Snowpark Checkpoints¶
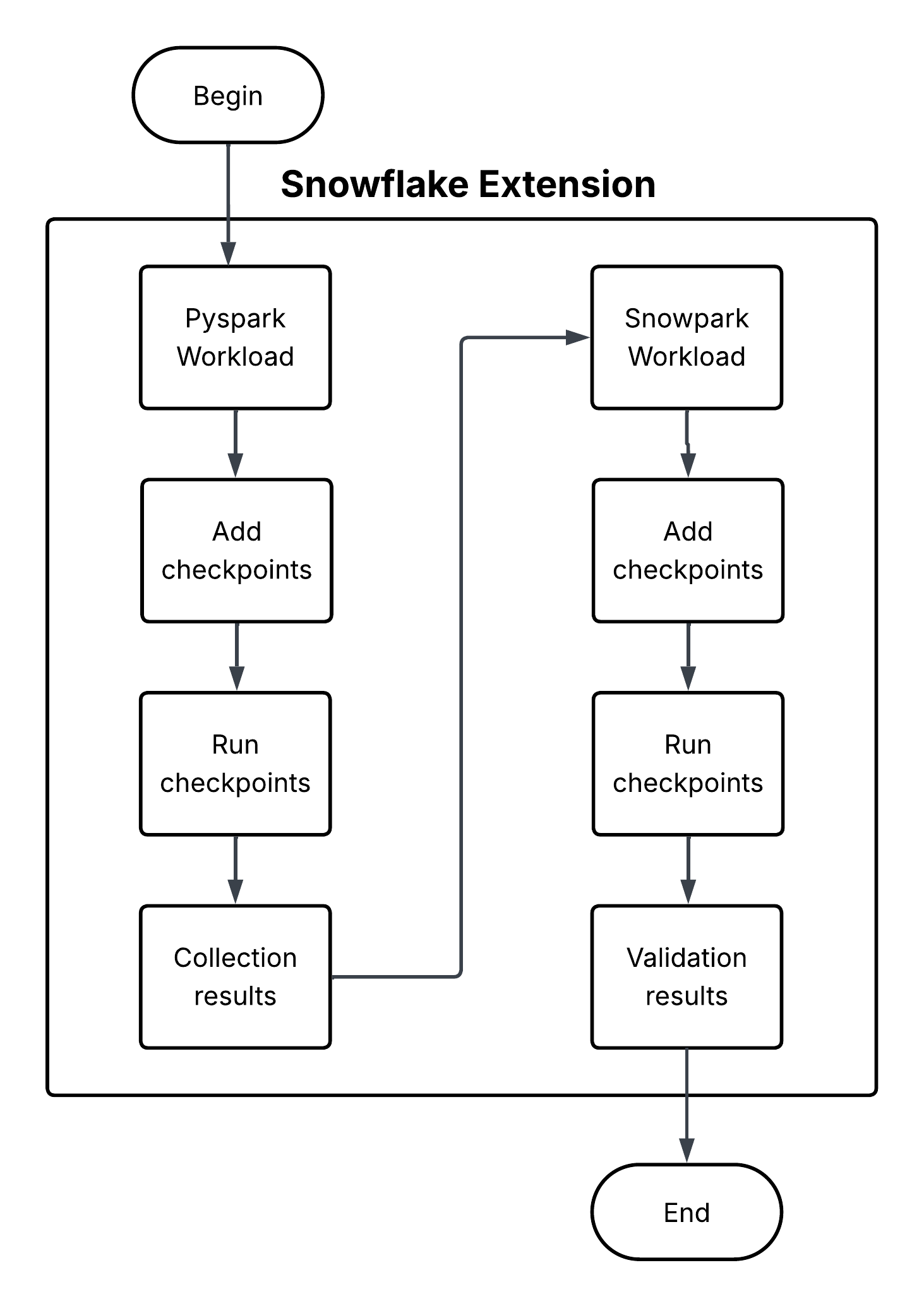
Snowpark Checkpoints is a testing library that validates code migrated from Apache PySpark (https://spark.apache.org/) to Snowpark Python. It compares the outputs of DataFrame operations across both platforms, ensuring that Snowpark implementations produce results that are functionally equivalent to their PySpark counterparts. It strives to maintain data integrity and analytical consistency throughout the migration process.