Snowpark Checkpoints¶
Snowpark Checkpoints 是一个测试库,用于验证从 Apache PySpark (https://spark.apache.org/) 迁移到 Snowpark Python 的代码。它比较了两个平台上的 DataFrame 操作输出,确保 Snowpark 实现产生的结果在功能上与对应的 PySpark 等效。它致力于在整个迁移过程中保持数据完整性和分析一致性。
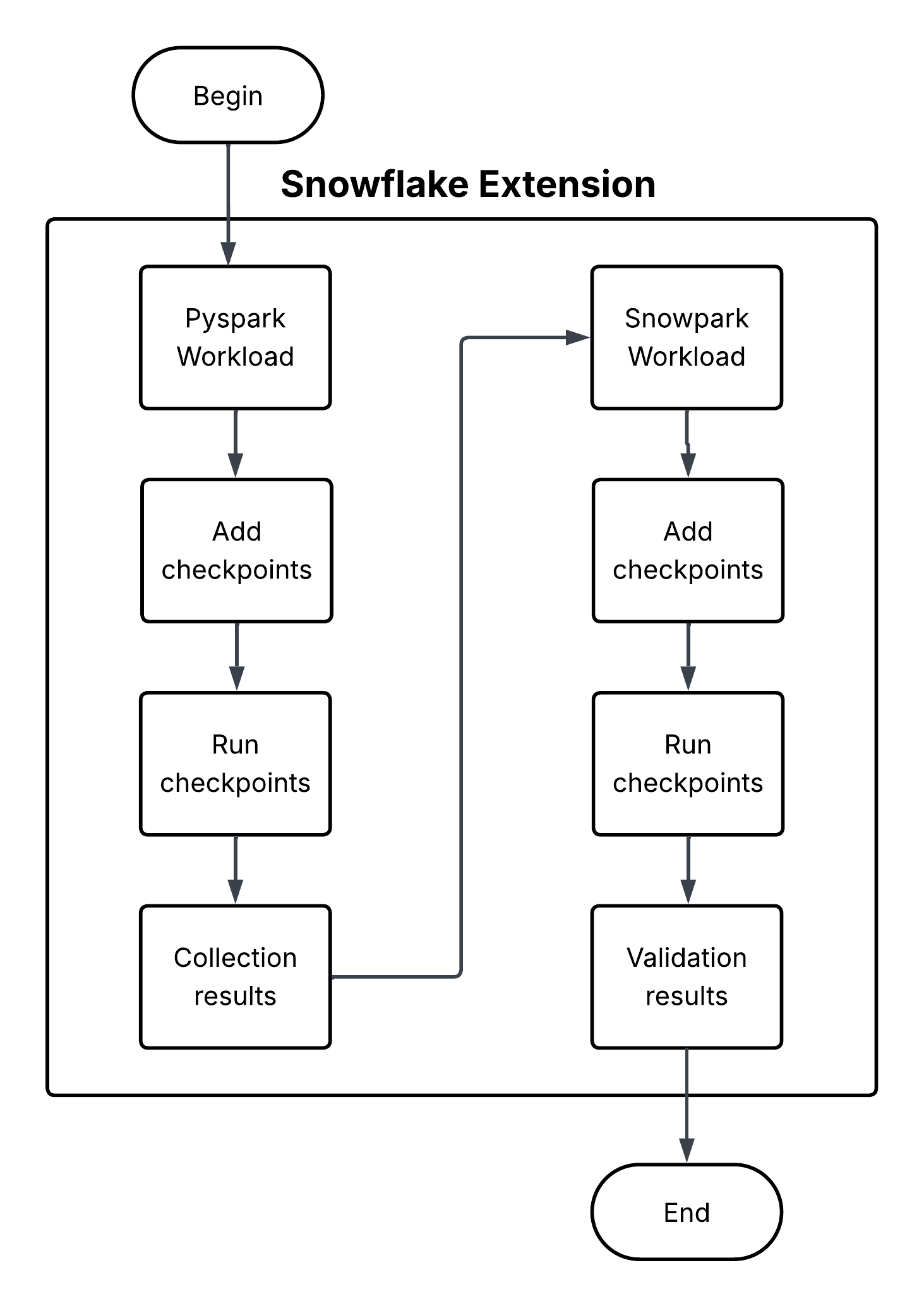
Snowpark Checkpoints 是一个测试库,用于验证从 Apache PySpark (https://spark.apache.org/) 迁移到 Snowpark Python 的代码。它比较了两个平台上的 DataFrame 操作输出,确保 Snowpark 实现产生的结果在功能上与对应的 PySpark 等效。它致力于在整个迁移过程中保持数据完整性和分析一致性。