教程 1:使用 Cortex Search 构建简单的搜索应用程序¶
简介
本教程介绍如何开始使用 Cortex Search 创建一个简单的搜索应用程序。
您将学习以下内容
- 在 AirBnb 列表数据集上创建 Cortex Search 服务。
- Create a Streamlit in Snowflake app that lets you query your Cortex Search Service.
先决条件
要完成本教程,需要满足以下先决条件:
- You have a Snowflake account and user with a role that grants the necessary privileges to create a database, tables, virtual warehouse objects, Cortex Search services, and Streamlit apps.
Refer to the Snowflake in 20 minutes for instructions to meet these requirements.
第 1 步:设置¶
获取样本数据
You will use a sample dataset hosted on Huggingface , downloaded as a single JSON file. Download the file directly from your browser by following this link:
- AirBnB listings dataset
Note
在非教程设置中,您将自带数据,这些数据可能已经存在于 Snowflake 表中。
创建数据库、表和仓库
执行以下语句,创建本教程所需的数据库和虚拟仓库。完成本教程后,您可以删除这些对象。
请注意以下事项:
- The
CREATE DATABASEstatement creates a database. The database automatically includes a schema named ‘public’. - The
CREATE WAREHOUSEstatement creates an initially suspended warehouse. The statement also setsAUTO_RESUME = true, which starts the warehouse automatically when you execute SQL statements that require compute resources.
第 2 步:将数据加载到 Snowflake¶
在创建搜索服务之前,必须将示例数据加载到 Snowflake 中。
You can upload the dataset in Snowsight or using SQL. To upload in Snowsight:
-
Select the + Create button above the left navigation bar.
-
Then select Table » From File.
-
从右上角的下拉列表中选择新创建的仓库作为表格仓库。
-
将 JSON 数据文件拖放到对话框中。
-
选择上面创建的数据库,并指定 PUBLIC 架构。
-
Finally, specify the creation of a new table called
airbnb_listingsand select Next.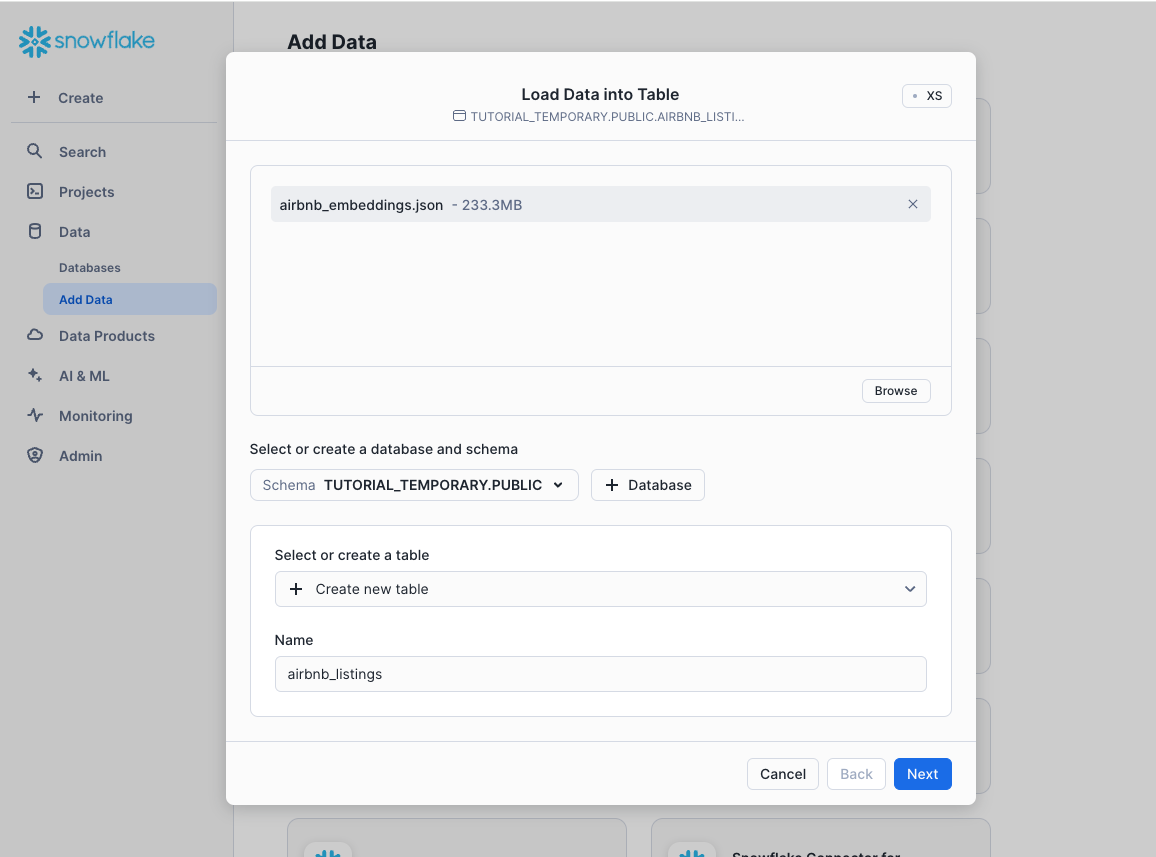
-
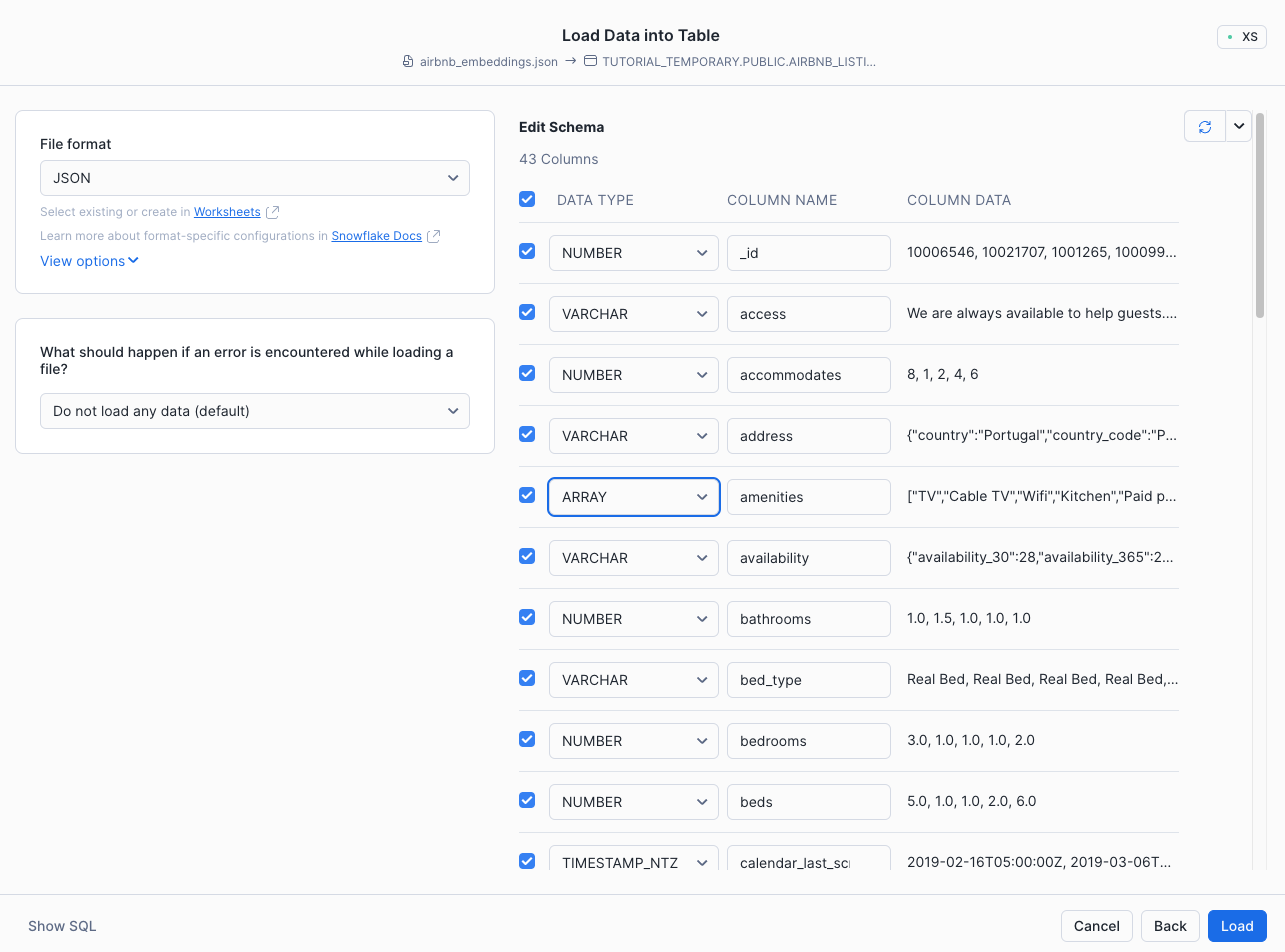
In the Load Data into Table dialog, make the following adjustments. First, uncheck the
image_embeddings,images, andtext_embeddingscolumns, since those do not apply to this tutorial. Second, adjust the datatype of theamenitiesfield to be ARRAY type.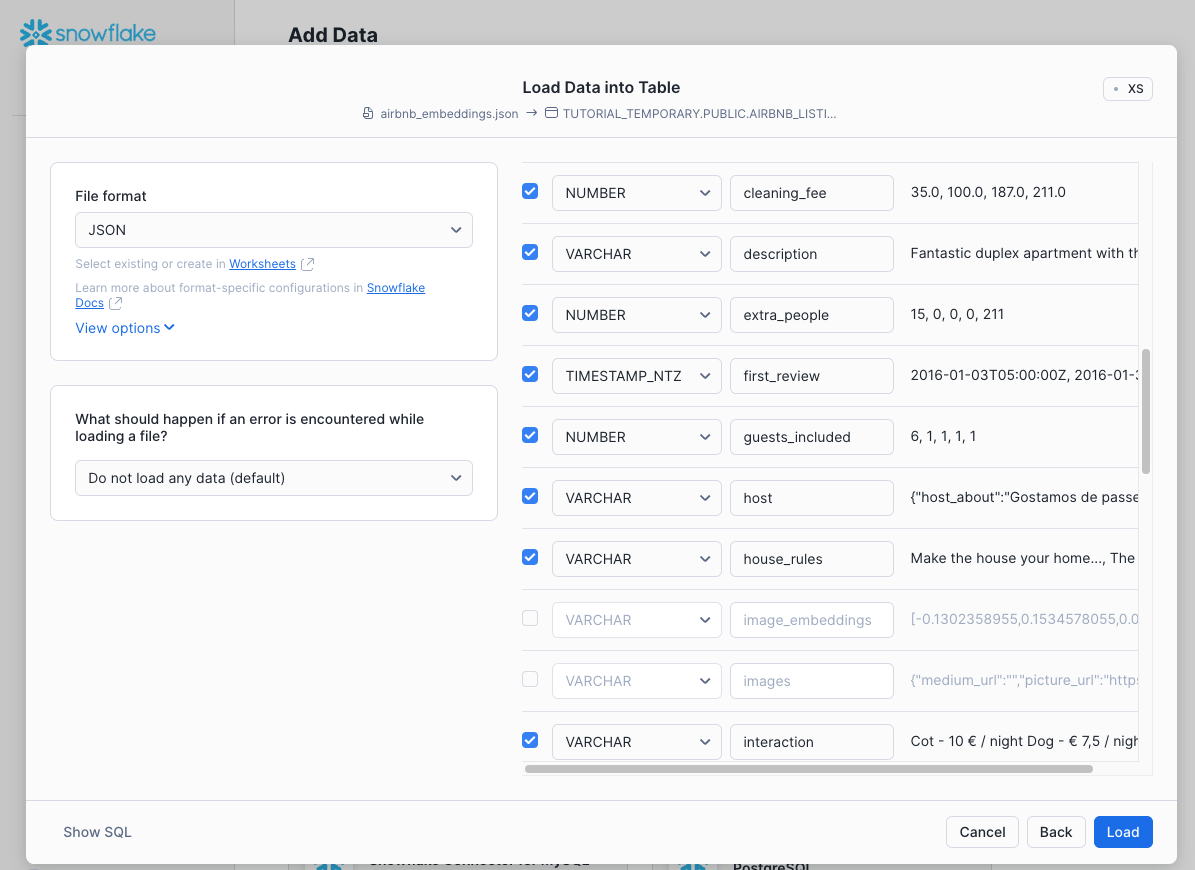
-
Once you have made these adjustments, Select Load to proceed.
-
片刻之后,即会看到一个确认页面,显示数据已加载。
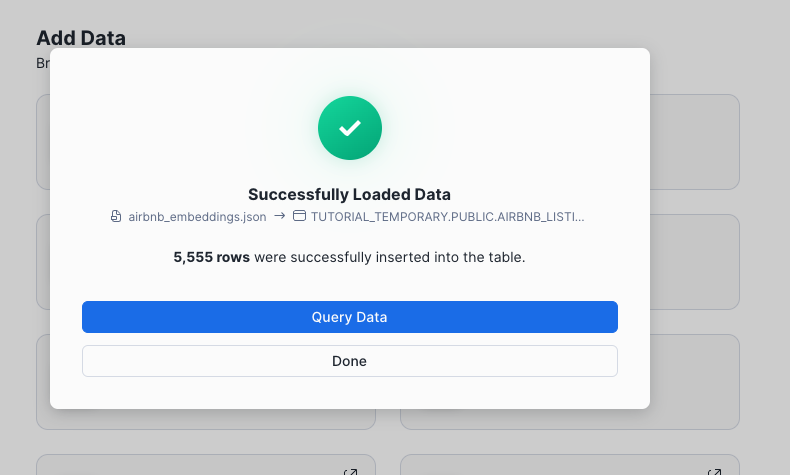
-
Select Query Data to open up a new Snowsight worksheet that you will use in the next step.
第 3 步:创建搜索服务¶
运行以下 SQL 命令,在新表上创建搜索服务。
- Let’s break down the arguments in this command:
- The
ONparameter specifies the column for queries to search over. In this case, it’s thelisting_text, which is generated in the source query as a concatenation of several text columns in the base table. - The
ATTRIBUTESparameter specifies the columns that you will be able to filter search results on. This example filers onroom_typeandamenitieswhen issuing queries to thelisting_textcolumn. - The
WAREHOUSEandTARGET_LAGparameters specify the user-provided warehouse and the desired freshness of the search service, respectively. This example specifies to use thecortex_search_tutorial_whwarehouse to create the index and perform refreshes, and to keep the service no more than'1 hour'behind the source tableAIRBNB_LISTINGS. - The
ASfield defines the source table for the service. This example concatenates several text columns in the original table into the search columnlisting_textso that queries can search over multiple fields.
- The
第 4 步:创建 Streamlit 应用程序¶
You can query the service with Python SDK (using the snowflake Python package). This tutorial
demonstrates using the Python SDK in a Streamlit in Snowflake application.
First, ensure your global Snowsight UI role is the same as the role used to create the service in the service creation step.
- Sign in to Snowsight.
- In the navigation menu, select Projects » Streamlit.
- Select + Streamlit App.
- Important: Select the
cortex_search_tutorial_dbdatabase andpublicschema for the app location. - In the left pane of the Streamlit in Snowflake editor, select Packages and add
snowflake(version >= 0.8.0) to install the package in your application. - 用以下 Streamlit 应用程序替换示例应用程序代码:
下面简要介绍上述 Streamlit-in-Snowflake 代码中的主要组成部分:
get_column_specificationuses a DESCRIBE SQL query to get information about the attributes available in the search service and stores them in Streamlit state.init_layoutsets up the header and intro of the page.query_cortex_search_servicehandles querying the Cortex Search Service via the Python client library.create_filter_objectprocesses selected filter attributes from the Streamlit form into the right objects to be used by the Python library for querying Cortex Search.distinct_values_for_attributedetermines which values are possible for each filterable attribute to populate the dropdown menus.init_search_input,init_limit_input,init_attribute_selectioninitialize inputs for the search query, limit of number of results, and attribute filters.display_search_resultsformats search results into Markdown elements displayed in the results page.
第 5 步:清理¶
清理(可选)
Execute the following DROP <object> commands to return your system to its state before you began the tutorial:
删除数据库会自动移除所有子数据库对象,例如表。
后续步骤
Congratulations! You have successfully built a simple search app on text data in Snowflake. You can move on to Tutorial 2 to see how to layer on Cortex LLM Functions to build an AI chatbot with Cortex Search.
其他资源
此外,您还可以利用以下资源继续学习: