Snowflake ML:端到端机器学习¶
Snowflake ML 是一组集成的功能,可在单个平台中基于您治理的数据进行端到端机器学习。这是一个用于 ML 开发和生产的统一环境,针对大规模分布式特征工程、模型训练和以及 CPU 和 GPU 计算的推理进行了优化,无需手动调整或配置。
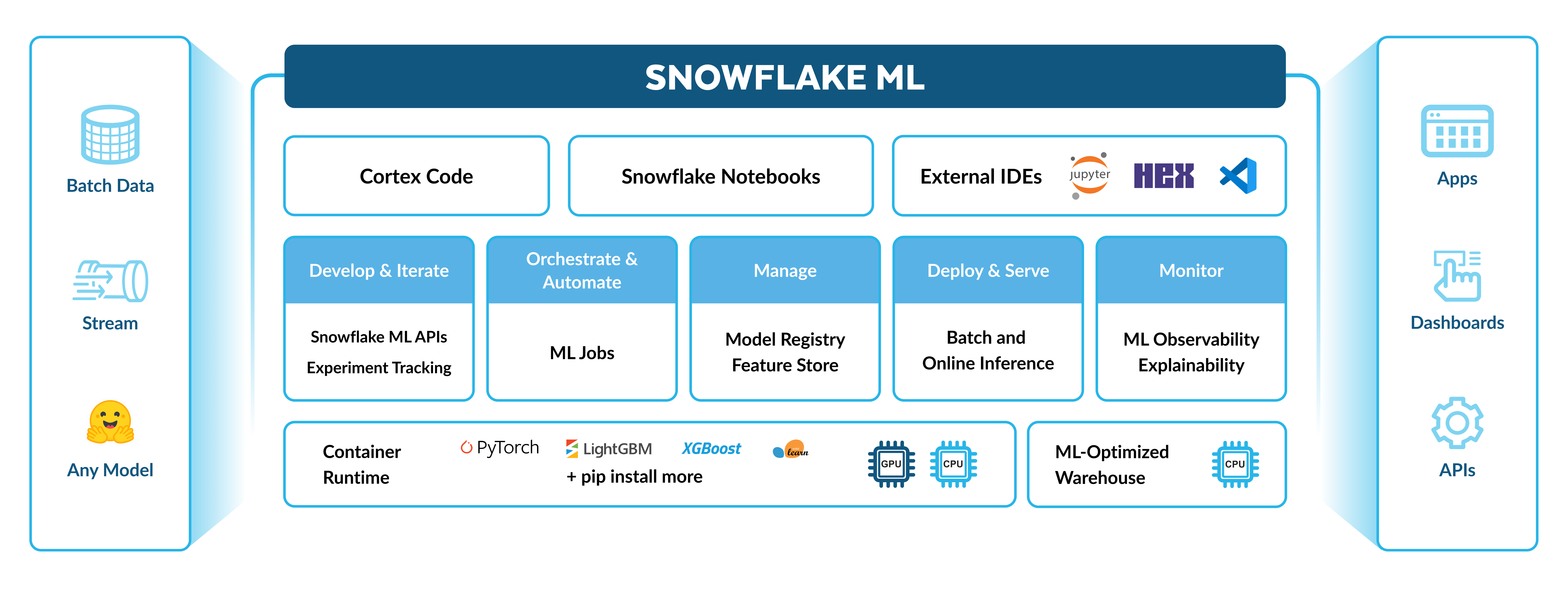
Snowflake 中扩展端到端 ML 工作流是无缝的。您可以执行以下操作:
准备数据
使用 Snowflake 特征商店创建和使用功能
使用容器运行时上的 Snowflake 笔记本提供的任何开源包,通过 CPUs 或 GPUs 训练模型
创建实验,根据设定的指标评估经过训练的模型
使用 Snowflake ML 作业运行您的管道
使用 Snowflake Model Registry 部署您的模型进行大规模推理
通过 ML 可观察性和可解释性监控您的生产模型
使用 ML 沿袭追踪 ML 管道中特征、数据集和模型的源数据
Snowflake ML 还具有灵活性和模块化特性。您可以将您在 Snowflake 中开发的模型部署到 Snowflake 之外,而外部训练的模型可以轻松地带入 Snowflake 中进行推理。
适用于数据科学家和 ML 工程师的功能¶
容器运行时的 Snowflake 笔记本¶
容器运行时 Snowflake 笔记本 为在 Snowflake 中训练和微调大型模型提供了类似 Jupyter 的环境,无需进行基础设施管理。使用预安装的包(如 PyTorch、XGBoost 或 Scikit-learn)开始训练,或者安装来自开源存储库(如 HuggingFace 或 PyPI)的包。容器运行时经过优化,可在 Snowflake 的基础设施上运行,为您提供高效的数据加载、分布式模型训练和超参数调整。
Snowflake 特征平台¶
Snowflake 特征平台 是一个集成的解决方案,用于定义、管理、存储和发现从数据中派生的 ML 特征。Snowflake 特征平台支持从批处理和流式处理数据源进行自动增量刷新,因此只需定义一次特征管道,即可使用新数据不断更新。
ML 作业¶
使用 Snowflake ML 作业 开发并自动化 ML 管道。ML 作业还使倾向于在外部 IDE(VS 代码、PyCharm、SageMaker 笔记本)工作的团队能够将函数、文件或模块向下调度到 Snowflake 的容器运行时。
实验¶
使用 实验 记录模型训练的结果,并以有组织的方式评估模型集合。实验可帮助您为用例选择最佳模型,并将其投入生产。可以在 Snowflake 上的模型训练期间将训练记录在实验中,也可以上传自己的元数据和之前训练的工件。训练结束后,在 Snowsight 中查看所有结果并根据您的需求选择合适的模型。
Snowflake Model Registry 和模型服务¶
Snowflake Model Registry 允许记录和管理您所有的 ML 模型,无论他们是在 Snowflake 还是其他平台上训练。您可以使用模型注册表中的模型来大规模运行推理任务。您可以使用模型服务将模型部署到 Snowpark Container Service 中进行推理。
ML 可观察性¶
ML 可观察性 提供了监视 Snowflake 中模型性能指标的工具。您可以跟踪生产中的模型、监控性能和漂移指标,并为性能阈值设置警报。此外,无论模型在何处训练,均可使用 ML 可解释性函数为 Snowflake Model Registry 中的模型计算 Shapley 值。
ML 沿袭¶
ML 沿袭 是一种能够追踪 ML 工件沿袭的功能,涵盖从源数据到特征、数据集及模型的端到端链路。这使得 ML 资产在整个生命周期内都具有可再现性、合规性和调试性。
Snowflake 数据集¶
Snowflake 数据集 提供了一个不可变、版本化的数据快照,适合机器学习模型引入。
适用于业务分析师的功能¶
对于业务分析师,可使用 ML 函数 缩短常见场景的开发时间,例如使用 SQL 在整个组织内进行预测和异常检测。
其他资源¶
请参阅以下资源开始使用 Snowflake ML:
训练端到端 ML 模型 (http://quickstarts.snowflake.com/guide/end-to-end-ml-workflow/)
快速入门 (https://quickstarts.snowflake.com/guide/intro_to_machine_learning_with_snowpark_ml_for_python)
如需提前获取当前正在开发的其他功能的文档,请联系您的 Snowflake 代表。