Snowpark ML Modeling:ML 模型开发¶
备注
Snowpark ML Modeling API 自包版本 1.1.1 开始正式发布。
Snowpark ML Modeling API 使用熟悉的 Python 框架,例如 scikit-learn 和 XGBoost,用于在 Snowflake 内部预处理数据、特征工程和训练模型。
使用 Snowpark ML Modeling 开发模型的好处包括:
特征工程和预处理: 通过分布式执行来提高常用的 scikit-learn 预处理函数的性能和可扩展性。
模型训练: 利用分布式超参数优化,加快 scikit-learn XGBoost 和 LightGBM 模型的训练,无需手动创建存储过程或用户定义函数 (UDFs)。
Snowpark ML Modeling API 提供的估计器和转换器的 APIs 与 scikit-learn、xgboost 和 lightgbm 库中的相似。您可以使用这些 APIs 来构建和训练机器学习模型,这些模型可用于 Snowpark ML 操作,例如 Snowpark Model Registry。
小技巧
请参阅 ` 通过 Snowpark ML 使用机器学习简介 <https://quickstarts.snowflake.com/guide/intro_to_machine_learning_with_snowpark_ml_for_python/#0 (https://quickstarts.snowflake.com/guide/intro_to_machine_learning_with_snowpark_ml_for_python/#0)>`_,其中提供了一个 Snowpark ML 中的端到端工作流程示例,包括建模 API。
备注
本主题假设已经安装了 Snowpark ML 及其建模依赖项。请参阅 安装 Snowpark ML。
示例¶
查看以下示例,了解 Snowpark ML Modeling API 与您可能熟悉的机器学习库的相似之处。
预处理¶
此示例说明了如何使用 Snowpark ML Modeling 数据预处理和转换函数。示例中使用的两个预处理函数(MixMaxScaler 和 OrdinalEncoder)使用 Snowflake 的分布式处理引擎,与客户端或存储过程实现相比,性能有显著提高。有关详细信息,请参阅 分布式预处理。
import numpy as np
import pandas as pd
import random
import string
from sklearn.datasets import make_regression
from snowflake.ml.modeling.preprocessing import MinMaxScaler, OrdinalEncoder
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
NUMERICAL_COLS = ["X1", "X2", "X3"]
CATEGORICAL_COLS = ["C1", "C2", "C3"]
FEATURE_COLS = NUMERICAL_COLS + CATEGORICAL_COLS
CATEGORICAL_OUTPUT_COLS = ["C1_OUT", "C2_OUT", "C3_OUT"]
FEATURE_OUTPUT_COLS = ["X1_FEAT_OUT", "X2_FEAT_OUT", "X3_FEAT_OUT", "C1_FEAT_OUT", "C2_FEAT_OUT", "C3_FEAT_OUT"]
# Create a dataset with numerical and categorical features
X, _ = make_regression(
n_samples=1000,
n_features=3,
noise=0.1,
random_state=0,
)
X = pd.DataFrame(X, columns=NUMERICAL_COLS)
def generate_random_string(length):
return "".join(random.choices(string.ascii_uppercase, k=length))
categorical_feature_length = 2
categorical_features = {}
for c in CATEGORICAL_COLS:
categorical_column = [generate_random_string(categorical_feature_length) for _ in range(X.shape[0])]
categorical_features[c] = categorical_column
X = X.assign(**categorical_features)
features_df = session.create_dataframe(X)
# Fit a pipeline with OrdinalEncoder and MinMaxScaler on Snowflake
pipeline = Pipeline(
steps=[
(
"OE",
OrdinalEncoder(
input_cols=CATEGORICAL_COLS,
output_cols=CATEGORICAL_OUTPUT_COLS,
)
),
(
"MMS",
MinMaxScaler(
input_cols=NUMERICAL_COLS + CATEGORICAL_OUTPUT_COLS,
output_cols=FEATURE_OUTPUT_COLS,
)
),
]
)
pipeline.fit(features_df)
# Use the pipeline to transform a dataset.
result = pipeline.transform(features_df)
训练¶
此示例说明如何使用 Snowpark ML Modeling 训练简单的 xgboost 分类器模型,然后运行预测。在这里,Snowpark ML API 与 xgboost 类似,只是在列的指定方式上有一些区别。有关这些差异的详细信息,请参阅 一般 API 差异。
import pandas as pd
from sklearn.datasets import make_classification
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Set up data.
X, y = make_classification(
n_samples=40000,
n_features=6,
n_informative=4,
n_redundant=1,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_df = session.create_dataframe(features_pandas)
# Train an XGBoost model on snowflake.
xgboost_model = XGBClassifier(
input_cols=FEATURE_COLS,
label_cols=LABEL_COLS,
output_cols=OUTPUT_COLS
)
xgboost_model.fit(features_df)
# Use the model to make predictions.
predictions = xgboost_model.predict(features_df)
predictions[OUTPUT_COLS].show()
基于非合成数据进行特征预处理和训练¶
此示例使用来自地面上大气 Cherenkov 望远镜的高能伽玛粒子数据。该望远镜利用电磁簇射(伽玛射线引发)中产生的带电粒子发出的辐射来观测高能伽玛粒子。探测器记录了穿过大气层的 Cherenkov 辐射(可见光至紫外波长),从而可以重建伽玛簇射参数。该望远镜还探测了宇宙簇射中大量存在的强子射线,这些射线会产生类似伽玛射线的信号。
目标是开发一种用于区分伽玛射线和强子射线的分类模型。该模型使科学家能够过滤掉背景噪音并集中精力研究真正的伽玛射线信号。通过伽玛射线,科学家能够观察各种宇宙事件,例如恒星的诞生、死亡、宇宙爆炸以及物质在极端条件下的行为。
粒子数据可从 MAGIC 伽玛望远镜 (https://archive.ics.uci.edu/dataset/159/magic+gamma+telescope) 下载。下载并解压缩数据,将 DATA_FILE_PATH 变量设置为指向数据文件,然后运行以下代码以将其加载到 Snowflake。
DATA_FILE_PATH = "~/Downloads/magic+gamma+telescope/magic04.data"
# Setup
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
import posixpath
import os
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
session.sql("""
CREATE OR REPLACE TABLE Gamma_Telescope_Data(
F_LENGTH FLOAT,
F_WIDTH FLOAT,
F_SIZE FLOAT,
F_CONC FLOAT,
F_CONC1 FLOAT,
F_ASYM FLOAT,
F_M3_LONG FLOAT,
F_M3_TRANS FLOAT,
F_ALPHA FLOAT,
F_DIST FLOAT,
CLASS VARCHAR(10))
""").collect()
session.sql("CREATE OR REPLACE STAGE SNOWPARK_ML_TEST_DATA_STAGE").collect()
session.file.put(
DATA_FILE_PATH,
"SNOWPARK_ML_TEST_DATA_STAGE/magic04.data",
auto_compress=False,
overwrite=True,
)
session.sql("""
COPY INTO Gamma_Telescope_Data FROM @SNOWPARK_ML_TEST_DATA_STAGE/magic04.data
FILE_FORMAT = (TYPE = 'CSV' field_optionally_enclosed_by='"',SKIP_HEADER = 0);
""").collect()
session.sql("select * from Gamma_Telescope_Data limit 5").collect()
加载数据后,使用以下代码按照下列步骤进行训练和预测。
预处理数据:
用平均值替换缺失值。
使用标准缩放器将数据居中。
训练 xgboost 分类器来确定事件类型。
基于训练和测试数据集测试模型的准确性。
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.preprocessing import StandardScaler
from snowflake.ml.modeling.impute import SimpleImputer
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.metrics import accuracy_score
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Step 1: Create train and test dataframes
all_data = session.sql("select *, IFF(CLASS = 'g', 1.0, 0.0) as LABEL from Gamma_Telescope_Data").drop("CLASS")
train_data, test_data = all_data.random_split(weights=[0.9, 0.1], seed=0)
# Step 2: Construct training pipeline with preprocessing and modeling steps
FEATURE_COLS = [c for c in train_data.columns if c != "LABEL"]
LABEL_COLS = ["LABEL"]
pipeline = Pipeline(steps = [
("impute", SimpleImputer(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("scaler", StandardScaler(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("model", XGBClassifier(input_cols=FEATURE_COLS, label_cols=LABEL_COLS))
])
# Step 3: Train
pipeline.fit(train_data)
# Step 4: Eval
predict_on_training_data = pipeline.predict(train_data)
training_accuracy = accuracy_score(df=predict_on_training_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
predict_on_test_data = pipeline.predict(test_data)
eval_accuracy = accuracy_score(df=predict_on_test_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
print(f"Training accuracy: {training_accuracy} \nEval accuracy: {eval_accuracy}")
分布式超参数优化¶
此示例说明如何使用 Snowpark ML 对 scikit-learn 中 GridSearchCV 的实现运行分布式超参数优化。使用分布式仓库计算资源并行执行各个运行。有关分布式超参数优化的详细信息,请参阅 分布式超参数优化。
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from sklearn.datasets import make_classification
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Create a session using your favorite login option.
# In this example we use a session builder with `SnowflakeLoginOptions`.
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Set up data.
def set_up_data(session: Session, n_samples: int) -> DataFrame:
X, y = make_classification(
n_samples=n_samples,
n_features=6,
n_informative=2,
n_redundant=0,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_pandas.head()
features_df = session.create_dataframe(features_pandas)
return features_df
features_df = set_up_data(session, 10**4)
# Create a warehouse to use for the tuning job.
session.sql(
"""
CREATE or replace warehouse HYPERPARAM_WH
WITH WAREHOUSE_SIZE = 'X-SMALL'
WAREHOUSE_TYPE = 'Standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;"""
).collect()
session.use_warehouse("HYPERPARAM_WH")
# Tune an XGB Classifier model using sklearn GridSearchCV.
DISTRIBUTIONS = dict(
n_estimators=[10, 50],
learning_rate=[0.01, 0.1, 0.2],
)
estimator = XGBClassifier()
grid_search_cv = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, input_cols=FEATURE_COLS, label_cols=LABEL_COLS, output_cols=OUTPUT_COLS)
grid_search_cv.fit(features_df)
# Use the best model to make predictions.
predictions = grid_search_cv.predict(features_df)
predictions[OUTPUT_COLS].show()
# Retrieve sklearn model, and print the best score
sklearn_grid_search_cv = grid_search_cv.to_sklearn()
print(sklearn_grid_search_cv.best_score_)
要真正了解分布式优化的强大功能,请基于一百万行数据进行训练。
large_features_df = set_up_data(session, 10**6)
# Scale up the warehouse for a faster fit. This takes 2m15s to run on an L warehouse versus 4m5s on a XS warehouse.
session.sql(f"ALTER WAREHOUSE {session.get_current_warehouse()} SET WAREHOUSE_SIZE='LARGE'").collect()
grid_search_cv.fit(large_features_df)
print(grid_search_cv.to_sklearn().best_score_)
Snowpark ML Modeling 类¶
所有 Snowpark ML 建模和预处理类都在 snowflake.ml.modeling 命名空间中。Snowpark ML 模块与 sklearn 命名空间中的相应模块同名。例如,与 sklearn.calibration 对应的 Snowpark ML 模块是 snowflake.ml.modeling.calibration。 xgboost 和 lightgbm 模块分别对应于 snowflake.ml.modeling.xgboost 和 snowflake.ml.modeling.lightgbm。
Snowpark ML Modeling API 为底层 scikit-learn、xgboost 和 lightgbm 类提供包装器,其中大部分在虚拟仓库中作为存储过程(在单个仓库节点上运行)执行。并非 scikit-learn 中的所有类都受 Snowpark ML 支持。有关当前可用类的列表,请参阅 Snowpark ML API 参考。
某些类(包括预处理类和指标类)支持分布式执行,与在本地执行相同的操作相比,可能会提供显著的性能优势。 有关更多信息,请参阅 分布式预处理 和 分布式超参数优化。下表列出了支持分布式执行的特定类。
Snowpark ML 模块名称 |
分布式类 |
|---|---|
|
|
|
|
|
|
|
|
一般 API 差异¶
小技巧
有关建模 API 的完整详细信息,请参阅 Snowpark ML API 参考。
Snowpark ML Modeling 包括基于 scikit-learn、xgboost 和 lightgbm 的数据预处理、转换和预测算法。Snowpark Python 类是原始包中相应类的替代品,具有类似的签名。但是,这些 APIs 是为与 Snowpark DataFrames(而非 NumPy 数组)配合使用而设计的。
尽管 Snowpark ML Modeling API 与 scikit-learn 相似,但仍有一些关键区别。本部分将介绍如何为 Snowpark ML 中提供的估计器和转换器类调用 __init__ (构造函数)、fit 和 predict 方法。
除 scikit-learn、xgboost 或 lightgbm 中的等效类接受的参数外,所有 Snowpark ML Python 模型类的 构造函数 还接受另外五个参数(
input_cols、output_cols、sample_weight_col、label_cols和drop_input_cols)。这些是字符串或字符串序列,用于指定 Snowpark 或 Pandas DataFrame 中输入列、输出列、样本权重列和标签列的名称。如果您使用的某些数据集具有不同的名称,则可以在实例化后使用提供的 setter 方法之一更改这些名称,例如set_input_cols。由于您在实例化类时(或之后使用 setter 方法)指定列名,因此 Snowpark ML 模型类中的
fit和predict方法接受单个 DataFrame 而不是单独的数组作为输入、权重和标签。提供的列名用于从fit或predict中的 DataFrame 访问相应的列。请参阅 fit 和 predict。默认情况下,Snowpark ML 中的
transform和predict方法会返回一个 DataFrame,其中包含 DataFrame 传递给该方法的所有列,预测的输出则存储在其他列中。(您可以通过指定与输入列名称匹配的输出列名称进行就地转换,也可以通过传递drop_input_cols = True来删除输入列。)scikit-learn、xgboost 和 lightgbm 等效方法会返回仅包含结果的数组。Snowpark Python 转换器没有
fit_transform方法。但是,与 scikit-learn 一样,参数验证仅在fit方法中执行,因此即使转换器未进行任何拟合,您也应在transform之前的某个时刻调用fit。fit返回转换器,因此方法调用可以是链式的;例如,Binarizer(threshold=0.5).fit(df).transform(df)。Snowpark ML 转换器目前没有
inverse_transform方法。在许多用例中,这种方法是不必要的,因为默认情况下,输入列保留在输出数据框中。
您可以将任意 Snowpark ML Modeling 对象转换为相应的 scikit-learn、xgboost 或 lightgbm 对象,以便使用底层类型的所有方法和属性。请参阅 检索底层模型。
构造模型¶
除各个 scikit-learn 模型类接受的参数外,所有 Snowpark ML Modeling 类在实例化时都接受以下附加参数。
这些参数在技术上都是可选的,但您通常需要指定 input_cols 和/或 output_cols。label_cols 和 sample_weight_col 在表中注明的特定情况下是必需的,但在其他情况下可以省略。
小技巧
所有列名称都必须遵守 Snowflake 标识符要求。在创建表时,若要保留大小写或使用特殊字符(美元符号和下划线除外),必需将列名称放在双引号内。尽可能使用全大写的列名称,以与区分大小写的 Pandas DataFrames 兼容。
from snowflake.ml.modeling.preprocessing import MinMaxScaler
from snowflake.snowpark import Session
# Snowflake identifiers are not case sensitive by default.
# These column names will be automatically updated to ["COLUMN_1", "COLUMN_2", "COLUMN_3"] by the Snowpark DataFrame.
schema = ["column_1", "column_2", "column_3"]
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
--------------------------------------
|"COLUMN_1" |"COLUMN_2" |"COLUMN_3"|
--------------------------------------
|1 |2 |3 |
--------------------------------------
# Identify the column names using the Snowflake identifier.
input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"]
mms = MinMaxScaler(input_cols=input_cols)
mms.fit(df)
# To maintain lower case column names, include a double quote within the string.
schema = ['"column_1"', '"column_2"', '"column_3"']
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
----------------------------------------
|'"column_1"'|'"column_2"'|'"column_3"'|
----------------------------------------
|1 |2 |3 |
----------------------------------------
# Since no conversion took place, the schema labels can be used as the column identifiers.
mms = MinMaxScaler(input_cols=schema)
mms.fit(df)
参数 |
描述 |
|---|---|
|
字符串或字符串列表,表示包含特征的列名称。 如果省略此参数,则输入 DataFrame 中的所有列(由 |
|
字符串或字符串列表,表示包含标签的列名称。 必须为有监督估计器指定标签列,因为这些列无法通过推断得出。这些标签列用作模型预测的目标,应明确与 |
|
字符串或字符串列表,表示用于存储 如果省略此参数,对于有监督估计器,输出列名将通过在标签列名称前添加 要进行就地转换,请为 |
|
字符串或字符串列表,表示要从训练、转换和推断中排除的列的名称。输入和输出 DataFrames 之间的直通列保持不变。 如果您希望在训练或推理期间避免使用特定列(例如索引列),但不传递 |
|
字符串,表示包含示例权重的列名称。 加权数据集需要使用此实参。 |
|
布尔值,指示是否从结果 DataFrame 中移除输入列。默认为 |
示例¶
在 scikit-learn 中, DecisionTreeClassifier 构造函数没有任何必需实参;所有实参都有默认值。因此,在 scikit-learn 中,您可以编写:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
在 Snowpark ML 中,必须指定列名称(或不指定列名称,而接受默认值)。在此示例中,已显式指定列名称。
您可以通过直接向构造函数传递实参或在实例化后将实参设置为模型的属性来初始化 Snowpark ML DecisionTreeClassifier。(属性可随时更改。)
作为构造函数实参:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier( input_cols=feature_column_names, label_cols=label_column_names, sample_weight_col=weight_column_name, output_cols=expected_output_column_names )
通过设置模型属性:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.set_input_cols(feature_column_names) model.set_label_cols(label_column_names) model.set_sample_weight_col(weight_column_name) model.set_output_cols(output_column_names)
fit¶
Snowpark ML 分类器的 fit 方法需要一个包含所有列(包括特征、标签和权重)的 Snowpark 或 Pandas DataFrame。这与 scikit-learn 的 fit 方法不同,后者需要单独的特征、标签和权重输入。
在 scikit-learn 中,DecisionTreeClassifier.fit 方法调用如下所示:
model.fit(
X=df[feature_column_names], y=df[label_column_names], sample_weight=df[weight_column_name]
)
在 Snowpark ML 中,您只需要传递 DataFrame。您已经在初始化时或使用 setter 方法设置了输入、标签和权重列的名称,如 构造模型 中所示。
model.fit(df)
predict¶
Snowpark ML 类的 predict 方法还需要一个包含所有特征列的 Snowpark 或 Pandas DataFrame。结果是一个 DataFrame,其中包含输入 DataFrame 中所有不变的列和追加的输出列。您必须从此 DataFrame 中提取输出列。这与 scikit-learn 中的 predict 方法不同,后者只会返回结果。
示例¶
在 scikit-learn 中, predict 仅返回预测结果:
prediction_results = model.predict(X=df[feature_column_names])
要在 Snowpark ML 中仅获取预测结果,请从返回的 DataFrame 中提取输出列。在以下示例中,output_column_names 是包含输出列名称的列表:
prediction_results = model.predict(df)[output_column_names]
分布式预处理¶
Snowpark ML 中的许多数据预处理和转换函数都是使用 Snowflake 的分布式执行引擎实现的,与单节点执行(即存储过程)相比,它具有显著的性能优势。要了解哪些函数支持分布式执行,请参阅 Snowpark ML Modeling 类。
下图展示了在中等 Snowpark 优化型仓库中运行的大型公共数据集的说明性性能数据,将存储过程中运行的 scikit-learn 与 Snowpark ML 的分布式实现进行了比较。在许多情况下,使用 Snowpark ML Modeling 时,您的代码运行速度可以加快 25 到 50 倍。
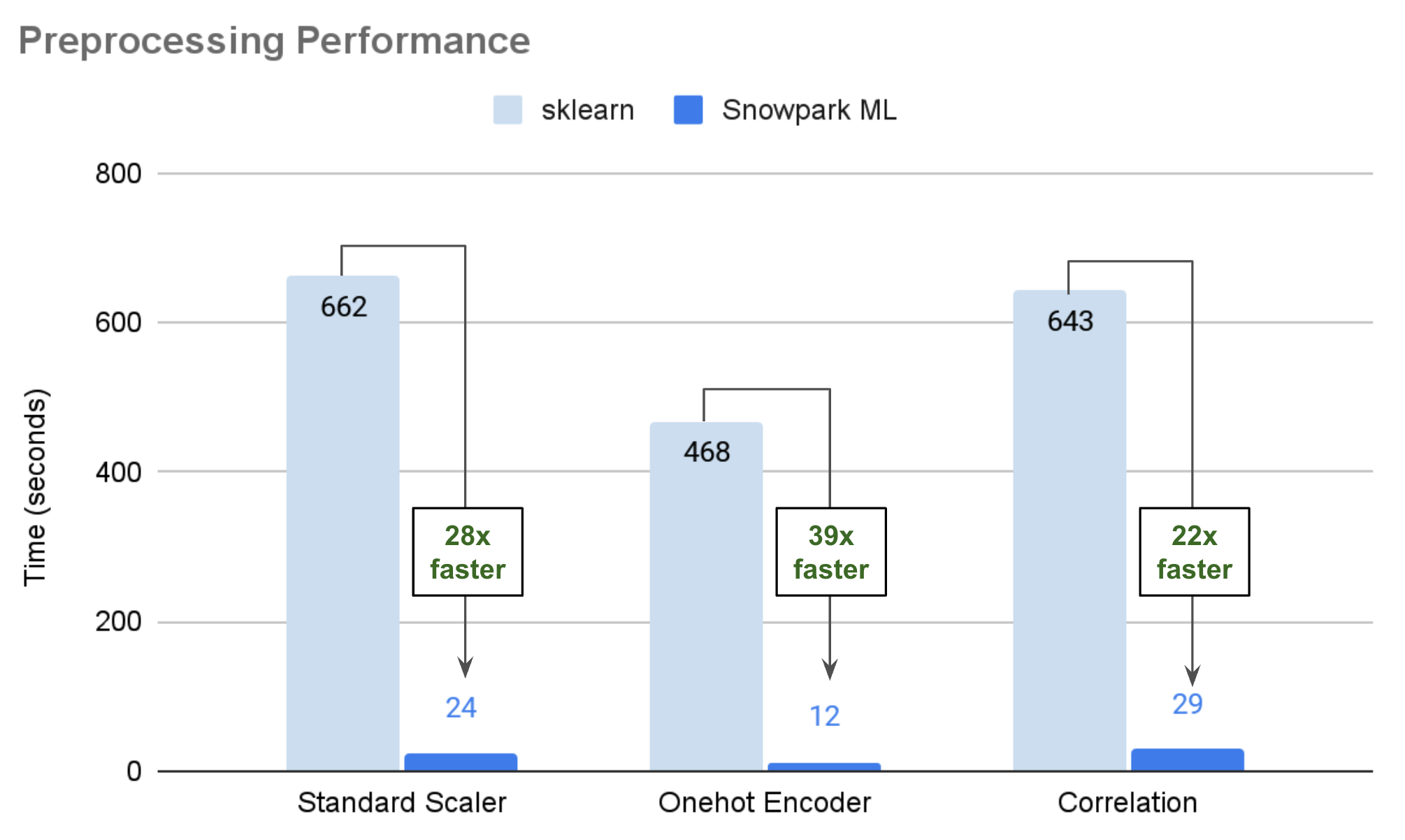
拟合如何分布¶
Snowpark ML 预处理转换器的 fit 方法接受 Snowpark 或 Pandas DataFrame、拟合数据集,然后返回拟合后的转换器。
对于 Snowpark DataFrames,分布式拟合使用 SQL 引擎。转换器生成 SQL 查询以计算必要的状态(例如平均值、最大值或计数)。然后,由 Snowflake 执行这些查询,并在本地将结果具体化。对于无法在 SQL 中计算的复杂状态,转换器会从 Snowflake 提取中间结果,并通过元数据执行本地计算。
对于在转换期间需要临时状态表的复杂转换器(例如,
OneHotEncoder或OrdinalEncoder),这些表使用 Pandas DataFrames 在本地表示。Pandas DataFrames 在本地进行拟合,与 scikit-learn 拟合类似。转换器使用所提供的参数创建相应的 scikit-learn 转换器。然后,对 scikit-learn 转换器进行拟合,继而 Snowpark ML 转换器从 scikit-learn 对象中推导出必要的状态。
转换如何分布¶
Snowpark ML 预处理转换器的 transform 方法接受 Snowpark 或 Pandas DataFrame、转换数据集,然后返回转换后的数据集。
对于 Snowpark DataFrames,分布式转换通过 SQL 引擎执行。拟合后的转换器会生成一个 Snowpark DataFrame,其中包含表示转换后的数据集的底层 SQL 查询。
transform方法会对简单转换(例如StandardScaler或MinMaxScaler)执行惰性计算,因此在transform方法期间,实际上不执行任何转换。但是,某些复杂的转换需要执行步骤。这其中包括在转换期间需要临时状态表的转换器(例如
OneHotEncoder和OrdinalEncoder)。此类转换器会从 Pandas DataFrame(存储对象状态)创建一个临时表,用于联接和其他操作。另一种情况是设置了某些参数时。例如,如果转换器被设置为通过引发错误来处理在转换期间发现的未知值,那么转换器会将数据(包括列、未知值等)进行具体化。Pandas DataFrames 在本地进行转换,与 scikit-learn 转换类似。转换器使用
to_sklearnAPI 创建相应的 scikit-learn 转换器,并在内存中执行转换。
分布式超参数优化¶
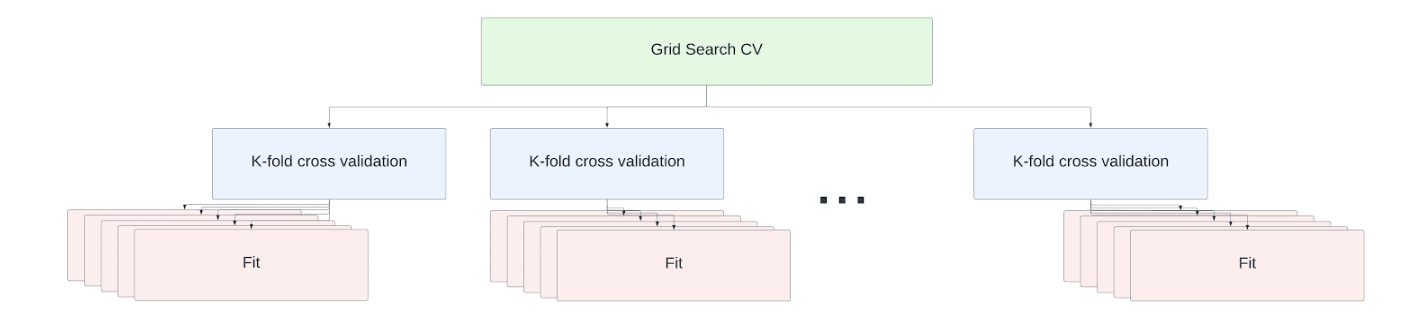
超参数调优是数据科学工作流程中不可或缺的一部分。Snowpark ML API 提供 scikit-learn GridSearchCV 和 RandomizedSearchCV APIs 的分布式实现,以便在单节点和多节点仓库上实现高效的超参数调优。
小技巧
默认情况下,Snowpark ML 启用分布式超参数优化。要禁用该优化,请使用以下 Python 导入。
import snowflake.ml.modeling.parameters.disable_distributed_hpo
最小的 Snowflake 虚拟仓库 (XS) 或 Snowpark 优化型仓库 (M) 只有一个节点。每增大一个规格,节点数量就会翻倍。
对于单节点 (XS) 仓库,默认情况下会使用 scikit-learn 的 Joblib 多处理框架来充分利用节点的容量。
小技巧
每个拟合操作都需要将该训练数据集自己的副本加载到 RAM 中。如果数据集大于约 10 GB,则可能会耗尽内存。要处理如此大规模的数据集,请禁用分布式超参数优化(使用 import snowflake.ml.modeling.parameters.disable_distributed_hpo)并将 n_jobs 参数设置为 1,以最大限度地减少并发性。
对于多节点仓库,交叉验证调优作业中的 fit 操作分布在不同节点上。无需更改代码即可扩展。估计器拟合在仓库中所有节点上的所有可用内核上并行执行。
以 scikit-learn 库提供的 ` 加利福尼亚州住房数据集 <https://scikit-learn.org/stable/datasets/real_world.html#california-housing-dataset (https://scikit-learn.org/stable/datasets/real_world.html#california-housing-dataset)>`_ 为例进行说明。该数据集包括 20,640 行数据,其中包含以下信息:
MedInc:街区组的收入中位数
HouseAge:街区组的中位房龄
AveRooms:每户的平均房间数
AveBedrms:每户的平均卧室数
人口:街区组人口
AveOccup:平均家庭成员数
纬度*和*经度
该数据集的目标是收入中位数,以十万美元为单位进行表示。
在本例中,我们对随机森林回归器进行网格搜索交叉验证,以找到预测收入中位数的最佳超参数组合。
from snowflake.ml.modeling.ensemble.random_forest_regressor import RandomForestRegressor
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
from sklearn import datasets
def load_housing_data() -> DataFrame:
input_df_pandas = datasets.fetch_california_housing(as_frame=True).frame
# Set the columns to be upper case for consistency with Snowflake identifiers.
input_df_pandas.columns = [c.upper() for c in input_df_pandas.columns]
input_df = session.create_dataframe(input_df_pandas)
return input_df
input_df = load_housing_data()
# Use all the columns besides the median value as the features
input_cols = [c for c in input_df.columns if not c.startswith("MEDHOUSEVAL")]
# Set the target median value as the only label columns
label_cols = [c for c in input_df.columns if c.startswith("MEDHOUSEVAL")]
DISTRIBUTIONS = dict(
max_depth=[80, 90, 100, 110],
min_samples_leaf=[1,3,10],
min_samples_split=[1.0, 3,10],
n_estimators=[100,200,400]
)
estimator = RandomForestRegressor()
n_folds = 5
clf = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, cv=n_folds, input_cols=input_cols, label_cols=label_col)
clf.fit(input_df)
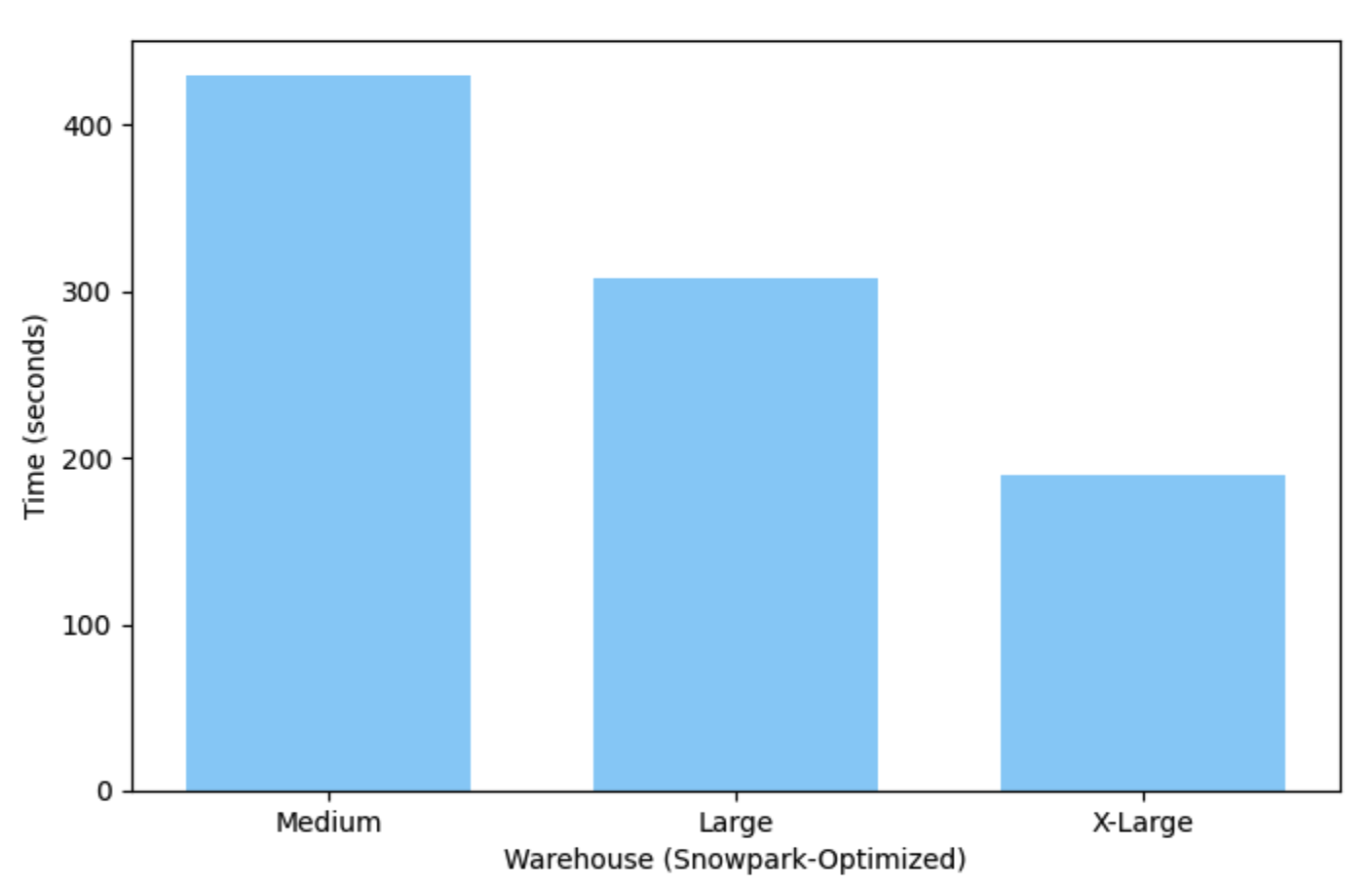
此示例在中等(单节点)Snowpark 优化型仓库上运行仅需 7 分钟多一点,而在 X-Large 仓库上运行仅需 3 分钟。
部署和运行您的模型¶
训练模型的结果是一个 Python Snowpark ML 模型对象。您可以通过调用模型的 predict 方法使用经过训练的模型进行预测。这会创建一个用户定义的临时函数,用于在 Snowflake 虚拟仓库中运行模型。此函数将在您的 Snowpark ML 会话结束时自动删除(例如,当脚本结束或关闭 Jupyter 笔记本时)。
要在会话结束后保留用户定义的函数,您可以手动创建该函数。 有关更多信息,请参阅关于该主题的 ` 快速入门 <https://github.com/Snowflake-Labs/sfguide-getting-started-machine-learning/blob/main/hol/2_1_DEMO_model_building_scoring.ipynb (https://github.com/Snowflake-Labs/sfguide-getting-started-machine-learning/blob/main/hol/2_1_DEMO_model_building_scoring.ipynb)>`_。
Snowpark ML 模型注册表还支持持久化模型,使查找和部署模型变得更加轻松。请参阅 Snowflake Model Registry (Snowpark ML Ops)。
多重转换的管道¶
在 scikit-learn 中,使用管道运行一系列转换的情况很常见。scikit-learn 管道不能与 Snowpark ML 类一起使用,因此 Snowpark ML 提供了一个 Snowpark Python 版本的 sklearn.pipeline.Pipeline,用于运行一系列转换。此类位于 snowflake.ml.modeling.pipeline 包中,其工作原理与 scikit-learn 版本相同。
检索底层模型¶
Snowpark ML 模型可以“展开”,即使用以下方法(视库而定)转换为底层的第三方模型类型:
to_sklearnto_xgboostto_lightgbm
然后,可以访问底层模型的所有属性和方法,并在本地针对估计器运行它们。例如,在 GridSearchCV 示例 中,我们将网格搜索估计器转换为 scikit-learn 对象,以检索最佳得分。
best_score = grid_search_cv.to_sklearn().best_score_
已知限制¶
Snowpark ML 估计器和转换器目前不支持稀疏输入或稀疏响应。如果您有稀疏数据,请先将其转换为密集格式,然后再传递给 Snowpark ML 的估计器或转换器。
Snowpark ML 包目前不支持矩阵数据类型。如果对估计器和转换器进行的操作会产生矩阵结果,则会失败。
无法保证结果数据中行的顺序与输入数据中行的顺序相匹配。
故障排除¶
向日志记录添加更多详细信息¶
Snowpark ML 使用 Snowpark Python 的日志记录。默认情况下,Snowpark ML 会将 INFO 级别的消息记录到标准输出。要获得更详细的日志,以帮助解决 Snowpark ML 的问题,您可以将该级别更改为某个 ` 受支持的级别 <https://docs.python.org/3/library/logging.html#logging-levels (https://docs.python.org/3/library/logging.html#logging-levels)>`_。
DEBUG 生成的日志中包含最为详细的信息。要将日志记录级别设置为 DEBUG,请执行以下操作:
import logging, sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
常见问题的解决方案¶
下表为解决 Snowflake ML 建模可能出现的问题提供了一些建议。
问题或错误消息 |
可能的原因 |
解决方案 |
|---|---|---|
NameError(例如“name x is not defined”)、ImportError 或 ModuleNotFoundError |
模块或类名称出现排印错误,或未安装 Snowpark ML。 |
有关正确的模块和类名称,请参阅 Snowpark ML Modeling 类表。确保已安装 Snowpark ML 模块(请参阅 安装 Snowpark ML)。 |
KeyError(“not in index”或“none of [Index[..]] are in the [columns]”) |
列名称不正确。 |
检查并更正列名称。 |
SnowparkSQLException,“does not exist or not authorize” |
表不存在,或者您对表没有足够的权限。 |
确保相应表存在且用户的角色具有权限。 |
SnowparkSQLException,“invalid identifier PETALLENGTH” |
列数不正确(通常是缺少列)。 |
检查创建模型类时指定的列数,并确保传递的列数正确。 |
InvalidParameterError |
将不恰当的类型或值作为参数传递。 |
在交互式 Python 会话中使用 |
TypeError,“unexpected keyword argument” |
命名实参中有排印错误。 |
在交互式 Python 会话中使用 |
ValueError,“array with 0 sample(s)” |
传入的数据集为空。 |
确保数据集不为空。 |
SnowparkSQLException,“authentication token has expired” |
会话已过期。 |
如果您使用的是 Jupyter 笔记本,请重新启动内核以创建新会话。 |
ValueError,例如“cannot convert string to float” |
数据类型不匹配。 |
在交互式 Python 会话中使用 |
SnowparkSQLException,“cannot create temporary table” |
在存储过程中使用了一个模型类,而该存储过程未使用调用方的权限运行。 |
使用调用方权限(而非所有者权限)创建存储过程。 |
SnowparkSQLException,“function available memory exceeded” |
在标准仓库中,您的数据集大于 5 GB。 |
切换到 :doc:` Snowpark-Optimized Warehouses </user-guide/warehouses-snowpark-optimized>`。 |
OSError,“no space left on device” |
您的模型超过标准仓库的大约 500 MB 容量。 |
切换到 :doc:` Snowpark-Optimized Warehouses </user-guide/warehouses-snowpark-optimized>`。 |
xgboost 版本不兼容或导入 xgboost 时出错 |
您安装时使用的是 |
根据错误消息的要求升级或降级包。 |
涉及 |
尝试在不同类型的模型上使用其中一种方法。 |
将 |
Jupyter Notebook 内核在基于 arm 的 Mac(M1 或 M2 芯片)上崩溃:“内核在当前单元或之前的单元中执行代码时崩溃。” |
使用不正确的架构安装了 XGBoost 或者另一个库。 |
使用 |
“lightgbm.basic.LightGBMError: (0000) 的功能名称中不支持特殊 JSON 字符。” |
LightGBM 不支持在 |
重命名 Snowpark DataFrames 中的列。在大多数情况下,用下划线替换非字母数字字符就足够了。下面的 Python 辅助函数可能很有用。 def fix_values(F, column):
return F.upper(F.regexp_replace(F.col(column), "[^a-zA-Z0-9]+", "_"))
|
延伸阅读¶
有关原始库功能的完整信息,请参阅原始库的文档。
Scikit-Learn (https://scikit-learn.org/stable/modules/classes.html)
XGBoost (https://xgboost.readthedocs.io/en/stable/python/index.html)
LightGBM (https://lightgbm.readthedocs.io/en/stable/Python-API.html)
致谢¶
本文档的某些部分源自 scikit-learn 文档,该文档根据 BSD-3 “新版”或“修订版”许可证获得授权,版权归 © 2007-2023 scikit-learn 开发者所有。保留所有权利。
本文档的某些部分源自 XGboost 文档,该文档受 Apache License 2.0(2004 年 1 月)保护,版权归 © 2019 的版权所有者所有。保留所有权利。
本文档的某些部分源自 LightGBM 文档,该文档已获 MIT 许可,版权归 © Microsoft Corp. 所有。保留所有权利。