使用 JDBC 驱动程序¶
本主题提供有关如何使用 JDBC 驱动程序的信息。
Snowflake JDBC API 扩展¶
Snowflake JDBC 驱动程序支持标准 JDBC 规范之外的其他方法。本节介绍如何使用展开来访问特定于 Snowflake 的方法,然后介绍可能需要展开的三种情况:
展开特定于 Snowflake 的类¶
Snowflake JDBC 驱动程序支持特定于 Snowflake 的方法。这些方法在特定于 Snowflake 的 Java 语言接口中定义,例如 SnowflakeConnection、SnowflakeStatement 和 SnowflakeResultSet。例如, SnowflakeStatement 接口包含不在 JDBC 语句接口中的 getQueryID() 方法。
当要求 Snowflake JDBC 驱动程序创建 JDBC 对象(例如,通过调用 Connection 对象的 createStatement() 方法创建 JDBC Statement 对象)时,Snowflake JDBC 驱动程序实际上会创建特定于 Snowflake 的对象,这些对象不仅实现了标准的 JDBC 方法,还实现了 Snowflake 接口中的其他方法。
要访问这些 Snowflake 方法,请“展开”对象(如 Statement 对象)以公开 Snowflake 对象及其方法。然后,您可以调用其他方法。
下面的代码演示如何展开 JDBC Statement 对象以公开接口的 SnowflakeStatement 方法,然后调用其中一个方法,在本例中,setParameter 如下所示:
执行异步查询¶
Snowflake JDBC 驱动程序支持异步查询,例如在查询完成前将控制权交还给用户的查询。您可以启动查询,然后使用轮询来确定查询何时完成。查询完成后,用户即可读取结果集。
此功能允许客户端程序并行运行多个查询,而客户端程序本身无需使用多线程。
异步查询使用添加到 SnowflakeConnection、SnowflakeStatement、SnowflakePreparedStatement 和 SnowflakeResultSet 类中的方法。
备注
要执行异步查询,您必须确保 ABORT_DETACHED_QUERY 配置参数为 ``FALSE``(默认值)。
如果客户端连接断开:
对于同步查询,无论参数值如何,所有正在进行的同步查询都会立即中止。
对于异步查询:
如果 ABORT_DETACHED_QUERY 设置为
FALSE,正在进行的异步查询将继续运行,直到它们正常结束。如果 ABORT_DETACHED_QUERY 设置为
TRUE,则 Snowflake 会在 5 分钟后客户端未重新建立连接的情况下,自动中止所有正在进行的异步查询。您可以通过调用
cursor.query_result(queryId)来防止异步查询在 5 分钟标记处中止。由于查询仍在运行,因此此调用不会检索实际查询结果,但可以防止查询被取消。调用query_result是同步操作,它可能适合您的特定使用案例,也可能不适合。
您可以在同一会话中混合运行同步查询和异步查询。
备注
异步查询不支持 PUT/GET 语句。
当使用 executeAsyncQuery(query) 时,Snowflake JDBC 驱动程序会自动跟踪异步提交的查询。当使用 connection.close() 显式关闭连接时,系统会检查异步查询列表,如果其中任何查询仍在运行,则不会删除 Snowflake 端的会话。
如果同一连接中没有运行任何异步查询,则属于该连接的 Snowflake 会话将在调用 connection.close() 时注销,这会隐式取消在同一会话中运行的所有其他查询。
此行为还取决于 SQL ABORT_DETACHED_QUERY 参数。有关更多信息,请参阅 ABORT_DETACHED_QUERY 参数 文档。
最佳实践是将所有长时间运行的异步任务(尤其是那些计划在连接关闭后继续运行的任务)隔离到单独的连接中。
为了更好地理解驱动程序业务逻辑的层级结构以及 ABORT_DETACHED_QUERY 参数的交互,请参阅以下流程图:
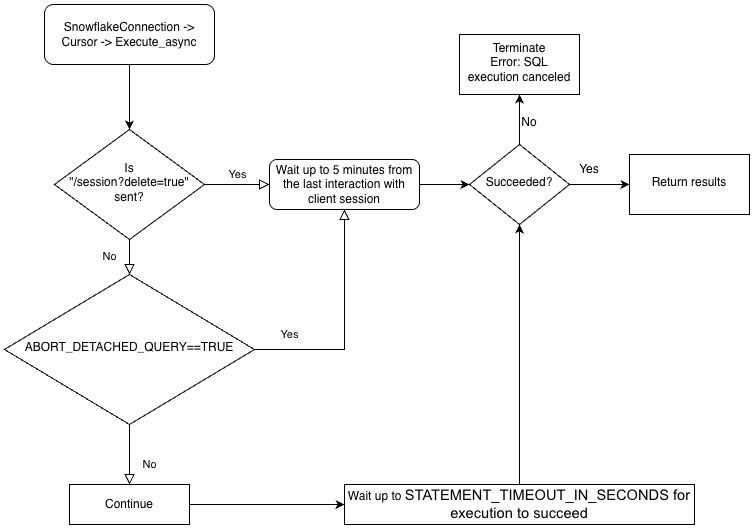
异步查询的最佳实践¶
在并行运行任何查询之前,请确保您了解哪些查询依赖于其他查询。相互依赖且对顺序敏感的查询不适合并行化。例如,INSERT 语句不应在相应的 CREATE TABLE 语句完成之前开始。
确保运行的查询数量不要超过可用内存承受能力。并行运行多个查询通常会消耗更多内存,尤其是在内存中同时存储多个 ResultSet 查询时。
轮询时,处理查询不成功的罕见情况。例如,避免以下潜在的无限循环:
请改用类似于以下内容的代码:
请改用类似于以下内容的代码:
确保事务控制语句(BEGIN、COMMIT 和 ROLLBACK)不与其他语句并行执行。
异步查询示例¶
这些示例中的大多数都要求程序导入类,如下所示:
下面是一个非常简单的示例:
此示例存储查询 ID,关闭连接,重新打开连接,并使用查询 ID 检索数据:
下面是一个非常简单的示例:
此示例存储查询 ID,关闭连接,重新打开连接,并使用查询 ID 检索数据:
将数据文件直接从流上传到内部暂存区¶
您可以使用 PUT 命令上传数据文件。但是,有时将数据作为文件直接从流传输到内部(即 Snowflake)暂存区是有意义的。(暂存区 可以是任何内部暂存区类型:表暂存区、用户暂存区或命名暂存区。JDBC 驱动程序不支持上传到外部暂存区。)下面是 SnowflakeConnection 类中公开的方法:
示例用法:
示例用法:
为 3.9.2 之前的 JDBC 驱动程序版本编写的代码可能会转换 SnowflakeConnectionV1 而不是展开 SnowflakeConnection.class。例如:
备注
使用较新版本的驱动程序的客户应更新其代码以使用 unwrap。
将数据文件直接从内部暂存区下载到流¶
您可以使用 GET 命令下载数据文件。但是,有时将数据直接从内部(即 Snowflake)暂存区的文件传输到流是有意义的。(暂存区 可以是任何内部暂存区类型:表暂存区、用户暂存区或命名暂存区。JDBC 驱动程序不支持下载到外部暂存区。)下面是 SnowflakeConnection 类中公开的方法:
示例用法:
示例用法:
为 3.9.2 之前的 JDBC 驱动程序版本编写的代码可能会转换 SnowflakeConnectionV1 而不是展开 SnowflakeConnection.class。例如:
多语句支持¶
本节介绍如何使用 JDBC 驱动程序 在单个请求中执行多条语句。
备注
在单个查询中执行多个语句要求会话中有一个可用的有效仓库。
默认情况下,Snowflake 会针对使用多个语句发出的查询返回错误,以防止 SQL 注入 (link removed)。在单个查询中执行多个语句会增加 SQL 注入。Snowflake 建议谨慎使用。要减少 SQL 注入风险,请使用
SnowflakeStatement类的setParameter()方法来指定要执行的语句数,这使得通过追加语句来注入语句变得更加困难。有关SnowflakeStatement的更多信息,请参阅 接口:SnowflakeStatement。
发送多个语句并处理结果¶
包含多个语句的查询的执行方式与具有单个语句的查询相同,但查询字符串包含多个用分号分隔的语句。
有两种方法可以允许多个语句:
调用 Statement.setParameter(“MULTI_STATEMENT_COUNT”,n)指定一次应允许执行多少条语句。有关详细信息,请参见下文。
通过执行以下命令之一,在会话级别或账户级别设置 MULTI_STATEMENT_COUNT 参数:
或者:
将该参数设置为 0 时,语句数量不受限制。将参数设置为 1 时,一次只能执行一条语句。
为了增加 SQL 注入攻击的难度,用户可以调用 setParameter 方法来指定单次调用中要执行的语句数,如下所示。在此示例中,单次调用中要执行的语句数为 3:
默认语句数为 1;换言之,多语句模式处于关闭状态。
若要在不指定确切数字的情况下执行多个语句,请传递值 0。
MULTI_STATEMENT_COUNT 参数不是 JDBC 标准的一部分;而是 Snowflake 扩展。此参数会影响多个 Snowflake 驱动程序/连接器。
在单个 execute() 调用中执行多条语句时,第一条语句的结果可通过标准 getResultSet() 和 getUpdateCount() 方法获得。若要访问后续语句的结果,请使用 getMoreResults() 方法。当有更多语句可供迭代时,此方法将返回 true,否则返回 false。
下面的示例设置了 MULTI_STATEMENT_COUNT 参数,执行了 3 条语句,并检索更新计数和结果集:
对于多语句查询,Snowflake 建议使用 execute()。executeQuery() 和 executeUpdate() 方法也支持多语句查询,但如果第一个结果不是预期的结果类型(分别为结果集和更新计数),则会引发异常。
失败的语句¶
如果任何 SQL 语句编译或执行失败,则执行将中止。之前运行的任何语句均不受影响。
例如,如果以下语句作为单个多语句查询运行,则查询将在进行到第三个语句时失败,并且将引发异常。
如果您要查询表 test 中的内容,则值 1 和 2 将会出现。
不支持的功能¶
多语句查询不支持 PUT 和 GET 语句。
多语句查询也不支持准备语句和使用绑定变量。
将变量绑定到语句¶
绑定 允许 SQL 语句使用存储在 Java 变量中的值。
简单绑定¶
在没有绑定的情况下,SQL 语句通过在语句中指定字面量来指定值。例如,以下语句在 UPDATE 语句中使用字面量值 42 :
通过绑定,可以使用变量中的值执行 SQL 语句。例如:
VALUES 子句中的 ? 表示 SQL 语句使用变量的值。setInt() 方法指定用名为 my_integer_variable 的变量中的值替换 SQL 语句中的第一个问号。请注意,setInt() 使用的是从 1 开始的值,而不是从 0 开始的值(即第一个问号的引用值是 1,而不是 0)。
将变量绑定到时间戳列¶
Snowflake 支持三种不同的时间戳变体:TIMESTAMP_LTZ、TIMESTAMP_NTZ、TIMESTAMP_TZ。当您调用 PreparedStatement.setTimestamp 将变量绑定到时间戳列时,JDBC 驱动程序会根据本地时区 (TIMESTAMP_LTZ) 或作为实参传递的 Calendar 对象的时区来解释时间戳值:
如果希望驱动程序使用不同的变体(例如 TIMESTAMP_NTZ)来解释时间戳,请使用以下方法之一:
将会话参数 CLIENT_TIMESTAMP_TYPE_MAPPING 设置为变体。
请注意,该参数会影响当前会话的所有绑定操作。如果需要更改变体(例如改回
TIMESTAMP_LTZ),则必须重新设置此会话参数。(在 JDBC 驱动程序 3.13.3 及更高版本中)调用
PreparedStatement.setObject方法,并使用targetSqlType参数指定以下 Snowflake 时间戳变体之一:SnowflakeType.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeType.EXTRA_TYPES_TIMESTAMP_TZSnowflakeType.EXTRA_TYPES_TIMESTAMP_NTZSnowflakeType.EXTRA_TYPES_VECTORSnowflakeType.EXTRA_TYPES_DECFLOATSnowflakeType.EXTRA_TYPES_YEAR_MONTH_INTERVALSnowflakeType.EXTRA_TYPES_DAY_TIME_INTERVAL
例如:
SnowflakeUtil.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_TZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_NTZ
例如:
批处理插入¶
在 Java 应用程序代码中,可以通过在 INSERT 语句中绑定参数并调用 addBatch() 和 executeBatch() 来在单个批处理中插入多行。
例如,下面的代码在包含 INTEGER 列和 VARCHAR 列的表中插入两行。该示例将值与 INSERT 语句中的参数绑定,并调用 addBatch() 和 executeBatch() 执行批处理插入。
使用此技术插入大量值时,驱动程序可以通过将数据流传输(而无需在本地计算机上创建文件)到临时暂存区进行引入来提高性能。当值数超过阈值时,驱动程序会自动执行此操作。
此外,您必须设置会话的当前数据库和架构。如果未设置这些值,则驱动程序执行的 CREATE TEMPORARY STAGE 命令可能会失败,并出现以下错误:
备注
有关将数据加载到 Snowflake 数据库的其他方法(包括使用 COPY 命令进行批量加载),请参阅 将数据载入 Snowflake。
Java 示例程序¶
对于用 Java 编写的工作示例,请右键单击文件的名称 (SnowflakeJDBCExample.java),然后将链接/文件保存到本地文件系统。
故障排除¶
I/O 错误:连接重置¶
在某些情况下,JDBC 驱动程序可能会在一段时间不活动后失败并显示以下错误消息:
您可以通过为连接设置特定的“生效时间”来解决此问题。如果连接处于空闲状态的时间超过“生效时间”,则 JDBC 驱动程序将从连接池中删除该连接,并创建新连接。
若要设置生效时间,请将名为 net.snowflake.jdbc.ttl 的 Java 系统属性设置为连接应生效的秒数:
若要以编程方式设置此属性,请调用
System.setProperty:若要在运行
java命令时设置此属性,请使用-D标志:
net.snowflake.jdbc.ttl 属性的默认值为 -1,这意味着不会从连接池中移除空闲连接。
处理错误¶
在处理 JDBC 应用程序的错误和异常时,您可以使用 Snowflake 提供的 ` ErrorCode.java <https://github.com/snowflakedb/snowflake-jdbc/blob/master/src/main/java/net/snowflake/client/jdbc/ErrorCode.java (https://github.com/snowflakedb/snowflake-jdbc/blob/master/src/main/java/net/snowflake/client/jdbc/ErrorCode.java)>`_ 文件来确定问题的原因。JDBC 驱动程序特有的错误代码以 2 开头,形式如下:2NNNNN。
备注
公共 snowflake-jdbc git 存储库中的 ErrorCode.java 的链接指向该文件的最新版本,该版本可能与您当前使用的 JDBC 驱动程序版本不同。