Replication considerations¶
This topic describes the behavior of certain Snowflake features in secondary databases and objects when replicated with replication or failover groups or database replication, and provides general guidance for working with replicated objects and data.
If you have previously enabled database replication for individual databases using the ALTER DATABASE … ENABLE REPLICATION TO ACCOUNTS command, see Database replication considerations for additional considerations specific to database replication.
Replication group and failover group constraints¶
The following sections explain the constraints around adding account objects, databases, and shares to replication and failover groups.
Database and share objects¶
The following constraints apply to database and share objects:
- An object can only be in one failover group.
- An object can be in multiple replication groups as long as each group is replicated to a different target account.
- An object cannot be in both a failover group and a replication group.
You can only replicate outbound shares. Replication of inbound shares (shares from providers) is not supported.
Account objects¶
An account can only have one replication or failover group that contains objects other than databases or shares.
Replication privileges¶
This section describes the replication privileges that are available to be granted to roles to specify the operations users can perform on replication and failover group objects in the system. For the syntax of the GRANT command, see GRANT <privileges> … TO ROLE.
Note
For database replication, only a user with the ACCOUNTADMIN role can enable and manage database replication and failover. For additional information on required privileges for database replication, see the required privileges table in Step 6. Refreshing a secondary database on a schedule.
| Privilege | Object | Usage | Notes |
|---|---|---|---|
| OWNERSHIP | Replication Group Failover Group | Grants the ability to delete, alter, and grant or revoke access to an object. | Can be granted by:
|
| CREATE REPLICATION GROUP | Account | Grants the ability to create a replication group. | Must be granted by the ACCOUNTADMIN role. |
| CREATE FAILOVER GROUP | Account | Grants the ability to create a failover group. | Must be granted by the ACCOUNTADMIN role. |
| FAILOVER | Failover Group | Grants the ability to promote a secondary failover group to serve as primary failover group. | Can be granted or revoked by a role with the OWNERSHIP privilege on the group. |
| REPLICATE | Replication Group Failover Group | Grants the ability to refresh a secondary group. | Can be granted or revoked by a role with the OWNERSHIP privilege on the group. |
| MODIFY | Replication Group Failover Group | Grants the ability to change the settings or properties of an object. | Can be granted or revoked by a role with the OWNERSHIP privilege on the group. |
| MONITOR | Replication Group Failover Group | Grants the ability to view details within an object. | Can be granted or revoked by a role with the OWNERSHIP privilege on the group. |
For instructions on creating a custom role with a specified set of privileges, see Creating custom roles.
For general information about roles and privilege grants for performing SQL actions on securable objects, see Overview of Access Control.
Replication and references across replication groups¶
Objects in a replication (or failover) group that have dangling references (i.e. references to objects in another replication or failover group) might successfully replicate to a target account in some circumstances. If the replication operation results in behavior in the target account consistent with behavior that can occur in the source account, replication succeeds.
For example, if a column in a table in failover group fg_a references a sequence in failover group fg_b, replication of both
groups succeeds. If fg_a is replicated before fg_b, insert operations (after failover) on the table that references the
sequence fails if fg_b was not replicated. This behavior can occur in a source account. If a sequence is dropped in a
source account, insert operations on a table with a column referencing the dropped sequence fails.
When the dangling reference is a security policy that protects data, the replication (or failover) group with the security policy must be replicated before any replication group that contains objects that reference the policy is replicated.
Attention
Making updates to security policies that protect data in separate replication or failover groups may result in inconsistencies and should be done with care.
For database objects, you can view object dependencies in the Account Usage OBJECT_DEPENDENCIES view.
Dangling references and network policies¶
Dangling references in network policies can cause replication to fail with the following error message:
To avoid dangling references, specify the following object types in the OBJECT_TYPES list when executing the CREATE or
ALTER command for the replication or failover group:
- If a network policy uses a network rule, include the database that contains the schema where the network rule was created.
- If a network policy is associated with the account, include
NETWORK POLICIESandACCOUNT PARAMETERSin theOBJECT_TYPESlist. - If a network policy is associated with a user, include
NETWORK POLICIESandUSERSin theOBJECT_TYPESlist.
For more details, see Replicating network policies.
Dangling references and packages policies¶
If there is a packages policy set on the account, the following dangling references error occurs during the refresh operation for a replication or failover group that contains account objects:
To avoid dangling references, replicate the database that contains the packages policy to the target account. The database containing the policy can be in the same or different replication or failover group.
Dangling references and secrets¶
For details, see Replication and secrets.
Dangling references and streams¶
Dangling references for streams cause replication to fail with the following error message:
To avoid dangling reference errors:
- The primary database must include both the stream and its base object or
- The database that contains the stream and the database that contains the base object referenced by the stream must be included in the same replication or failover group.
Replication and read-only secondary objects¶
All secondary objects in a target account, including secondary databases and shares, are read-only. Changes to replicated objects or object types
cannot be made locally in a target account. For example, if the USERS object type is replicated from a source
account to a target account, new users cannot be created or modified in the target account.
New, local databases and shares can be created and modified in a target account. If ROLES are also replicated
to the target account, new roles cannot be created or modified in that target account. Therefore, privileges cannot be granted to (or revoked from)
a
role on a secondary object in the target account. However, privileges can be granted to (or revoked from) a secondary role on local
objects (for example, databases, shares, or replication or failover groups) created in the target account.
Replication and objects in target accounts¶
If you created account objects, for example, users and roles, in your target account by any means other than via replication (for example,
using scripts), these users and roles have no global identifier by default. When a target account is refreshed from the source account, the
refresh operation drops any account objects of the types in the OBJECT_TYPES list in the target account that have no
global identifier.
Note
The initial refresh operation to replicate USERS or ROLES might result in an error. This is to help prevent accidental deletion of data and metadata associated with users and roles. For more information about the circumstances that determine whether these object types are dropped or the refresh operation fails, see Initial replication of users and roles.
To avoid dropping these objects, see Apply global IDs to objects created by scripts in target accounts.
Objects recreated in target accounts¶
If an existing object in the source account is replaced using a CREATE OR REPLACE statement, the existing object is dropped, and then
a new object with the same name is created in a single transaction. For example, if you execute a CREATE OR REPLACE statement for an
existing table t1, table t1 is dropped, and then a new table t1 is created. For more information, see the
usage notes for CREATE TABLE.
When objects are replaced on the target account, the DROP and CREATE statements do not execute atomically during a refresh operation. This means the object might disappear briefly from the target account while it is being recreated as a new object.
Replication and security policies¶
The database containing a security policy and the references (i.e. assignments) can be replicated using replication and failover groups. Security policies include:
- Aggregation policies
- Authentication policies
- Masking policies
- Password policies
- Privacy policies
- Projection policies
- Row access policies
- Session policies, including session policies with secondary roles
- Tag-based masking policies
If you are using database replication, see Database replication and security objects.
Authentication, password, & session policies¶
Authentication, password, and session policy references for users are replicated when specifying the database containing policy
(ALLOWED_DATABASES = policy_db) and USERS in a replication group or failover group.
If either the policy database or users have already been replicated to a target account, update the replication or failover group in the source account to include the databases and object types required to successfully replicate the policy. Then execute a refresh operation to update the target account.
If user-level policies are not in use, USERS do not need to be included in the replication or failover group.
Note
The policy must be in the same account as the account-level policy assignment and the user-level policy assignment.
If you have a security policy set on the account or a user in the account and you do not update the
replication or failover group to include the policy_db containing the policy and USERS, a dangling reference occurs in
the target account. In this case, a dangling reference means that Snowflake cannot locate the policy in the target account because the
fully-qualified name of the policy points to the database in the source account. Consequently, the target account or users in the target
account are not required to comply with the security policy.
To successfully replicate a security policy, verify the replication or failover group includes the object types and databases required to prevent a dangling reference.
Privacy policies¶
Consider the following when replicating privacy policies and privacy-protected tables and views associated with differential privacy:
- If a privacy policy is assigned to a table or view in the source account, the policy needs to be replicated in the target account.
- Cumulative privacy loss for a privacy budget is not replicated.
- Cumulative privacy loss in the target and source accounts are tracked separately.
- Administrators in the target account cannot adjust the replicated privacy budget. The privacy budget is synced with the one in the source account.
- If an analyst has access to the privacy-protected table or view in both the source account and the target account, they can incur twice the amount of privacy loss before reaching the privacy budget’s limit.
- Privacy domains set on the columns are also replicated.
Session policies with secondary roles¶
If you are using session policies with secondary roles, you must specify the policy database in the same replication group that contains the roles. For example:
If you specify the session policy database that references secondary roles in a different replication or failover group (rg2) than the
replication or failover group that contains account-level objects (myrg) and you replicate or fail over rg2 first, a
dangling reference occurs. An error message tells you to place the session policy
database in the replication or failover group that contains the roles. This behavior occurs when the session policy is set on the account
or users.
If the session policy and account level objects are in different replication groups, and the session policy is not set on the account or users, you can replicate and refresh the target account. Be sure to refresh for the replication group that contains the account level objects first.
If you refresh the target account after replicating or failing over the session policy with secondary roles and role objects, the target account reflects the session policy and secondary roles behavior in the source account.
Additionally, when you refresh the database in the target account and the database contains a session policy that references secondary
roles, ALLOWED_SECONDARY_ROLES always evaluates to [ALL].
Replication and secrets¶
You can only replicate the secret using a replication or failover group. Specify the database that contains the secret, the database that contains UDFs or procedures that reference the secret, and the integrations that reference the secret in a single replication or failover group.
If you have the database that contains the secret in one replication or failover group and the integration that references the secret in a different replication or failover group, then:
-
If you replicate the integration first and then the secret, the operation is successful: all objects are replicated and there are no dangling references.
-
If you replicate the secret before the integration and the secret does not already exist in the target account, a “placeholder secret” is added in the target account to prevent a dangling reference. Snowflake maps the placeholder secret to the integration.
After you replicate the group that contains the integration, on the next refresh operation for the group that contains the secret, Snowflake updates the target account to replace the placeholder secret with the secret that is referenced in the integration.
-
If you replicate the secret and do not replicate the integration from
account1toaccount2, the integration doesn’t work in the target account (account2) because there is no integration to use the secret. Additionally, if you failover and the target account is promoted to source account, the integration will not work.When you decide to failover to make
account1as the source account, the secret and integration references match and the placeholder secret is not used. This allows you to use the security integration and the secret that contains the credentials because the objects can reference each other.
Replication and cloning¶
Historically Cloned objects were replicated physically rather than logically to secondary databases. That is, cloned tables in a standard database don’t contribute to the overall data storage unless or until DML operations on the clone add to or modify existing data. However, when a cloned table is replicated to a secondary database, the physical data is also replicated, increasing the data storage usage for your account.
A logically replicated cloned table shares the micro-partitions of the original table it was cloned from, reducing the physical storage of the secondary table in the target account.
If the original table and cloned table are included in the same replication or failover group, the cloned table can be replicated logically to the target account.
Logical replication of clones¶
If the original and cloned table are included in the same replication or failover group, the cloned table can be replicated logically to the target account.
For example, if table t2 in database db2 is a clone of table t1 in database db1, and both databases are included
in replication group rg1, then table t2 is created as a logical clone in the target account.
A cloned object can be cloned to create additional clones of the original object. The original object and the cloned objects are part
of the same clone group. For example, if table t3 in database db3 is created as a clone of t2, it is in the same clone group
as the original table t1 and the cloned table t2.
If database db3 is later added to the replication group rg1, table t3 is created in the target account as a logical clone of
table t1.
Considerations¶
- Tables that are in the same clone group in the source account might not be in the same clone group in the target account.
- The original table and its cloned table must be in the same replication or failover group.
- In some cases, not all micro-partitions of the clone group can be shared with the cloned table. This can result in additional storage usage for the cloned table in the target account.
Example¶
Table t2 in database db2 is a clone of table t1 in database db1. Include both databases in
replication group myrg to logically replicate t2 to the target account:
Replication and automatic clustering¶
In a primary database, Snowflake monitors clustered tables using Automatic Clustering and reclusters them as needed. As part of a refresh operation, clustered tables are replicated to a secondary database with the current sorting of the table micro-partitions. As such, reclustering is not performed again on the clustered tables in the secondary database, which would be redundant.
If a secondary database contains clustered tables and the database is promoted to become the primary database, Snowflake begins Automatic Clustering of the tables in this database while simultaneously suspending the monitoring of clustered tables in the previous primary database.
See Replication and Materialized Views (in this topic) for information about Automatic Clustering for materialized views.
Replication and large, high-churn tables¶
When one or more rows of a table are updated or deleted, all of the impacted micro-partitions that store this data in a primary database are re-created and must be synchronized to secondary databases. For large, high-churn dimension tables, the replication costs can be significant.
For large, high-churn dimension tables that incur significant replication costs, the following mitigations are available:
- Replicate any primary databases that store such tables at a lower frequency.
- Change your data model to reduce churn.
For more information, see Managing costs for large, high-churn tables.
Replication and Time Travel¶
Time Travel and Fail-safe data is maintained independently for a secondary database and is not replicated from a primary database. Querying tables and views in a secondary database using Time Travel can produce different results than when executing the same query in the primary database.
- Historical Data:
Historical data available to query in a primary database using Time Travel is not replicated to secondary databases.
For example, suppose data is loaded continuously into a table every 10 minutes using Snowpipe, and a secondary database is refreshed every hour. The refresh operation only replicates the latest version of the table. While every hourly version of the table within the retention window is available for query using Time Travel, none of the iterative versions within each hour (the individual Snowpipe loads) are available.
- Data Retention Period:
The data retention period for tables in a secondary database begins when the secondary database is refreshed with the DML operations (i.e. changing or deleting data) written to tables in the primary database.
Note
The data retention period parameter, DATA_RETENTION_TIME_IN_DAYS, is only replicated to database objects in the secondary database, not to the database itself. For more details about parameter replication, see Parameters.
Replication and materialized views¶
In a primary database, Snowflake performs automatic background maintenance of materialized views. When a base table changes, all materialized views defined on the table are updated by a background service that uses compute resources provided by Snowflake. In addition, if Automatic Clustering is enabled for a materialized view, then the view is monitored and reclustered as necessary in a primary database.
A refresh operation replicates the materialized view definitions to a secondary database; the materialized view data is not replicated. Automatic background maintenance of materialized views in a secondary database is enabled by default. If Automatic Clustering is enabled for a materialized view in a primary database, automatic monitoring and reclustering of the materialized view in the secondary database is also enabled.
Note
The charges for automated background synchronization of materialized views are billed to each account that contains a secondary database.
Replication and Apache Iceberg™ tables¶
Consider the following points when you use replication for Iceberg tables:
- Snowflake currently supports replication of Snowflake-managed tables only.
- Replicating converted Iceberg tables isn’t supported. Snowflake skips converted tables during refresh operations.
- For replicated tables, you must configure access to a storage location in the same region as the target account.
- If you drop or alter a storage location that is used for replication on the primary external volume, refresh operations might fail.
- Secondary tables in the target account are read-only until you promote the target account to serve as the source account.
- Snowflake maintains the directory hierarchy of the primary Iceberg table for the secondary table.
- Replication costs apply for this feature. For more information, see Understanding replication cost.
- For considerations about the account objects for replication and failover groups, see Account objects.
Replication and dynamic tables¶
Dynamic table replication behavior varies based on whether the primary database containing the dynamic table is part of a replication group or a failover group.
Dynamic tables and replication groups¶
A database that contains a dynamic table can be replicated using a replication group. The source object(s) it depends on are not required to be in the same replication group.
Replicated objects in each target account are referred to as secondary objects and are replicas of the primary objects in the source account. Secondary objects are read-only in the target account. If a secondary replication group is dropped in a target account, the databases that were included in the group become read/write. However, any dynamic tables included in a replication group remain read-only even after the secondary group is dropped in the target account. No DML or dynamic table refreshes can happen on these read-only dynamic tables.
Dynamic tables and failover groups¶
A database that contains a dynamic table can be replicated using a failover group. If a dynamic table references source objects outside the failover group or database replication, it can still be replicated. After a failover, the dynamic table resolves source objects using name resolution during refresh. The refresh might succeed or fail, depending on the state of the source objects. If successful, the dynamic table is reinitialized with the latest data from the source objects.
Secondary dynamic tables are read-only and do not get refreshed. After a failover occurs and a secondary dynamic table is promoted to primary dynamic table, the first refresh is a reinitialization followed by incremental refreshes if the dynamic table is configured for incremental refresh of data.
Note
The reinitialized dynamic table might differ from the original replica because the source objects and dynamic table are not guaranteed to share the same replication snapshot.
Example: Refresh failure due to missing source objects
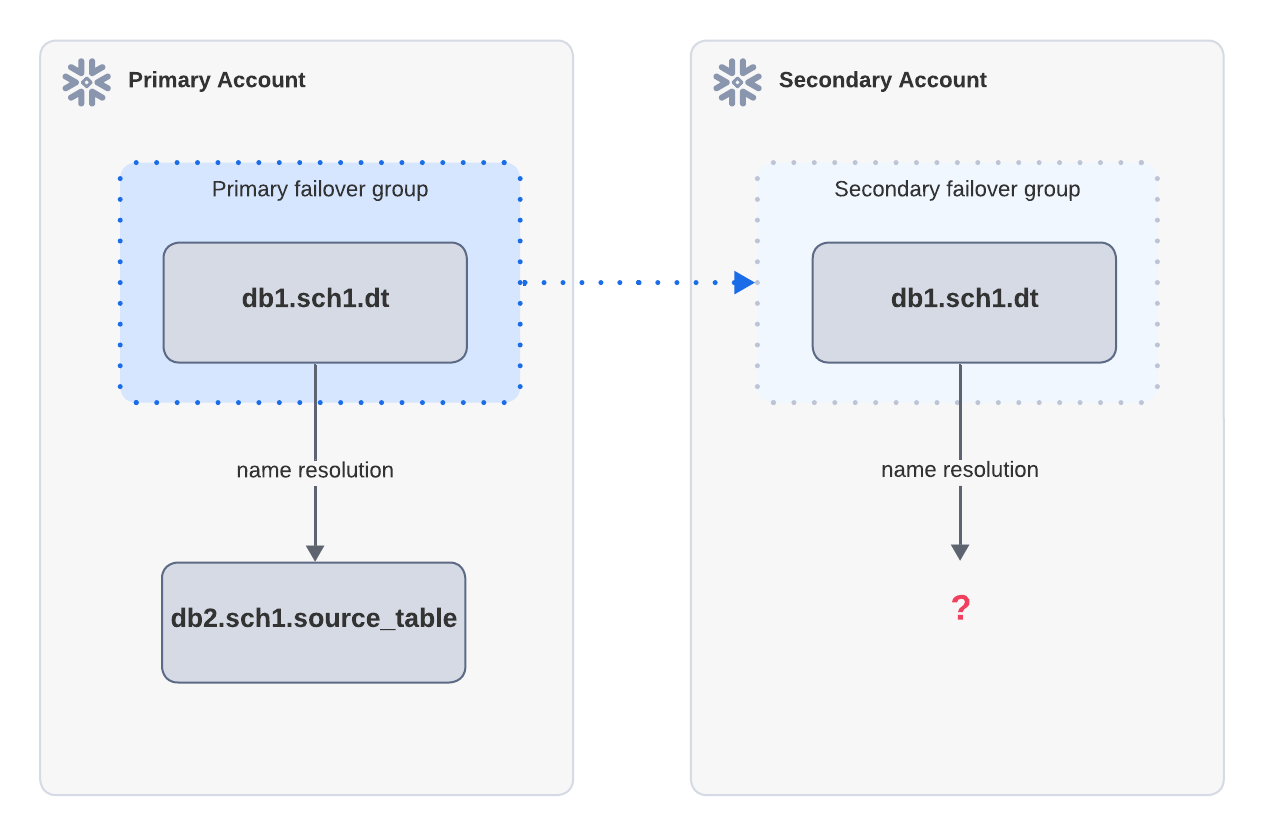
If a dynamic table depends on a source table outside the failover group, it cannot refresh after a failover. In the
above diagram, the dynamic table dt in the primary account is replicated to the secondary account. dt
depends on source_table, which is not included in the same failover group as the primary account. After failover,
the refresh in the secondary account fails because source_table cannot be resolved.
Example: Successful refresh when source objects exist in secondary account via separate replication
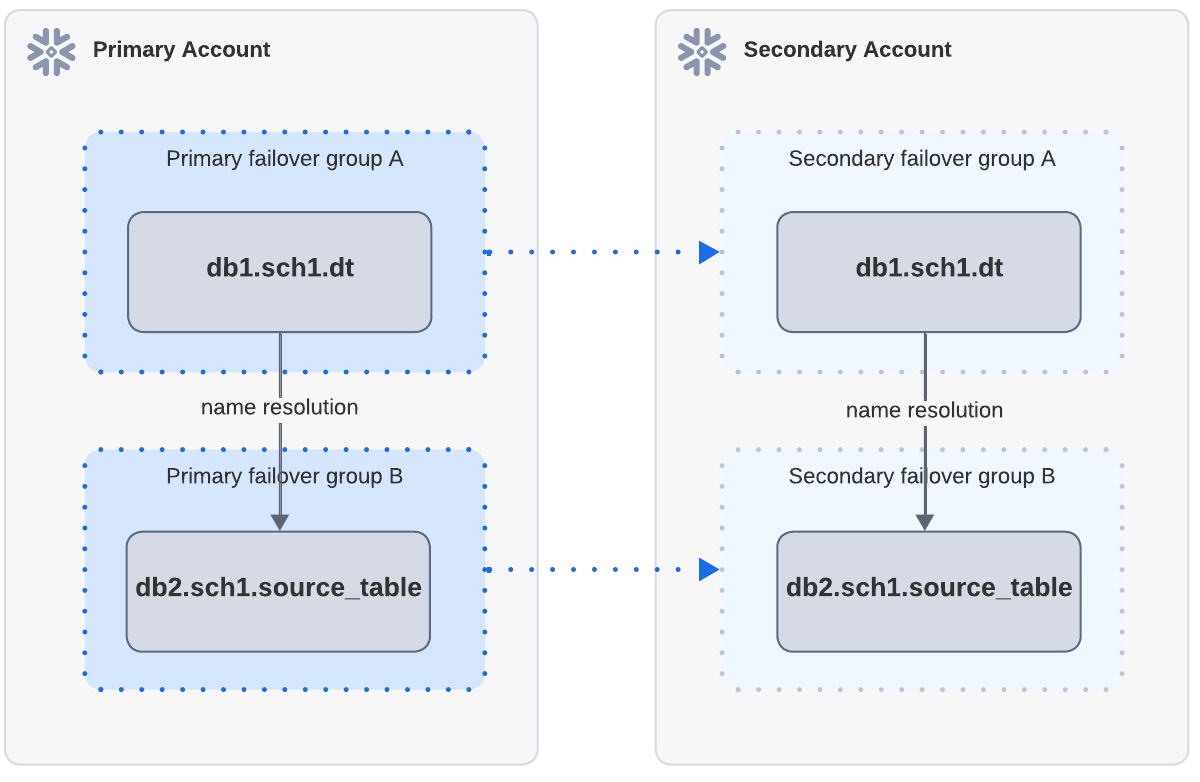
In the above diagram, the dynamic table dt depends on source_table. Both dt and source_table in the
primary account are replicated to the secondary account through independent failover groups. After replication and
failover, when dt is refreshed in the secondary account, the refresh succeeds because source_table can be
found through name resolution.
Example: Successful refresh when source objects exist in secondary account locally
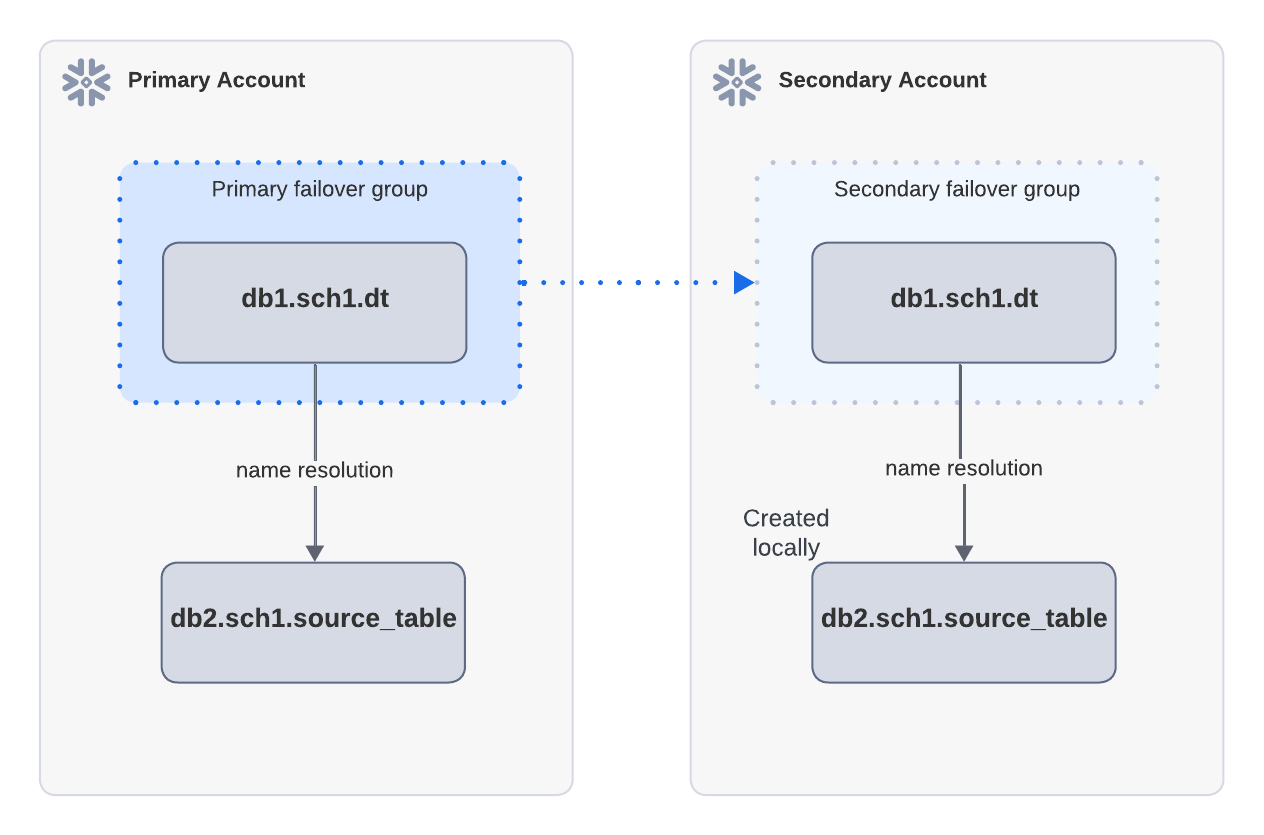
In the above diagram, the dynamic table dt depends on source_table and is replicated through a failover group
from the primary account to the secondary account. A source_table is created locally in the secondary account.
After failover, when dt1 is refreshed in the secondary account, the refresh can succeed because source_table
can be found through name resolution.
Replication and Snowpipe Streaming¶
A table populated by Snowpipe Streaming in a primary database is replicated to the secondary database in a target account.
In the primary database, tables are created and rows are inserted through channels. Offset tokens track the ingestion progress. A refresh operation replicates the table object, table data, and the channel offsets associated with the table from the primary database to the secondary database.
Snowpipe Streaming architectures¶
Snowflake supports two underlying architectures for Snowpipe Streaming, which determine the available client APIs and performance characteristics.
Snowpipe Streaming with classic architecture¶
Read-only operations (available in source and target accounts):
- The channel
getLatestCommittedOffsetTokenAPI SHOW CHANNELScommand
Write operations (only available in the source account):
- The client openChannel (https://javadoc.io/doc/net.snowflake/snowflake-ingest-sdk/latest/net/snowflake/ingest/streaming/SnowflakeStreamingIngestClient.html#openChannel(net.snowflake.ingest.streaming.OpenChannelRequest)) API
- The channel insertRow (https://javadoc.io/doc/net.snowflake/snowflake-ingest-sdk/latest/net/snowflake/ingest/streaming/SnowflakeStreamingIngestChannel.html#insertRow(java.util.Map,java.lang.String)) API
- The channel insertRows (https://javadoc.io/doc/net.snowflake/snowflake-ingest-sdk/latest/net/snowflake/ingest/streaming/SnowflakeStreamingIngestChannel.html#insertRows(java.lang.Iterable,java.lang.String)) API
Snowpipe Streaming with high-performance architecture¶
This architecture offers optimized features, including bulk operations and enhanced status checks, crucial for managing high-volume, replicated environments.
All functions described below are accessible via both Snowpipe Streaming SDKs and the Snowpipe Streaming REST API, allowing for flexible integration based on your infrastructure needs.
Write & management operations (available only in the source account):
- Channel lifecycle management: Open and manage the ingestion channels required to establish a data stream. For example, the openChannel method in the Java SDK.
- Transactionally consistent ingestion: The core function for appending rows. Data inserted here is guaranteed to be included in the replication snapshot once committed. For example, the appendRows method in the Java SDK.
- Offset token tracking: Retrieve the latest committed offset tokens to ensure data integrity and prevent duplication during ingestion. For example, the getLatestCommittedOffsetToken method in the Java SDK.
- Bulk status monitoring: Efficiently monitor health and lag metrics across multiple channels. This is critical for verifying that data latency is acceptable before replication occurs. For example, the getChannelStatus method in the Java SDK.
Read-only operations (available in both source and target accounts):
- Channel inspection: Use metadata commands, such as
SHOW CHANNELS, to view configuration details, status, and properties of existing ingestion channels across the replicated environment.
Data loss avoidance¶
To avoid data loss in the case of failover, the data retention time for successfully inserted rows in your upstream data source must be greater than the configured replication schedule. If data is inserted into a table in a primary database, and failover occurs before the data can be replicated to the secondary database, the same data will need to be inserted into the table in the newly promoted primary database. The following example shows a failover scenario:
- Table
t1in primary databaserepl_dbis populated with data with Snowpipe Streaming and the Kafka connector. - The
offsetTokenis 100 for channel 1 and 100 for channel 2 fort1in the primary database. - A refresh operation completes successfully in the target account.
- The
offsetTokenis 100 for channel 1 and 100 for channel 2 for thet1in the secondary database. - More rows are inserted into
t1in the primary database. - The
offsetTokenis now 200 for channel 1 and 200 for channel 2 for thet1in the primary database. - A failover occurs before the additional rows and new channel offsets can be replicated to the secondary database.
In this case, there are 100 missing offsets in each channel for table t1 in the newly promoted primary database. To insert the missing data, see Reopen active channels for Snowpipe Streaming in newly promoted source account.
Replication support requirements¶
Snowpipe Streaming with classic architecture¶
Snowpipe Streaming replication support for the classic architecture requires the following minimum versions:
- Snowflake Ingest SDK version 1.1.1 or later.
- If you use the Kafka connector: Kafka connector version 1.9.3 or later.
Snowpipe Streaming with high-performance architecture¶
Snowpipe Streaming replication support for the high-performance architecture requires the following minimum versions:
- Snowpipe Streaming SDK version 1.1.0 or later.
Data retention requirement for both architectures¶
The data retention time for successfully inserted rows in your upstream data source must be greater than the configured replication schedule. If you use the Kafka connector, ensure that your log.retention configuration is set with a sufficient buffer.
Replication and stages¶
The following constraints apply to stage objects:
-
Snowflake currently supports stage replication as part of group-based replication (replication and failover groups). Stage replication is not supported for database replication.
-
You can replicate an external stage. However, the files on an external stage are not replicated.
-
You can replicate an internal stage. To replicate the files on an internal stage, you must enable a directory table on the stage. Snowflake replicates only the files that are mapped by the directory table.
-
When you replicate an internal stage with a directory table, you cannot disable the directory table on the primary or secondary stage. The directory table contains critical information about replicated files and files loaded using a COPY statement.
-
A refresh operation will fail if the directory table on an internal stage contains a file that is larger than 5GB. To work around this limitation, move any files larger than 5GB to a different stage.
You cannot disable the directory table on a primary or secondary stage, or any stage that has previously been replicated. Follow these steps before you add the database that contains the stage to a replication or failover group.
- Disable the directory table on the primary stage.
- Move the files that are larger than 5GB to another stage that does not have a directory table enabled.
- After you move the files to another stage, re-enable the directory table on the primary stage.
-
Files on user stages and table stages are not replicated.
-
For named external stages that use a storage integration, you must configure the trust relationship for secondary storage integrations in your target accounts prior to failover. For more information, see Configure cloud storage access for secondary storage integrations.
-
If you replicate an external stage with a directory table, and you have configured automated refresh for the source directory table, you must configure automated refresh for the secondary directory table before failover. For more information, see Configure automated refresh for directory tables on secondary stages.
-
A copy command might take longer than expected if the directory table on a replicated stage is not consistent with the replicated files on the stage. To make a directory table consistent, refresh it with an ALTER STAGE … REFRESH statement. To check the consistency status of a directory table, use the SYSTEM$GET_DIRECTORY_TABLE_STATUS function.
Replication and pipes¶
The following constraints apply to pipe objects:
- Snowflake currently supports pipe replication as part of group-based replication (replication and failover groups). Pipe replication is not supported for database replication.
- Snowflake replicates the copy history of a pipe only when the pipe belongs to the same replication group as its target table.
- Replication of notification integrations is not supported.
- Snowflake only replicates load history after the latest table truncate.
- To receive notifications, you must configure a secondary auto-ingest pipe in a target account prior to failover. For more information, see Configure notifications for secondary auto-ingest pipes.
- Use the SYSTEM$PIPE_STATUS function to resolve any pipes not in their expected execution state after failover.
- Snowflake doesn’t support replication and failover for Snowpipe with the Kafka connector, but Snowflake does support replication and failover for Snowpipe Streaming with the Kafka connector. For more information, see Snowpipe Streaming and the Kafka connector.
Replication of data metric functions (DMFs)¶
The following behaviors apply to DMF replication:
- Event tables
The event table that stores the results of manually calling or scheduling a DMF to run is not replicated because the event table is local to your Snowflake account, and Snowflake does not support replicating event tables.
- Replication groups
When you add the database(s) that contain your DMFs to a replication group, the following occurs in the target account:
- DMFs are replicated from the source account.
- Tables or views that the DMF definition specifies, such as with a foreign key reference are replicated from the source account, unless the table or view is associated with Cross-Cloud Auto-Fulfillment.
- Scheduled DMFs in the target account are suspended. The secondary DMFs resume their schedule when you promote the target account to source account and the secondary DMFs become primary DMFs.
- Failover groups
When you replicate the database(s) that contain your DMFs using a failover group, the following occurs in the case of failover:
- Resumes the schedule of suspended DMFs when you promote the target account to source account.
- Suspends scheduled DMFs in the target account after you promote a different account to source account.
If you do not replicate the database that contains the DMF to a target account, the DMF associations to a table or view are dropped when the target account is promoted to source account because they are not available in the newly promoted source account.
Tip
Prior to failing over your account, check the DMF references by calling the DATA_METRIC_FUNCTION_REFERENCES Information Schema table function to determine the table objects that are associated with a DMF before the promotion and refresh operations.
Replication of stored procedures and user-defined functions (UDFs)¶
Stored procedures and UDFs are replicated from a primary database to secondary databases.
Stored Procedures and UDFs and Stages¶
If a stored procedure or UDF depends on files in a stage (for example, if the stored procedure is defined in Python code that is uploaded from a stage), you must replicate the stage and its files to the secondary database. For more information about replicating stages, see Stage, pipe, and load history replication.
For example, if a primary database has an in-line Python UDF that imports any code that is stored on a stage, the UDF does not work unless the stage and its imported code are replicated in the secondary database.
Stored Procedures and UDFs and External Network Access¶
If a stored procedure or UDF depends on access to an external network location, you must replicate the following objects:
- EXTERNAL ACCESS INTEGRATIONS must be included in the
allowed_integration_typeslist for the replication or failover group. - The database that contains the network rule.
- The database that contains the secret that stores the credentials to authenticate with the external network location.
- If the secret object references a security integration, you must include SECURITY INTEGRATIONS in the
allowed_integration_typeslist for the replication or failover group.
Replication and storage lifecycle policies¶
Snowflake replicates storage lifecycle policies and their associations with tables to target accounts, but doesn’t run the policies. Snowflake doesn’t replicate archived data in the COOL or COLD tiers. Archived data in your source account isn’t available in the target account.
After failover to a target account, Snowflake pauses storage lifecycle policy execution in the original source account. After failback to the source account, Snowflake resumes policy execution.
Snowflake never automatically runs secondary storage lifecycle policies on secondary tables, even after failover. However, you can use secondary policies in a target account by attaching them to new tables. For those new tables, Snowflake runs the policies.
Replication and streams¶
This section describes recommended practices and potential areas of concern when replicating streams in Replicating databases across multiple accounts or Account Replication and Failover/Failback.
Supported Source Objects for Streams¶
Replicated streams can successfully track the change data for tables and views in the same database.
Currently, the following source object types are not supported:
- External tables
- Tables or views in databases separate from the stream databases, unless both the stream database and the database that stores the source object are included in the same replication or failover group.
- Tables or views in a shared databases (i.e. databases shared from provider accounts to your account)
Replicating streams on directory tables is supported when you enable Stage, pipe, and load history replication.
A database replication or refresh operation fails if the primary database includes a stream with an unsupported source object. The operation also fails if the source object for any stream has been dropped.
Append-only streams are not supported on replicated source objects.
Avoiding Data Duplication¶
Note
In addition to the scenario described in this section, streams in a secondary database could return duplicate rows the first time they are included in a refresh operation. In this case, duplicate rows refers to a single row with multiple METADATA$ACTION column values.
After the initial refresh operation, you should not encounter this specific issue in a secondary database.
Data duplication occurs when DML operations write the same change data from a stream multiple times without a uniqueness check. This can occur if a stream and a destination table for the stream change data are stored in separate databases, and these databases are not replicated and failed over in the same group.
For example, suppose you regularly insert change data from stream s into table dt. (For this example, the source object for the stream does not matter.) Separate databases store the stream and destination table.
- At timestamp
t1, a row is inserted into the source table for streams, creating a new table version. The stream stores the offset for this table version. - At timestamp
t2, the secondary database that stores the stream is refreshed. Replicated streamsnow stores the offset. - At timestamp
t3, the change data for streamsis inserted into tabledt. - At timestamp
t4, the secondary database that stores streamsis failed over. - At timestamp
t5, the change data for streamsis inserted again into tabledt.
To avoid this situation, replicate and fail over together the databases that store streams and their destination tables.
Stream References in Task WHEN Clause¶
To avoid unexpected behavior when running replicated tasks that reference streams in the WHEN boolean_expr clause, we recommend that you either:
- Create the tasks and streams in the same database, or
- If streams are stored in a different database from the tasks that reference them, include both databases in the same failover group.
If a task references a stream in a separate database, and both databases are not included in the same failover group, then the database that contains the task could be failed over without the database that contains the stream. In this scenario, when the task is resumed in the failed over database, it records an error when it attempts to run and cannot find the referenced stream. This issue can be resolved by either failing over the database that contains the stream or recreating the database and stream in the same account as the failed over database that contains the task.
Stream Staleness¶
If a stream in the primary database has become stale, the replicated stream in a secondary database is also stale and cannot be queried or its change data consumed. To resolve this issue, recreate the stream in the primary database (using CREATE OR REPLACE STREAM). When the secondary database is refreshed, the replicated stream is readable again.
Note that the offset for a recreated stream is the current table version by default. You can recreate a stream that points to an earlier table version using Time Travel; however, the replicated stream would remain unreadable. For more information, see Stream Replication and Time Travel (in this topic).
Stream Replication and Time Travel¶
After a primary database is failed over, if a stream in the database uses Time Travel to read a table version for the source object from a point in time before the last refresh timestamp, the replicated stream cannot be queried or the change data consumed. Likewise, querying the change data for a source object from a point in time before the last refresh timestamp using the CHANGES clause for SELECT statements fails with an error.
This is because a refresh operation collapses the table history into a single table version. Iterative table versions created before the refresh operation timestamp are not preserved in the table history for the replicated source objects.
Consider the following example:
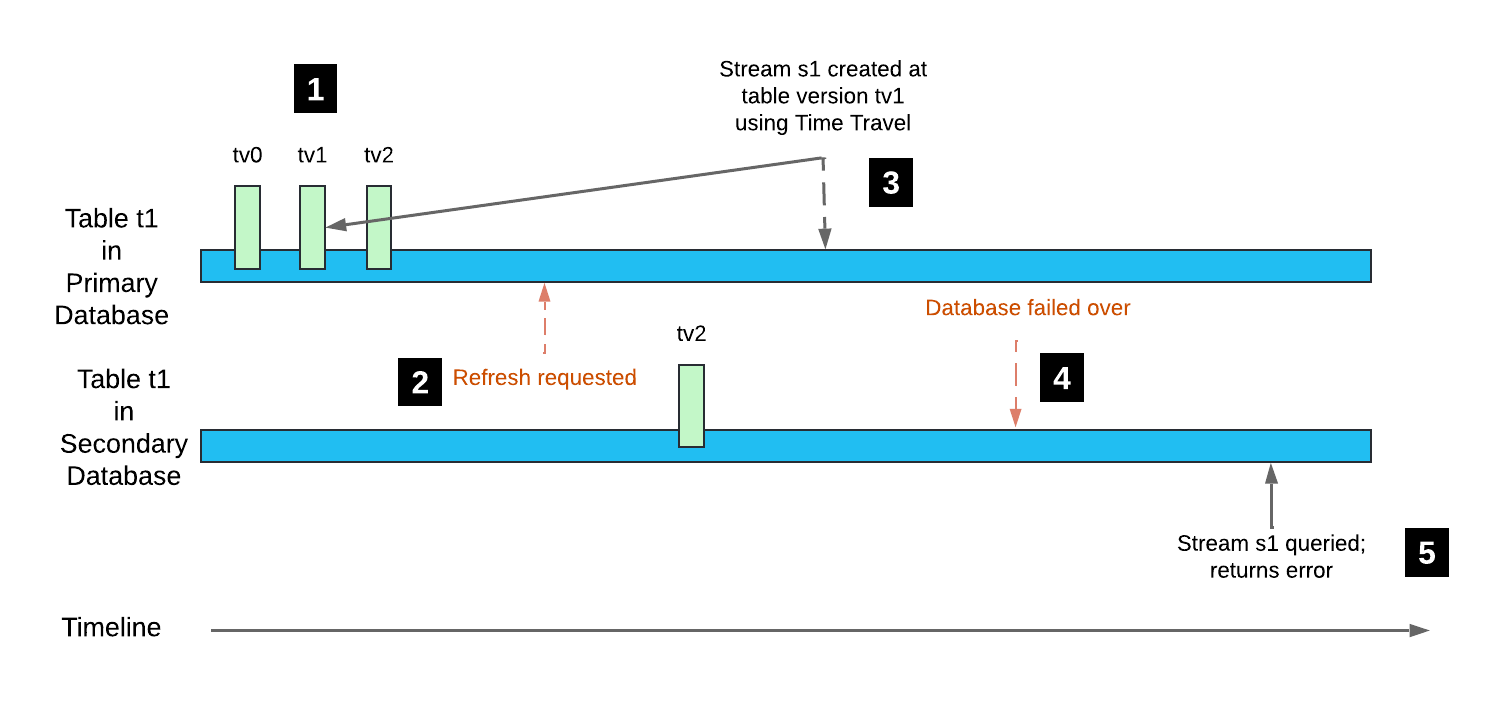
- Table
t1is created in the primary database with change tracking enabled (table versiontv0). Subsequent DML transactions create table versionstv1andtv2. - A secondary database that contains table
t1is refreshed. The table version for this replicated table istv2; however, the table history is not replicated. - A stream is created in the primary database with its offset set to table version
tv1using Time Travel. - The secondary database is failed over, becoming the primary database.
- Querying stream
s1returns an error, because table versiontv1is not in the table history.
Note that when a subsequent DML transaction on table t1 iterates the table version to tv3, the offset for stream s1 is advanced. The stream is readable again.
Avoiding Data Loss¶
Data loss can occur when the most recent refresh operation for a secondary database is not completed prior to the failover operation. We recommend refreshing your secondary databases frequently to minimize the risk.
Replication and tasks¶
This section describes task replication in Replicating databases across multiple accounts or Account Replication and Failover/Failback.
Note
Database replication does not work for task graphs if the graph is owned by a different role than the role that performs replication.
Replication Scenarios¶
The following table describes different task scenarios and specifies whether the tasks are replicated or not. Except where noted, the scenarios pertain to both standalone tasks and tasks in a task graph:
| Scenario | Replicated | Notes |
|---|---|---|
| Task was created and either resumed or executed manually (using EXECUTE TASK). Resuming or executing a task creates an initial task version. | ✔ | |
| Task was created but never resumed or executed. | ❌ | |
| Task was recreated (using CREATE OR REPLACE TASK but never resumed or executed). | ✔ | The latest version before the task was recreated is replicated. Resuming or manually executing the task commits a new version. When the database is replicated again, the new, or latest, version is replicated to the secondary database. |
| Task was created and resumed or executed, but subsequently dropped. | ❌ | |
Task graph was created and resumed or executed. Subsequently, a task in the task graph was modified, but the task graph’s root task wasn’t resumed or executed again. Examples of modifications include the following:
| ✔ | The latest version of the task graph before the task was modified is replicated. Resuming or manually executing a task commits a new version that includes any changes to the parameters of the tasks within the task graph. Because the new changes were never committed, only the previous version of the task graph is replicated. Note that if the modified task graph is not resumed within a retention period (currently 30 days), the latest version of the task is dropped. After this period, the task is not replicated to a secondary database unless it’s resumed again. |
| Root task in a task graph was created and resumed or executed, but was subsequently suspended and dropped. | ❌ | The entire task graph is not replicated to a secondary database. |
| Child task in a task graph is created and resumed or executed, but is subsequently suspended and dropped. | ✔ | The latest version of the task graph (before the task was suspended and dropped) is replicated to a secondary database. |
Resumed or Suspended State of Replicated Tasks¶
If all of the following conditions are met, a task is replicated to a secondary database in a resumed state:
-
A standalone or root task is in a resumed state in the primary database when the replication or refresh operation begins until the operation is completed. If a task is in a resumed state during only part of this period, it might still be replicated in a resumed state.
A child task is in a resumed state in the latest version of the task.
-
The parent database was replicated to the target account along with role objects in the same, or different, replication or failover group.
After the roles and database are replicated, you must refresh the objects in the target account by executing either ALTER REPLICATION GROUP … REFRESH or ALTER FAILOVER GROUP … REFRESH, respectively. If you refresh the database by executing ALTER DATABASE … REFRESH, the state of the tasks in the database is changed to suspended.
A replication or refresh operation includes the privilege grants for a task that were current when the latest table version was committed. For more information, see Replicated Tasks and Privilege Grants (in this topic).
If these conditions are not met, the task is replicated to a secondary database in a suspended state.
Note
Secondary tasks aren’t scheduled until after a failover, regardless of their state. For more details, refer to Task Runs After a Failover
Replicated Tasks and Privilege Grants¶
If the parent database is replicated to a target account along with role objects in the same, or different, replication or failover group, the privileges granted on the tasks in the database are replicated as well.
The following logic determines which task privileges are replicated in a replication or refresh operation:
- If the current task owner (that is, the role that has the OWNERSHIP privilege on a task) is the same role as when the task was resumed last, then all current grants on the task are replicated to the secondary database.
- If the current task owner is not the same role as when the task was resumed last, then only the OWNERSHIP privilege granted to the owner role in the task version is replicated to the secondary database.
- If the current task owner role is not available (for example, a child task is dropped but a new version of the task graph is not committed yet), then only the OWNERSHIP privilege granted to the owner role in the task version is replicated to the secondary database.
Task Runs After a Failover¶
After a secondary failover group is promoted to serve as the primary group, any resumed tasks in databases within the failover group are scheduled gradually. The amount of time required to restore normal scheduling of all resumed standalone tasks and task graphs depends on the number of resumed tasks in a database.
Replication and dbt projects¶
- dbt project objects are replicated from a primary database to secondary databases.
- All secondary objects in a target account, including secondary databases, are read-only. A secondary dbt project cannot be executed.
- Any objects that a dbt project references, such as source tables and views, should be replicated with the dbt project in order for executions of that dbt project to succeed after failover.
dbt projects and external network access¶
If a dbt project depends on access to an external network location, you must replicate the following objects:
- EXTERNAL ACCESS INTEGRATIONS must be included in the
allowed_integration_typeslist for the replication or failover group. - The database that contains the network rule.
- The database that contains the secret that stores the credentials to authenticate with the external network location.
- If the secret object references a security integration, you must include SECURITY INTEGRATIONS in the
allowed_integration_typeslist for the replication or failover group.
A dbt project does not store the external network access integrations that it is associated with. External network access integrations are specified when the user runs the EXECUTE DBT PROJECT command. This makes the requirement to replicate external access integrations separately more apparent.
Replication and tags¶
Tags and their assignments can be replicated from a source account to a target account.
Tag assignments cannot be modified in the target account after the initial replication from the source account. For example, setting a tag on a secondary (i.e. replicated) database is not allowed. To modify tag assignments in the target account, modify them in the source account and replicate them to the target account.
To successfully replicate tags, ensure that the replication or failover group includes:
-
The database containing the tags in the
ALLOWED_DATABASESproperty. -
Other account-level objects that have a tag in the
OBJECT_TYPESproperty (e.g.ROLES,WAREHOUSES).For more information, see CREATE REPLICATION GROUP and CREATE FAILOVER GROUP.
Replication and instances of Snowflake classes¶
An instance of the CUSTOM_CLASSIFIER class is replicated when the database that contains the instance is replicated. Replication of instances of other Snowflake classes is not supported.
Historical usage data¶
Historical usage data for activity in a primary database is not replicated to secondary databases. Each account has its own query history, login history, etc.
Historical usage data includes the query data returned by the following Snowflake Information Schema table functions or Account Usage views:
- COPY_HISTORY
- LOGIN_HISTORY
- QUERY_HISTORY
- etc.