Spark Connector 概述¶
Snowflake Connector for Spark 可将 Snowflake 用作 Apache Spark 数据源,并且与其他数据源类似(PostgreSQL、HDFS、S3 等)。
备注
As an alternative to using Spark, consider writing your code to use Snowpark API instead. Snowpark allows you to perform all of your work within Snowflake (rather than in a separate Spark compute cluster). Snowpark also supports pushdown of all operations, including Snowflake UDFs. However, when you want to enforce row and column policies on Iceberg tables, use the Snowflake Spark Connector. For more information, see 从 Apache Spark™ 查询 Apache Iceberg™ 表时强制执行数据保护策略.
Snowflake 和 Spark 之间的交互¶
该连接器支持在 Snowflake 集群和 Spark 集群之间双向移动数据。Spark 集群可以是自托管的,也可以通过 Qubole、 AWS EMR 或 Databricks 等其他服务进行访问。
您可以使用该连接器执行以下操作:
从 Snowflake 中的表(或查询)填充 Spark DataFrame。
将 Spark DataFrame 的内容写入 Snowflake 中的表。
该连接器使用 Scala 2.12.x 或 2.13.x 执行这些操作,并使用 Snowflake JDBC 驱动程序与 Snowflake 通信。
备注
连接 Snowflake 和 Apache Spark 并不严格要求使用 Snowflake 连接器;可以使用其他第三方 JDBC 驱动程序。但是,我们建议使用 Snowflake Connector for Spark,因为该连接器与 Snowflake JDBC 驱动程序结合使用时,已针对在两个系统之间传输大量数据进行了优化。它还通过支持从 Spark 向 Snowflake 下推查询,从而提高性能。
数据传输¶
Snowflake Spark Connector 支持两种传输模式:
内部传输使用由 Snowflake 内部/透明创建和管理的临时位置。
外部传输使用由用户创建和管理的存储位置,通常是临时位置。
小技巧
如果满足以下任一条件,则使用外部数据传输:
您使用的是 Spark Connector 的 2.1.x 或更低版本(不支持内部传输)。
您的传输可能需要 36 小时或更长时间(内部传输使用在 36 小时后过期的临时凭证)。
否则,我们 建议 使用内部数据传输。
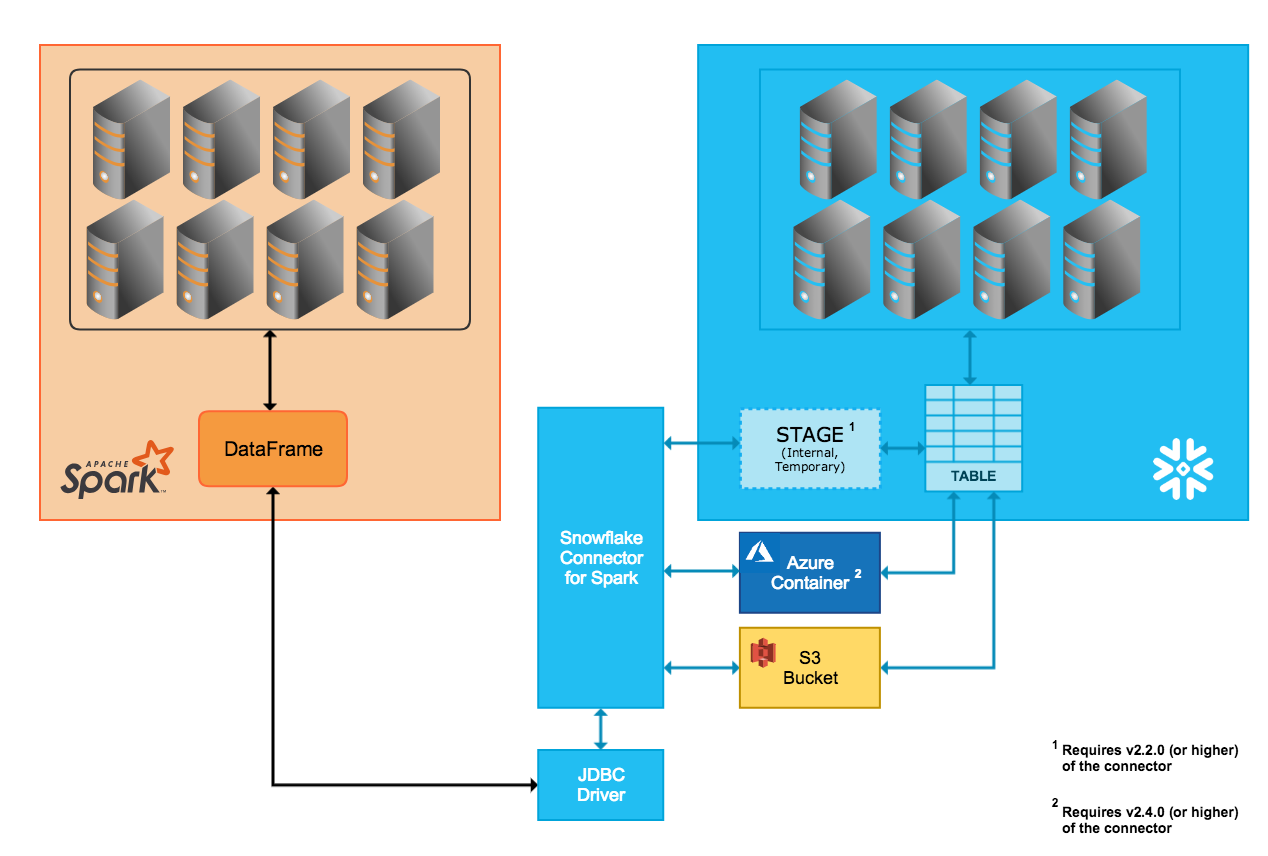
内部数据传输¶
两个系统之间的数据传输通过连接器自动创建和管理的 Snowflake 内部暂存区来实现:
连接到 Snowflake 并在 Snowflake 中初始化会话时,连接器会创建内部暂存区。
在 Snowflake 会话的整个持续时间内,连接器使用暂存区存储数据,同时将数据传输到目的地。。
在 Snowflake 会话结束时,连接器会删除暂存区,从而删除暂存区中的所有临时数据。
请注意,支持内部传输需要使用连接器的特定版本(或更高版本),具体取决于您的 Snowflake 账户所在的云平台。
- AWS:
内部数据传输模式仅在连接器的 2.2.0 版(及更高版本)中受支持。
- Azure:
内部数据传输模式仅在连接器的 2.4.0 版(及更高版本)中受支持。
- GCP:
内部数据传输模式仅在连接器的 2.7.0 版(及更高版本)中受支持。
外部数据传输¶
两个系统之间的数据传输通过用户指定的存储位置和连接器自动创建的文件实现:
- AWS:
传输数据文件创建并存储在 S3 桶中。
- Azure:
传输数据文件创建并存储在 Blob 存储容器中。只有 2.4.0 版(及更高版本)的连接器才支持通过 Azure 进行外部传输。
用于指定存储位置的参数在 为连接器设置配置选项 中有详细说明:
备注
对于外部数据传输,必须在 Spark Connector 安装/配置过程中创建和配置存储位置。
此外,连接器在外部传输期间创建的文件是临时的,但连接器不会自动从存储位置删除这些文件。若要删除文件,请使用下列方法之一:
手动删除它们。
设置连接器的
purge参数。有关此参数的详细信息,请参阅 为连接器设置配置选项。设置存储系统参数(如 Amazon S3 生命周期策略参数),以便在传输完成后清理文件。
列映射¶
将数据从 Spark 表复制到 Snowflake 表时,如果列名不匹配,则可以使用 columnmapping 参数将列名从 Spark 映射到 Snowflake,该参数在 为连接器设置配置选项 中有详细说明。
备注
只有内部数据传输支持列映射。
查询下推¶
为了获得最佳性能,您通常希望避免在系统之间读取大量数据或传输大型中间结果。理想情况下,大多数处理应在靠近数据存储的位置进行,以利用参与存储的功能来动态消除不需要的数据。
查询下推允许在 Snowflake 中处理(全部或部分)大型和复杂的 Spark 逻辑计划,通过使用 Snowflake 完成大部分实际工作来提高性能效率,
Snowflake Connector for Spark 2.1.0 版(及更高版本)支持查询下推。
并非在所有情况下都可进行下推。例如,无法将 Spark UDFs 向下推送到 Snowflake。有关下推支持的操作列表,请参阅 下推。
备注
如果需要下推所有运算,请考虑编写代码以改用 Snowpark API。Snowpark 还支持下推 Snowflake UDFs。
Databricks 集成¶
Databricks 已将 Snowflake Connector for Spark 集成到 Databricks 统一分析平台,以提供 Spark 和 Snowflake 之间的本机连接。
有关更多信息,包括使用 Scala 和 Python 的代码示例,请参阅 数据源 – Snowflake (https://docs.databricks.com/spark/latest/data-sources/snowflake.html) (在 Databricks 文档中)或 在 Databricks 中为 Spark 配置 Snowflake。
Qubole 集成¶
Qubole 已将 Snowflake Connector for Spark 集成到 Qubole 数据服务 (QDS) 生态系统中,以提供 Spark 和 Snowflake 之间的本机连接。通过这种集成,Snowflake 可以直接在 Qubole 中添加为 Spark 数据存储。
将 Snowflake 添加为 Spark 数据存储后,数据工程师和数据科学家就可以使用 Spark 和 QDS UI、API 和 Notebook 执行以下操作:
执行高级数据转换,例如准备外部数据源并将其整合到 Snowflake 中,或者优化和转换 Snowflake 数据。
使用 Snowflake 中已有的数据在 Spark 中构建、训练和执行机器学习和 AI 模型。
有关更多信息,请参阅 Qubole-Snowflake 集成指南 (http://docs.qubole.com/en/latest/partner-integration/snowflake-integration/index.html) (在 Qubole 文档中)或 在 Qubole 中配置 Snowflake for Spark。