Parsing documents with AI_PARSE_DOCUMENT¶
AI_PARSE_DOCUMENT is a Cortex AI Function that extracts text, data, layout elements, and images from documents. It can be used with other functions to create custom document processing pipelines for a variety of use cases (see Cortex AI 函数:文档).
For information on using AI_PARSE_DOCUMENT to extract images, with examples, see Cortex AI 函数:使用 AI_PARSE_DOCUMENT 进行图像提取.
The function extracts text and layout from documents stored on internal or external stages and preserves reading order and structures like tables and headers. For information about creating a stage suitable for storing documents, see Create stage for media files.
AI_PARSE_DOCUMENT orchestrates advanced AI models for document understanding and layout analysis and processes complex multi-page documents with high fidelity.
PARSE_DOCUMENT 函数提供两种处理 PDF 文档的模式:
LAYOUT mode is the preferred choice for most use cases, especially for complex documents. It's specifically optimized for extracting text and layout elements like tables, making it the best option for building knowledge bases, optimizing retrieval systems, and enhancing AI based applications.
推荐使用 OCR 模式从手册、协议合同、产品详情页面、保险单和索赔以及 SharePoint 文档 中快速、高质量地提取文本。
For both modes, use the page_split option to split multi-page documents into separate
pages in the response. You can also use the page_filter option to process only specified pages.
If using page_filter, page_split is implied, and you do not need to set it explicitly.
AI_PARSE_DOCUMENT is horizontally scalable, enabling efficient batch processing of multiple documents simultaneously. Documents can be processed directly from object storage to avoid unnecessary data movement.
备注
PARSE_DOCUMENT 目前与自定义 网络策略 不兼容。
示例¶
Simple layout example¶
This example uses AI_PARSE_DOCUMENT's LAYOUT mode to process a two-column research paper. The page_split parameter
is set to TRUE in order to separate the document into pages in the response. AI_PARSE_DOCUMENT returns the content in Markdown
format. The following shows rendered Markdown for one of the processed pages (page index 4 in the JSON output) next to
the original page. The raw Markdown is shown in the JSON response following the images.
Page from the original document |
Extracted Markdown rendered as HTML |
|---|---|

|

|
小技巧
To view either of the these images at a more legible size, select it by clicking or tapping.
The following is the SQL command to process the original document:
The response from AI_PARSE_DOCUMENT is a JSON object containing metadata and text from the pages of the document, like the following. Some page objects have been omitted for brevity.
Table structure extraction example¶
This example demonstrates extracting structural layout, including a table, from a 10-K filing. The following shows the rendered results for one of the processed pages (page index 28 in the JSON output).
Page from the original document |
Extracted Markdown rendered as HTML |
|---|---|
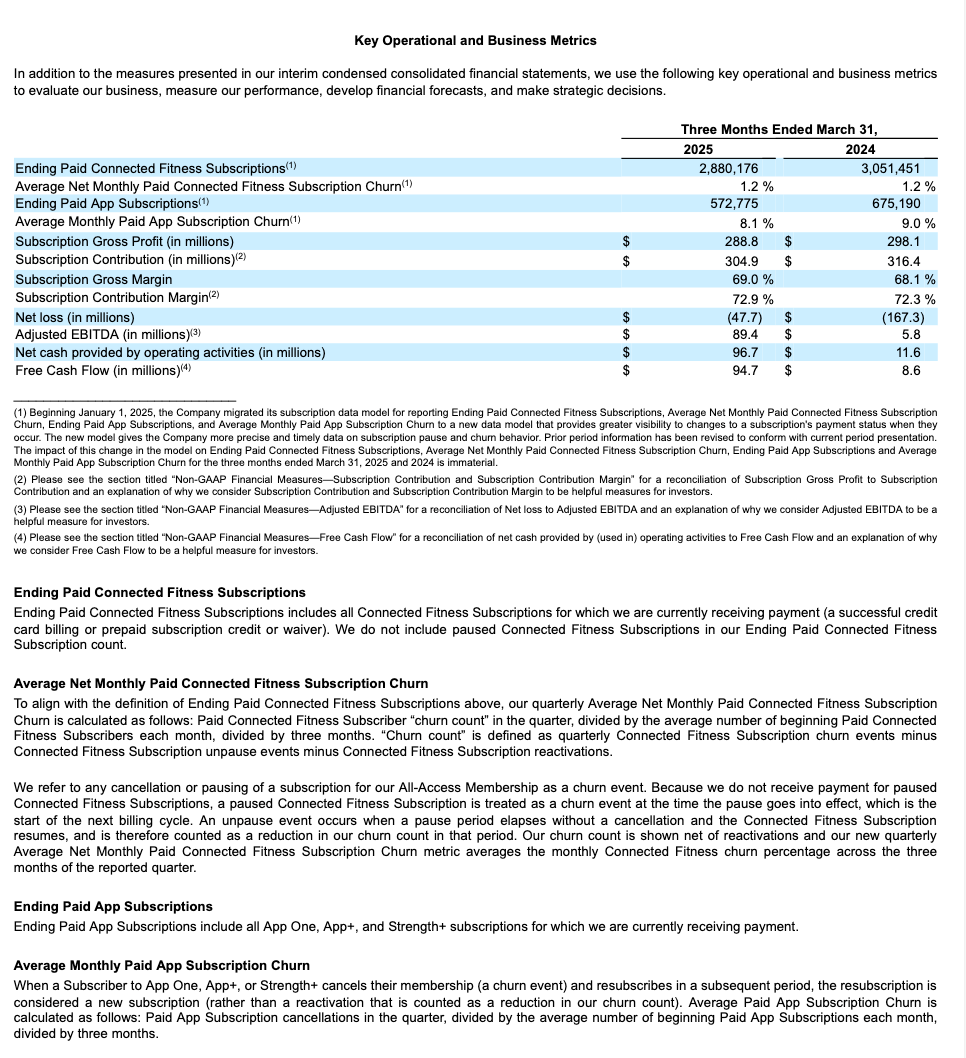
|
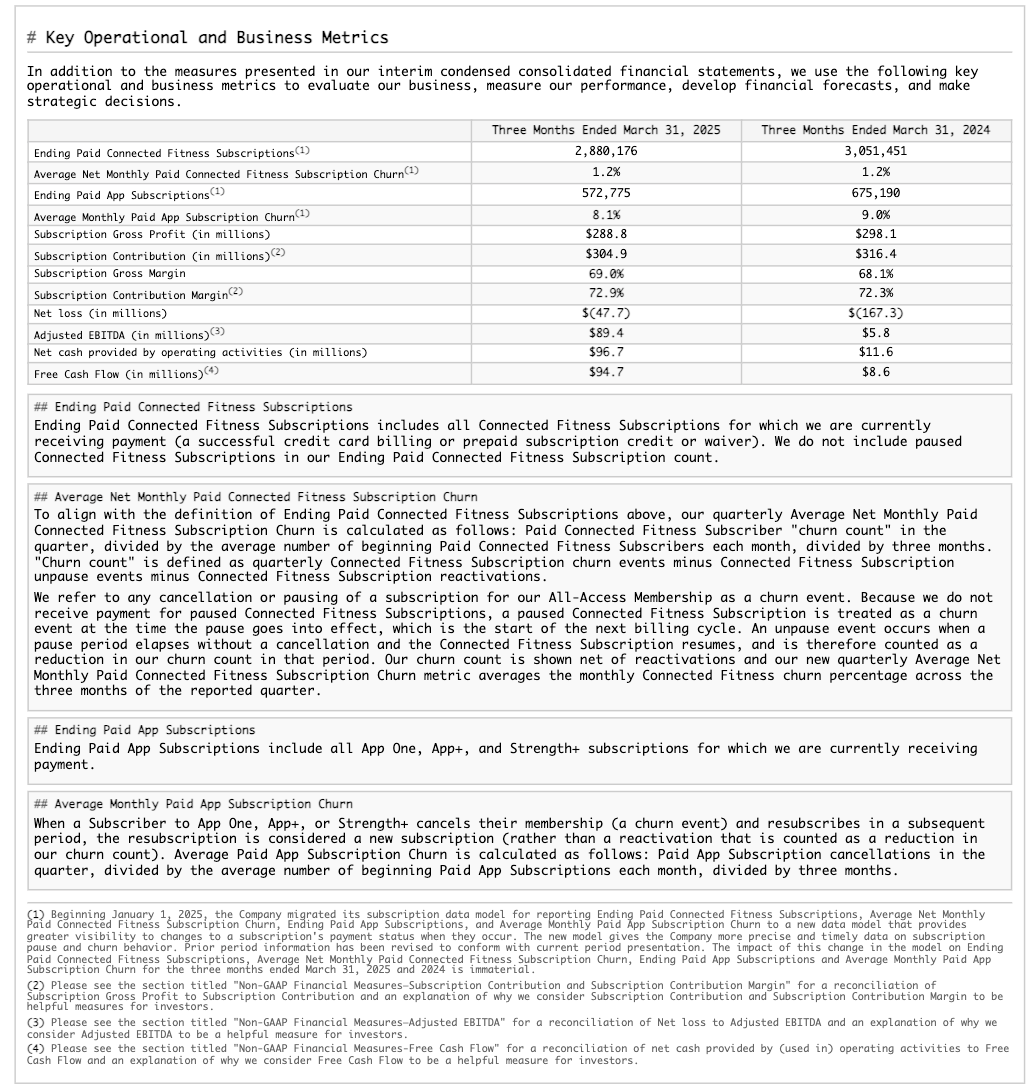
|
小技巧
To view either of the these images at a more legible size, select it by clicking or tapping.
The following is the SQL command to process the original document:
The response from AI_PARSE_DOCUMENT is a JSON object containing metadata and text from the pages of the document, like the following. The results for all but the page previously shown have been omitted for brevity.
Slide deck example¶
This example demonstrates extracting structural layout from a presentation. Below we show the rendered results for one of the processed slides (page index 17 in the JSON output).
Slide from the original document |
Extracted Markdown rendered as HTML |
|---|---|

|

|
小技巧
To view either of the these images at a more legible size, select it by clicking or tapping.
The following is the SQL command to process the original document:
The response from AI_PARSE_DOCUMENT is a JSON object containing metadata and the text from the slides of the presentation, like the following. The results for some slides have been omitted for brevity.
Multilingual document example¶
This example showcases AI_PARSE_DOCUMENT's multilingual capabilities by extracting structural layout from a German article. AI_PARSE_DOCUMENT preserves the reading order of the main text even when images and pull quotes are present.
Page from the original document |
Extracted Markdown rendered as HTML |
|---|---|

|

|
小技巧
To view either of the these images at a more legible size, select it by clicking or tapping.
The following is the SQL command to process the original document. Since the document has a single page, you do not need page splitting for this example.
The response from AI_PARSE_DOCUMENT is a JSON object containing metadata and the text from the document, like the following.
Snowflake Cortex can produce a translation to any supported language (English, language code 'en', in this case) as follows:
The translation is as follows:
OCR 模式¶
OCR mode extracts text from scanned documents, such as screenshots or PDFs containing images of text. It does not preserve layout.
Customer Data
Process only certain pages of a document¶
This example demonstrates using the page_filter option to extract specific pages from a document, specifically
the first page of a 55-page research paper. Keep in mind that page indexes starts at 0 and ranges are inclusive of
the start value but exclusive of the end value. For example, start: 0, end: 1 returns only the first page (index 0).
Result:
Classify multiple documents¶
To classify multiple documents, first create a table of the files by retrieving the document locations from a directory, converting these locations to FILE objects.
Then apply AI_PARSE_DOCUMENT to each document in the table and process the results, for example by passing them to AI_CLASSIFY to categorize the documents by type. This is an efficient approach to batch document analysis in a document collection.
The query returns classification labels for each document.
输入要求¶
PARSE_DOCUMENT 针对数字化文档和扫描文档进行了优化。下表列出了输入文档的限制和要求:
最大文件大小 |
100 MB |
|---|---|
每个文档的最大页数 |
500 |
Maximum page resolution |
|
Supported file type |
PDF、PPTX、DOCX、JPEG、JPG、PNG、TIFF、TIF |
暂存区加密 |
服务器端加密 |
字体大小 |
8 分或以上可获得最佳效果 |
支持的文档功能¶
页面方向 |
PARSE_DOCUMENT 自动检测页面方向。 |
|---|---|
Page splitting |
AI_PARSE_DOCUMENT can split multi-page documents into individual pages and parse each separately. This is useful for processing large documents that exceed the maximum size. |
Page filtering |
AI_PARSE_DOCUMENT can process some of the pages in a document, instead of all of them, by specifying page ranges. This is useful when you know what pages the information you're looking for is on. |
字符 |
PARSE_DOCUMENT 检测以下字符:
|
Images |
AI_PARSE_DOCUMENT generates markup for images in the document, but does not currently extract the actual images. |
Structured elements |
PARSE_DOCUMENT 自动检测页面方向。 |
字体大小 |
AI_PARSE_DOCUMENT recognizes text in most serif and sans-serif fonts, but may have difficulty with decorative or script fonts. The function does not recognize handwriting. |
支持的语言¶
PARSE_DOCUMENT 经过精心训练,可使用以下语言:
OCR 模式 |
LAYOUT 模式 |
|---|---|
|
|
区域可用性¶
以下 Snowflake 区域的账户支持此功能:
AWS |
Azure |
Google Cloud Platform |
|---|---|---|
US 西部 2(俄勒冈州) |
US 东部 2(弗吉尼亚州) |
US 中部 1(爱荷华州) |
US 东部(俄亥俄州) |
US 西部 2(华盛顿) |
|
US 东部 1(弗吉尼亚北部) |
欧洲(荷兰) |
|
欧洲(爱尔兰) |
||
欧洲中部 1(法兰克福) |
||
Europe West 2 (London) |
||
亚太地区(悉尼) |
||
亚太地区(东京) |
AI_PARSE_DOCUMENT has cross-region support in other Snowflake regions. For information on enabling Cortex AI cross-region support, see 跨区域推理.
访问控制要求¶
要使用 PARSE_DOCUMENT 函数,ACCOUNTADMIN 角色用户须将 SNOWFLAKE.CORTEX_USER 数据库角色授予将调用该函数的用户。有关详细信息,请参阅 Cortex LLM privileges 主题。
成本注意事项¶
The Cortex AI_PARSE_DOCUMENT function incurs compute costs based on the number of pages per document processed. The following describes how pages are counted for different file formats:
对于文档文件格(PDF、DOCX),文档中的每一页均按页计费。
对于图像文件格式(JPEG、JPG、TIF、TIFF、PNG),每个单独的图像文件均按页计费。
For HTML and TXT files, each chunk of 3,000 characters is billed as a page, including the last chunk, which may be less than 3,000 characters.
Snowflake 建议在使用较小仓库(不大于 MEDIUM)的情况下执行调用 Cortex PARSE_DOCUMENT 函数的查询。较大的仓库并不会提高性能。
错误条件¶
Snowflake Cortex PARSE_DOCUMENT 可能会生成以下错误消息:
Message |
Explanation |
|---|---|
|
Input document contains unsupported language. |
|
The document is in unsupported format. |
|
The file format is not supported and understood as a binary file. |
|
The document exceeds the 500-page limit. |
|
Image input or a converted document page is larger than the supported dimensions. |
|
Page is larger than the supported dimensions. |
|
The document is larger than 100 MB. |
|
The file does not exist. |
|
The file can't be accessed due to insufficient privileges. |
|
出现超时。 |
|
System error occurred. Wait and try again. |
法律声明¶
输入和输出的 Data Classification 如下表所示。
输入 Data Classification |
输出 Data Classification |
|---|---|
Usage Data |
Customer Data |
有关更多信息,请参阅 Snowflake AI 和 ML。