Channels and exactly-once delivery¶
This topic explains how Snowpipe Streaming ingests data through channels with ordering guarantees and how offset tokens enable exactly-once delivery.
Streaming ingestion fundamentals¶
Snowpipe Streaming is built around several core streaming ingestion principles:
- Continuous ingestion: Data flows into Snowflake as it is produced, rather than being collected into batches and loaded periodically. Applications submit rows continuously through long-lived connections, and Snowflake commits the data automatically.
- Exactly-once delivery: Each record is ingested exactly once, even in the event of client failures or network interruptions. Snowpipe Streaming achieves this through offset token tracking, which lets clients resume from the last committed position without duplicating data.
- Ordered ingestion: Rows are committed in the order they are submitted within a channel. This preserves the sequence of events from the source system, which is critical for time-series data, CDC pipelines, and audit trails.
- Low latency: Data becomes available for query in as low as 5 seconds after ingestion. This enables near-real-time analytics without the delays of traditional batch loading.
- Serverless: Snowflake manages all compute resources for ingestion. Resources scale automatically based on throughput, with no infrastructure for the client to provision or manage.
How data flows¶
A client application connects to Snowflake using a Snowpipe Streaming SDK (Java, Python, or Node.js) or the REST API. The client opens one or more channels against a pipe, then submits rows through those channels. Snowflake buffers and commits the data to the target table, making it available for query within seconds.
The end-to-end flow:
- Client application submits rows using the SDK (
appendRows) or the REST API (Append Rowsendpoint). - Channel receives the rows in order and associates each batch with an offset token for progress tracking.
- Pipe processes the data server-side: validates the schema, applies any configured transformations or pre-clustering, then commits to the target table.
- Target table receives the committed data, which becomes immediately queryable.
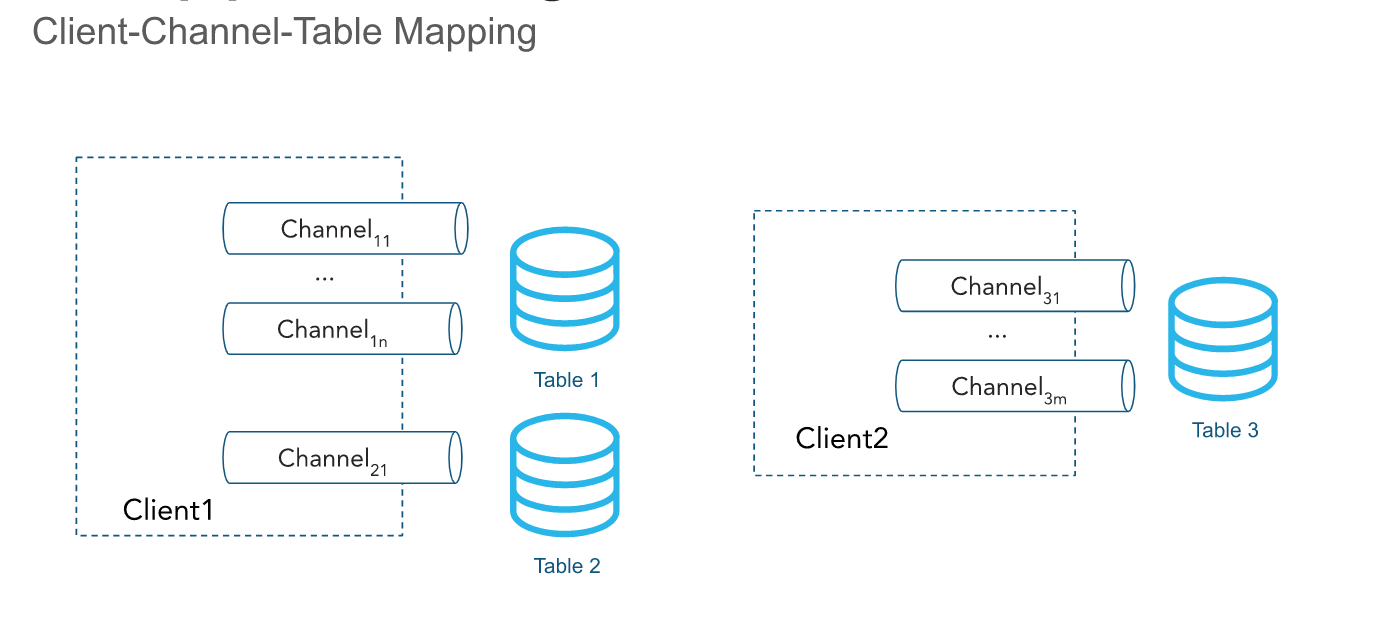
Channels¶
A channel is a logical, named streaming connection to Snowflake for loading data into a table. Channels provide two guarantees:
- Ordered ingestion: The ordering of rows and their corresponding offset tokens is preserved within a channel.
- Exactly-once delivery: Offset tokens enable clients to track committed progress and replay from the last committed position on recovery.
Ordering is preserved within a channel but not across channels that point to the same table.
Channels are opened against a pipe. The client SDK can open multiple channels to multiple pipes; however, the SDK can’t open channels across accounts. Channels are meant to be long lived when a client is actively inserting data and should be reused across client process restarts because offset token information is retained.
You can permanently drop channels by using the DropChannelRequest API when you no longer need the channel and the associated offset metadata. You can drop a channel in two ways:
- Dropping a channel at closing. Data inside the channel is automatically flushed before the channel is dropped.
- Dropping a channel blindly. We don’t recommend this approach because it discards any pending data.
You can run the SHOW CHANNELS command to list the channels for which you have access privileges. For more information, see SHOW CHANNELS.
Note
Inactive channels, along with their offset tokens, are deleted automatically after 30 days of inactivity.
Offset tokens and exactly-once delivery¶
Tip
How exactly-once works in Snowpipe Streaming: Your application submits rows with an offset token (for example, a Kafka partition offset). Snowflake persists the token when the data is committed. On recovery, your application calls getLatestCommittedOffsetToken to find where it left off, then replays from that position. No duplicate data is ingested, and no data is lost.
An offset token is a string that a client includes in row-submission requests to track ingestion progress on a per-channel basis. The specific methods used are appendRow or appendRows for the SDK and the Append Rows endpoint for the REST API.
The token is initialized to NULL on channel creation and is updated when the rows with a provided offset token are committed to Snowflake. Clients can periodically call getLatestCommittedOffsetToken to get the latest committed offset token for a channel and use that to reason about ingestion progress.
When a client re-opens a channel, the latest persisted offset token is returned. The client can reset its position in the data source by using the token to avoid sending the same data twice. When a channel re-open event occurs, any uncommitted data buffered in Snowflake is discarded to avoid committing it.
You can use the latest committed offset token to perform the following:
- Track ingestion progress
- Check whether a specific offset has been committed by comparing it with the latest committed offset token
- Advance the source offset and purge the data that has already been committed
- Enable de-duplication and ensure exactly-once delivery of data
Example: Kafka connector crash recovery
The Kafka connector reads an offset token from a topic such as <partition>:<offset>. Consider the following scenario:
-
The Kafka connector comes online and opens a channel corresponding to
Partition 1in Kafka topicTwith the channel nameT:P1. -
The connector begins reading records from the Kafka partition.
-
The connector calls the API, making an
appendRowsmethod request, with the offset associated with the record as the offset token.For example, the offset token could be
10, referring to the tenth record in the Kafka partition. -
The connector periodically makes
getLatestCommittedOffsetTokenmethod requests to determine the ingest progress.
If the Kafka connector crashes, the following procedure resumes reading records from the correct offset:
-
The Kafka connector comes back online and re-opens the channel, using the same name as earlier.
-
The connector calls
getLatestCommittedOffsetTokento get the latest committed offset for the partition.For example, assume the latest persisted offset token is
20. -
The connector uses the Kafka read APIs to reset a cursor corresponding to the offset plus 1 (
21in this example). -
The connector resumes reading records. No duplicate data is retrieved after the read cursor is repositioned successfully.
Example: Log file ingestion with crash recovery
An application reads logs from a directory and uses the Snowpipe Streaming SDK to export those logs to Snowflake. The application does the following:
-
Lists files in the log directory.
Assume that the logging framework generates log files that can be ordered lexicographically and that new log files are positioned at the end of this ordering.
-
Reads a log file line by line and calls the API, making
appendRowsmethod requests with an offset token corresponding to the log file name and the line count or byte position.For example, an offset token could be
messages_1.log:20, wheremessages_1.logis the name of the log file, and20is the line number.
If the application crashes or needs to be restarted, it calls getLatestCommittedOffsetToken to retrieve the offset token that corresponds to the last exported log file and line. Continuing with the example, this could be messages_1.log:20. The application then opens messages_1.log and seeks line 21 to prevent the same log line from being ingested twice.
Note
The offset token information can be lost. The offset token is linked to a channel object, and a channel is automatically cleared if no new ingestion is performed using the channel for a period of 30 days. To prevent the loss of the offset token, consider maintaining a separate offset and resetting the channel’s offset token if required.
Roles of offsetToken and continuationToken¶
Both offsetToken and continuationToken are used to ensure exactly-once data delivery, but they serve different purposes and are managed by different subsystems. The primary distinction is who controls the token’s value and the scope of its use.
-
continuationToken(only used by direct REST API users):This token is managed by Snowflake and is essential for maintaining the state of a single, continuous streaming session. When a client sends data using the
Append RowsAPI, Snowflake returns acontinuationToken. The client must pass back this token in its next AppendRows request to ensure the data is received by Snowflake in the correct order and without gaps. Snowflake uses the token to detect and prevent duplicate data or missing data in the event of an SDK retry. -
offsetToken:This token is a user-defined identifier that enables exactly-once delivery from an external source. Snowflake stores this value but doesn’t use it for its own internal operations or to prevent re-ingestion. It is the responsibility of the external system, such as a Kafka connector, to read the offsetToken from Snowflake and use it to track its own ingestion progress and avoid sending duplicate data if the external stream needs to be replayed.