教程 3:使用 Cortex Search 构建 PDF 聊天机器人¶
简介
This tutorial describes how to build a chatbot from a dataset of PDF documents using Cortex Search. In Tutorial 2, you learned how to build a chatbot from text data that was already extracted from its source. This tutorial walks through an example of extracting that text from the PDFs using a basic Python UDF, then ingesting the extracted data into a Cortex Search Service.
您将学习以下内容
- 使用 Python UDF 从暂存区内的一组 PDF 文件中提取文本。
- 从提取的文本中创建 Cortex Search 服务。
- Create a Streamlit-in-Snowflake chat app that lets you ask questions about the data extracted from the PDF documents.
先决条件
要完成本教程,需要满足以下先决条件:
- You have a Snowflake account and user with a role that grants the necessary privileges to create a database, tables, virtual warehouse objects, Cortex Search Services, and Streamlit apps.
Refer to the Snowflake in 20 minutes for instructions to meet these requirements.
第 1 步:设置¶
获取 PDF 数据¶
您将使用联邦公开市场委员会 (FOMC) 会议记录的样本数据集。这是一个包含 12 份文件的样本,每份文件有 10 页,记录了 2023 年和 2024 年 FOMC 会议的会议记录。通过此链接直接从浏览器下载文件:
- FOMC minutes sample
The complete set of FOMC minutes can be found at the US Federal Reserve’s website (https://www.federalreserve.gov/monetarypolicy/fomccalendars.htm).
Note
在非教程设置中,您需要自带数据,这些数据可能已存储于 Snowflake 暂存区。
创建数据库、表和仓库
执行以下语句,创建本教程所需的数据库和虚拟仓库。完成本教程后,您可以删除这些对象。
Note
- The
CREATE DATABASEstatement creates a database. The database automatically includes a schema named PUBLIC. - The
CREATE WAREHOUSEstatement creates an initially suspended warehouse.
第 2 步:将数据加载到 Snowflake¶
首先创建一个 Snowflake 暂存区,用于存储包含数据的文件。此暂存区将保存会议记录 PDF 文件。
Note
配置目录和加密,用于生成文件的 presigned_url。如果不需要生成 presigned_url,可以跳过这些配置。
Now upload the dataset. You can upload the dataset in Snowsight or using SQL. To upload in Snowsight:
- Sign in to Snowsight.
- In the navigation menu, select Catalog » Database Explorer.
- Select your database
cortex_search_tutorial_db. - Select your schema
public. - Select Stages and select
fomc. - On the top right, Select the + Files button.
- Drag and drop files into the UI or select Browse to choose a file from the dialog window.
- Select Upload to upload your file.
第 3 步:解析 PDF 文件¶
在此步骤中,我们将从 PDFs 中提取原始文本,然后将其拆分为多个块,以供引入到搜索服务中。
First, we will use the Parsing documents with AI_PARSE_DOCUMENT function to extract the text and layout
information from the PDFs into a new table, RAW_TEXT.
Then, we will use SPLIT_TEXT_MARKDOWN_HEADER to
split the documents up into chunks of maximum size 2000 characters each, using the top two markdown header levels as chunk boundaries.
We’ll insert the chunks into a new table DOC_CHUNKS.
第 4 步:创建搜索服务¶
运行以下 SQL 命令,在新表上创建搜索服务:
This command specifies the attributes, which are the columns that you’ll be able to filter search results on, as well as the
warehouse and target lag. The search column is designated as chunk, which is generated in the source query as a
concatenation of several text columns in the base table. The other columns in the source query can be included in response to a search request.
第 5 步:创建一个 Streamlit 应用程序¶
You can query the service with Python SDK (using the snowflake Python package). This tutorial
demonstrates using the Python SDK in a Streamlit in Snowflake application.
First, ensure your global Snowsight UI role is the same as the role used to create the service in the service creation step.
- Sign in to Snowsight.
- In the navigation menu, select Projects » Streamlit.
- Select + Streamlit App.
- Important: Select the
cortex_search_tutorial_dbdatabase and thepublicschema for the app location. - In the left pane of the Streamlit in Snowflake editor, select Packages and add
snowflake(version >= 0.8.0) andsnowflake-ml-pythonto install the required packages in your application. - 用以下 Streamlit 应用程序替换示例应用程序代码:
第 6 步:试用应用程序¶
In the right pane of the Streamlit in Snowflake editor window, you’ll see a preview of your Streamlit app. It should look similar to the following screenshot:
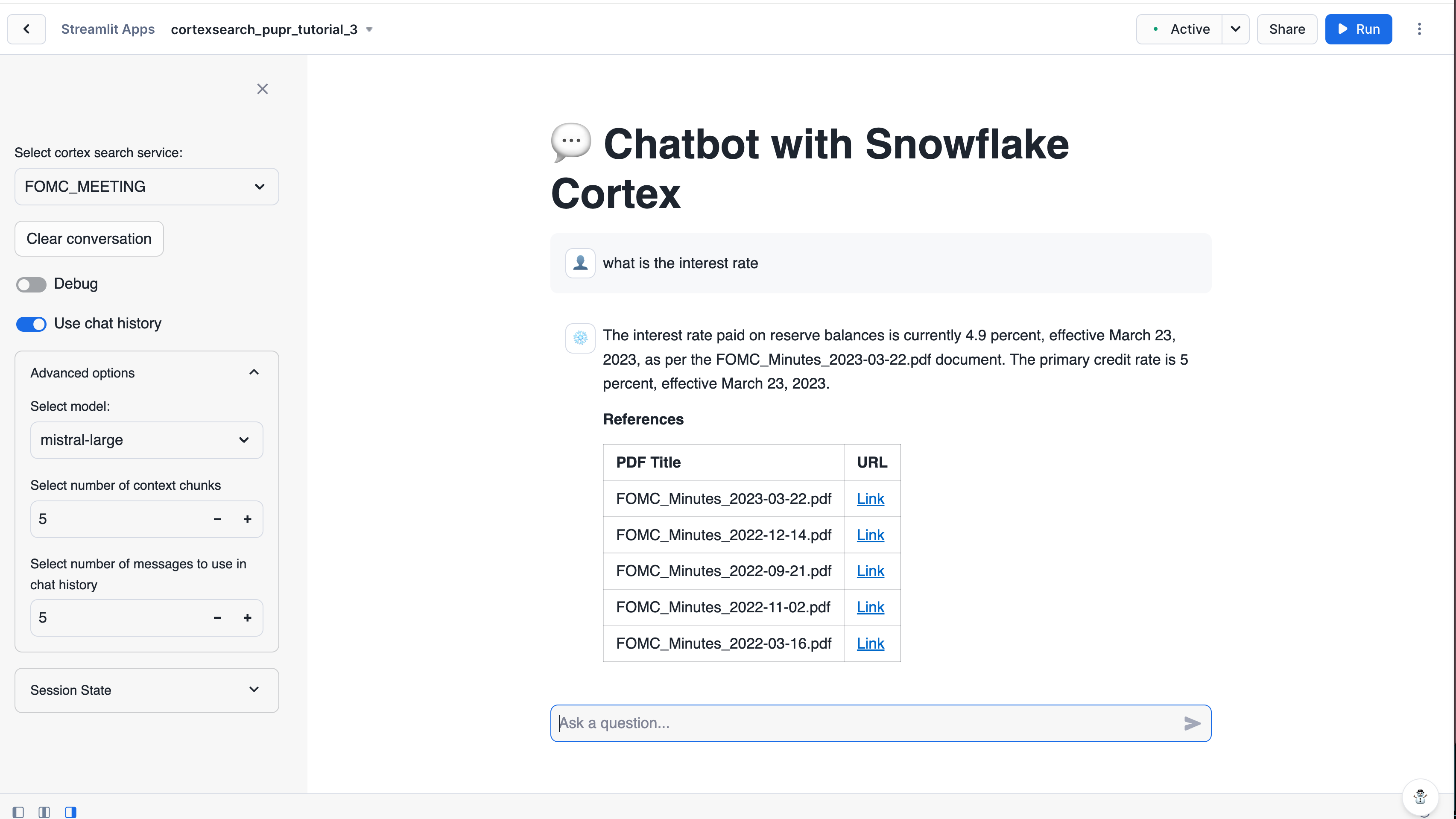
在文本框中输入查询,试用新应用程序。您可尝试的一些示例查询如下:
-
- Example session 1: multi-turn question-answering
How was gpd growth in q4 23?How was unemployment in the same quarter?
-
- Example session 2: summarizing multiple documents
How has the fed's view of the market change over the course of 2024?
-
- Example session 3: abstaining when the documents don’t contain the right answer
What was janet yellen's opinion about 2024 q1?
第 7 步:清理¶
清理(可选)
Execute the following DROP <object> commands to return your system to its state before you began the tutorial:
删除数据库会自动移除所有子数据库对象,例如表。
后续步骤
恭喜!您已成功在 Snowflake 中通过一组 PDF 文件构建了一个搜索应用程序。
其他资源
您可以利用以下资源继续学习: