Snowflake 关键概念和架构¶
Snowflake 由先进的数据平台提供支持,该平台作为自我管理的服务提供给您。Snowflake 的数据平台汇集了数据存储、处理和分析解决方案,这些解决方案比传统产品更快、更易于使用且更加灵活。
Snowflake 将全新的 SQL 查询引擎与专为云原生设计的创新架构结合在一起。它提供完整的企业分析数据库功能以及独特的特性和功能。
作为自我管理服务的数据平台¶
作为一项 自我管理的服务,Snowflake 具有以下优势:
没有可供您选择、安装、配置或管理的硬件(虚拟或物理)。
您几乎无需安装、配置或管理软件。
持续的维护、管理、升级和调整由 Snowflake 处理。
Snowflake 使用公共云基础设施来托管虚拟计算实例和持久数据存储。Snowflake 管理软件更新和基础设施,因此您无需管理。您无法在本地或私有云基础设施(无论是本地还是托管)上安装和运行 Snowflake。
Snowflake 架构¶
Snowflake 的架构是传统共享磁盘和无共享数据库架构的混合体。与共享磁盘架构类似,Snowflake 使用中央数据存储库来存储可从平台中的所有计算节点访问的持久数据。但与无共享架构类似,Snowflake 使用大规模并行处理 (MPP) 计算群集,其中群集中的每个节点都在本地存储整个数据集的一部分。如下图所示,这种混合架构提供了共享磁盘架构的数据管理简单性,但具有无共享架构的性能和横向扩展优势:
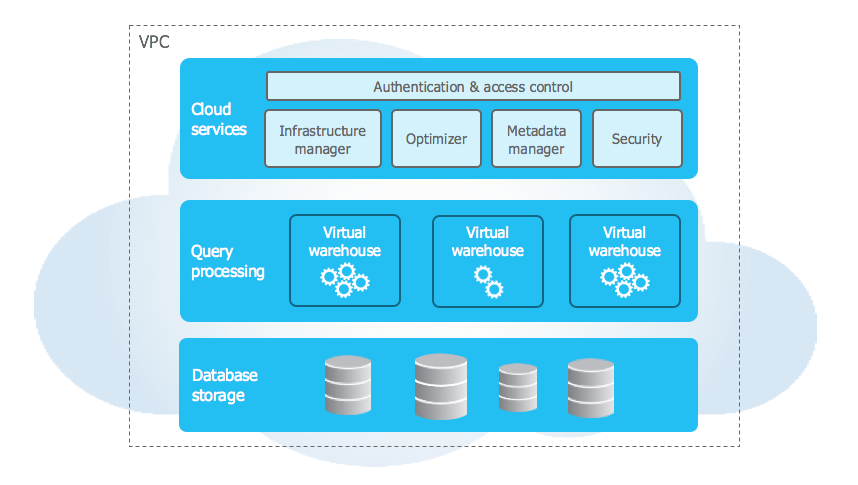
Snowflake 的独特架构具有以下关键层:
数据库存储¶
Snowflake 支持以下类型的数据:
结构化数据 – 例如表中的行和列,遵循严格的表格架构。
半结构化数据 – 例如 JSON 文件或 XML 文件,具有灵活的架构。
非结构化数据 – 例如文档、图像或音频文件,没有固有架构。
Snowflake 支持多种类型的表进行数据存储,包括以下表类型:
Snowflake 表¶
当数据加载到 Snowflake 表中时,Snowflake 会将该数据重新组织为其内部优化的压缩柱状格式。Snowflake 将这些优化数据存储在云存储中。Snowflake 表非常适合数据仓库。
Snowflake 管理此数据存储方式的各个方面,包括组织、文件大小、结构、压缩、元数据和统计数据。Snowflake 表中的所有数据都会自动划分到 微分区,微分区是连续的存储单元。微分区可提高效率并提供其他好处。
您可以使用 Snowflake 表来存储结构化和半结构化数据。您还可以将 FILE 数据类型 用于非结构化数据。
有关 Snowflake 表的更多信息,请参阅 了解 Snowflake 表结构。
Apache Iceberg™ 表¶
Snowflake 的 Apache Iceberg™ 表将典型 Snowflake 表的性能和查询语义与您管理的外部云存储结合在一起。它们非常适合您无法或选择不存储在 Snowflake 中的现有数据湖和数据湖屋。
Iceberg 表将其数据和元数据文件存储在外部云存储位置;例如,Amazon S3、Google Cloud Storage 或 Microsoft Azure Storage。外部存储不是 Snowflake 的一部分。
您可以使用 Iceberg 表来存储结构化和半结构化数据。
有关更多信息,请参阅 Apache Iceberg™ 表。
混合表¶
混合表使用基于索引的随机读写进行了优化,实现低延迟和高吞吐量。混合表支持行锁定,并能强制执行唯一性和参照完整性约束,这对事务性工作负载至关重要。您可以使用混合表以及其他 Snowflake 表和 Unistore 工作负载 的功能,将交易和分析数据整合到一个平台中。
您可以使用混合表来存储结构化和半结构化数据。
有关更多信息,请参阅 混合表。
计算¶
虚拟仓库 是 Snowflake 中的计算资源群集。虚拟仓库流程 SQL 语句,并使用 Snowpark,运行 Java、Python 和 Scala 等语言的代码。借助 Snowpark Connect for Spark,您还可以在虚拟仓库上运行 Apache Spark™ 工作负载。
每个虚拟仓库都是一个独立的计算群集,不与其他虚拟仓库共享计算资源。因此,每个虚拟仓库不会对其他虚拟仓库的性能产生影响。
有关更多信息,请参阅 虚拟仓库。
云服务¶
云服务层是协调 Snowflake 中活动的服务集合。这些服务将 Snowflake 的所有不同组件结合在一起,以便处理从登录查询调度的用户请求。云服务层同样运行在由 Snowflake 从云服务提供商处调配的计算实例上。
此层管理的服务包括以下内容:
适用于工作负载的集成功能¶
您不必将数据移动到不同的系统,以便不同的团队完成特定的操作和任务,而是可以通过一组集成的功能将所有工作负载直接引入他们的数据。
这些功能支持以下广泛的数据集成和开发领域:
数据工程¶
Snowflake 将存储和计算分开,这简化了数据工程的一些传统挑战,例如基础设施管理和性能调整。数据工程师可以专注于实施引入、转换和交付数据的管道。
Snowflake 提供了几种引入数据的方法,包括以下选项:
COPY INTO <table> 命令 – 将数据从文件加载到表中。
Snowpipe – 当文件在暂存区中可用时,立即加载文件中的数据。
Snowpipe Streaming – 使用 Snowflake SDKs 或 REST API,将行级数据以低延迟连续加载到 Snowflake 表和 Snowflake 管理的 Iceberg 表中,而不是从文件加载数据。
Openflow 连接器 – 使用基于 Apache NiFi 构建的连接器(例如 Microsoft Sharepoint 和 Google Drive)从特定来源引入数据。
Snowflake 连接器 – 从外部应用程序和系统连接,并将数据流式传输到 Snowflake 中。
Snowflake 还提供了几种转换数据的方法,包括以下选项:
动态表 – 定义根据目标新鲜度自动刷新的表和执行数据转换的查询。
流和任务 – 使用流获取对基础对象所做的更改,并定义执行数据转换的任务。
Snowpark – 使用 Python、Java 和 Scala 等编程语言执行更复杂的转换。
dbt – 使用开源数据转换工具和框架来定义、测试和部署 SQL 转换。
此外,SnowConvert AI 可以引入和转换数据,并且 Snowpark Migration Accelerator 可以将各种平台的代码转换为 Snowflake。
有关更多信息,请参阅 数据加载概述。
分析¶
借助 Snowflake,您可以根据需求动态扩展工作负载,访问不同类型的数据(包括结构化、半结构化和非结构化),并轻松共享数据。这些功能可让您分析存储在 Snowflake 中的数据,为分析用例(例如商业智能或预测建模)提取有意义的见解、模式和趋势。
Snowflake 提供了多种分析数据的方法,包括以下选项:
系统函数和 SQL 构造 – 使用以下 Snowflake 系统函数和 SQL 构造执行计算和统计分析:
聚合函数 – 通过对一组相关行执行计算并返回单个值来汇总数据。
窗口函数 – 对分区中的一组相关行执行计算,以便对每个分区中的行子集进行滚动操作,例如计算累计总数或移动平均线。
公用表表达式 (CTEs) – 提高复杂查询的可读性和可重用性,这些查询可能执行多个数据转换步骤。
Cortex AI Functions --- Run unstructured analytics on text and images with large language models (LLMs) from OpenAI, Anthropic, Meta, Mistral AI, and DeepSeek.
语义视图 – 将语义业务概念直接存储在数据库中,以定义业务指标并为业务实体及其关系建模。
AI 和 ML¶
Snowflake 简化了人工智能 (AI) 和机器学习 (ML) 功能,以便您可以使用 Snowflake 数据执行 AI 和 ML 特征工程、训练和推理。模型可以在安全的环境中访问最新数据。借助 Snowflake,您可以避免将数据移动到单独的平台进行 AI 和 ML 任务的成本和复杂性。
Snowflake 提供两大功能套件的 AI 和 ML 功能:
Snowflake Cortex – 使用 LLMs 的 AI 功能可理解非结构化数据,回答自由形式的问题,并提供智能帮助。Cortex AI functions 可以自动执行日常任务,例如简单的摘要和快速翻译。
Snowflake ML – 可用于构建自己的模型的功能。ML 函数 通过 ML 为您提供对数据的自动预测和见解。Snowflake ML 是一个统一的 ML 开发环境。
有关更多信息,请参阅 Snowflake AI 和 ML。
应用程序和协作¶
Snowflake 提供了多种构建应用程序并与团队、合作伙伴和客户共享应用程序的方法。当您使用 Snowflake 共享数据时,您可以控制对数据的访问,并避免在不同位置保持数据同步的挑战。
以下列表显示了一些可用于在 Snowflake 中构建、部署和管理应用程序的工具和服务:
Streamlit – 使用开源 Python 库创建和共享采用 ML 和数据科学的交互式用户界面 (UI) 的自定义 Web 应用程序。
Snowpark Container Services – 直接从 Snowflake 内部部署、管理和扩展容器化应用程序。
Snowflake Native App Framework – 通过与其他 Snowflake 账户共享数据和相关业务逻辑,构建可扩展其他 Snowflake 功能的应用程序。应用程序的业务逻辑可以包括 Streamlit 应用程序、存储过程和使用 Snowpark API、JavaScript 和 SQL 的编写的函数。Snowflake Native App 还可以使用 Snowpark Container Services 运行容器工作负载。
Snowflake 支持以下类型的协作:
Secure Data Sharing – 与其他 Snowflake 账户共享您账户中数据库中的选定对象。
列表 – 向其他 Snowflake 用户提供数据和其他信息,或访问 Snowflake 提供商共享的数据和其他信息。您可以私下或在 Snowflake Marketplace 上探索、访问并向使用者提供列表。
Data Clean Rooms --- Define what analyses can be run against the shared data, which allows the consumer to gather insights from the data without having unrestricted access to it.
Snowgrid¶
Snowgrid 是 Snowflake 的跨区域、跨云技术层。使用 Snowgrid,您可以实现以下目标:
通过使用 列表 和其他 协作功能,连接不同云区域和提供商的数据生态系统,例如 Amazon Web Services (AWS)、Microsoft Azure 和 Google Cloud。
应用一致 跨云和跨区域的安全和治理策略。
通过 复制 启用跨区域的灾难恢复和业务连续性功能:
有关更多信息,请参阅 Snowgrid。
连接到 Snowflake¶
Snowflake 支持多种连接服务的方式:
Snowsight 是一个基于 Web 的 UI,用于访问管理和使用 Snowflake 的所有方面。
命令行客户端,您还可以使用它来访问管理和使用 Snowflake 的各个方面;例如,Snowflake CLI。
原生 APIs 可用于以编程方式创建和管理 Snowflake 资源;例如,Snowflake Python APIs 和 Snowflake REST APIs。
其他应用程序可将其用于连接到 Snowflake 的 驱动程序;例如,JDBC 和 ODBC。
原生 连接器 可用于开发连接到 Snowflake 的应用程序;例如,Apache Kafka 和 Apache Spark。
第三方技术 可用于将应用程序连接到 Snowflake;例如,提取、转换、加载 (ETL) 工具(如 Informatica)和商业智能 (BI) 工具(例如 ThoughtSpot)。
有关更多信息,请参阅 登录 Snowflake。