- description:
Start running your Spark code with Snowpark Connect
Snowpark Migration Accelerator: Determining Compatibility with Snowpark Connect¶
With Snowpark Connect for Spark, you can run your Spark code with Snowflake.
You can determine if a Spark workload is a good fit for Snowpark Connect for Spark by using the following steps:
-
Take a moment to understand what you have and what you are looking to do.
Snowpark Connect for Spark will be a great choice for many Spark workloads, but not all.
-
Run the Snowpark Migration Accelerator (SMA), as described below.
Currently, the SMA will report on compatibility for Snowpark Connect for Spark for any code written in Python with references to the Spark API.
-
Use the SMA to identify all references to the Spark API that are present in the codebase you’ve scanned with it.
Analyze compatibility with the SMA¶
Accessing the SMA¶
The Snowpark Migration Accelerator (SMA) is a tool that accelerates the migration of pipelines written in or with Spark. The SMA assesses the compatibility of references of the Spark API in Python and Scala code, and can convert some references to the Snowpark API.
Installation¶
You can download the SMA from the Snowflake website as described in Installation.
Before running the SMA¶
Once you have installed the SMA, you can assess a codebase. As you do, keep in mind the following:
-
The SMA can only analyze certain extensions for references to the Spark API. However, only Python code can be analyzed for Snowpark Connect.
Notebooks and code files can be processed at the same time.
-
The SMA reads files from a local directory. You will need to put them all in a root directory (there can be as many subdirectories as you like) for the SMA to analyze them. You can run many files or a single file through as much as you like.
For more SMA considerations, see Before Using the SMA.
Generating the assessment¶
-
Open the Snowpark Migration Accelerator (SMA).
-
Start a new project by selecting the New Project button.

-
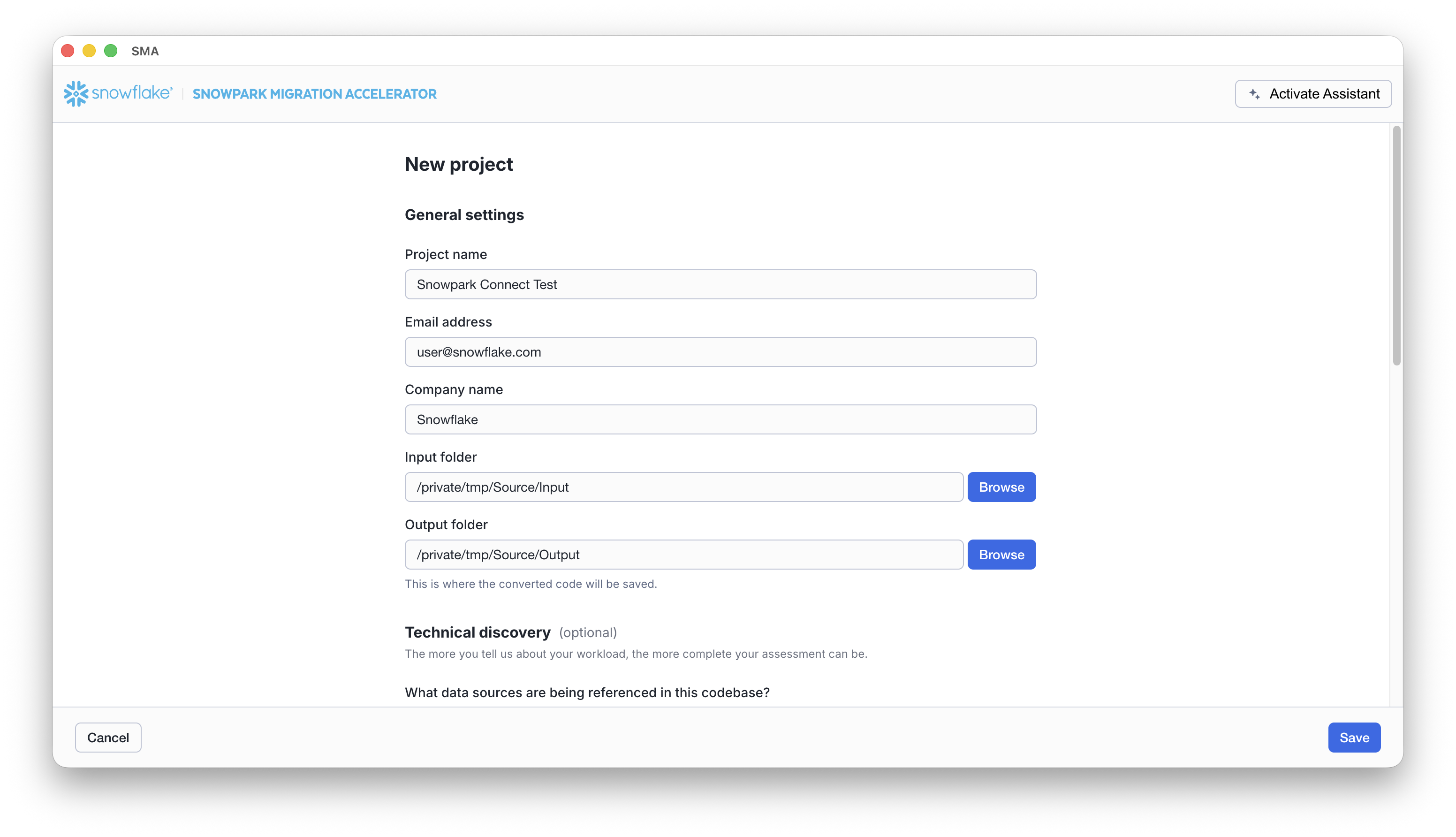
Fill out the fields on the project creation screen, including the locally accessible directory where the source codebase is. The field Company name helps Snowflake identify other runs of the SMA that may be related to your codebase or other codebases (depending on how you name it), both in the past or the future. Once you have filled out all the fields, click the Save button in the bottom right corner.
-
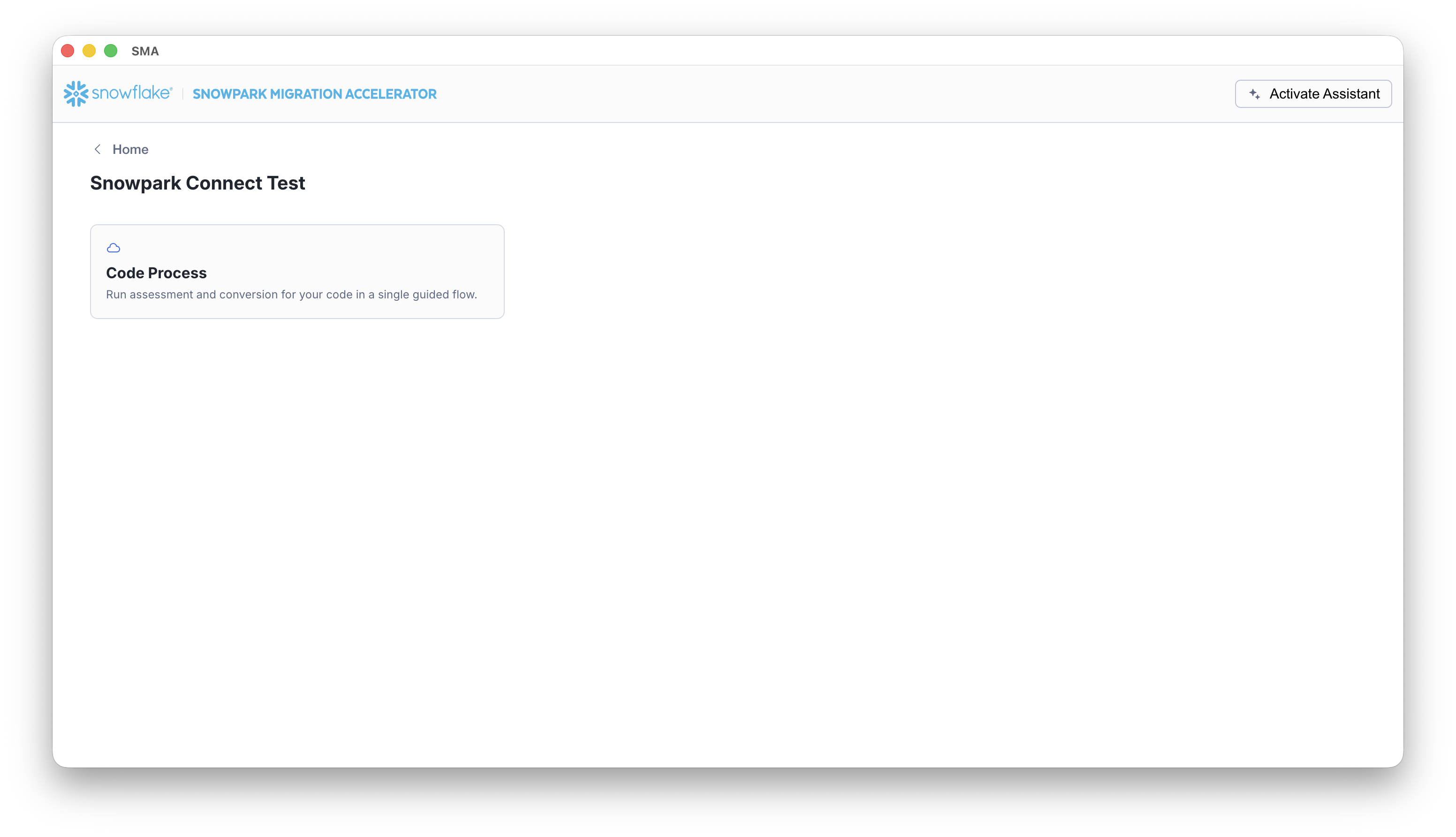
Select the Code Process card to proceed to the assessment settings screen.
-
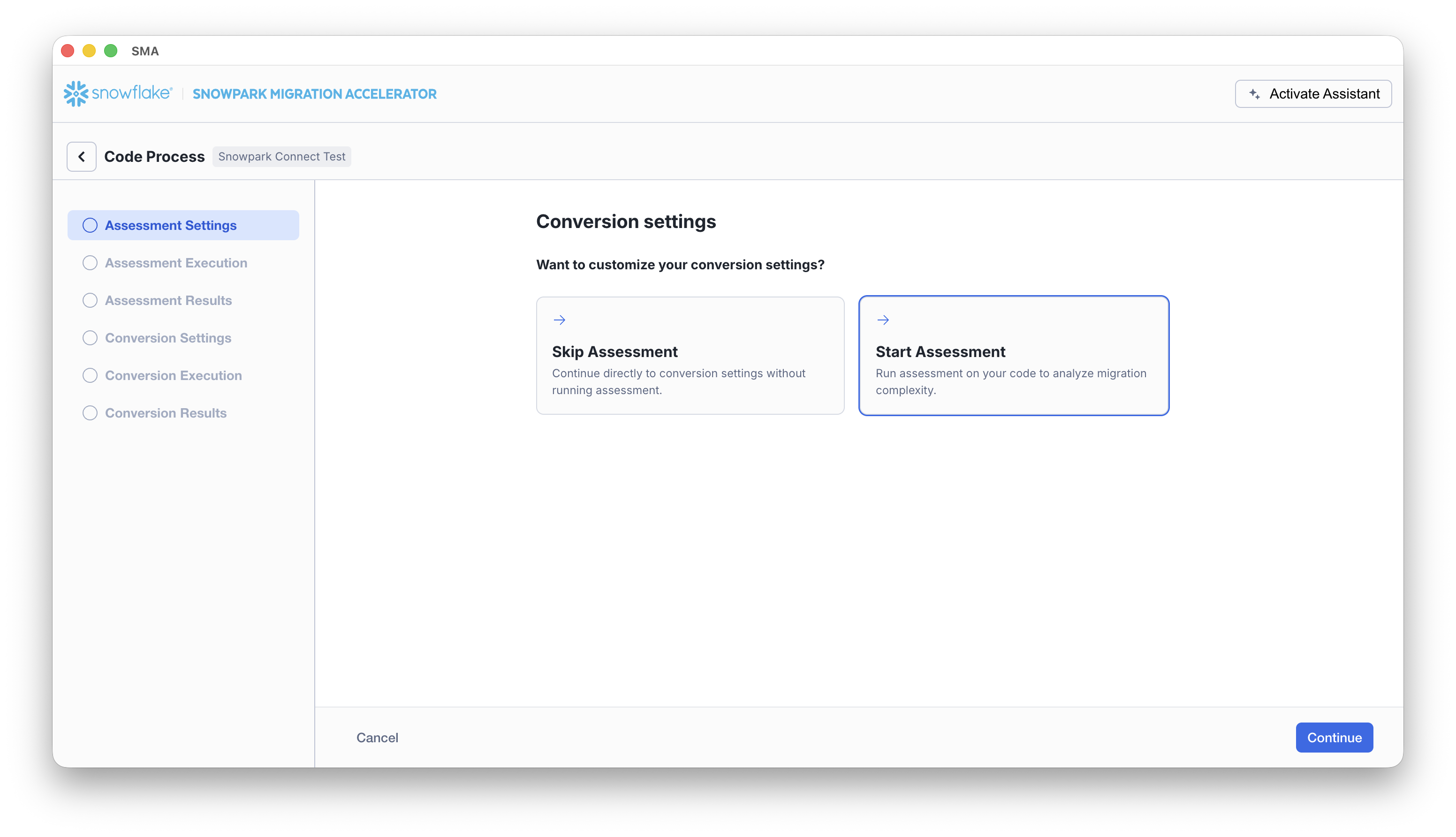
On the Assessment Settings screen, select Start Assessment to run the assessment on your code.
-
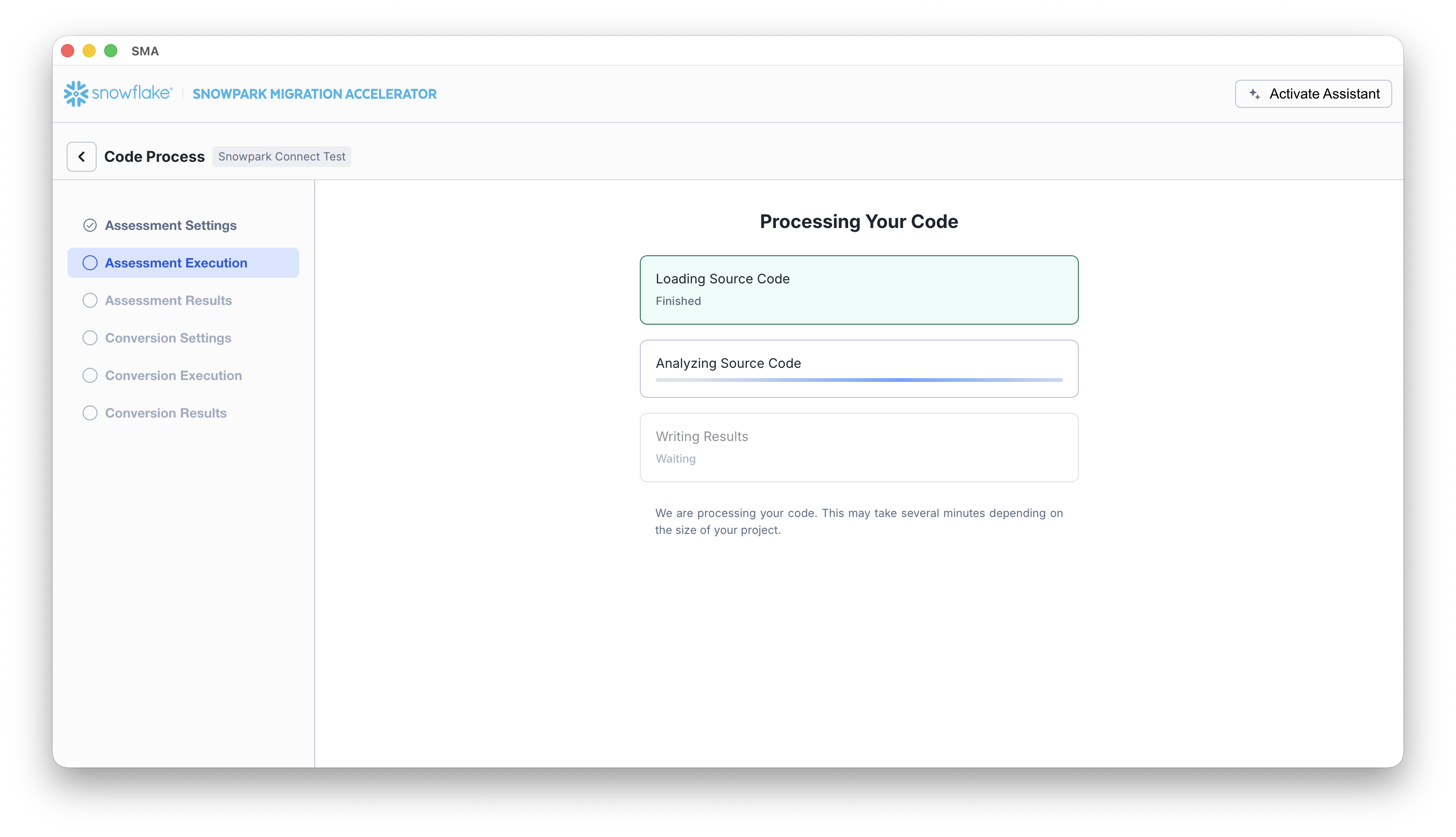
The SMA displays progress indicators while the assessment runs: Loading Source Code, Analyzing Source Code, and Writing Results. This may take several minutes depending on project size.
-
When assessment has finished, the SMA displays the Assessment Results page.
-
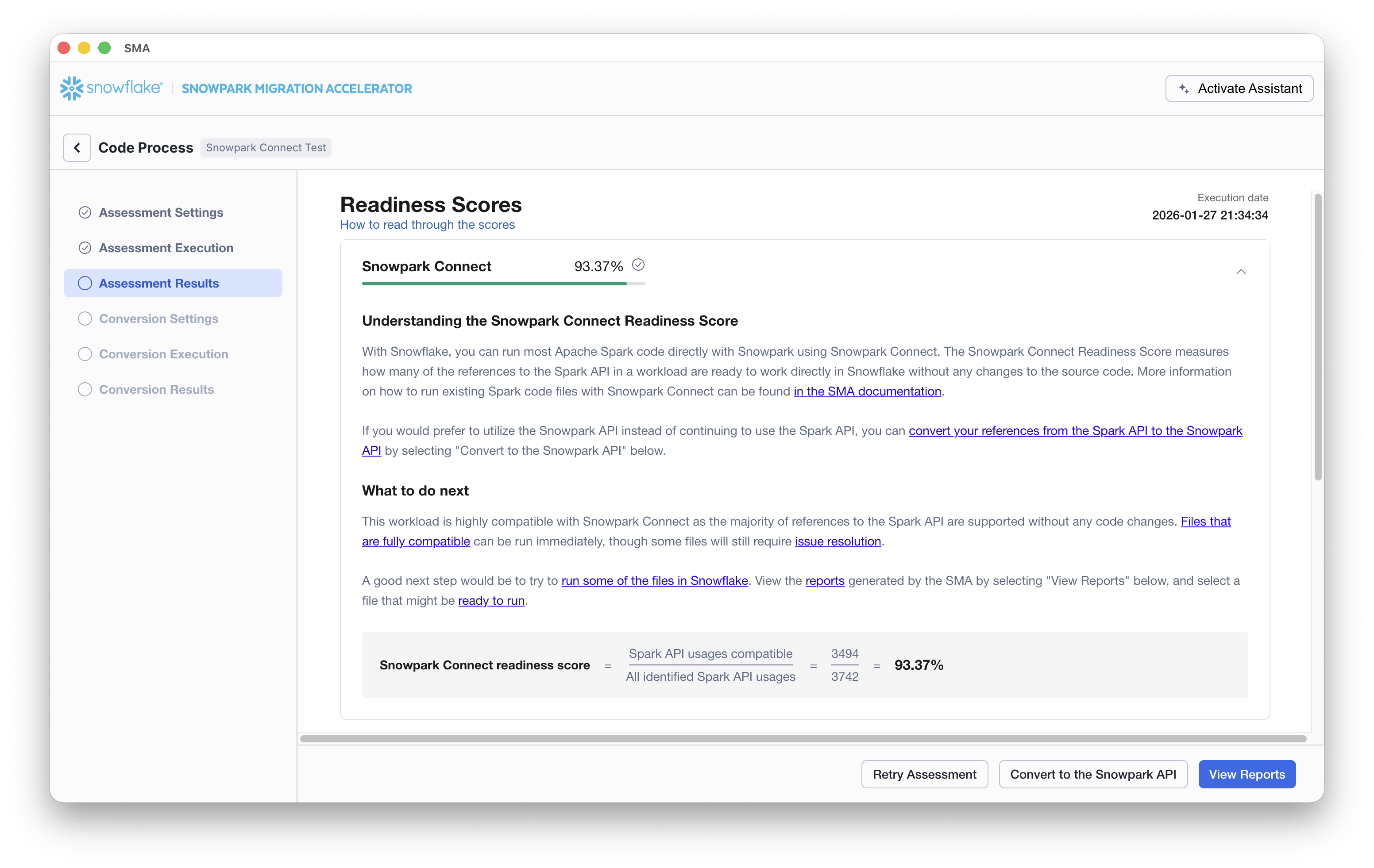
Determine a codebase’s compatibility with Snowpark Connect by looking at the Snowpark Connect Readiness Score.
The number of Readiness Scores shown varies depending on the SMA version you run.
The percentage shown is the count of references to the Spark API that are fully compatible with Snowpark Connect. Next to the percentage, you’ll find green (greater than 90 percent of references are supported), yellow (between 70 percent and 90 percent of references are supported), or red (less than 70 percent of references are supported) indicators.
The following describes what the indicators mean:
-
Green: Good candidate for Snowpark Connect (less than 10 percent of references to the Spark API are not supported in Snowpark Connect).
-
Yellow: Possibly a good candidate.
Determine if you can make what is not supported work with Snowpark Connect. You can use the SMA to convert to the Snowpark API and compare that result with the Snowpark Readiness Score to see which is a better fit.
-
Red: Could still work, but there’s a lot of incompatibility.
Check the Snowpark API Readiness score. If that is high (greater than 90 percent), then it’s likely that Snowpark is the better route for migration for this workload.
For the yellow and red options, reach out to sma-support@snowflake.com for more support, but for the green indicator you may want to see if you can take the next step and identify a POC.
-
Note
The SMA converts only a few elements to Snowpark Connect. You can choose Continue to Conversion in the SMA user interface, but that will only convert the code to the Snowpark API.
Determining what files are ready to run with Snowpark Connect¶
The score is a high level indicator, but the SMA allows you to see exactly what elements of the Spark API are supported and what files are fully supported.
Note
This guide shows you how to do this locally, but you can also use the Interactive Assessment Application (IAA).
To determine what files are ready to run, you will have to use the SparkUsagesInventory.csv file generated in the
local Reports output folder by the SMA. This file lists every
reference to the Spark API found by the SMA.
-
Navigate to the reports directory from the application by selecting View Reports.
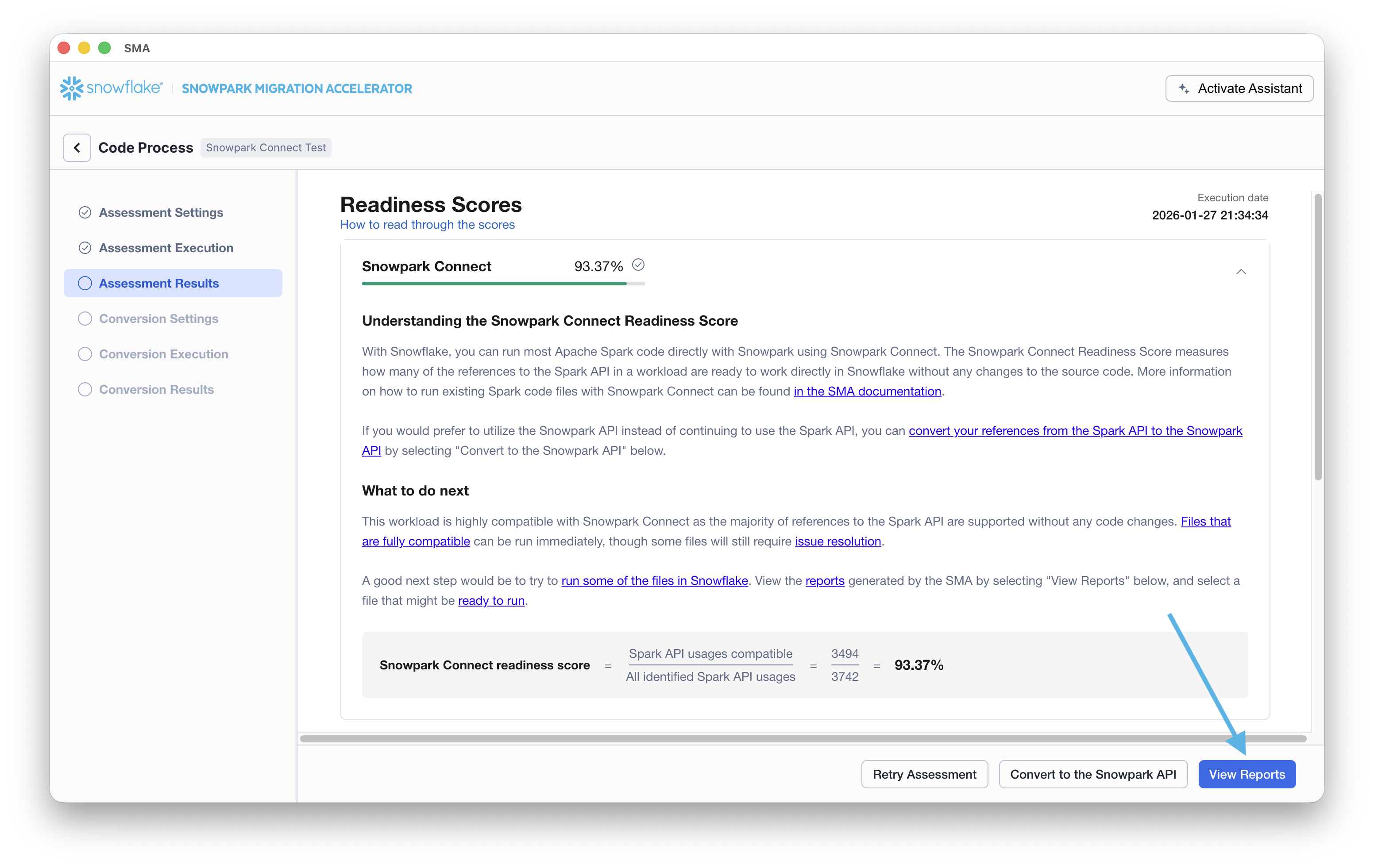
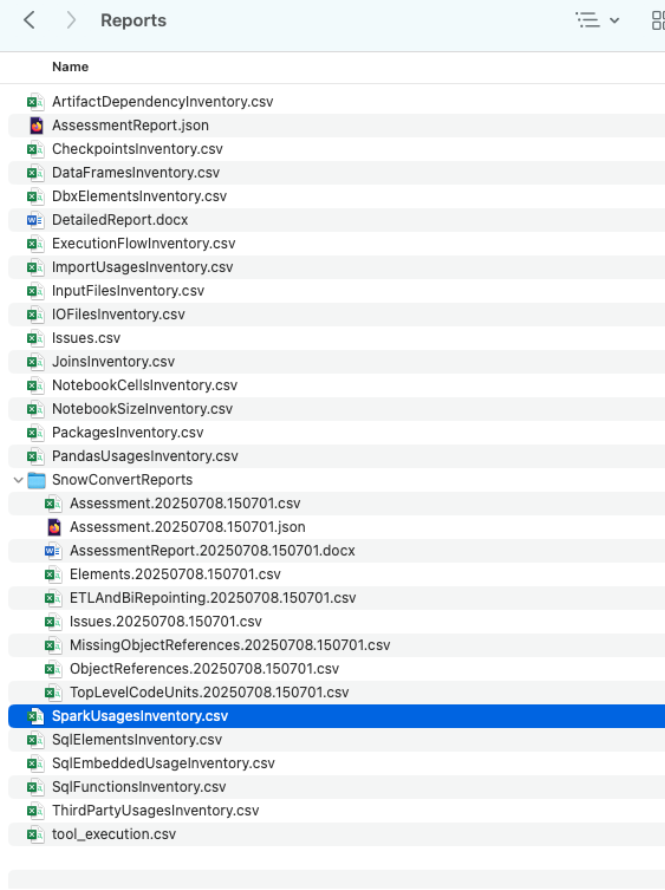
This will take you to a local directory that has a large number of inventories and other reports that the SMA generates.
-
Open the
SparkUsagesInventory.csvfile in a spreadsheet editor. -
Locate the IsSnowparkConnectSupported field.
This will give a TRUE or FALSE indicator of each element of the Spark API.

-
Pivot this spreadsheet to determine if there are any files that are fully supported.
-
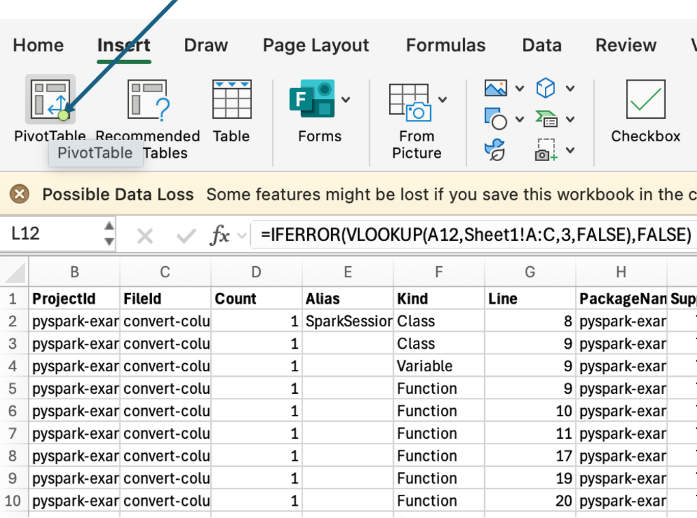
Insert a pivot table with the entire spreadsheet in the range for the pivot.
-
Select FileId as the row, and IsSnowparkConnectSupported as the column and values.
This will give you a result that looks like the following image:
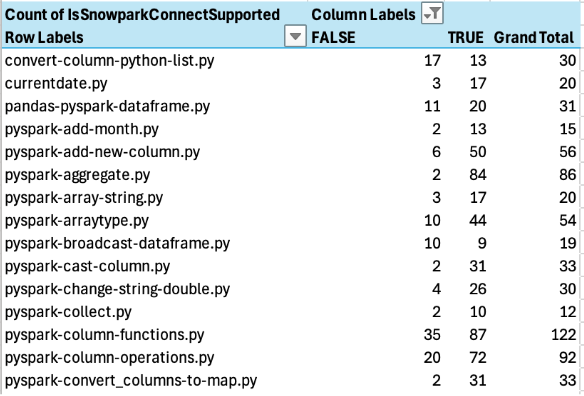
-
Sort the result by FALSE ascending (meaning, lowest to highest).
-
If there are any files that have zero unsupported references in Snowpark Connect, they will show up at the top.
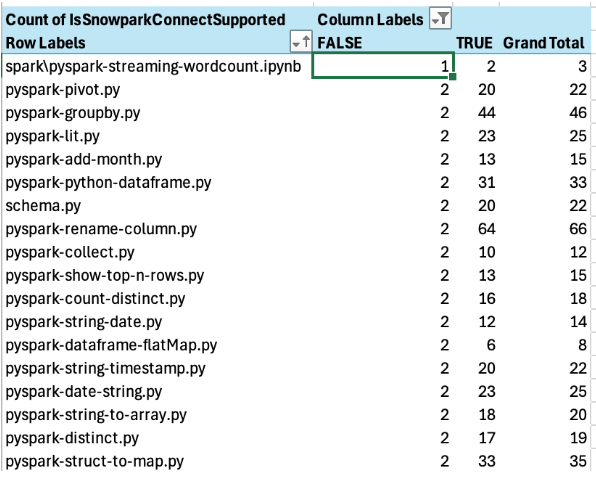
There are none in this example (the lowest count of unsupported references in a specific file is 1).
-
From this, you can use the artifact dependency output of the SMA to get the dependencies for the file list above.
With those dependencies, you can see what inputs or outputs may be present in order to run the file, and ultimately build a POC.
-