使用 Snowpark Scala 时分析查询和排除故障¶
本主题提供了一些有关在使用 Snowpark 库时分析查询和故障排除的指引。
在 Snowpark 中查看查询的执行计划¶
要检查 DataFrame 的计算计划,请调用 DataFrame 的 explain 方法。此方法会打印用于计算 DataFrame 的 SQL 语句。如果只有一个 SQL 语句,此方法还会打印该语句的逻辑计划。
After the execution of a DataFrame has been triggered, you can check on the progress of the query in the Query History page in Snowsight.
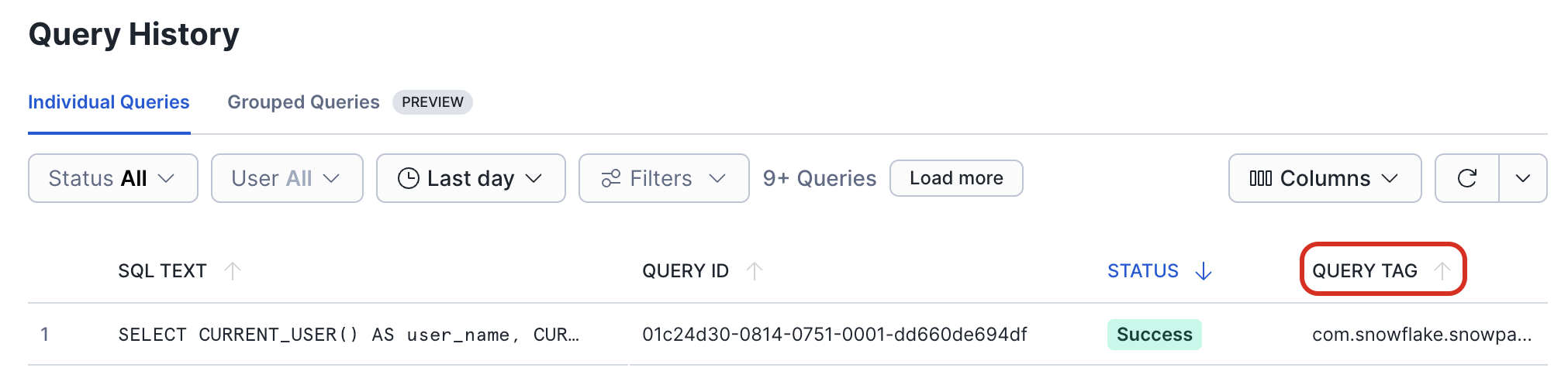
在 Query Tag 列中,可以在触发此查询的代码中找到函数名称和行号。
故障排除¶
更改日志记录设置¶
默认情况下,Snowpark 库会将 INFO 级别的消息记录到标准输出。若要更改日志记录设置,请创建一个 simplelogger.properties 文件,并在该文件中配置记录器属性。例如,将日志级别设置为 DEBUG:
将此文件放在类路径中。如果您使用的是 Maven 目录布局,请将此文件放在 src/main/resources/ 目录中。
java.lang. OutOfMemoryError 异常¶
如果引发 java.lang.OutOfMemoryError 异常,请为 JVM 增加最大堆大小。
如果您使用的是 Scala REPL,并且需要增加最大堆大小,请编辑 run.sh shell 脚本(在归档文件中提供),并将 -J-Xmxmaximum_size 标志添加到 scala 命令中。以下示例将最大堆大小增加到 4 GB: