Introduction to streams¶
流对象记录对表所做的数据操作语言 (DML) 变更,包括插入(含 COPY INTO)、更新和删除,以及有关每项变更的元数据,以便可以使用变更的数据采取操作。此过程称为变更数据获取 (CDC)。本主题介绍使用流获取变更数据的关键概念。
单个表流可以跟踪对 源表 中的行所做的变更。表流(简称为“流”)提供了一个“变更表”,记录了表中两个事务时间点之间的行级变更情况。这样就能以事务方式查询和使用一系列变更记录。
可以创建流来查询以下对象的变更数据:
标准表,包括共享表
视图,包括安全视图
具有 :ref:`label-stream_limitations 的 Apache Iceberg™ 表 </user-guide/tables-iceberg>`。
Offset storage¶
在创建流时,流会将时间点(称为 偏移)初始化为对象的当前事务版本,从而通过逻辑方式获取源对象(例如表、外部表或视图的基础表)中每一行的初始快照。随后,流使用的变更跟踪系统会记录有关获取此快照后的 DML 变更的信息。变更记录提供了行在变更前后的状态。变更信息会镜像所跟踪源对象的列结构,并包括描述各变更事件的其他元数据列。
流使用当前表架构。然而,由于流可能读取已删除的数据以跟踪随时间的变化,因此偏移量和推进之间的任何不兼容架构更改都可能导致查询失败。
请注意,流本身 不 包含任何表数据。流仅存储源对象的偏移,并利用源对象的版本控制历史记录返回 CDC 记录。在创建表的第一个流时,源表中会添加多个隐藏列,并开始存储变更跟踪元数据。这些列会占用少量存储空间。在查询流时返回的 CDC 记录依赖于流中存储的 偏移 和表中存储的 变更跟踪元数据 的组合。请注意,对于视图上的流,必须为视图和基础表显式启用变更跟踪,只有这样才能向这些表添加隐藏列。
为了理解流,不妨将它视为书签,用来指示书籍(相当于源对象)页面中的某个时间点。您可以丢弃书签,也可以在书籍中的不同位置插入其他书签。同样,可以删除流,并在相同或不同的时间点创建其他流(方法有两种:在不同时间连续创建流,或者使用 Time Travel),以使用一个对象的偏移相同或不同的变更记录。
CDC 记录使用者的一个示例是数据管道,其中仅有符合此条件的数据才会转换并复制到其他表中:自上次提取以来发生过变更的暂存表中的数据。
Table versioning¶
每当将包含一条或多条 DML 语句的事务提交到该表时,都会创建新的表版本。这适用于以下表类型:
标准表
目录表
动态表
外部表
Apache Iceberg™ 表
视图的基础表
在表的事务历史记录中,流偏移位于两个表版本之间。查询流将返回由偏移之后、当前时间或之前提交的事务引起的变更。
以下示例在时间线中显示了具有 10 个已提交版本的源表。流 s1 的偏移目前介于表版本 v3 和 v4 之间。查询(或使用)流时,返回的记录包括表版本 v4 (在表时间线中紧接在流偏移之后)与 v10 (时间线中最近提交的表版本)之间的所有事务,包含这两个版本在内。
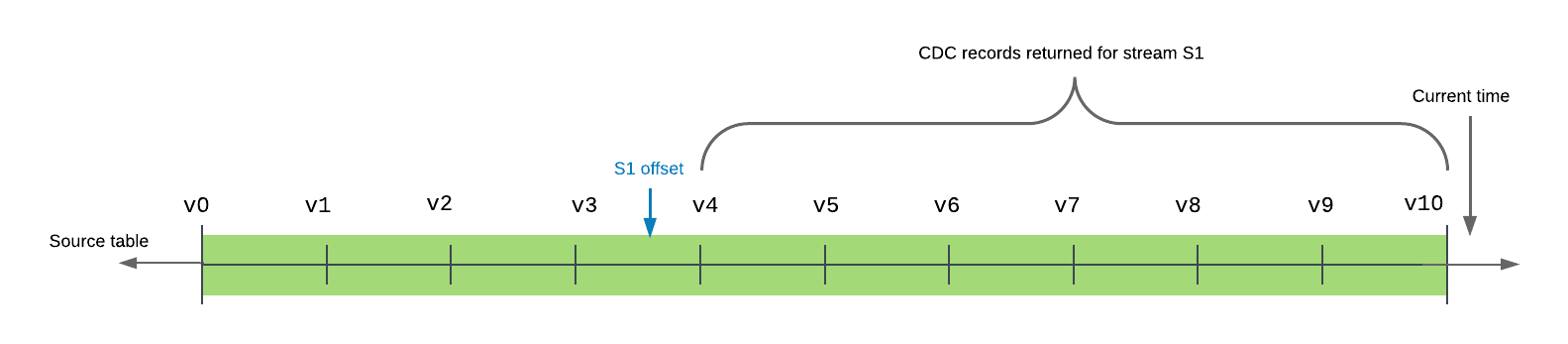
流提供从其当前偏移到表的当前版本的最小变更集。
多个查询可以独立使用流中的相同变更数据,而无需更改偏移。仅 当在 DML 事务中使用时,流才会推进偏移。这包括 Create Table As Select (CTAS) 事务或 COPY INTO 位置事务,此行为同时适用于显式和 自动提交 事务。(默认情况下,执行 DML 语句时,将会隐式启动自动提交事务,并在语句完成时提交事务。这种行为由 AUTOCOMMIT 参数控制。仅对流执行查询这项操作本身不会推进其偏移,即使在显式事务中也是如此;流内容必须在 DML 语句中使用。
备注
要将数据流的偏移推进到当前表版本,而不在 DML 操作中使用变更数据,请完成以下任一操作:
重建流(使用 CREATE OR REPLACE STREAM 语法)。
将当前变更数据插入到临时表中。在 INSERT 语句中查询流,但包含一个 WHERE 子句,用于筛选出所有变更数据(例如
WHERE 0 = 1)。
在 SQL 语句查询显式事务中的流时,在事务开始时的流推进点(即时间戳)而非语句运行时查询流。此行为既与 DML 语句有关,也与 CREATE TABLE ...AS SELECT (CTAS) 语句(使用现有流中的行填充新表)有关。
只要事务成功提交,从流中进行选择的 DML 语句就会使用流中的所有变更数据。为确保多个语句访问流中的相同变更记录,请将其置于显式事务语句 (BEGIN ..:doc:/sql-reference/sql/commit)。这样做将锁定流。并行事务中对源对象的 DML 更新由变更跟踪系统进行跟踪,但在提交显式事务语句并且消耗现有变更数据之前,不会对流进行更新。
Repeatable read isolation¶
Streams 支持可重复的读取隔离。在可重复读取模式下,事务中的多条 SQL 语句可查看流中的同一组记录。这与表支持的读取提交模式不同,在这种模式下,语句会查看在同一事务中执行的先前语句所做的任何变更,即使这些变更尚未提交。
在事务中,流返回的增量记录是从流的当前位置到事务开始时间的范围。如果事务提交,则流位置推进到事务开始时间;否则会保持在原位不变。
请参考以下示例:
时间 |
事务 1 |
事务 2 |
|---|---|---|
1 |
开始事务。 |
|
2 |
在表 |
|
3 |
更新表 |
|
4 |
查询流 |
|
5 |
提交事务。 如果流是在事务内的 DML 语句中使用的,则流位置将推进到事务开始时间。 |
|
6 |
开始事务。 |
|
7 |
查询流 |
在事务 1 中,所有对流 s1 的查询都会看到同一组记录。只有在提交事务时,对表 t1 的 DML 变更才会记录到流中。
在事务 2 中,对流的查询会看到记入事务 1 中表的变更。请注意,如果事务 2 在事务 1 提交 之前 就已经开始,则对流的查询将返回从流位置到事务 2 开始时间的流快照,并且不会看到由事务 1 提交的任何更改。
Stream columns¶
流存储的是源对象的偏移,而非任何实际的表列或数据。查询时,流会访问并返回与源对象形式相同(即具有相同的列名和排序)的历史数据,并包含如下额外的列:
- METADATA$ACTION:
指示记录到的 DML 操作(INSERT、DELETE)。
- METADATA$ISUPDATE:
指示操作是否是 UPDATE 语句的一部分。对源对象中行的更新表示为流中的一对 DELETE 和 INSERT 记录,其中元数据列 METADATA$ISUPDATE 的值设置为 TRUE。
请注意,流会记录两个偏移之间的差异。如果在当前偏移中添加了一行,随后进行了更新,则增量变更是新行。METADATA$ISUPDATE 行会记录一个 FALSE 值。
- METADATA$ROW_ID:
指定唯一的、不可变的行 ID 用于跟踪不同时间的变化。如果对流的源对象禁用 CHANGE_TRACKING,然后再重新启用,则行 ID 可能会改变。
Snowflake 就 METADATA$ROW_ID 提供以下保证:
METADATA$ROW_ID 取决于流的源对象。
例如,表
table1中的流stream1和表table1中的流stream2在相同的行中产生了相同的 METADATA$ROW_ID,但是视图view1中的流stream_view不能保证产生与stream1相同的 METADATA$ROW_ID,即使view使用CREATE VIEW view AS SELECT * FROM table1语句定义。源对象上的流和源对象克隆上的流会对克隆时存在的行产生相同的 METADATA$ROW_ID。
源对象上的流和源对象副本上的流会对复制的行产生相同的 METADATA$ROW_ID。
Types of streams¶
可用的流类型如下,划分依据是每种流类型记录到的元数据:
- Standard:
:emph:`支持标准表、动态表、Snowflake 管理的 Apache Iceberg™ 表、目录表或视图上的流。`标准(即增量)流跟踪对源对象的所有 DML 变更,包括插入、更新和删除(包括表截断在内)。这种流类型对变更集中插入和删除的行执行联接,以提供行级别增量。例如,最终效果是,在表中的两个事务时间点之间插入且随后删除的行将在增量中删除(即在查询流时不会返回此类行)。
备注
标准流无法检索地理空间数据的变更数据。我们建议在包含地理空间数据的对象上创建仅追加流。
- 仅追加:
:emph:`支持标准表、动态表、Snowflake 管理的 Apache Iceberg™ 表或视图上的流。`仅追加流专门跟踪行插入。仅追加流不会捕获更新、删除和截断操作。例如,如果最初向表中插入了 10 行,然后在仅追加流向前推进偏移量之前删除了其中的 5 行,那么该流将仅记录 10 行插入的记录。
仅追加流专门返回追加的行,因此在提取、加载和转换 (ELT),以及仅依赖于行插入的类似情景,其性能可能比标准流要高得多。例如,源表可在仅追加流中的行被使用后立即截断,并且下次查询或使用流时,该记录删除不会增加开销。
不支持在目标账户中使用辅助对象作为源创建仅追加流。
- 仅插入:
支持外部管理的 Apache Iceberg™ 或外部表上的流。`仅插入流只会跟踪行插入;它们不会记录从插入集中删除行的删除操作(即无操作)。例如,在任意两个偏移之间,如果从外部表引用的云存储位置中移除 ``File1` 并添加
File2,则此流仅返回File2中行的记录,无论File1是在请求的更改间隔之前还是之内添加都如此。与跟踪标准表的 CDC 数据不同,对云存储中文件的历史记录的访问不受 Snowflake 的控制,也无法得到其保证。覆盖或追加的文件实际上是作为新文件处理的:旧版本的文件将从云存储中删除,但仅插入流不会记录删除操作。新版本的文件将添加到云存储中,仅插入流会将行记录为插入。流不会记录旧文件版本与新文件版本的差异。请注意,追加操作可能不会触发外部表元数据的自动刷新,例如在使用 Azure AppendBlobs 时。
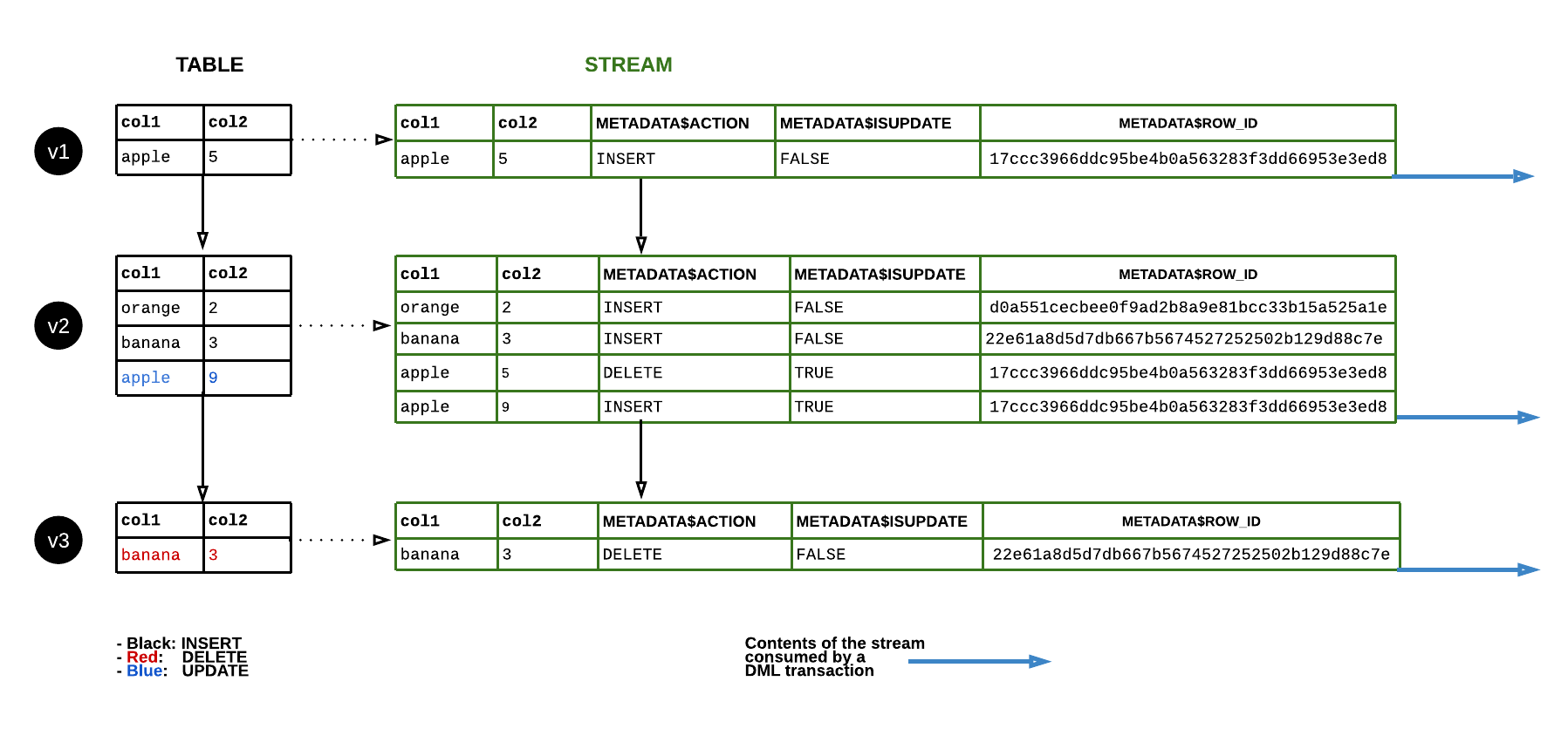
Data flow¶
下图显示了标准流的内容如何随着源表中行的更新而变化。每当 DML 语句使用流内容时,流位置都会推进,以跟踪对于表的下一组 DML 更改(即 表版本 中的更改):
Data retention period and staleness¶
在流的偏移超出其源表(或源视图的基础表)的数据保留期时,流将变为过期。在过时状态下,无法再访问源表的历史数据和任何未使用的变更记录。要继续跟踪新的变更记录,必须使用 CREATE STREAM 命令重新创建流。
为防止流过时,请在表的保留期内使用 DML 语句中的流记录,并定期在其 STALE_AFTER 时间戳(即在源对象的延长数据保留期内)之前使用其变更数据。此外,只要流为空且 SYSTEM$STREAM_HAS_DATA 函数返回 FALSE,则在流上调用 SYSTEM$STREAM_HAS_DATA 可防止其过期。
有关数据保留期的更多信息,请参阅 了解和使用 Time Travel。
备注
共享表或视图上的流不会分别延长表或基础表的数据保留期。有关更多信息,请参阅 共享对象上的流。
如果表的数据保留期不足 14 天,且流尚未被消耗,Snowflake 会暂时延长此时间段,以防止流过期。保留期将延长至流的偏移,默认情况下最多为 14 天,这与 Snowflake 版本 无关。Snowflake 可以为数据保留期延长的最大天数由 MAX_DATA_EXTENSION_TIME_IN_DAYS 参数值决定。在流被使用后,延长的数据保留期将恢复为表的默认值。
下表显示了 DATA_RETENTION_TIME_IN_DAYS 和 MAX_DATA_EXTENSION_TIME_IN_DAYS 值的示例,并指示为避免流过期,应该按照怎样的频率使用流内容:
DATA_RETENTION_TIME_IN_DAYS |
MAX_DATA_EXTENSION_TIME_IN_DAYS |
在 X 天内使用流 |
|---|---|---|
14 |
0 |
14 |
1 |
14 |
14 |
0 |
90 |
90 |
要查看流的过期状态,请使用 DESCRIBE STREAM 或 SHOW STREAMS 命令。STALE_AFTER 列时间戳指示源对象的延长数据保留期。它指示预测流在何时会过期,如果此时间戳是过去,则为其过期时间。此时间戳的计算方式是,将源对象的 DATA_RETENTION_TIME_IN_DAYS 或 MAX_DATA_EXTENSION_TIME_IN_DAYS 参数设置中较大的值与流的最后使用时间相加。
备注
如果源表的数据保留期在架构或数据库级别设置,则当前角色必须有权访问架构或数据库才能计算 STALE_AFTER 值。
使用流的变更数据会更新 STALE_AFTER 时间戳。尽管在 STALE_AFTER 时间戳之后的一段时间内可能会成功读取流数据,但流可能会随时过期。STALE 列指示流预计是否会过期,但可能尚未过期。
为了防止流过期,请在其 STALE_AFTER 时间戳之前(即在源对象的延长数据保留期内)定期使用其变更数据。在 STALE_AFTER 期限结束后,不要依赖流的结果,因为 STREAM_HAS_DATA 函数可能会返回意外的结果。
在 STALE_AFTER 时间戳过后,即使流没有未使用的记录,流也可能随时过期。即使源对象有变更数据,查询流时也可能返回 0 条记录。例如,仅追加流仅跟踪行插入,但更新和删除操作也会向源对象写入变更记录。此外,一些表写入操作(如重聚类)不会生成变更数据。使用流的变更数据时,会将其偏移提前到当前值,而不管中间是否有变更数据。
重要
重新创建对象(使用 CREATE OR REPLACE TABLE 语法)会删除其历史记录,这也会导致表或视图上的任何流过期。此外,重新创建或删除视图的任何基础表时,都会导致视图上的任何流过期。
目前,在克隆包含流及其源表(或源视图的基础表)的数据库或架构时,流克隆中任何未使用的记录都无法访问。此行为与表的 Time Travel 一致。如果克隆了表,则表克隆的历史数据将从创建克隆的时间/点开始。
重命名源对象不会中断流,也不会导致其过期。此外,如果删除了源对象并创建了具有相同名称的新对象,则链接到原始对象的任何流都 不会 链接到新对象。
Multiple consumers of streams¶
我们建议用户为对象变更记录的每个使用者创建一个单独的流。“使用者”是指利用 DML 事务使用对象变更记录的任务、脚本或其他机制。如本主题前面所述,仅当流在 DML 事务中使用时,其偏移才会推进。这包括 Create Table As Select (CTAS) 事务或 COPY INTO 位置事务。
在单个流中,变更数据的不同使用者会检索不同的增量,除非使用了 Time Travel。利用 DML 事务使用从流中的最新偏移获取到的变更数据时,流会推进偏移。变更数据不再可供下一个使用者使用。要为对象使用 相同 的变更数据,请为该对象创建多个流。流仅存储源对象的偏移,而 不 会存储任何实际的表列数据;因此,您可以为对象创建任意多个流,而不会产生高额的费用。
Streams on views¶
视图上的流支持本地视图,以及通过 Snowflake Secure Data Sharing 共享的视图,包括安全视图。目前,流无法跟踪物化视图中的变更。
流仅限于满足以下要求的视图:
- 基础表:
所有基础表都必须是原生表。
该视图仅可以应用以下操作:
Projections
筛选器
内联接或交叉联接
UNION ALL
只要完全展开的查询满足此要求表中的其他要求,就支持在 FROM 子句中使用嵌套视图和子查询。
- 查看查询:
一般要求:
查询可以选择任意多个列。
查询可包含任意多个 WHERE 谓词。
目前还不支持具有以下操作的视图:
GROUP BY 子句
QUALIFY 子句
不在 FROM 中未的子查询
相关子查询
LIMIT 子句
DISTINCT 子句
函数:
选择列表中的函数必须是由系统定义的标量函数。
- 变更跟踪:
必须在基础表中启用变更跟踪。
在视图上创建流之前,必须为视图的基础表启用变更跟踪。有关说明,请参阅 Enabling change tracking on views and underlying tables。
Join results behavior¶
如果一个流跟踪包含联接的视图的变更,在检查其结果时,了解所联接的数据非常重要。自流偏移以来,在左侧表上发生的变更将与右侧表联接,由于流偏移而在右侧表上发生的变更将与左侧表联接,两个表上自流偏移以来发生的变更将相互联接。
请参考以下示例:
创建了两个表:
创建了一个视图,以基于 id 联接两个表。每个表都有一行与另一行联接:
将会创建一个流,跟踪对视图的变更:
该视图有一个条目,而流没有条目,因为自流当前偏移以来,表没有发生任何变更:
对基础表进行更新后,选择 ordersByCustomerStream 将生成此记录: orders x Δ customers + Δ orders x customers + Δ orders x Δ customers,其中:
Δ
orders和 Δcustomers是自流偏移以来,每个表发生的变更。orders 和 customers 是表在当前流偏移处的整体内容。
请注意,由于 Snowflake 中的优化,计算此表达式的费用并非总是与输入大小成线性比例关系。
如果在 orders 中插入另一个联接行,则 ordersByCustomer 将有一个新行:
从 ordersByCustomersStream 中进行选择时,会产生一个新行,因为 Δ orders x customers 包含新插入,且 orders x Δ customers + Δ orders x Δ customers 为空:
如果随后将另一个联接行插入到 customers,则 ordersByCustomer 总共将有三个 新 行:
从 ordersByCustomersStream 中进行选择时,会生成三行,因为 Δ orders x customers、orders x Δ customers 和 Δ orders x Δ customers 各会生成一行:
请注意,对于仅追加流,Δ orders 和 Δ customers 将仅包含行插入,而 orders 和 customers 将包含表的完整内容,包括流偏移之前发生的任何更新。
CHANGES clause: Read-only alternative to streams¶
作为流的替代方案,Snowflake 支持为 SELECT 语句使用 CHANGES 子句查询表或视图的变更跟踪元数据。CHANGES 子句允许查询两个时间点之间的变更跟踪元数据,而不必创建具有显式事务偏移的流。使用 CHANGES 子句 不会 推进偏移(即使用记录)。多个查询可检索不同事务开始点和结束点之间的变更跟踪元数据。此选项要求使用 AT | BEFORE 子句指定元数据的事务开始点;可使用可选的 END 子句设置变更跟踪间隔的结束点。
流存储当前事务 表版本,在大多数情况下,均为 CDC 记录的适当来源。对于需要管理任意时间段偏移的罕见情况,可使用 CHANGES 子句。
目前,在记录变更跟踪元数据之前,必须满足以下条件:
- 表:
在表上启用变更跟踪(使用 ALTER TABLE ...CHANGE_TRACKING = TRUE),或在表上创建一个流(使用 CREATE STREAM)。
- 视图:
为视图及其基础表启用变更跟踪。有关说明,请参阅 Enabling change tracking on views and underlying tables。
启用变更跟踪会将多个隐藏列添加到表中,并开始存储变更跟踪元数据。这些隐藏 CDC 数据列中的值为流 元数据列 提供输入。这些列会占用少量存储空间。
在满足这些条件之一之前的时间段内,没有任何对象的变更跟踪元数据可用。
Required access privileges¶
若要查询流,至少需要具备以下角色权限的角色:
对象 |
权限 |
备注 |
|---|---|---|
数据库 |
USAGE |
|
架构 |
USAGE |
|
流 |
SELECT |
|
表 |
SELECT |
仅表上的流。 |
视图 |
SELECT |
仅视图上的流。 |
外部暂存区 |
USAGE |
仅目录表(位于外部暂存区中)上的流 |
内部暂存区 |
READ |
仅目录表上的流(位于内部暂存区中) |
Billing for streams¶
如本主题中的 数据保留期和过期 所述,如果流未得到定期使用,Snowflake 会 暂时 延长源表或源视图中基础表的数据保留期。如果表的数据保留期不足 14 天,则在后台,该期限将延长至流事务偏移或 14 天(如果表的数据保留期少于 14 天),以 较小 者为准,而不考虑账户的 Snowflake 版本。
延长数据保留期需要占用额外的存储空间,这将体现在您的每月存储费用中。
与流关联的主要费用是虚拟仓库为查询流而使用的处理时间。这些费用在账单上显示为您熟悉的 Snowflake Credit。
限制¶
以下限制适用于流:
您不能对使用外部目录的 Apache Iceberg™ 表使用标准流或仅追加流。(支持仅插入流。)
您无法使用 GROUP BY 子句跟踪视图上的更改。
在添加列或将列修改为 NOT NULL 后,如果流输出的行具有不允许的 NULL 值,则对流的查询可能会失败。发生这种情况是因为,流的架构强制执行当前 NOT NULL 约束,该约束与流返回的历史数据不匹配。
如果通过视图上的流 触发任务,则通过视图上的流查询引用的表的任何更改也将触发该任务,且不受该查询中任何联接、聚合或筛选操作的影响。
分区外部表或由外部目录管理的分区 Apache Iceberg™ 表不支持流。