群集密钥和聚类表
通常,Snowflake 在表中生成聚类良好的数据;但是,随着时间的推移,特别是在超大型表(由表中的数据量而非行数定义)上发生 DML 时,某些表行中的数据可能不再按所需维度以最佳方式聚类。
为了改善基础表微分区的聚类情况,您可以随时手动对键表列上的行进行排序,然后将其重新插入表中;但是,执行这些任务可能既繁琐又昂贵。
Snowflake 支持通过将一个或多个表列/表达式指定为表的 群集密钥 来自动执行这些任务。定义了群集密钥的表被视为 已聚类 。
您可以对 物化视图 物化视图和群集 物化视图的最佳实践
注意
由于最初对数据进行聚类和维护群集的成本很高,因此群集密钥并 不 适用于所有表。在以下任一情况下,使用聚类是最佳方法:
有关选择要聚类的表的更多信息,请参阅:为表选择群集的注意事项
什么是群集密钥?
群集密钥是表中列的子集(或表上的表达式),这些列被显式指定用于将表中的数据放在相同的 微分区
一些有助于确定是否为表定义群集密钥的一般指标包括:
可以在创建表(使用 CREATE TABLE ALTER TABLE
注意
不能为 混合表
定义群集密钥的优势(适用于超大型表)
使用群集密钥将相似的行放在同一个微分区中可以为超大型表带来多种优势,包括:
通过跳过与筛选谓词不匹配的数据,提高了查询的扫描效率。
与没有采用聚类的表相比,列压缩效果更好。当其他列与构成群集密钥的列高度关联时,尤其如此。
在表上定义密钥后,无需进行额外的管理,除非您选择删除或修改该密钥。未来对表中行进行的所有维护(目的是为了确保形成最佳群集)将由 Snowflake 自动执行。
尽管群集可以显著提高性能并降低某些查询的成本,但用于执行群集的计算资源会消耗 credit。因此,只有当查询广泛受益于群集时,才应进行聚类。
通常,当查询根据表的群集密钥进行筛选或排序时,查询会受益于群集。通常对 ORDER BY GROUP BY
SELECT ...
FROM my_table INNER JOIN my_materialized_view
ON my_materialized_view . col1 = my_table . col1
...
在这个伪示例中,Snowflake 可能会将 my_materialized_view.col1 my_table.col1 my_table.col1 my_table
查询表的频率越高,聚类提供的好处就越多。但是,表更改的频率越高,保持聚类的成本就越高。因此,对于经常查询且不经常更改的表,聚类通常最具成本效益。
备注
为表定义群集密钥后,行不一定会立即更新。Snowflake 只有在表受益于操作时才执行自动维护。有关更多详细信息,请参阅 重聚类 (本主题内容)和 自动聚类
为表选择群集的注意事项
无论您想要更快的响应速度还是更低的总体成本,群集都是满足以下 所有 条件的表的最佳选择:
该表包含大量的 微分区
查询可以利用群集的优势。通常,这意味着以下一项或两项是正确的:
很大比例的查询可以受益于相同的群集密钥。换句话说,许多/大多数查询都在相同的几列上进行选择或排序。
如果您的目标主要是降低总体成本,那么每个聚类表对 DML 操作 (INSERT/UPDATE/DELETE)的查询频率很高。这通常意味着该表被频繁查询而却不经常更新。如果您想对一个执行了很多 DML 的表进行聚类,那么可以考虑将 DML 语句按不频繁的大批次来分组。
此外,在选择对表进行聚类之前,Snowflake 强烈 建议您在表上测试一组代表性的查询,以建立一些性能基准。
选择群集密钥的策略
单个群集密钥可以包含一个或多个列或表达式。对于大多数表,Snowflake 建议每个密钥最多使用 3 列或 4 列(或者 3 个或 4 个表达式)。添加超过 3-4 列往往会致使成本的增加大于收益。
为群集密钥选择正确的列/表达式会显著影响查询性能。对工作负载的分析通常会产生良好的群集密钥候选项。
Snowflake 建议按以下顺序排列密钥的优先次序:
将在选择性筛选器中最常用的列进行聚类。对于涉及基于日期的查询的多个事实表(例如“WHERE invoice_date > x AND invoice date <= y”),选择日期列是个好主意。对于事件表,如果有大量不同的事件类型,事件类型可能是一个不错的选择。(如果表中只有少量不同的事件类型,则在选择事件列作为群集密钥之前,请查看下方有关基数的注释。)
如果有空间容纳其他群集密钥,则考虑联接谓词中经常使用的列,例如“FROM table1 JOIN table2 ON table2.column_A = table1.column_B”。
如果您通常根据两个维度(如 application_id user_status
列/表达式中非重复值(即基数)的数量是选择该列/表达式作为群集密钥的关键方面。选择具有以下条件的群集密钥很重要:
基数非常低的列可能只能进行最少的裁剪,例如仅包含布尔值的名为的 IS_NEW_CUSTOMER 不是 直接用作群集密钥的良好候选项。例如,包含纳秒时间戳值的列并非好的群集密钥。
小技巧
通常,如果列(或表达式)的基数更高,则在该列上保持群集的成本更高。
在唯一密钥上进行群集的成本可能超过在该密钥上进行群集的好处,尤其是在点查询不是该表的主要用例的情况下。
如果您想使用基数非常高的列作为群集密钥,Snowflake 建议将该密钥定义为列上的表达式,而不是直接在列上定义,以减少非重复值的数量。该表达式应保留列的原始顺序,以便每个分区中的最小值和最大值仍能进行裁剪。
例如,如果事实表的 TIMESTAMP 列 c_timestamp to_date(c_timestamp)
再举一个例子,您可以使用 TRUNC TRUNC(123456789, -5)
小技巧
如果要为表定义多列群集密钥,则在 CLUSTER BY 最低 基数到 最高 基数进行排列。在较低基数列之前放置较高基数列通常会降低后一列的群集有效性。
小技巧
在文本字段上进行聚类时,群集密钥元数据仅跟踪前几个字节(通常为 5 或 6 字节)。请注意,对于多字节字符集,甚至会少于 5 个 字符 。
在某些情况下,对 GROUP BY ORDER BY JOIN ORDER BY GROUP BY
重聚类
当对聚类表执行 DML 操作(INSERT、 UPDATE、 DELETE、 MERGE、 COPY)时,表中数据的聚类程度可能会降低。需要定期对表进行重聚类以保持最佳群集。
在重聚类过程中,Snowflake 使用聚类表的群集密钥来重新组织列数据,以便将相关记录重新定位到同一个微分区。此 DML 操作会删除受影响的记录,然后重新插入这些记录,并根据群集密钥进行分组。
备注
Snowflake 中的重聚类是自动的;无需维护。有关更多详细信息,请参阅 自动聚类
但是,对于某些账户,手动重聚类已被弃用,但仍允许使用。有关更多详细信息,请参阅 手动重聚类
重聚类对 credit 和存储的影响
与 Snowflake 中的所有 DML 操作类似,重聚类会消耗 credit。消耗的 credit 数量取决于表的大小和需要重聚类的数据量。
重聚类还会导致存储成本。每次重聚类数据时,都会根据表的群集密钥对行进行物理分组,这会导致 Snowflake 为表生成 新 的微分区。即使在表中添加少量行也可能导致所有包含这些值的微分区被重新创建。
此过程可能会造成大量数据周转,因为原始微分区被标记为已删除,但会保留在系统中以启用 Time Travel 和故障安全。只有在 Time Travel 保留期和随后的故障安全期结束后(即如果您使用的是 Snowflake Enterprise Edition [或更高版本],Time Travel 最少延长 8 天,最多延长 97 天),原始微分区才会被清除。这通常会导致存储成本增加。有关更多信息,请参阅 Snowflake Time Travel和故障安全
重要
在为表定义群集密钥之前,应考虑相关的 credit 和存储成本。
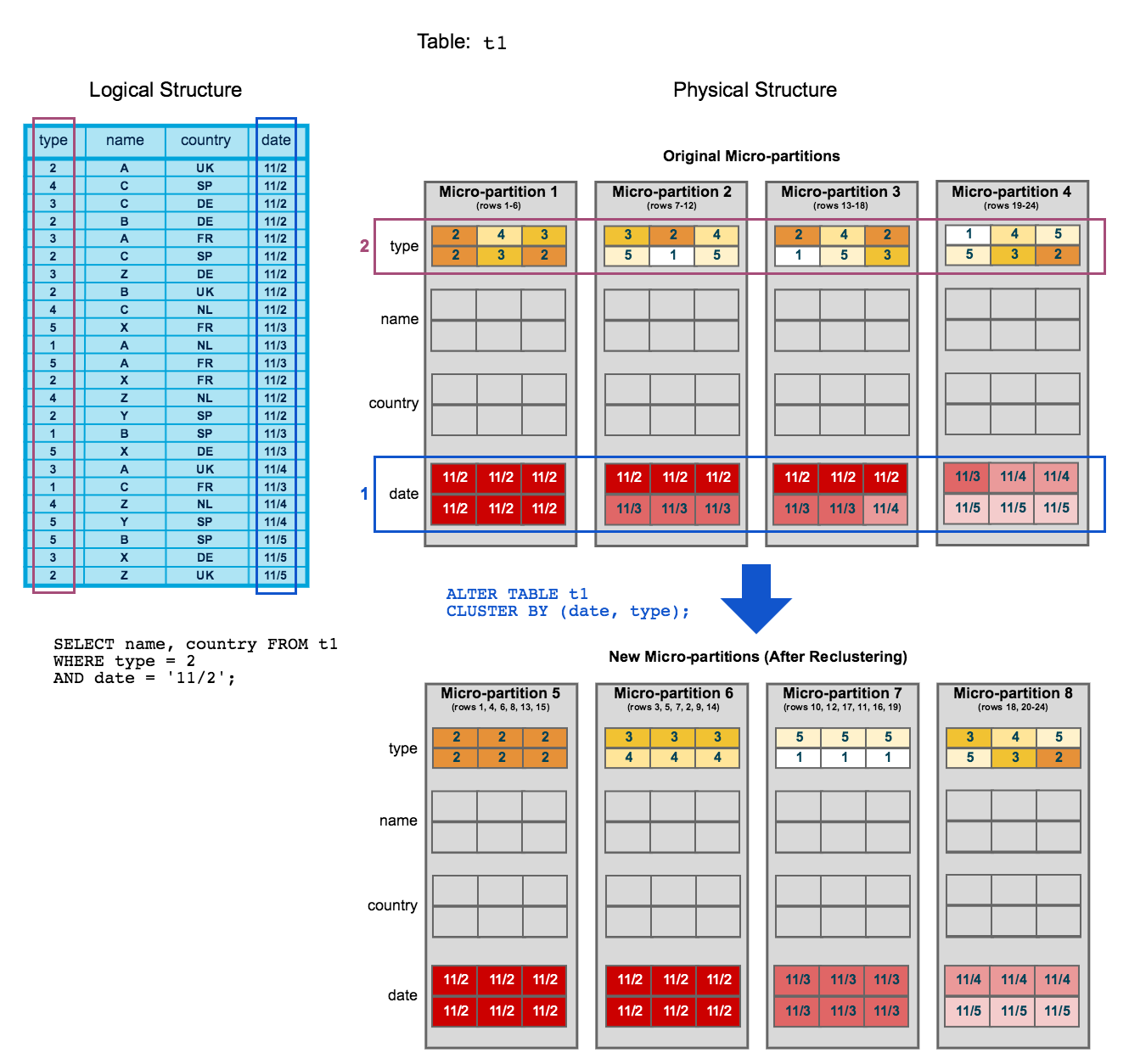
重聚类示例
此图构建于前一主题的 群集图
此外,在重聚类之后:
备注
此示例说明了极小规模的重聚类所产生的影响。推断到一个非常大的表(即由数百万个或更多的微分区组成),重聚类会对扫描产生重大影响,从而对查询性能产生重大影响。
定义聚类表
为表定义群集密钥
创建表时,可以通过将 CLUSTER BY CREATE TABLE
CREATE TABLE <name> ... CLUSTER BY ( <expr1> [ , <expr2> ... ] )
其中每个群集密钥由一个或多个表列/表达式组成,这些表列/表达式可以是任何数据类型,但 GEOGRAPHY、 VARIANT、 OBJECT 或 ARRAY 除外 。群集密钥可以包含以下任何内容:
基础列。
基础列上的表达式。
VARIANT 列中路径上的表达式。
例如:
-- cluster by base columns
CREATE OR REPLACE TABLE t1 ( c1 DATE , c2 STRING , c3 NUMBER ) CLUSTER BY ( c1 , c2 );
SHOW TABLES LIKE 't1' ;
+ -------------------------------+------+---------------+-------------+-------+---------+----------------+------+-------+----------+----------------+----------------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering |
|-------------------------------+------+---------------+-------------+-------+---------+----------------+------+-------+----------+----------------+----------------------|
| 2019-06-20 12:06:07.517 -0700 | T1 | TESTDB | PUBLIC | TABLE | | LINEAR(C1, C2) | 0 | 0 | SYSADMIN | 1 | ON |
+ -------------------------------+------+---------------+-------------+-------+---------+----------------+------+-------+----------+----------------+----------------------+
-- cluster by expressions
CREATE OR REPLACE TABLE t2 ( c1 timestamp , c2 STRING , c3 NUMBER ) CLUSTER BY ( TO_DATE ( C1 ), substring ( c2 , 0 , 10 ));
SHOW TABLES LIKE 't2' ;
+ -------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------+------+-------+----------+----------------+----------------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering |
|-------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------+------+-------+----------+----------------+----------------------|
| 2019-06-20 12:07:51.307 -0700 | T2 | TESTDB | PUBLIC | TABLE | | LINEAR(CAST(C1 AS DATE), SUBSTRING(C2, 0, 10)) | 0 | 0 | SYSADMIN | 1 | ON |
+ -------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------+------+-------+----------+----------------+----------------------+
-- cluster by paths in variant columns
CREATE OR REPLACE TABLE T3 ( t timestamp , v variant ) cluster by ( v : "Data" :id ::number );
SHOW TABLES LIKE 'T3' ;
+ -------------------------------+------+---------------+-------------+-------+---------+-------------------------------------------+------+-------+----------+----------------+----------------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering |
|-------------------------------+------+---------------+-------------+-------+---------+-------------------------------------------+------+-------+----------+----------------+----------------------|
| 2019-06-20 16:30:11.330 -0700 | T3 | TESTDB | PUBLIC | TABLE | | LINEAR(TO_NUMBER(GET_PATH(V, 'Data.id'))) | 0 | 0 | SYSADMIN | 1 | ON |
+ -------------------------------+------+---------------+-------------+-------+---------+-------------------------------------------+------+-------+----------+----------------+----------------------+
重要使用注意事项
对于每个 VARCHAR 列,目前执行聚类仅使用前 5 个字节。
如果每行的前 N 个字符相同,或者没有提供足够的基数,则可以考虑在子字符串上进行聚类,该子字符串在相同字符之后开始,并且具有最佳基数。(有关最佳基数的更多信息,请参阅 选择群集密钥的策略
create or replace table t3 ( vc varchar ) cluster by ( SUBSTRING ( vc , 5 , 5 ));
如果您将两个或更多列/表达式定义为表的群集密钥,则顺序会影响数据在微分区中聚类的方式。
有关更多详细信息,请参阅 选择群集密钥的策略 (本主题内容)。
当使用 CREATE TABLE ...CLONE 创建表时,会复制现有的群集密钥。但是,这会使 已克隆的表
如果表使用以下语句创建,则:emph:`
不支持直接在 VARIANT 列的顶部定义群集密钥;但是,如果您提供的表达式由路径和目标类型组成,则可以在群集密钥中指定 VARIANT 列。
更改表的群集密钥
您可以随时向现有表添加群集密钥或使用 ALTER TABLE
ALTER TABLE <name> CLUSTER BY ( <expr1> [ , <expr2> ... ] )
例如:
-- cluster by base columns
ALTER TABLE t1 CLUSTER BY ( c1 , c3 );
SHOW TABLES LIKE 't1' ;
+ -------------------------------+------+---------------+-------------+-------+---------+----------------+------+-------+----------+----------------+----------------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering |
|-------------------------------+------+---------------+-------------+-------+---------+----------------+------+-------+----------+----------------+----------------------|
| 2019-06-20 12:06:07.517 -0700 | T1 | TESTDB | PUBLIC | TABLE | | LINEAR(C1, C3) | 0 | 0 | SYSADMIN | 1 | ON |
+ -------------------------------+------+---------------+-------------+-------+---------+----------------+------+-------+----------+----------------+----------------------+
-- cluster by expressions
ALTER TABLE T2 CLUSTER BY ( SUBSTRING ( C2 , 5 , 15 ), TO_DATE ( C1 ));
SHOW TABLES LIKE 't2' ;
+ -------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------+------+-------+----------+----------------+----------------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering |
|-------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------+------+-------+----------+----------------+----------------------|
| 2019-06-20 12:07:51.307 -0700 | T2 | TESTDB | PUBLIC | TABLE | | LINEAR(SUBSTRING(C2, 5, 15), CAST(C1 AS DATE)) | 0 | 0 | SYSADMIN | 1 | ON |
+ -------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------+------+-------+----------+----------------+----------------------+
-- cluster by paths in variant columns
ALTER TABLE T3 CLUSTER BY ( v : "Data" :name ::string , v : "Data" :id ::number );
SHOW TABLES LIKE 'T3' ;
+ -------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------------------------------------+------+-------+----------+----------------+----------------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering |
|-------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------------------------------------+------+-------+----------+----------------+----------------------|
| 2019-06-20 16:30:11.330 -0700 | T3 | TESTDB | PUBLIC | TABLE | | LINEAR(TO_CHAR(GET_PATH(V, 'Data.name')), TO_NUMBER(GET_PATH(V, 'Data.id'))) | 0 | 0 | SYSADMIN | 1 | ON |
+ -------------------------------+------+---------------+-------------+-------+---------+------------------------------------------------------------------------------+------+-------+----------+----------------+----------------------+
重要使用注意事项
向已填充数据的表添加群集密钥时,不允许在密钥中指定所有表达式。您可以使用 SHOW FUNCTIONS
show functions like ' function_name ';
输出在其末尾包含列 valid_for_clustering
在 Snowflake 对表进行重聚类之前,更改表的群集密钥不会影响表中的现有记录。
删除表的群集密钥
您可以随时使用 ALTER TABLE
ALTER TABLE <name> DROP CLUSTERING KEY
例如:
ALTER TABLE t1 DROP CLUSTERING KEY ;
SHOW TABLES LIKE 't1' ;
+ -------------------------------+------+---------------+-------------+-------+---------+------------+------+-------+----------+----------------+----------------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering |
|-------------------------------+------+---------------+-------------+-------+---------+------------+------+-------+----------+----------------+----------------------|
| 2019-06-20 12:06:07.517 -0700 | T1 | TESTDB | PUBLIC | TABLE | | | 0 | 0 | SYSADMIN | 1 | OFF |
+ -------------------------------+------+---------------+-------------+-------+---------+------------+------+-------+----------+----------------+----------------------+