Overview of the Spark Connector¶
The Snowflake Connector for Spark enables using Snowflake as an Apache Spark data source, similar to other data sources (PostgreSQL, HDFS, S3, etc.).
Note
As an alternative to using Spark, consider writing your code to use Snowpark API instead. Snowpark allows you to perform all of your work within Snowflake (rather than in a separate Spark compute cluster). Snowpark also supports pushdown of all operations, including Snowflake UDFs. However, when you want to enforce row and column policies on Iceberg tables, use the Snowflake Spark Connector. For more information, see Enforce data protection policies when querying Apache Iceberg™ tables from Apache Spark™.
Interaction between Snowflake and Spark¶
The connector supports bi-directional data movement between a Snowflake cluster and a Spark cluster. The Spark cluster can be self-hosted or accessed through another service, such as Qubole, AWS EMR, or Databricks.
Using the connector, you can perform the following operations:
- Populate a Spark DataFrame from a table (or query) in Snowflake.
- Write the contents of a Spark DataFrame to a table in Snowflake.
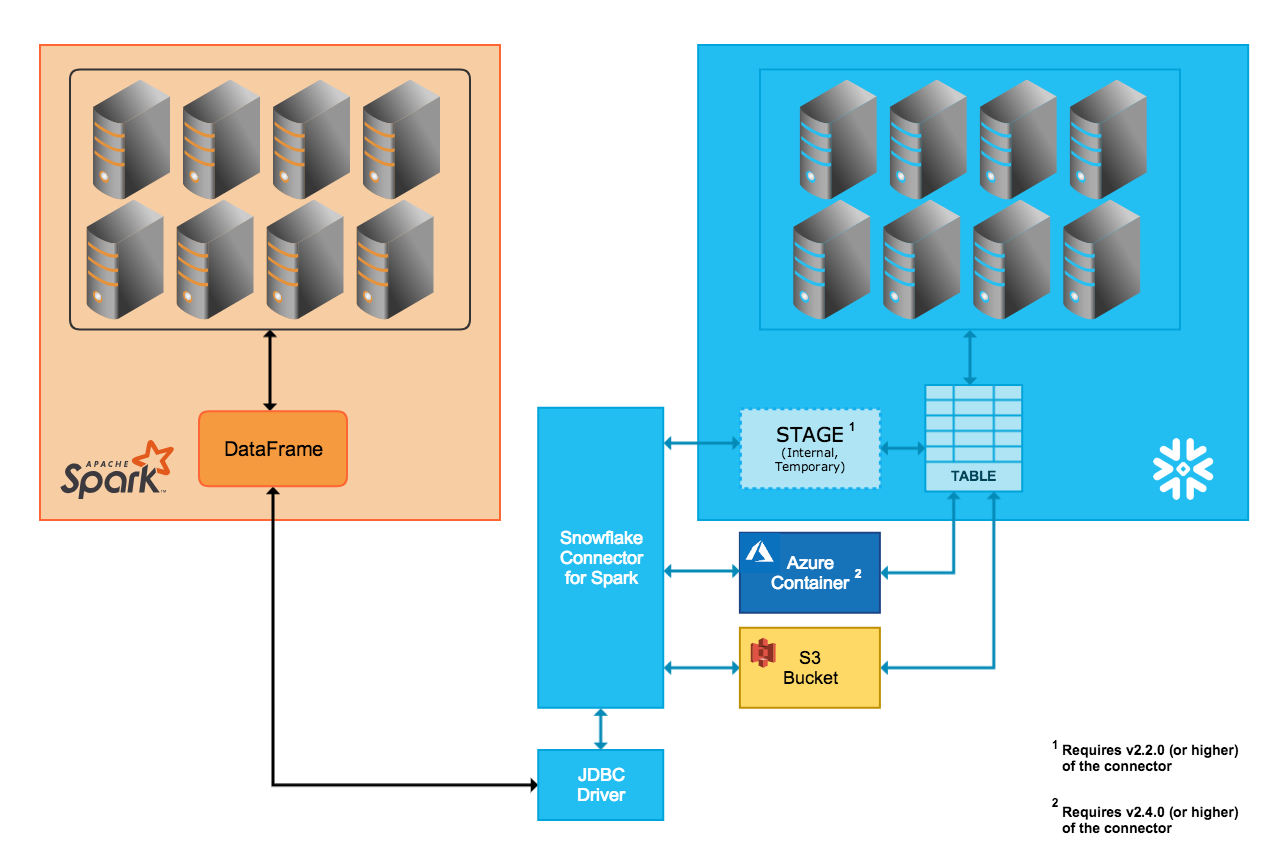
The connector uses Scala 2.12.x or 2.13.x to perform these operations and uses the Snowflake JDBC driver to communicate with Snowflake.
Note
The Snowflake Connector for Spark is not strictly required to connect Snowflake and Apache Spark; other 3rd-party JDBC drivers can be used. However, we recommend using the Snowflake Connector for Spark because the connector, in conjunction with the Snowflake JDBC driver, has been optimized for transferring large amounts of data between the two systems. It also provides enhanced performance by supporting query pushdown from Spark into Snowflake.
Data Transfer¶
The Snowflake Spark Connector supports two transfer modes:
- Internal transfer uses a temporary location created and managed internally/transparently by Snowflake.
- External transfer uses a storage location, usually temporary, created and managed by the user.
Tip
Use external data transfer if either of the following is true:
- You are using version 2.1.x or lower of the Spark Connector (which does not support internal transfer).
- Your transfer is likely to take 36 hours or more (internal transfer uses temporary credentials that expire after 36 hours).
Otherwise, we recommend using internal data transfer.
Internal Data Transfer¶
The transfer of data between the two systems is facilitated through a Snowflake internal stage that the connector automatically creates and manages:
- Upon connecting to Snowflake and initializing a session in Snowflake, the connector creates the internal stage.
- Throughout the duration of the Snowflake session, the connector uses the stage to store data while transferring it to its destination.
- At the end of the Snowflake session, the connector drops the stage, thereby removing all the temporary data in the stage.
Note that support for internal transfer requires a specific version (or higher) of the connector, based on the cloud platform for your Snowflake account:
- AWS:
The internal data transfer mode is supported only in version 2.2.0 (and higher) of the connector.
- Azure:
The internal data transfer mode is supported only in version 2.4.0 (and higher) of the connector.
- GCP:
The internal data transfer mode is supported only in version 2.7.0 (and higher) of the connector.
External Data Transfer¶
The transfer of data between the two systems is facilitated through a storage location that the user specifies and files automatically created by the connector:
- AWS:
Transfer data files are created and stored in an S3 bucket.
- Azure:
Transfer data files are created and stored in a Blob storage container. External transfer via Azure is supported only in version 2.4.0 (and higher) of the connector.
The parameter(s) to specify the storage location are documented in Setting Configuration Options for the Connector:
Note
For external data transfer, the storage location must be created and configured as part of the Spark connector installation/configuration.
Also, the files created by the connector during external transfer are intended to be temporary, but the connector does not automatically delete the files from the storage location. To delete the files, use any of the following methods:
- Delete them manually.
- Set the
purgeparameter for the connector. For more information about this parameter, see Setting Configuration Options for the Connector. - Set a storage system parameter, such as the Amazon S3 lifecycle policy parameter, to clean up the files after the transfer is done.
Column Mapping¶
When you copy data from a Spark table to a Snowflake table, if the column names do not match, you can map column names from Spark to Snowflake using the columnmapping parameter, which is
documented in Setting Configuration Options for the Connector.
Note
Column mapping is supported only for internal data transfer.
Query Pushdown¶
For optimal performance, you typically want to avoid reading lots of data or transferring large intermediate results between systems. Ideally, most of the processing should happen close to where the data is stored to leverage the capabilities of the participating stores to dynamically eliminate data that is not needed.
Query pushdown leverages these performance efficiencies by enabling large and complex Spark logical plans (in their entirety or in parts) to be processed in Snowflake, thus using Snowflake to do most of the actual work.
Query pushdown is supported in Version 2.1.0 (and higher) of the Snowflake Connector for Spark.
Pushdown is not possible in all situations. For example, Spark UDFs cannot be pushed down to Snowflake. See Pushdown for the list of operations supported for pushdown.
Note
If you need pushdown for all operations, consider writing your code to use Snowpark API instead. Snowpark also supports pushdown of Snowflake UDFs.
Databricks Integration¶
Databricks has integrated the Snowflake Connector for Spark into the Databricks Unified Analytics Platform to provide native connectivity between Spark and Snowflake.
For more details, including code examples using Scala and Python, see Data Sources — Snowflake (https://docs.databricks.com/spark/latest/data-sources/snowflake.html) (in the Databricks documentation) or Configuring Snowflake for Spark in Databricks.
Qubole Integration¶
Qubole has integrated the Snowflake Connector for Spark into the Qubole Data Service (QDS) ecosystem to provide native connectivity between Spark and Snowflake. Through this integration, Snowflake can be added as a Spark data store directly in Qubole.
Once Snowflake has been added as a Spark data store, data engineers and data scientists can use Spark and the QDS UI, API, and Notebooks to:
- Perform advanced data transformations, such as preparing and consolidating external data sources into Snowflake, or refining and transforming Snowflake data.
- Build, train, and execute machine learning and AI models in Spark using the data that already exists in Snowflake.
For more details, see the Qubole-Snowflake Integration Guide (http://docs.qubole.com/en/latest/partner-integration/snowflake-integration/index.html) (in the Qubole Documentation) or Configuring Snowflake for Spark in Qubole.