Python 用户定义的聚合函数¶
用户定义的聚合函数 (UDAFs) 一行或多行作为输入并生成单行输出。它们对多行的值进行运算,以执行数学计算,例如总和、平均值、计数、求最小值或最大值、标准偏差和估计,以及一些非数学运算。
Python UDAFs 为您提供了一种编写自己的聚合函数的方法,这些聚合函数与 Snowflake 系统定义的 SQL 聚合函数 类似。
您也可以使用 Snowpark APIs 创建自己的 UDAFs,如 在 Python 中为 DataFrames 创建用户定义的聚合函数 (UDAFs) 中所述。
限制¶
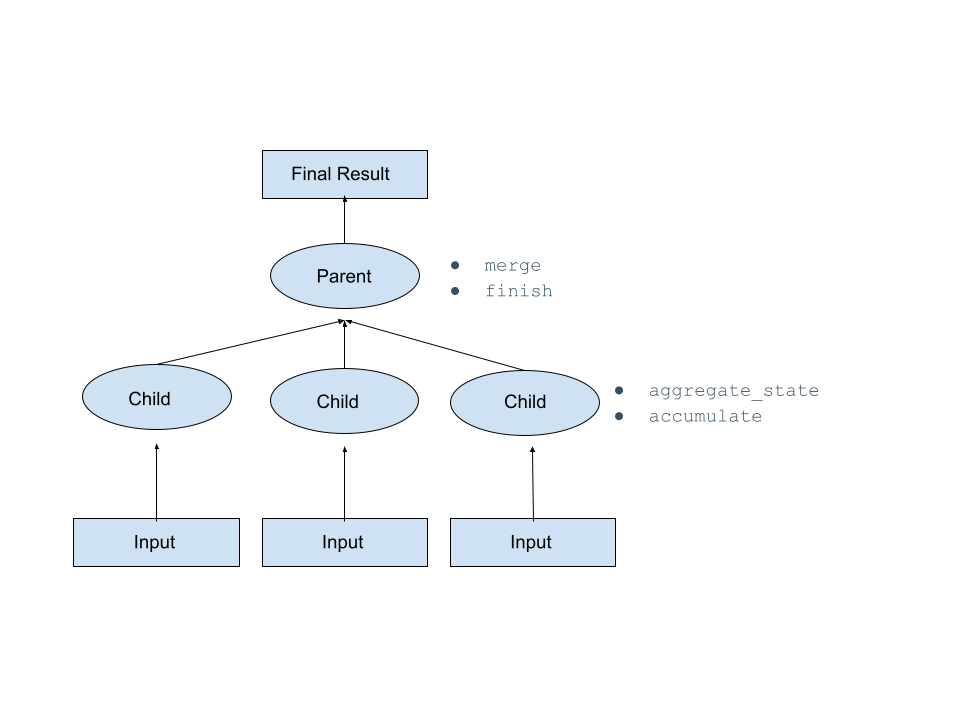
aggregate_state在序列化版本中的最大大小为 64 MB,因此请尝试控制汇总状态的大小。不能将 UDAF 作为 窗口函数 调用(换句话说,使用 OVER 子句)。
IMMUTABLE 不支持聚合函数(使用 AGGREGATE 参数时)。因此,所有聚合函数默认都是 VOLATILE。
用户定义的聚合函数无法与 WITHIN GROUP 子句一起使用。查询将无法执行。
聚合函数处理程序的接口¶
聚合函数汇总子节点中的状态,然后最终将这些汇总状态序列化并发送到父节点,在那里对它们进行合并以及计算最终结果。
要定义聚合函数,您必须定义一个 Python 类(即函数的处理程序),其中包含 Snowflake 在运行时调用的方法。下表介绍了这些方法。请参阅本主题的其他部分示例。
方法 |
要求 |
描述 |
|---|---|---|
|
必填 |
将汇总的内部状态初始化。 |
|
必填 |
返回汇总的当前状态。
|
|
必填 |
根据新的输入行累积汇总的状态。 |
|
必填 |
结合两个中间汇总状态。 |
|
必填 |
根据汇总状态生成最终结果。 |
示例:计算总和¶
以下示例中的代码定义了 python_sum 用户定义的聚合函数 (UDAF) 以返回数值的总和。
创建 UDAF。
创建测试数据表。
调用
python_sumUDAF。将结果与 Snowflake 系统定义的 SQL 函数 SUM 进行比较,并看到结果是相同的。
根据销售表中的商品类型对销售额进行分组。
示例:计算平均值¶
以下示例中的代码定义了 python_avg 用户定义的聚合函数以返回数值的总和。
创建函数。
创建测试数据表。
调用
python_avg用户定义的函数。将结果与 Snowflake 系统定义的 SQL 函数 AVG 进行比较,并看到结果是相同的。
在销售表中按商品类型对平均值进行分组。
示例:仅返回唯一值¶
以下示例中的代码采用一个数组,并返回一个仅包含唯一值的数组。
示例:返回字符串计数¶
以下示例中的代码返回一个对象中所有字符串实例的计数。
示例:返回前 k 个最大值¶
以下示例中的代码返回 k 的前几个最大值的列表。此代码在最小堆上累积否定的输入值,然后返回前几个 k 最大值。