameterized_hash`).
- Incident to display details for statements with an execution status of incident, used for troubleshooting or debugging purposes.
To view additional details about a query, select a query in the table to open the Query Details.
在 Snowsight 中使用分组查询历史记录视图¶
You can use the Grouped Query History view in Snowsight to monitor usage and performance of critical and frequently run queries. This graphical view is based on information that is recorded in the AGGREGATE_QUERY_HISTORY view. Executed queries are grouped by a parameterized query hash ID. You can monitor key statistics over time and drill down into individual queries that belong to each group.
Although this view includes all queries against Snowflake, it is particularly useful for monitoring and analyzing Unistore workloads that execute a small number of distinct statements repeatedly at high throughput. For workloads that involve hybrid tables, it is challenging to monitor performance by looking at individual queries.
例如,您的工作负载可能由数千个非常相似的点查找查询和插入组成,这些查询和插入仅因用户 ID 而异,运行速度极快,而且重复的速度使它们无法单独分析。当您要回答类似以下问题时,这些操作的汇总视图是必不可少的:
- 在我的账户或工作负载中,哪些分组查询(或 参数化查询)消耗的总时间或资源最多?
- 随着时间的推移,参数化查询的性能是否发生了重大变化?
- What sorts of issues is a parameterized query running into? Locking? Queueing? Long compilation times?
- How often does a parameterized query succeed or fail? Less than one percent of the time, or more often than that?
如何使用分组查询历史记录
To access the Grouped Query History in Snowsight, do the following:
-
Sign in to Snowsight.
-
In the navigation menu, select Monitoring » Query History » Grouped Queries. The page shows you queries grouped by their common parameterized query hash ID.
Note
Individual queries do not immediately appear in the Grouped Queries list. Latency for updating the list from the records in the AGGREGATE_QUERY_HISTORY view might be up to 180 minutes (3 hours), but the list is often populated much faster.
-
Select any grouped query to see performance statistics for that parameterized query hash. Snowsight displays the total number of queries executed, the number of queries that failed, latency (p50, p90, p99), and executions per minute. The bottom section of the page shows some sample individual queries run as part of that hash; you can select each query to see its specific details.
For example, during the last day, about 540 queries ran in this group, with a total duration of about 3 hours:
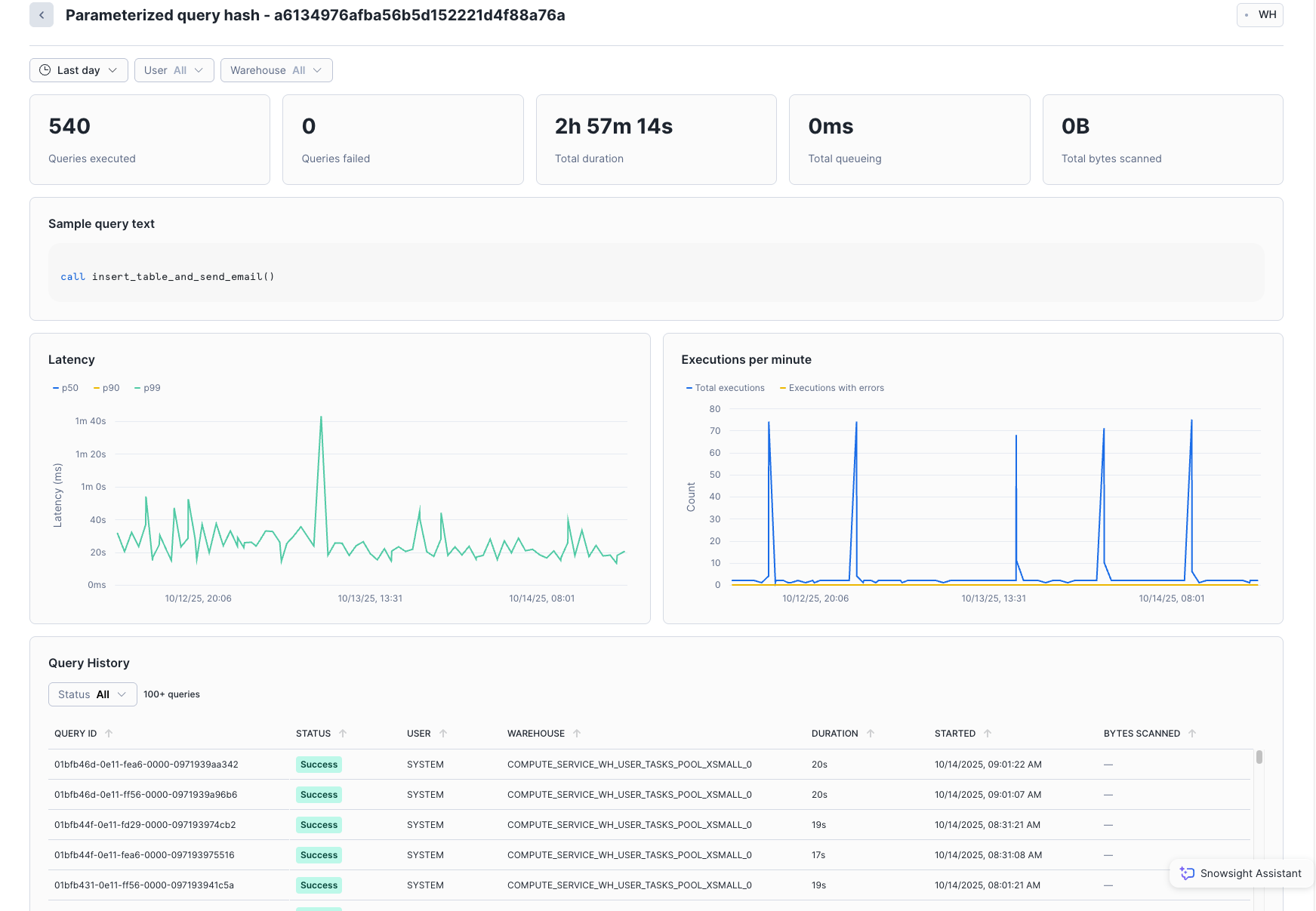
In the Parameterized query hash view, you can filter queries by status, such as Failed or
Successful. In both the Grouped Queries view and the Parameterized query hash
view, you can filter by a date range, by user, and by warehouse. The date range is limited to a maximum
of the last 14 days of grouped query history. You can’t retrieve information about queries that were
executed more than 14 days ago.
Note that some warehouses are internal warehouses managed by Snowflake, and those warehouses don’t appear in the Warehouse filter. Similarly, the SYSTEM user does not appear in the User filter.
As an alternative to using filters, you can run aggregate queries that return filtered results. See also the AGGREGATE_QUERY_HISTORY view.
Individual Queries list¶
Alternatively, you can look at Individual Queries. This view doesn’t reflect all of the queries run by Unistore workloads, given the sheer volume of queries that can be created against hybrid tables. For more information about this behavior, see the hybrid tables section of the Usage notes. Snowflake recommends that all users with Unistore workloads start by monitoring the Grouped Queries view.
查看分组查询历史记录时所需的权限
Users can always view the history of queries that they’ve run. A user’s active role affects which other queries are visible. You can view both Grouped Queries and Individual Queries if one of the following is true:
- 您的活动角色是 ACCOUNTADMIN。
- Your active role has been granted IMPORTED PRIVILEGES on the SNOWFLAKE database (see Enabling other roles to use schemas in the SNOWFLAKE database).
- You have the GOVERNANCE_VIEWER database role.
If you don’t have any of these roles or privileges, you can only see Individual Queries. For more information about access privileges, see Monitor query activity with Query History.
查看特定查询的详细信息和配置文件
When you select a query in Query History, you can review details and the profile of the query.
Query Profile data redacted from a Snowflake Native App¶
The Snowflake Native App Framework redacts information from the query profile in the following contexts:
- Queries that are run when the app is installed or upgraded.
- Queries that originate from a stored procedure owned by the app.
- Queries containing a non-secure view or function owned by the app.
For each of these types of queries, Snowsight collapses the query profile data into a single empty node instead of displaying the full query profile tree.
查看查询详细信息
To review the details of a specific query, and view the results of a successful query, open the Query Details for a query.
You can review the Details for information about the query execution, including:
- 查询的状态。
- 查询开始时,采用用户的当地时区。
- 查询结束时,采用用户的当地时区。
- 用于运行查询的仓库的大小。
- 查询的持续时间。
- 查询 ID。
- 查询的查询标签(如果存在)。
- The driver status. For more details, see View the Snowflake client version.
- The name and version of the client, driver, or library used to submit the query.
For example,
Go 1.1.5for queries run using Snowsight. - 会话 ID。
You can see the warehouse used to run the query and the user who ran the query listed above the Query Details tab.
Review the SQL Text section for the actual text of the query. You can hover over the SQL text to open the statement in a worksheet or copy the statement. If the query failed, you can review the error details.
The Results section displays the results of the query. You can only view the first 10,000 rows of results, and only the user who ran the query can view the results. Select Export Results to export the full set of results as a CSV-formatted file.
排查查询详细信息不可用的原因
如果查询没有查询详细信息,一些可能的原因包括:
- 查询仍在运行。查询完成运行后,您可以查看查询详细信息和配置文件。
- 您的角色无权查看查询详细信息。
- 查询在 14 多天前运行,查询详细信息和配置文件不再可用。
- 查询无法运行,因此没有查询配置文件。
- 尽管 Snowflake 平台旨在保留作业详细信息,但作业查询详细信息的深度和查询配置文件指标是基于尽力而为的原则,并不保证适用于所有查询。
查看查询配置文件
The Query Profile tab lets you explore the query execution plan and understand granular details about each step of execution.
查询配置文件是用于了解查询机制的强大工具。每当您需要了解有关特定查询的性能或行为的更多信息时,都可以使用它。它旨在帮助您发现 SQL 查询表达式中的典型错误,以识别潜在的性能瓶颈和改进机会。
本节简要概述了如何导航和适用查询配置文件。
| Interface | Description |
|---|---|
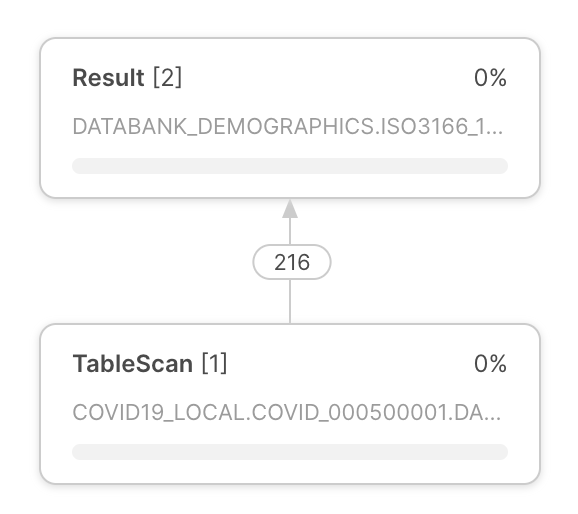 Query execution plan Query execution plan | The query execution plan appears at the center of the query profile. The query execution plan is composed of operator nodes, which represent rowset operators. Arrows between operator nodes indicate the rowsets that flow out of one operator and into another. |
 Operator node Operator node | Each operator node includes the following:
|
 Query profile navigation Query profile navigation | In the upper-left corner of the query profile, use the buttons to:
Note Steps only appear if the query was executed in steps. |
 Information panes Information panes | The query profile provides various information panes. The panes appear in the query execution plan. The panes that appear depend on the focus of the query execution plan. The query profile includes the following information panes:
To learn more about the information provided by the panes, see Query Profile reference. |
Query History data redacted from a Snowflake Native App¶
For queries related to a Snowflake Native App, the query_text and error_message fields are redacted
from the query history in the following contexts:
- Queries run when the app is installed or upgraded.
- Queries that originate from a child job of a stored procedure owned by the app.
In each of these situations, the cell of the query history in Snowsight appears blank.
查询配置文件参考
本部分介绍每个信息窗格中可以显示的所有项目。信息窗格的确切内容取决于查询执行计划的上下文。
配置文件概述
该窗格提供有关哪些处理任务占用了查询时间的信息。执行时间提供有关查询处理期间“时间花费在何处”的信息。花费的时间可以分为以下几类:
- Processing — time spent on data processing by the CPU.
- Local Disk IO — time when the processing was blocked by local disk access.
- Remote Disk IO — time when the processing was blocked by remote disk access.
- Network Communication — time when the processing was waiting for the network data transfer.
- Synchronization — various synchronization activities between participating processes.
- Initialization — time spent setting up the query processing.
- Hybrid Table Requests Throttling — time spent throttling requests to read and write data that is stored in hybrid tables.
查询见解
如果存在影响查询执行性能的条件,此窗格会提供有关这些条件的见解。每项见解都包含一条消息,其中解释了查询性能可能受到的影响,并为后续步骤提供了一般性建议。
For information, see Using query insights to improve performance.
Note
You can also access these insights by querying the QUERY_INSIGHTS view.
统计信息
A major source of information provided in the detail pane is the various statistics, grouped in the following sections:
-
IO — information about the input-output operations performed during the query:
- Scan progress — the percentage of data scanned for a given table so far.
- Bytes scanned — the number of bytes scanned so far.
- Percentage scanned from cache — the percentage of data scanned from the local disk cache.
- Bytes written — bytes written (e.g. when loading into a table).
- Bytes written to result — bytes written to the result object. For example,
select * from . . .would produce a set of results in tabular format representing each field in the selection. In general, the results object represents whatever is produced as a result of the query, and Bytes written to result represents the size of the returned result. - Bytes read from result — bytes read from the result object.
- External bytes scanned — bytes read from an external object, e.g. a stage.
-
DML — statistics for Data Manipulation Language (DML) queries:
- Number of rows inserted — number of rows inserted into a table (or tables).
- Number of rows updated — number of rows updated in a table.
- Number of rows deleted — number of rows deleted from a table.
- Number of rows unloaded — number of rows unloaded during data export.
-
Pruning — information on the effects of table pruning:
- Partitions scanned — number of partitions scanned so far.
- Partitions total — total number of partitions in a given table.
-
Spilling — information about disk usage for operations where intermediate results do not fit in memory:
- Bytes spilled to local storage — volume of data spilled to local disk.
- Bytes spilled to remote storage — volume of data spilled to remote disk.
-
Network — network communication:
- Bytes sent over the network — amount of data sent over the network.
-
External Functions — information about calls to external functions:
The following statistics are shown for each external function called by the SQL statement. If the same function was called more than once from the same SQL statement, then the statistics are aggregated.
- Total invocations — number of times that an external function was called. (This can be different from the number of external function calls in the text of the SQL statement due to the number of batches that rows are divided into, the number of retries (if there are transient network problems), etc.)
- Rows sent — number of rows sent to external functions.
- Rows received — number of rows received back from external functions.
- Bytes sent (x-region) — number of bytes sent to external functions. If the label includes “(x-region)”, the data was sent across regions (which can impact billing).
- Bytes received (x-region) — number of bytes received from external functions. If the label includes “(x-region)”, the data was sent across regions (which can impact billing).
- Retries due to transient errors — number of retries due to transient errors.
- Average latency per call — average amount of time per invocation (call) between the time Snowflake sent the data and received the returned data.
- HTTP 4xx errors — total number of HTTP requests that returned a 4xx status code.
- HTTP 5xx errors — total number of HTTP requests that returned a 5xx status code.
- Latency per successful call (avg) — average latency for successful HTTP requests.
- Avg throttle latency overhead — average overhead per successful request due to a slowdown caused by throttling (HTTP 429).
- Batches retried due to throttling — number of batches that were retried due to HTTP 429 errors.
- Latency per successful call (P50) — 50th percentile latency for successful HTTP requests. 50 percent of all successful requests took less than this time to complete.
- Latency per successful call (P90) — 90th percentile latency for successful HTTP requests. 90 percent of all successful requests took less than this time to complete.
- Latency per successful call (P95) — 95th percentile latency for successful HTTP requests. 95 percent of all successful requests took less than this time to complete.
- Latency per successful call (P99) — 99th percentile latency for successful HTTP requests. 99 percent of all successful requests took less than this time to complete.
-
Extension Functions — information about calls to extension functions:
- Java UDF handler load time — amount of time for the Java UDF handler to load.
- Total Java UDF handler invocations — number of times the Java UDF handler is invoked.
- Max Java UDF handler execution time — maximum amount of time for the Java UDF handler to execute.
- Avg Java UDF handler execution time — average amount of time to execute the Java UDF handler.
- Java UDTF process() invocations — number of times the Java UDTF process method was invoked.
- Java UDTF process() execution time — amount of time to execute the Java UDTF process.
- Avg Java UDTF process() execution time — average amount of time to execute the Java UDTF process.
- Java UDTF’s constructor invocations — number of times the Java UDTF constructor was invoked.
- Java UDTF’s constructor execution time — amount of time to execute the Java UDTF constructor.
- Avg Java UDTF’s constructor execution time — average amount of time to execute the Java UDTF constructor.
- Java UDTF endPartition() invocations — number of times the Java UDTF endPartition method was invoked.
- Java UDTF endPartition() execution time — amount of time to execute the Java UDTF endPartition method.
- Avg Java UDTF endPartition() execution time — average amount of time to execute the Java UDTF endPartition method.
- Max Java UDF dependency download time — maximum amount of time to download the Java UDF dependencies.
- Max JVM memory usage — peak memory usage as reported by the JVM.
- Java UDF inline code compile time in ms — compile time for the Java UDF inline code.
- Total Python UDF handler invocations — number of times the Python UDF handler was invoked.
- Total Python UDF handler execution time — total execution time for Python UDF handler.
- Avg Python UDF handler execution time — average amount of time to execute the Python UDF handler.
- Python sandbox max memory usage — peak memory usage by the Python sandbox environment.
- Avg Python env creation time: Download and install packages — average amount of time to create the Python environment, including downloading and installing packages.
- Conda solver time — amount of time to run the Conda solver to solve Python packages.
- Conda env creation time — amount of time to create the Python environment.
- Python UDF initialization time — amount of time to initialize the Python UDF.
- Number of external file bytes read for UDFs — number of external file bytes read for UDFs.
- Number of external files accessed for UDFs — number of external files accessed for UDFs.
If the value of a field, for example “Retries due to transient errors”, is zero, then the field is not displayed.
最昂贵的节点
该窗格列出了持续时间占查询执行总计时间的 1% 或更长时间的所有节点(如果查询是在多个处理步骤中执行的,则为所显示查询步骤的执行时间)。该窗格按执行时间降序列出节点,使用户能够根据执行时间快速找到成本最高的运算符节点。
属性
以下各部分提供了最常见的运算符类型及其属性的列表:
数据访问和运算符生成
- TableScan:
表示对单个表的访问。属性:
- Full table name — the fully qualified name of the scanned table
- Table alias — used table alias, if present
- Columns — list of scanned columns
- Extracted variant paths — list of paths extracted from VARIANT columns
- Scan mode — ROW_BASED or COLUMN_BASED (shown only for scans of hybrid tables)
- Access predicates — conditions from the query that are applied during the table scan
- IndexScan:
Represents access to secondary indexes on hybrid tables. Attributes:
- Full table name — the fully qualified name of the scanned table that contains the index
- Columns — list of scanned index columns
- Scan mode — ROW_BASED or COLUMN_BASED
- Access predicates — conditions from the query that are applied during the index scan
- Full index name — the fully qualified name of the scanned index
- ValuesClause:
随 VALUES 子句提供的值列表。属性:
- Number of values — the number of produced values.
- Values — the list of produced values.
- Generator:
Generates records using the
TABLE(GENERATOR(...))construct. Attributes:- rowCount — provided rowCount parameter.
- timeLimit — provided timeLimit parameter.
- ExternalScan:
表示对存储在暂存区对象中的数据的访问。可以是直接从暂存区扫描数据的查询的一部分,也可以是数据加载操作(即 COPY 语句)的一部分。
属性:
- Stage name — the name of the stage where the data is read from.
- Stage type — the type of the stage (e.g. TABLE STAGE).
- InternalObject:
表示对内部数据对象(例如 Information Schema 表或上一个查询的结果)的访问。属性:
- Object Name — the name or type of the accessed object.
数据处理运算符
- Filter:
表示筛选记录的操作。属性:
- 筛选条件 – 用于执行筛选的条件。
- Join:
在给定条件下组合两个输入。属性:
- Join Type — Type of join (e.g. INNER, LEFT OUTER, etc.).
- Equality Join Condition — for joins which use equality-based conditions, it lists the expressions used for joining elements.
- Additional Join Condition — some joins use conditions containing non-equality based predicates. They are listed here.
Note
非相同的联接谓词可能会导致处理速度明显变慢,应尽可能避免使用。
- Aggregate:
对输入进行分组并计算聚合函数。可以表示 SQL 结构,例如 GROUP BY 和 SELECT DISTINCT 等。属性:
- Grouping Keys — if GROUP BY is used, this lists the expressions we group by.
- Aggregate Functions — list of functions computed for each aggregate group, e.g. SUM.
- GroupingSets:
表示 GROUPING SETS、ROLLUP 和 CUBE 等结构。属性:
- Grouping Key Sets — list of grouping sets
- Aggregate Functions — list of functions computed for each group, e.g. SUM.
- WindowFunction:
计算窗口函数。属性:
- Window Functions — list of window functions computed.
- Sort:
对给定表达式的输入进行排序。属性:
- Sort keys — expression defining the sorting order.
- SortWithLimit:
Produces a part of the input sequence after sorting, typically a result of an
ORDER BY ... LIMIT ... OFFSET ...construct in SQL.属性:
- Sort keys — expression defining the sorting order.
- Number of rows — number of rows produced.
- Offset — position in the ordered sequence from which produced tuples are emitted.
- Flatten:
处理 VARIANT 记录,可能在指定路径上展平记录。属性:
- input — the input expression used to flatten the data.
- JoinFilter:
特殊筛选操作,用于移除识别为可能不符合查询计划中进一步联接条件的元组。属性:
- Original join ID — the join used to identify tuples that can be filtered out.
- UnionAll:
连接两个输入。属性:无。
- ExternalFunction:
表示外部函数执行的处理。
DML 运算符¶
- Insert:
通过 INSERT 或 COPY 操作将记录添加到表中。属性:
- Input expressions — which expressions are inserted.
- Table names — names of tables that records are added to.
- Delete:
从表中移除记录。属性:
- Table name — the name of the table that records are deleted from.
- Update:
更新表中的记录。属性:
- Table name — the name of the updated table.
- Merge:
对表执行 MERGE 操作。属性:
- Full table name — the name of the updated table.
- Unload:
表示将数据从表导出到暂存区中的文件的 COPY 操作。属性:
- 位置 – 保存数据的暂存区的名称。
元数据运算符
某些查询包含的步骤是纯元数据/目录操作,而不是数据处理操作。这些步骤由单个运算符组成。一些例子包括:
- DDL and Transaction Commands:
用于创建或修改对象、会话、事务等。通常,这些查询不由虚拟仓库处理,并且最终会生成与匹配 SQL 语句对应的单步配置文件。例如:
CREATE DATABASE | SCHEMA | …
ALTER DATABASE | SCHEMA | TABLE | SESSION | …
DROP DATABASE | SCHEMA | TABLE | …
COMMIT
- Table Creation Command:
用于创建表的 DDL 命令。例如:
CREATE TABLE
与其他 DDL 命令类似,这些查询会生成单步配置文件;但是,它们也可以是多步骤配置文件的一部分,例如在 CTAS 语句中使用时。例如:
CREATE TABLE …AS SELECT …
- Query Result Reuse:
重用上一个查询结果的查询。
- Metadata-based Result:
纯粹根据元数据计算结果,不访问任何数据的查询。这些查询不由虚拟仓库处理。例如:
SELECT COUNT(*) FROM …
SELECT CURRENT_DATABASE()
其他运算符
- Result:
返回查询结果。属性:
- 表达式列表 – 生成的表达式。
查询配置文件识别的常见查询问题
本部分描述一些可以使用查询配置文件识别和解决的问题。
“爆炸”联接
One of the common mistakes SQL users make is joining tables without providing a join condition (resulting in a “Cartesian product”), or providing a condition where records from one table match multiple records from another table. For such queries, the Join operator produces significantly (often by orders of magnitude) more tuples than it consumes.
This can be observed by looking at the number of records produced by a Join operator, and typically is also reflected in Join operator consuming a lot of time.
UNION(无 ALL)¶
在 SQL 中,可以将两组数据与 UNION 或 UNION ALL 结构组合在一起。它们之间的区别在于,UNION ALL 只是简单地连接输入,而 UNION 在执行同样操作的同时,也会消除重复数据。
A common mistake is to use UNION when the UNION ALL semantics are sufficient. These queries show in Query Profile as a UnionAll operator with an extra Aggregate operator on top (which performs duplicate elimination).
查询太大而无法放入内存
对于某些操作(例如,对大型数据集进行重复数据消除),用于执行操作的服务器的可用内存量可能不足以保存中间结果。因此,查询处理引擎会开始将数据 溢出 到本地磁盘。如果本地磁盘空间不足,则溢出的数据将保存到远程磁盘。
这种溢出可能会对查询性能产生深远影响(尤其是在因为溢出而使用远程磁盘时)。为了缓解这种情况,我们建议:
- 使用更大的仓库(有效地增加操作的可用内存/本地磁盘空间),以及/或者
- 以较小的批次处理数据。
修剪效率低下
Snowflake 会收集有关数据的丰富统计信息,从而根据查询筛选器避免读取表中不必要的部分。但是,要使此设置生效,需要将数据存储顺序与查询筛选器属性相关联。
The efficiency of pruning can be observed by comparing Partitions scanned and Partitions total statistics in the TableScan operators. If the former is a small fraction of the latter, pruning is efficient. If not, the pruning did not have an effect.
Of course, pruning can only help for queries that actually filter out a significant amount of data. If the pruning statistics do not show data reduction, but there is a Filter operator above TableScan which filters out a number of records, this might signal that a different data organization might be beneficial for this query.
For more information about pruning, see Understanding Snowflake Table Structures.