事务¶
事务是作为一个单元提交或回滚的一系列 SQL 语句。
简介¶
什么是事务?¶
事务是作为原子单元处理的一系列 SQL 语句。事务中的所有语句要么一起应用(提交),要么一起撤销(回滚)。Snowflake 事务保证了 ACID 属性 (link removed)。
事务可以同时包括读取和写入。
事务遵循以下规则:
事务永远不会 嵌套。例如,不能创建将回滚已提交的 内部 事务的 外部 事务,也不能创建将提交已回滚的 内部 事务的 外部 事务。
事务与单个会话相关联。多个会话不能共享同一事务。有关处理同一会话中具有重叠线程的事务的信息,请参阅 事务和多线程。
术语¶
本主题内容:
术语 DDL 包括 CTAS 语句 (CREATE TABLE AS SELECT) 以及其他定义数据库对象的 DDL 语句。
术语 DML 是指 INSERT、UPDATE、DELETE、MERGE、和 TRUNCATE 语句。
术语 查询语句 是指 SELECT 和 CALL 语句。
虽然 CALL 语句(调用 存储过程)是一条语句,但它调用的存储过程可以包含多条语句。存储过程和事务有特殊的规则。
显式事务¶
可以通过执行 BEGIN 语句显式启动事务。Snowflake 支持同义词 BEGIN WORK 和 BEGIN TRANSACTION。Snowflake 建议使用 BEGIN TRANSACTION。
可以通过执行 COMMIT 或 ROLLBACK 显式结束事务。Snowflake 支持 COMMIT 的同义词 COMMIT WORK,以及 ROLLBACK 的同义词 ROLLBACK WORK。
通常,如果事务已经处于活动状态,任何 BEGIN TRANSACTION 语句都会被忽略。但是,用户应避免使用额外的 BEGIN TRANSACTION 语句,因为这会使人类读者更难将 COMMIT(或 ROLLBACK)语句与相应的 BEGIN TRANSACTION 语句配对。
此规则的一个例外涉及嵌套存储过程调用。有关详细信息,请参阅 范围内事务。
备注
显式事务应仅包含 DML 语句和查询语句。DDL 语句隐式提交活动的事务(有关详细信息,请参阅 DDL 部分)。
隐式事务¶
事务可以隐式开始和结束,而无需显式的 BEGIN TRANSACTION 或 COMMIT/ROLLBACK。隐式事务的行为方式与显式事务相同。但是,确定隐式事务何时启动的规则与确定显式事务何时启动的规则不同。
停止和启动的规则取决于语句是 DDL 语句、DML 语句还是查询语句。如果语句是 DML 或查询语句,则规则取决于是否启用了 AUTOCOMMIT。
DDL¶
每个 DDL 语句都作为单独的事务执行。
如果在事务处于活动状态时执行 DDL 语句,则该 DDL 语句:
隐式提交活动的事务。
将 DDL 语句作为单独的事务执行。
因为 DDL 语句是它自己的事务,所以不能回滚 DDL 语句;包含 DDL 的事务在您可以执行显式 ROLLBACK 之前完成。
如果 DDL 语句后面紧跟 DML 语句,则该 DML 语句会隐式启动一个新事务。
AUTOCOMMIT¶
Snowflake 支持 AUTOCOMMIT 参数。AUTOCOMMIT 的默认设置为 TRUE(启用)。
AUTOCOMMIT 启用时:
显式事务之外的每个语句都被视为在其自己的隐式单语句事务中。换言之,如果该语句成功,则自动提交,如果失败,则自动回滚。
显式事务中的语句不受 AUTOCOMMIT 的影响。例如,即使 AUTOCOMMIT 为 TRUE,显式 BEGIN TRANSACTION ROLLBACK 中的语句也会回滚。
禁用 AUTOCOMMIT 时:
隐式 BEGIN TRANSACTION 在以下位置执行:
事务结束后的第一条 DML 语句。无论是什么结束了前面的事务(例如 DDL 语句、显式 COMMIT 或 ROLLBACK),都是如此。
禁用 AUTOCOMMIT 后的第一条 DML 语句。
在以下情况下执行隐式 COMMIT(如果事务已经处于活动状态):
执行 DDL 语句时。
执行
ALTER SESSION SET AUTOCOMMIT语句时,无论新值为 TRUE 还是 FALSE,也无论新值是否与先前的值不同都是如此。例如,即使您将 AUTOCOMMIT 设置为 FALSE (当它已经为 FALSE 时),也会执行隐式 COMMIT。
在以下情况下执行隐式 ROLLBACK(如果事务已经处于活动状态):
会话结束时。
存储过程结束时。
无论存储过程的活动事务是显式启动还是隐式启动,Snowflake 都会回滚活动事务并发出错误消息。
小心
不要在 存储过程 中更改 AUTOCOMMIT 设置。您将收到一条错误消息。
混合事务的隐式和显式开始和结束¶
为了避免编写令人困惑的代码,应避免在同一事务中混合隐式和显式开始和结束。以下情况是合法的,但不鼓励:
隐式启动的事务可以通过显式 COMMIT 或 ROLLBACK 来结束。
显式启动的事务可以通过隐式 COMMIT 或 ROLLBACK 来结束。
事务中的失败语句¶
尽管事务作为一个单元提交或回滚,但这并不等同于说它作为一个单元成功或失败。如果语句在事务中失败,您仍然可以提交事务,而不是回滚事务。
当事务中的 DML 语句或 CALL 语句失败时,该失败语句所做的更改将被回滚。但是,事务将保持活动状态,直到提交或回滚整个事务。如果已提交事务,则应用成功语句进行的更改。
例如,请考虑以下代码,该代码会向表中插入两个有效值和一个无效值:
如果执行失败的 INSERT 语句之后的语句,则最终 SELECT 语句的输出将包括整数值为 1 和 2 的行,即使事务中的其他语句之一失败也是如此。
备注
失败的 INSERT 语句之后的语句可能会执行,也可能不执行。行为取决于语句的运行方式和错误处理方式。
例如:
如果这些语句位于用 Snowflake Scripting 语言编写的存储过程中,失败的 INSERT 语句将引发异常。
如果不处理该异常,则存储过程永远不会完成,COMMIT 永远不会执行,因此打开的事务将隐式回滚。在这种情况下,该表不包含值
1或2。如果存储过程处理异常并提交失败的 INSERT 语句之前的语句,但不执行失败的 INSERT 语句之后的语句,则表中只存储值为
1的行。
如果这些语句不在存储过程中,则行为取决于语句的执行方式。例如:
如果语句是通过 Snowsight 执行的,则执行会在第一个错误时停止。
如果 SnowSQL 使用 ``-f``(文件名)选项执行语句,那么执行不会在第一个错误发生时停止,而是执行错误之后的语句。
事务和多线程¶
尽管多个会话不能共享同一个事务,但使用单个连接的多个 线程 共享同一个会话,因此共享同一个事务。此行为可能会导致意外结果,例如一个线程回滚在另一个线程中完成的工作。
当使用 Snowflake 驱动程序(如 Snowflake JDBC 驱动程序)或连接器(如 Snowflake Connector for Python)的客户端应用程序为多线程时,会出现这种情况。如果两个或多个线程共享同一连接,则这些线程也共享该连接中的当前事务。一个线程的 BEGIN TRANSACTION、COMMIT 或 ROLLBACK 会影响使用该共享连接的所有线程。如果线程异步运行,则结果可能无法预测。
同样,更改一个线程中的 AUTOCOMMIT 设置会影响使用同一连接的所有其他线程中的 AUTOCOMMIT 设置。
Snowflake 建议多线程客户端程序至少执行以下操作之一:
对每个线程使用单独的连接。
请注意,即使使用单独的连接,您的代码仍可能遇到生成不可预测输出的争用条件;例如,一个线程可能会在另一个线程尝试更新数据之前删除数据。
以同步而不是异步方式执行线程,以控制执行步骤的顺序。
存储过程和事务¶
通常,前面各节中介绍的规则也适用于存储过程。本节提供特定于存储过程的其他信息。
事务可以位于存储过程内,也可以位于事务内;但是,事务不能部分位于存储过程内部,部分位于存储过程外部,也不能在一个存储过程中启动而在另一个存储过程中完成。
例如:
不能在调用存储过程之前启动事务,然后在存储过程中完成事务。如果尝试执行此操作,Snowflake 会报告错误,如下所示:
不能在存储过程中启动事务,然后在从该过程返回后完成该事务。如果事务在存储过程中启动,并且在存储过程完成时仍处于活动状态,则会发生错误,并且事务将回滚。
这些规则也适用于嵌套存储过程。如果过程 A 调用过程 B,那么过程 B 不能完成在过程 A 中启动的事务,反之亦然。A 中的每个 BEGIN TRANSACTION 必须在 A 中有相应的 COMMIT(或 ROLLBACK),B 中的每个 BEGIN TRANSACTION 必须在 B 中有相应的 COMMIT(或 ROLLBACK)。
如果存储过程包含显式事务,则该事务可以包含存储过程正文的一部分或全部。例如,在下面的存储过程中,显式事务中只有部分语句。(为简单起见,此示例以及后续几个示例使用伪代码。)
非重叠事务¶
以下各节介绍:
在事务中使用存储过程。
在存储过程中使用事务。
在事务中使用存储过程¶
在最简单的情况下,如果满足以下条件,则将存储过程视为在事务内部:
在调用存储过程之前执行 BEGIN TRANSACTION。
相应的 COMMIT (或 ROLLBACK)在存储过程完成后执行。
存储过程的正文不包含显式或隐式的 BEGIN TRANSACTION 或 COMMIT(或 ROLLBACK)。
事务中的存储过程遵循封闭事务的规则:
如果已提交事务,则将提交过程中的所有语句。
如果事务已回滚,则该过程中的所有语句都将回滚。
以下伪代码显示了完全在显式事务中调用的存储过程:
这等效于执行以下语句序列:
在存储过程中使用事务¶
可以在存储过程中执行零个、一个或多个事务。以下伪代码显示了一个存储过程中两个事务的示例:
可以调用存储过程,如下所示:
这相当于执行以下序列:
在此代码中,将执行四个单独的事务。每个事务要么在过程外部启动和完成,要么在过程内部启动和完成。任何事务都不会跨过程边界拆分,即部分在存储过程内部,部分在存储过程外部。没有事务嵌套在另一个事务中。
范围内事务¶
包含一个事务的 存储过程 可以从另一个事务中调用。例如,存储过程中的事务可以包括对包含事务的另一个存储过程的调用。
Snowflake 不 将内部事务视为嵌套事务;相反,内部事务是一个 单独的事务。Snowflake 称这些为“自治范围内事务”(或简称为“范围内事务”)。
每个范围内事务的起点和终点决定了事务中包含哪些语句。开始和结束可以是显式的,也可以是隐式的。每个 SQL 语句只是一个事务的一部分。封闭 ROLLBACK 或 COMMIT 不会撤销封闭的 COMMIT 或 ROLLBACK。
备注
术语“内部”和“外部”通常用于描述嵌套操作,例如嵌套存储过程调用。但是,Snowflake 中的事务并不是真正的“嵌套”;因此,为了减少提及事务时的混淆,本文档经常使用术语“封闭的”和“封闭”,而不是“内部”和“外部”。
下图显示了两个存储过程和两个范围内事务。在此示例中,每个存储过程都包含其自己的独立事务。第一个存储过程调用第二个存储过程,因此这些过程在时间上重叠;但是,它们在内容上不重叠。阴影内框内的所有语句都在一个事务中;所有其他语句都在另一个事务中。
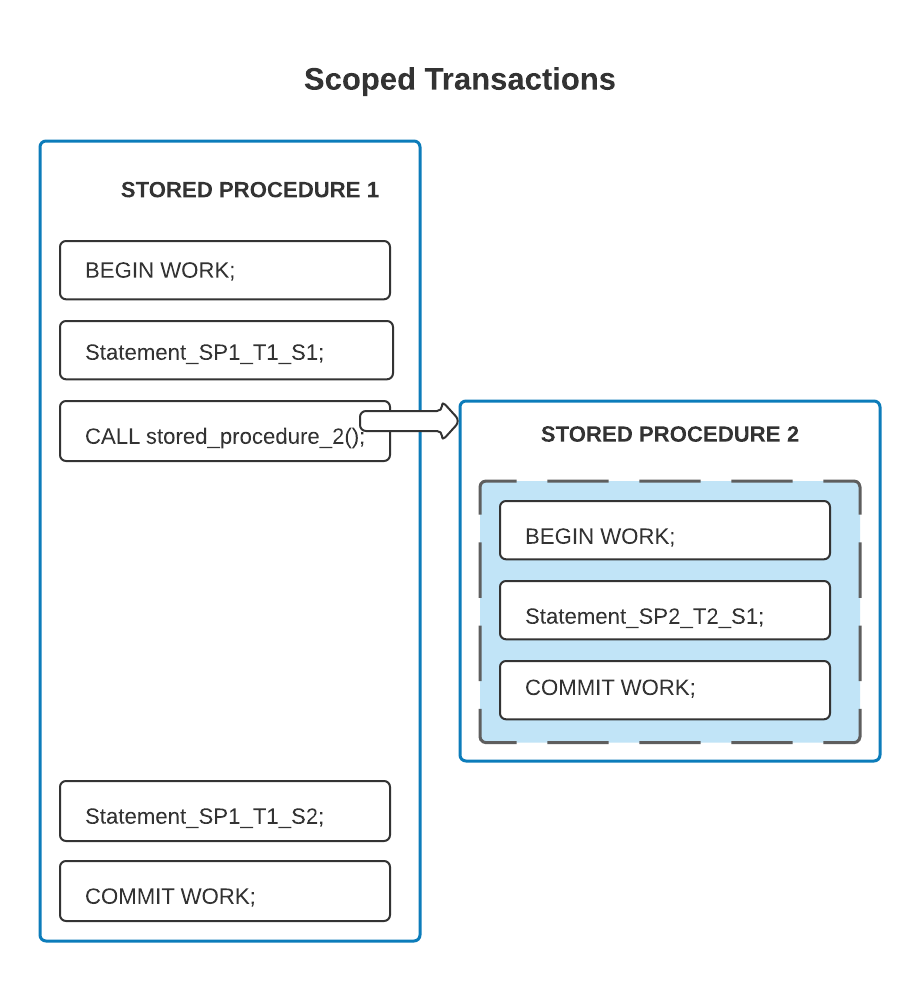
在下一个示例中,事务边界与存储过程边界不同;在封闭存储过程中启动的事务包括封闭存储过程中的部分语句,但不是全部语句。
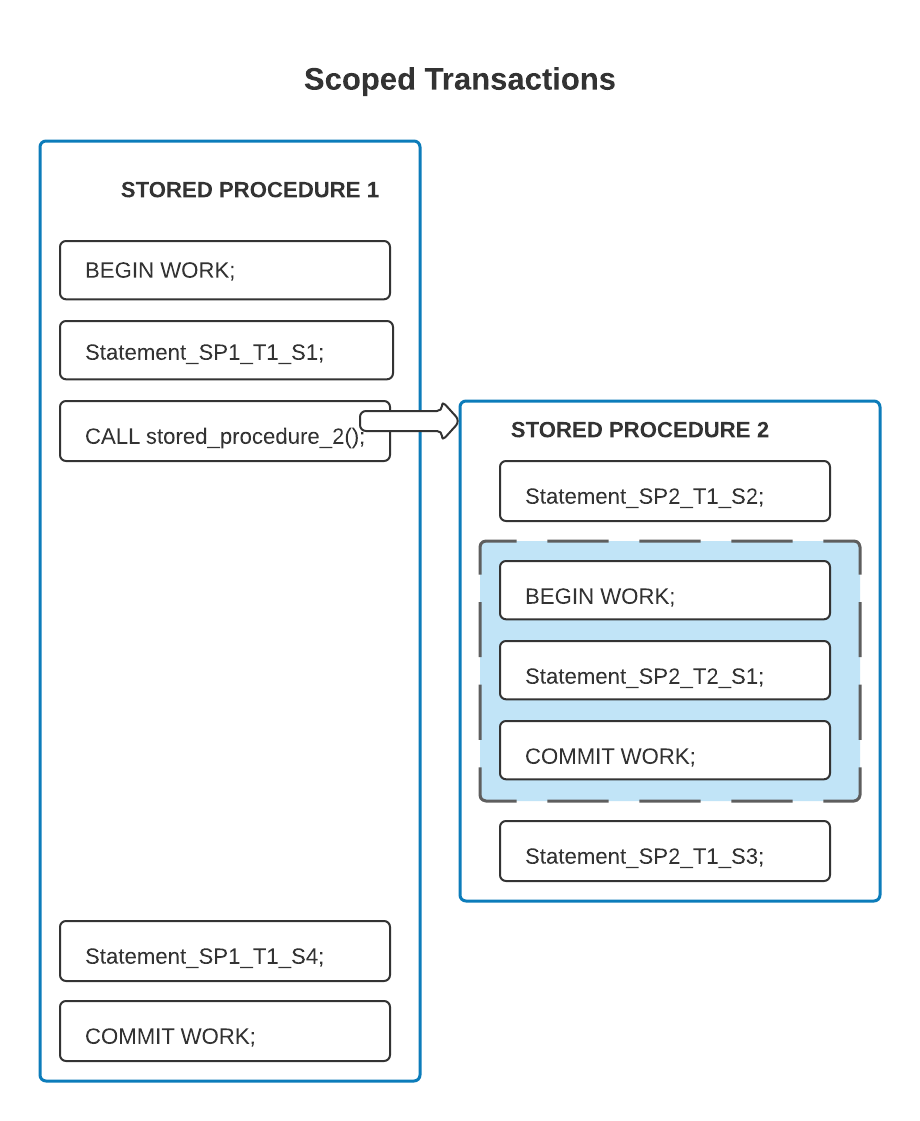
在上面的代码中,第二个存储过程包含第一个事务范围内的一些语句(SP2_T1_S2 和 SP2_T1_S3)。只有阴影内框中的语句 SP2_T2_S1 在第二个事务的范围内。
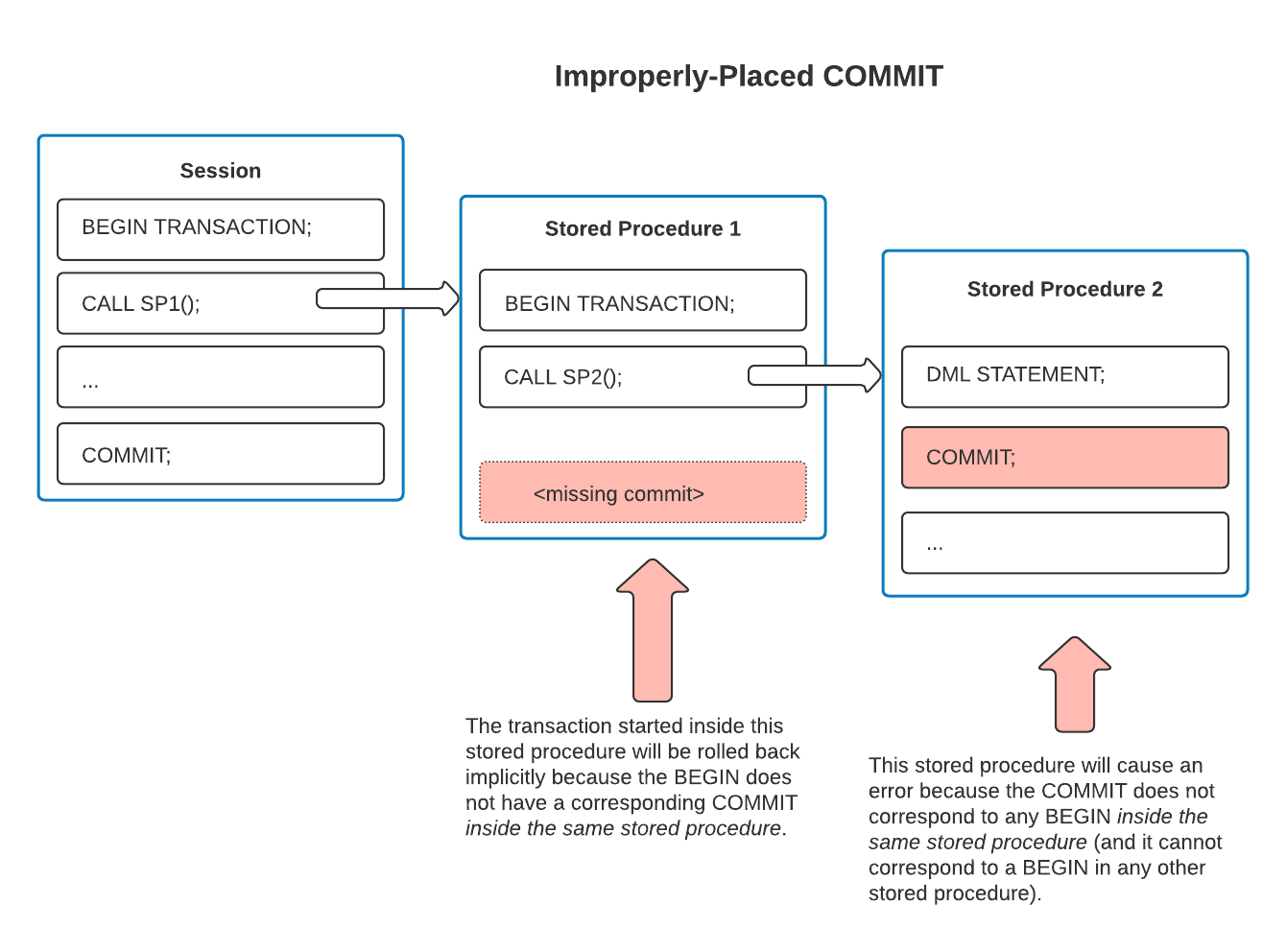
下一个示例演示了如果事务未在同一存储过程中开始和结束,则会出现的问题。该示例包含与 BEGIN 语句相同数量的 COMMIT 语句。但是,BEGIN 和 COMMIT 语句没有正确配对,因此该示例包含两个错误:
封闭存储过程启动范围内事务,但不会显式完成它。因此,该范围内事务在该存储过程的末尾会导致错误,并且活动事务将隐式回滚。
第二个存储过程包含一个 COMMIT,但在该存储过程中没有相应的 BEGIN。此 COMMIT 不 提交在第一个存储过程中启动的打开事务。相反,不正确的成对 COMMIT 会导致错误。
下一个示例显示了三个在时间上重叠的范围内事务。在此示例中,存储过程 p1() 从事务内部调用另一个存储过程 p2(),p2() 包含自己的事务,因此在 p2() 中启动的事务也独立运行。(此示例使用伪代码。)
在这三个范围内事务中:
任何存储过程之外的事务都包含语句
A和E。存储过程
p1()中的事务包含语句B和D。p2()中的事务包含语句C。
范围内事务的规则也适用于递归存储过程调用。递归调用只是一种特定类型的嵌套调用,遵循与嵌套调用相同的事务规则。
小心
如果重叠的范围内事务操作同一个数据库对象(例如表),则可能导致 死锁。仅在必要时才应使用范围内事务。
Implicit commits for transactions inside stored procedures¶
Some commands, including most DDL statements, implicitly commit any active transaction. If an outer stored procedure opens a transaction and an inner stored procedure executes such a command, the command returns the following error message:
For example, the following code fails because the DROP TAG statement in the inner procedure attempts to implicitly commit the transaction that was started in the outer procedure:
To avoid this error, do not execute DDL statements (or other commands that implicitly commit transactions) inside a stored procedure that might be called from within an active transaction started in another scope.
Implicit ROLLBACK for transactions at the end of stored procedures¶
禁用 AUTOCOMMIT 时,在组合隐式事务和存储过程时要特别小心。如果在存储过程结束时意外地使事务处于活动状态,则该事务将回滚。
例如,以下伪代码示例会在存储过程结束时导致隐式 ROLLBACK:
在此示例中,设置 AUTOCOMMIT 的命令提交任何活动事务。新事务不会立即启动。存储过程包含一条 DML 语句,该语句隐式开始一个新事务。该隐式 BEGIN TRANSACTION 在存储过程中没有匹配的 COMMIT 或 ROLLBACK。由于存储过程末尾有一个活动事务,因此该活动事务会隐式回滚。
如果要在单个事务中运行整个存储过程,请在调用存储过程之前启动事务,并在调用后提交事务:
在这种情况下,BEGIN 和 COMMIT 正确配对,代码执行时不会出错。
或者,将 BEGIN TRANSACTION 和 COMMIT 都放在存储过程中,如下面的伪代码示例所示:
Improperly paired BEGIN/COMMIT blocks in scoped transactions¶
如果在范围内事务中没有正确配对 BEGIN/COMMIT 块,Snowflake 会报告错误。该错误可能会产生进一步的影响,例如阻止完成存储过程或阻止提交封闭事务。例如,在下面的伪代码示例中,将回滚封闭存储过程以及封闭的存储过程中的某些语句:
在此示例中,插入的唯一值是 osp1_alpha。因为 COMMIT 与 BEGIN 没有正确配对,所以没有插入任何其他值。错误处理方式如下:
当过程
inner_sp2()完成时,Snowflake 检测到inner_sp2()中的 BEGIN 没有相应的 COMMIT (或 ROLLBACK)。Snowflake 隐式回滚在
inner_sp2()中启动的范围内事务。Snowflake 还会返回错误,因为对
inner_sp2()的 CALL 失败。
因为对
inner_sp2()的 CALL 失败,并且因为该 CALL 语句在outer_sp1()中,所以存储过程outer_sp1()本身也失败并返回错误,而不是继续。因为
outer_sp1()没有完成执行:值
osp1_delta和osp1_omega的 INSERT 语句从不执行。outer_sp1()中的打开事务被隐式回滚而不是提交,因此值osp1_beta的插入永远不会提交。
Apache Iceberg™ 表和事务¶
Snowflake 事务原则通常适用于 Apache Iceberg™ 表。有关特定于 Iceberg 表的事务的更多信息,请参阅 :doc:` 关于事务的 Iceberg 主题 </user-guide/tables-iceberg-transactions>`。
READ COMMITTED 隔离级别¶
READ COMMITTED 是表当前支持的唯一隔离级别。使用 READ COMMITTED 隔离时,语句只能看到语句开始前提交的数据。它永远不会看到未提交的数据。
在多语句事务中执行语句时:
语句只能看到 语句 开始前提交的数据。如果在执行第一个和第二个语句之间提交了另一个事务,则同一事务中的两个连续语句可以看到不同的数据。
语句 确实 会看到同一事务 中 以前执行的语句所做的更改,即使这些更改尚未提交。
跨会话的读取一致性¶
一般来说,Snowflake 会保持 在任何给定会话中 发生的所有更改的读取一致性,例如由 DDL 和 DML 操作引入的更改。当用户启动新会话时,在会话启动之前提交的所有更改,以及会话中提交的所有更改,都对该会话中的后续查询立即可见。这是标准行为,满足大多数工作负载的要求。
如果您希望扩展读取一致性,以保证 跨会话 在近乎并发运行的查询中保持一致,并且可以接受查询响应时间(通常为毫秒级)的轻微延迟,请将 READ_CONSISTENCY_MODE 参数设置为 'GLOBAL'。通过设置此参数,您可以更改默认行为,使查询能够读取并发会话中发生的任何近乎同时的更改。保证此级别一致性的另一种方法是在同一会话中运行所有查询。
例如,使用默认值 'SESSION':
会话 1 开始。
会话 2 开始。
会话 1 在表
t中插入一行。会话 1 从表
t中查询数据,并立即看到新行。会话 2 执行相同查询。会话 2 可能看不到新行。
在此情况下,为确保会话 1 和会话 2 对同一查询获得相同结果,请按以下三种方式之一操作,顺序按推荐程度从高到低:
对所有相互依赖的查询使用同一会话。在这种情况下:
会话 1 开始。
会话 1 在表
t中插入一行。会话 1 从表
t中查询数据,并立即看到新行。
在会话 1 提交更改后再启动会话 2。在这种情况下:
会话 1 开始。
会话 1 在表
t中插入一行。会话 2 开始。
会话 1 从表
t中查询数据,并立即看到新行。会话 2 执行相同查询,可确保看到新行。
使用 ALTER ACCOUNT 命令将 READ_CONSISTENCY_MODE 设置为
'GLOBAL':此参数仅可由具有 ACCOUNTADMIN 权限的用户在账户级别进行设置。
资源锁定¶
事务操作在修改资源(如表)时获取该资源的锁。锁会阻止其他语句修改资源,直到释放锁。
以下准则适用于大多数情况:
COMMIT 操作(包括 AUTOCOMMIT 和显式 COMMIT)锁定资源,但通常只是短暂的。
当设置 CHANGE_TRACKING = TRUE 时,CREATE TABLE、CREATE DYNAMIC TABLE、CREATE STREAM 和 ALTER TABLE 操作都会锁定其底层资源,但通常只是短暂锁定。当表被锁定时,只有 UPDATE 和 DELETE DML 操作被阻止。INSERT 操作 未 被阻止。
UPDATE、DELETE 和 MERGE 语句持有锁,通常会阻止它们与其他 UPDATE、DELETE 和 MERGE 语句并行运行。
对于 混合表,锁定控制在单个行。锁定 UPDATE、DELETE 和 MERGE 语句只能阻止在同一行或多行上运行的并行 UPDATE、DELETE 和 MERGE 语句。UPDATE、DELETE 和 MERGE 可以在同一个表中的不同行上执行。
大多数 INSERT 和 COPY 语句只写入新分区。这些语句通常可以与其他 INSERT 和 COPY 操作并行运行,有时也可以与 UPDATE、DELETE 或 MERGE 语句并行运行。
避免在不同的会话中同时执行 INSERT 语句和 COPY 语句以及同一对象的 DDL 语句,因为这样做会导致不一致。当对 显式事务 中的对象执行 INSERT 或 COPY 语句时,在事务期间避免在不同会话中执行对同一对象的 DDL 语句。例如,不要在一个会话中对表运行 INSERT 语句,同时在不同的会话中运行更改表中列的数据类型的 DDL 语句。
COMMIT 或 ROLLBACK 事务时释放语句持有的锁。
锁定超时参数¶
两个参数可以控制锁定超时:LOCK_TIMEOUT 和 HYBRID_TABLE_LOCK_TIMEOUT。
LOCK_TIMEOUT 参数¶
被阻止的语句等待资源变得可用时,要么获取它正在等待的资源的锁,要么超时。您可以通过设置 LOCK_TIMEOUT 参数来设置语句应该阻止的时长(以秒为单位)。
例如,要将当前会话的锁超时更改为 2 小时(7200 秒):
HYBRID_TABLE_LOCK_TIMEOUT 参数¶
混合表上被阻止的语句在等待表可用时,要么在等待的表上获取行级锁定,要么超时。您可以通过设置 HYBRID_TABLE_LOCK_TIMEOUT 参数来设置语句应该阻止的时长(以秒为单位)。
例如,要将当前会话的混合表锁超时更改为 10 分钟(600 秒):
死锁¶
当并发事务正在等待彼此锁定的资源时,可能会发生死锁。
请注意以下规则:
并发执行自动提交查询语句时不会发生死锁。标准表和混合表都是如此,因为 SELECT 语句始终为只读。
标准表上自动提交 DML 操作时不会发生死锁,但混合表上自动提交 DML 操作时可能会发生死锁。
当显式启动事务并在每个事务中执行多个语句时,可能会发生死锁。Snowflake 检测死锁并选择作为死锁一部分的最新语句作为牺牲品。语句将回滚,但事务本身仍处于活动状态,必须提交或回滚。
死锁检测可能需要一些时间。
管理事务和锁定¶
Snowflake 提供以下 SQL 命令来帮助您监控和管理事务和锁定:
LOCK_WAIT_HISTORY 视图 记录了与锁定相关的事务的详细历史记录,显示了特定锁定的请求和获取时间。
此外,Snowflake 还提供以下上下文函数,用于获取有关会话中事务的信息:
您可以调用以下函数来中止事务:SYSTEM$ABORT_TRANSACTION。
中止事务¶
如果事务在会话中运行,并且会话突然断开连接,从而阻止事务提交或回滚,则事务将处于分离状态,包括事务在资源上保留的任何锁。如果发生这种情况,可能需要中止事务。
要中止正在运行的事务,启动事务的用户或账户管理员可以调用系统函数 SYSTEM$ABORT_TRANSACTION。
如果用户未中止事务:
它会阻止另一个事务获取同一表上的锁,并且 空闲 5 分钟,则会自动中止并回滚。
而且它 不 阻止其他事务修改同一表,并且超过 4 小时,则会自动中止并回滚。
它会读取或写入混合表,空闲 5 分钟,无论是否阻止其他事务修改同一个表,它都会自动中止并回滚。
要允许事务中的语句错误中止事务,请在会话或账户级别设置 TRANSACTION_ABORT_ON_ERROR 参数。
使用 LOCK_WAIT_HISTORY 视图分析被阻止的事务¶
LOCK_WAIT_HISTORY 视图 返回事务详细信息,这些信息对分析被阻止的事务非常有用。输出中的每一行都包含正在等待锁的事务的详细信息,以及持有该锁或正在等待该锁的事务的详细信息。
例如,请参阅以下方案:
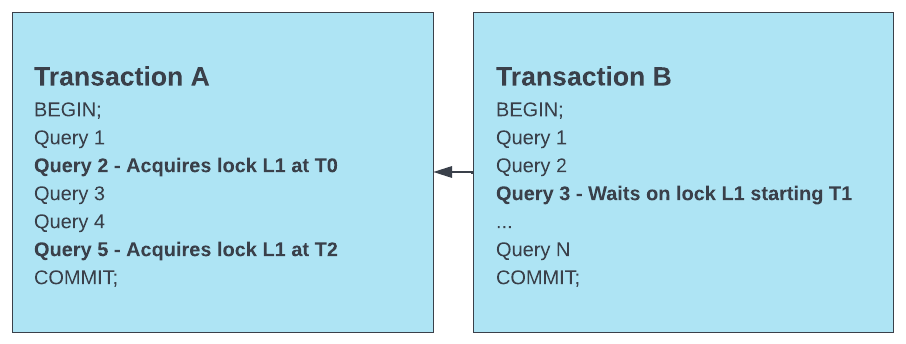
在此方案中,将返回以下数据:
事务 B 是等待锁的事务。
事务 B 在时间戳 T1 时请求锁。
事务 A 是持有锁的事务。
事务 A 中的查询 2 是阻止程序查询。
查询 2 是阻止程序查询,因为它是事务 A(持有锁的事务)中事务 B(等待锁的事务)开始等待的第一个语句。
但是,请注意,事务 A(查询 5)中的后续查询也获取了锁。这些事务的后续并发执行可能会导致事务 B 阻止获取事务 A 中锁的其他查询。因此,您必须调查第一个阻止程序事务中的所有查询。
另请参阅 混合表的事务和锁定可见性。
检查长时间运行的语句¶
在 Account Usage QUERY_HISTORY 视图 中查询过去 24 小时内等待锁的事务:
查看查询结果,并记下 TRANSACTION_BLOCKED_TIME 值较高的查询的查询 IDs。
要查找上一步中确定的查询的阻止程序事务,请在 LOCK_WAIT_HISTORY 视图中查询具有这些查询 IDs 的行:
结果中的
blocker_queries列可能有多个查询。注意输出中每个阻止程序查询的transaction_id。查询
blocker_queries输出中每个事务的 QUERY_HISTORY 视图:调查查询结果。如果事务中的某个语句是 DML 语句并在锁定的资源上操作,则该语句可能在事务期间的某个时间点获得了锁。
监控事务和锁定¶
您可以使用 SHOW TRANSACTIONS 命令返回当前用户(在该用户的所有会话中)或账户中所有会话中的所有用户正在运行的事务列表。以下示例适用于当前用户的会话。
每个 Snowflake 事务都分配有一个唯一的事务 ID。id 值是一个有符号的 64 位(长)整数。值的范围为 -9,223,372,036,854,775,808 (-2 63) 到 9,223,372,036,854,775,807 (2 63 - 1)。
您也可以使用 CURRENT_TRANSACTION 函数返回当前在会话中运行的事务的事务 ID。
如果您知道要监控的事务 ID,则可以在事务仍在运行时或提交或中止后使用 DESCRIBE TRANSACTION 命令返回有关该事务的详细信息。例如:
混合表的事务和锁定可见性¶
当您查看访问混合表或锁定混合表行的事务的命令和视图的输出时,请注意以下行为:
仅会列出阻止其他事务或被阻止的事物。
请记住,访问混合表的事务持有行级锁(
ROW类型)。如果两个事务访问同一个表中的不同行,则它们不会相互阻止。仅当被阻止的事务被阻止超过 5 秒时,才会列出事务。
某个事务不再被阻止时,可能仍会显示在输出中,但持续时间不超过 15 秒。
同样,在 SHOW LOCKS 输出中,以下规则适用:
仅当一个事务持有锁而另一个事务在该特定锁上被阻止时,才会列出锁。
在
type列中,混合表锁显示ROW。resource列始终显示阻止事务 ID。(被阻止的事务被使用此 ID 的事务阻止。)在许多情况下,针对混合表的查询不会生成查询 IDs。请参阅 使用说明。
例如:
在 LOCK_WAIT_HISTORY 视图 中,输出行为如下:
requested_at和acquired_at列定义何时请求和获取行级锁,但须遵守使用混合表报告事务活动的一般规则。lock_type和object_name列都显示值Row。schema_id和schema_name列始终为空(分别为0和 NULL)。object_id列始终显示阻止对象的 ID。blocker_queries列是一个仅包含一个元素的 JSON 数组,该元素显示了阻止事务。即使在同一行上阻止了多个事务,其在输出中也会显示为多行。
例如:
最佳实践¶
事务应包含相关的语句,并且应该同时成功或失败,例如,从一个账户中提取资金并将相同的资金存入另一个账户。如果发生回滚,付款人或收款人最终都会拿到钱;这笔钱永远不会“消失”(从一个账户中提取,但从未存入另一个账户)。
通常,一个事务应仅包含相关语句。使语句不那么精细意味着当事务回滚时,它可能会回滚实际上不需要回滚的有用工作。
在某些情况下,较大的事务可以提高标准表的性能,但通常不适用于混合表。
尽管前面的要点强调了仅将真正需要提交或回滚的语句分组为一组的重要性,但较大的事务有时可能很有用。在 Snowflake 中,与大多数数据库一样,管理事务会消耗资源。例如,在一个事务中插入 10 行通常比在 10 个单独的事务中各插入一行更快、更便宜。将多个语句合并到单个事务中可以提高性能。
过大的事务会降低并行性或增加死锁。如果您决定对不相关的语句进行分组以提高性能(如前一要点所述),请记住事务可以获取资源 锁,这可能会延迟其他查询或导致 死锁。
对于混合表:
一般而言,AUTOCOMMIT DML 语句的运行速度比非 AUTOCOMMIT DML 语句快得多。
相对较小的 AUTOCOMMIT DML 语句的运行速度比非 AUTOCOMMIT DML 语句快得多。运行时间不足 5 秒或访问的数据量不超过 1 MB 的 DML 语句会利用快速模式,运行时间较长或较大的 DML 语句不可用。
Snowflake 建议保持启用 AUTOCOMMIT 并尽可能使用显式事务。使用显式事务可以使人类读者更容易看到事务的开始和结束位置。这与 AUTOCOMMIT 相结合,使代码不太可能经历意外的回滚,例如在存储过程结束时。
避免仅仅为了隐式启动新事务而更改 AUTOCOMMIT。相反,使用 BEGIN TRANSACTION 可以使新事务的开始位置更加明显。
避免在一行中执行多个 BEGIN TRANSACTION 语句。额外的 BEGIN TRANSACTION 语句使得更难看到事务的实际开始位置,并且使得更难将 COMMIT/ROLLBACK 命令与相应的 BEGIN TRANSACTION 配对。
示例¶
范围内事务和存储过程的简单示例¶
这是范围内事务的简单示例。存储过程包含一个事务,该事务插入值为 12 的行,然后回滚。外部事务提交。输出显示保留外部事务范围内的所有行,而不保留内部事务范围内的行。
请注意,因为只有部分存储过程位于其自己的事务内,所以由存储过程内但不在存储过程事务内的 INSERT 语句插入的值将被保留。
创建两个表:
创建存储过程:
调用存储过程:
结果应包括 00、11、13 和 09。ID = 12 的行不应包含在内。此行位于已回滚的封闭的事务的范围内。所有其他行都在外部事务的范围内,并且已提交。请特别注意,IDs 为 11 和 13 的行位于存储过程内部,但在最内部的事务之外;它们在封闭事务的范围内,并通过该事务提交。
记录独立于事务成功的信息¶
这是如何使用范围内事务的简单实用示例。在此示例中,事务记录某些信息;无论事务本身是成功还是失败,都会保留该记录的信息。此技术可用于跟踪所有尝试的操作,无论每个操作是否成功。
创建两个表:
创建存储过程:
调用存储过程:
数据表为空,因为事务已回滚:
但是,日志记录表不为空;插入到日志记录表中是在与插入到 data_table 不同的事务中完成的。
范围内的事务和存储过程的示例¶
接下来的几个示例使用下面所示的表和存储过程。通过传递适当的参数,调用方可以控制 BEGIN TRANSACTION、COMMIT 和 ROLLBACK 语句在存储过程中的执行位置。
创建表:
此过程是封闭存储过程,根据传递给它的参数,可以创建封闭事务。
此过程是内部存储过程,根据传递给它的参数,可以创建封闭的事务。
提交三个级别的中间级别¶
此示例包含 3 个事务。此示例提交“中间”级别(由最外层事务括起来的事务,并包含最内层的事务)。这将回滚最外层和最内层的事务。
结果是只提交中间事务(12、21 和 23)中的行。外部事务和内部事务中的行未提交。
回滚三个级别的中间级别¶
此示例包含 3 个事务。此示例回滚“中间”级别(由最外层事务括起来的事务,并包含最内层的事务)。这将提交最外层和最内层的事务。
结果是,除中间事务中的行(12、21 和 23)之外的所有行都提交。
在存储过程中对事务使用错误处理¶
下面的代码演示存储过程中事务的简单错误处理。如果传递参数值“fail”,则存储过程会尝试从两个存在的表和一个不存在的表中删除,并且存储过程将捕获错误并返回错误消息。如果未传递参数值“fail”,则该过程将尝试从两个确实存在的表中删除,并成功。
创建表和存储过程:
调用存储过程并强制出错:
在不强制出错的情况下调用存储过程: