Snowpark Container Services:使用服务¶
Snowpark Container Services 使您能够轻松部署、管理和扩展容器化应用程序。创建应用程序并将应用程序映像上传到 Snowflake 账户中的存储库后,您就可以将应用程序容器作为服务运行。
服务表示 Snowflake 在 计算池 上运行您的容器化应用程序,计算池是虚拟机 (VM) 节点的集合。服务分为两类:
长期运行的服务。 长期运行的服务就像不会自动结束的 Web 服务。创建服务后,Snowflake 会管理正在运行的服务。例如,如果某个服务容器出于某种原因停止,Snowflake 会重新启动该容器,以便服务不间断地运行。
作业服务。 作业服务会在代码退出时终止,与存储过程类似。当所有容器都退出时,作业服务便已完成。
下图显示了服务的架构:
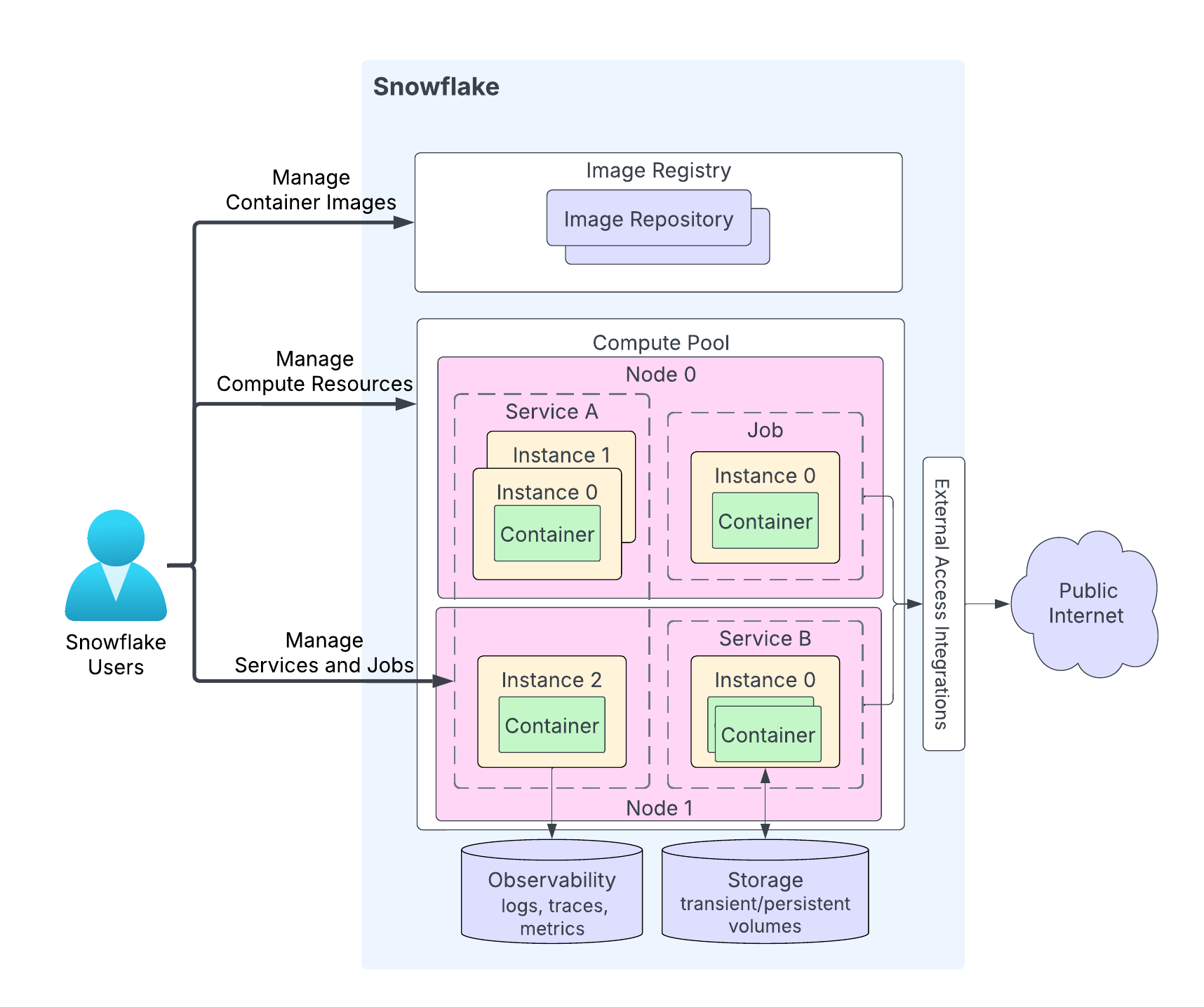
该图表的亮点如下:
用户将他们的应用程序代码上传到其 Snowflake 账户中的仓库。镜像注册表服务提供 OCIv2 API,用于在仓库中存储兼容 OCI 的镜像。例如,您可以使用 Docker API 将镜像上传到仓库。创建服务时,您需要指定要使用的镜像。
计算池是 Snowflake 运行您的服务的地方。该图表显示了一个具有两个计算节点(节点 0 和节点 1)的计算池。Snowflake 在节点上运行您的服务实例。运行多个服务实例时,根据资源需求,Snowflake 可能会在同一个节点上运行它们,也可能将它们分布在多个节点上。例如:
节点 0 正在运行服务 A(该服务总的三个实例中的两个实例)和一个作业(包含一个实例)。
节点 1 正在运行服务 A 的第三个实例。该节点还运行服务 B 的一个实例。
根据您的应用程序代码,服务实例可以由多个容器组成。虽然 Snowflake 可能会在多个计算池节点上分配一项服务的多个实例,但单个服务实例中的所有容器始终在同一个计算池节点上运行。
服务可以选择与公共互联网通信。
服务可以使用包括瞬态存储(例如,内存和本地磁盘)和永久卷(例如,块卷)在内的存储。
Snowflake 可以将服务中的日志、跟踪和指标记录到 Snowflake 账户中的事件表。
Snowflake 提供 APIs,以便您创建和管理仓库、计算池和服务。本主题介绍如何使用服务。用于管理服务的 APIs 包括以下内容:
SQL 命令:
更改服务。 ALTER SERVICE、DROP SERVICE。
获取有关服务的信息。 SHOW SERVICES、DESCRIBE SERVICE 和 其他命令。
非 SQL 接口: Snowflake Python APIs、Snowflake REST APIs 和 Snowflake CLI。
启动服务¶
将应用程序代码上传到 Snowflake 账户中的 仓库 后,即可启动服务。启动服务所需的最低限度信息包括:
创建长期服务¶
使用 CREATE SERVICE 创建长期运行的服务。
在大多数情况下,您可以通过指定内联规范来创建服务,如下所示:
通过引用 Snowflake 暂存区上存储的服务规范来创建服务。在生产环境中部署服务时,您可以应用关注点分离设计原则,并将规范上传到一个暂存区,在 CREATE SERVICE 命令中提供暂存区信息,如下所示:
运行作业服务¶
使用 EXECUTE JOB SERVICE 创建作业服务。默认情况下,此命令同步运行,并在任务服务的所有容器退出后返回响应。您可以选择指定 ASYNC 参数以异步运行作业服务。
Execute a job service using an inline specification. The command waits until the job finishes executing:
您可以选择使用该
ASYNC属性异步执行此作业。When you execute an asynchronous job, you can use the helper function <service_name>!SPCS_WAIT_FOR to wait for the job to complete.
使用暂存区信息执行作业服务:
运行作业服务的多个副本(批处理作业)¶
默认情况下,EXECUTE JOB SERVICE 在计算池上运行单个作业服务实例来执行作业。但是,您可以选择运行多个作业服务副本,以在计算池节点之间分配工作负载。例如,您可以使用 10 个副本来处理一个 1000 万行的数据集,每个副本处理 100 万行。
批处理作业支持这样的场景:可以将工作分成独立的任务,每个作业服务实例(也称为副本)一个,这些任务可以并行执行。Snowflake 能否并行执行实例取决于计算池的大小。
要使用多个实例执行批处理作业,请使用的可选的 REPLICAS 参数 EXECUTE JOBSERVICE,如下所示。以下示例使用 10 个实例执行作业服务:
在 EXECUTE JOB SERVICE 中指定 REPLICAS 参数后,Snowflake 会在作业容器中填充以下两个环境变量:
SNOWFLAKE_JOBS_COUNT:EXECUTE JOB SERVICE 上指定的 REPLICAS 属性的值。SNOWFLAKE_JOB_INDEX:作业服务实例的 ID,从 0 开始。如果您有三个副本,则实例 IDs 将为 0、1 和 2。
提供这些环境变量是为了使作业容器可以使用它们对输入进行分区,并为每个实例分配一个特定的分区来进行处理。例如,当使用 10 个作业副本来处理 1000 万行时,作业索引为 0 的实例将处理 1 到 100 万行,作业索引为 1 的实例将处理 100 万到 200 万的行,依此类推。
使用 SHOW SERVICE INSTANCES IN SERVICE 命令查找每个作业服务实例的状态。
使用 DESCRIBE SERVICE 命令获取整体作业服务状态。Snowflake 按如下方式计算整体作业服务状态:
如果任何实例失败,则作业状态为 FAILED。
如果所有实例都成功完成,则作业状态为 DONE。
如果当前有任何实例正在运行,则作业状态为 RUNNING。
否则,作业状态为 PENDING。
使用规范模板¶
有时,您可能希望使用相同的规范创建多项服务,但采用不同的配置。例如,假设您以一种服务规范定义了一个 环境变量,并且您希望使用相同的规范创建多项服务,但环境变量的值不同。
借助规范模板,您可以为规范中的字段值定义变量。在创建服务时,您需要为这些变量提供值。
在规范模板中,您可以将变量指定为各种规范字段的值。使用 {{ variable_name }} 语法来指定这些变量。然后,在 CREATE SERVICE 命令中,指定 USING 参数来设置这些变量的值。
例如,以下 CREATE SERVICE 命令中的内联规范模板为镜像标签名称使用名为 tag_name 的变量。您可以使用此变量为每项服务指定不同的镜像标签。在此示例中,USING 参数将 tag_name 变量设置为值 latest。
如果您选择将规范模板保存到账户中的 Snowflake 暂存区,您可以在 CREATE SERVICE 命令中指向模板的位置:
在规范中定义变量的准则¶
使用
{{ variable_name }}语法将变量定义为规范中的字段值。这些变量可以具有默认值。要指定默认值,请在变量声明中使用
default函数。例如,以下规范定义具有默认值的两个变量(character_name和endpoint_name)。此外,您还可以为
default函数指定可选布尔参数,以指示是否要在为变量传递空白值时使用默认值。请考虑以下规范:在规范中:
对于
character_name变量,布尔参数设置为false。因此,如果变量设置为此参数的空字符串值 (''),则该值将保留空值;不使用默认值(“Bob”)。对于
echo_endpoint变量,布尔参数设置为true。因此,如果向此参数传递空值,则使用默认值(“echo-endpoint”)。
默认情况下,
default函数的布尔参数为false。
为规范变量传递值的准则¶
在 CREATE SERVICE 命令中指定 USING 参数,为变量提供值。USING 的一般语法是:
其中
var_name区分大小写,并且应该是有效的 Snowflake 标识符(请参阅 标识符要求)。var_value可以是字母数字值或有效 JSON 值。示例:
CREATE SERVICE 中的 USING 参数必须为规范变量提供值(规范为其提供默认值的变量除外)。否则,返回错误。
示例¶
以下示例显示如何使用规范模板创建服务。这些示例中的 CREATE SERVICE 命令使用内联规范。
示例 1:提供简单值¶
在 教程 1 中,您可以通过提供内联规范来创建服务。以下示例是该示例的修改版本,其中规范定义了两个变量:image_url 和 SERVER_PORT。请注意,SERVER_PORT 变量在三个地方重复使用。这样可以实现使用变量的额外优势,即确保所有这些字段像预期一样具有相同的值。
在此 CREATE SERVICE 命令中,USING 参数为两个规范变量提供值。image_url 值包括斜杠和冒号。这些不是字母数字字符。因此,该示例将值引在双引号中,使其成为有效的 JSON 字符串值。模板规范扩展了以下规范:
示例 2:提供 JSON 值¶
在教程 1 中,规范定义了两个环境变量(SERVER_PORT 和 CHARACTER_NAME),如下所示:
您可以为 env 字段使用变量,以此模板化此规范。这允许您创建多项服务,为环境变量使用不同的值。以下 CREATE SERVICE 命令为 env 字段使用变量 (env_values)。
CREATE SERVICE 中的 USING 参数为 env_values 变量提供值。该值是 JSON 映射,为两个环境变量提供值。
示例 3:提供列表作为变量值¶
在 教程 2 中,该规范包括 args 字段,其中包含两个实参。
在规范的模板版本中,您可以以 JSON 列表的形式提供这些实参,如下所示:
扩展服务¶
默认情况下,Snowflake 会在指定的计算池中运行一个服务实例。要管理繁重的工作负载,您可以通过设置 MIN_INSTANCES 和 MAX_INSTANCES 属性运行多个服务实例,这两个属性指定了服务启动时的最小实例数和需要时 Snowflake 可扩展到的最大实例数。
示例
当多个服务实例正在运行时,Snowflake 会自动提供一个负载均衡器来分配传入请求。
Snowflake 不会将服务视为 READY,直到至少有两个实例可用。当服务尚未准备就绪时,Snowflake 会阻止对它的访问,这意味着在确认准备就绪之前,关联的服务函数或入口请求会遭据。
在某些情况下,您可能希望 Snowflake 将服务视为就绪(并转发传入请求),即使可用的实例数少于指定的最小实例数也是如此。您可以通过设置 MIN_READY_INSTANCES 属性来实现此目标。
考虑以下情况:在维护或滚动服务升级期间,Snowflake 可能会终止一个或多个服务实例。这可能会导致可用实例少于指定的 MIN_INSTANCES,从而阻止服务进入 READY 状态。在这些情况下,您可以将 MIN_READY_INSTANCES 设置为小于 MIN_INSTANCES 的值,以确保服务可以继续接受请求。
示例
有关更多信息,请参阅 CREATE SERVICE。
启用自动扩缩¶
To configure Snowflake to autoscale the number of service instances running, set the MIN_INSTANCES and MAX_INSTANCES parameters in the CREATE SERVICE command. You can also use ALTER SERVICE to change these values. Autoscaling occurs when the specified MAX_INSTANCES is greater than MIN_INSTANCES.
Snowflake starts by creating the minimum number of service instances on the specified compute pool. Snowflake then scales up or scales down the number of service instances based on an 80% CPU resource requests. Snowflake continuously monitors CPU utilization within the compute pool, aggregating the usage data from all currently running service instances.
When the aggregated CPU usage (across all service instances) surpasses 80%, Snowflake deploys an additional service instance within the compute pool. If the aggregated CPU usage falls below 80%, Snowflake scales down by removing a running service instance. Snowflake uses a five-minute stabilization window to prevent frequent scaling. The target_instances service property reports the target number of service instances that Snowflake is scaling towards.
请注意以下扩缩行为:
服务实例的扩缩受限于为服务配置的 MIN_INSTANCES 和 MAX_INSTANCES 参数。
如果需要扩大规模,而计算池节点缺乏启动另一个服务实例所需的资源能力,则可以触发计算池自动扩缩。有关更多信息,请参阅 计算池节点的自动扩缩。
如果您在创建服务时指定 MAX_INSTANCES 和 MIN_INSTANCES 参数,但没有在服务规范文件中为服务实例指定 CPU 和内存要求,则不会发生自动扩缩;Snowflake 会以 MIN_INSTANCES 属性指定的实例数启动,不会自动扩缩。
暂停服务¶
长期运行的服务会消耗计算池资源并产生成本,但您可以在服务不执行有意义的工作时将其暂停。当任何计算池节点上没有服务或作业处于活动状态时,Snowflake 的计算池自动暂停机制会暂停计算池,以降低成本。
要暂停服务,您可以明确调用 :doc:` ALTER SERVICE ...SUSPEND </sql-reference/sql/alter-service>` 以暂停服务或使用 CREATE SERVICE 或 ALTER SERVICE 设置 AUTO_SUSPEND_SECS 属性来定义空闲时长,在此之后 Snowflake 将自动暂停服务。
设置 AUTO_SUSPEND_SECS 属性后,如果服务尚未暂停且空闲时间超过 AUTO_SUSPEND_SECS 秒钟,Snowflake 会自动暂停该服务。当满足以下两个条件时,服务处于空闲状态:
当前没有正在运行的查询包含对该服务的 服务函数 调用。
服务状态为 RUNNING。
小心
自动暂停功能不会追踪由服务函数调用发起的数据处理(即使该处理在服务函数返回后仍持续运行)。在当前的实现中,自动暂停也不跟踪入口和服务间通信。因此,对于提供此类功能的服务,您不应启用自动暂停功能,因为这可能会干扰这些可能仍在进行的处理流程。
当 Snowflake 暂停服务时,它会关闭计算池上的所有服务实例。如果计算池上没有运行其他服务,且为该计算池配置了自动暂停功能,则 Snowflake 也会暂停该计算池节点。因此,您无需为非活动计算池付费。
同时请注意以下事项:
作业服务不支持自动暂停。
对于具有公共端点的服务,系统不支持自动暂停功能,因为 Snowflake 目前仅通过服务函数流量(而非入口流量)来判断服务是否处于空闲状态。
修改和删除服务¶
创建服务或作业服务后,您可以执行以下操作:
使用 DROP SERVICE 命令从架构中移除服务,Snowflake 终止所有服务容器。
调用 <service_name>!SPCS_CANCEL_JOB 函数以取消作业服务。当您取消作业时,Snowflake 会停止该作业的运行并移除为该作业运行分配的资源。
使用 ALTER SERVICE 命令修改服务,例如,暂停或恢复服务、更改正在运行的实例数,以及使用新的服务规范指示 Snowflake 重新部署服务。
备注
您不能更改作业服务。
终止服务¶
当您暂停服务 (ALTER SERVICE ...SUSPEND) 或放弃服务 (DROP SERVICE) 时,Snowflake 会终止所有服务实例。同样,当您升级服务代码 (ALTER SERVICE...<fromSpecification>) 时,Snowflake 会通过每次终止和重新部署一个服务实例来应用 滚动升级。
在终止服务实例时,Snowflake 会首先将 SIGTERM 信号发送到每个服务容器。容器可以选择处理信号并在 30 秒的窗口内正常关闭。否则,宽限期过后,Snowflake 会终止容器中的所有进程。
更新服务代码并重新部署服务¶
创建服务后,使用 ALTER SERVICE … <fromSpecification> 命令更新服务代码并重新部署服务。
您首先将修改后的应用程序代码上传到您的镜像仓库。然后,您可以执行 ALTER SERVICE 命令,要么提供内联服务规范,要么在 Snowflake 暂存区指定规范文件的路径。例如:
收到请求后,Snowflake 会使用新代码重新部署服务。
备注
当您运行 CREATE SERVICE ... <fromSpecification> 命令时,Snowflake 会记录所提供镜像的特定版本。在以下情况下,Snowflake 会部署相同的镜像版本,即使仓库中的镜像已更新也是如此:
当恢复暂停的服务时(使用 ALTER SERVICE ...RESUME)。
当自动扩缩添加更多服务实例时。
当在集群维护期间重新启动服务实例时。
但是,当您调用 ALTER SERVICE ... <fromSpecification> 时,Snowflake 会使用仓库中该镜像的最新版本。
如果您是服务所有者,则 DESCRIBE SERVICE 命令的输出包括服务规范,其中包括镜像摘要(规范中 sha256 字段的值),如下所示:
ALTER SERVICE 可能会影响与服务的通信(请参阅 使用服务)。
如果 ALTER SERVICE ...<fromSpecification> 移除了一个端点或移除了使用端点时所需的相关权限(请参阅 规范参考中的 serviceRoles),因此对服务的访问将失败。有关更多信息,请参见 使用服务。
在升级过程中,新连接可能会路由到新版本。如果新服务版本不向后兼容,它将中断任何正在进行的服务使用。例如,使用服务函数的持续查询可能会失败。
备注
当更新的服务代码是带容器的原生应用程序的一部分时,您可以使用 SYSTEM$WAIT_FOR_SERVICES 系统函数暂停原生应用程序设置脚本,以允许服务完全升级。有关更多信息,请参阅 升级应用程序(旧版)。
监控滚动更新¶
当多个服务实例运行时,Snowflake 会根据服务实例的 ID 降序执行滚动更新。使用以下命令监控服务更新:
DESCRIBE SERVICE 和 SHOW SERVICES:
如果服务正在升级,则输出中的
is_upgrading列显示 TRUE。输出中的
spec_digest列表示当前服务规范的规范摘要。您可以定期执行此命令;spec_digest值中的更改表示已触发服务升级。仅在is_upgrading为 FALSE 后,spec_digest才在使用中;否则,服务升级仍在进行中。使用 SHOW SERVICE INSTANCES IN SERVICE 命令检查是否所有实例都已更新到最新版本,如下所述。
SHOW SERVICE INSTANCES IN SERVICE:
输出中的
status列提供滚动升级过程中每个服务实例的状态。在升级过程中,您将观察每个服务实例的转换状态,例如 TERMINATING 至 PENDING,以及 PENDING 至 READY。在服务升级期间,此命令输出中的
spec_digest列可能显示与 SHOW SERVICES(始终返回最新的规范摘要)不同的值。 此区别只是表示服务升级正在进行中,并且服务实例仍在运行旧版本的服务。
获取服务信息¶
您可以使用以下命令:
使用 DESCRIBE SERVICE 命令检索服务的属性和状态。输出返回所有服务属性。
使用 SHOW SERVICES 命令列出您具有权限的当前服务(包括作业服务)。输出提供了这些服务的一些属性和状态。
默认情况下,输出会列出当前数据库和架构中的服务。您还可以指定以下任何范围。例如:
列出账户、特定数据库或特定架构中的服务: 例如,使用 IN ACCOUNT 筛选器列出 Snowflake 账户中的服务,不管服务属于哪个数据库或架构。如果您在账户中的多个数据库和架构中创建了 Snowflake 服务,这将非常有用。与所有其他命令一样,SHOW SERVICES IN ACCOUNTS 也受权限限制,仅返回所使用角色有查看权限的服务。
您还可以指定 IN DATABASE 或 IN SCHEMA,以列出当前(或指定)数据库或架构中的服务。
列出在计算池中运行的服务: 例如,使用 IN COMPUTE POOL 筛选器列出计算池中运行的服务。
列出以前缀开头或与模式匹配的服务: 您可以应用 LIKE 和 STARTS WITH 筛选器,按名称筛选服务。
列出作业服务或从列表中排除作业服务: 您可以使用 SHOW JOB SERVICES 或 SHOW SERVICES EXCLUDE JOBS,仅列出作业服务或排除作业服务。
您还可以将这些选项组合起来,自定义 SHOW SERVICES 输出。
使用 SHOW SERVICE INSTANCES IN SERVICE 命令检索服务实例的属性。
使用 SHOW SERVICE CONTAINERS IN SERVICE 命令检索服务实例的属性和状态。
调用 GET_JOB_HISTORY 函数以获取在指定时间范围内运行的作业的作业历史记录。
调用 <service_name>!SPCS_WAIT_FOR 函数,等待并在特定时间后检索服务状态(包括作业服务的状态)。
监控服务¶
Snowpark Container Services 提供一些工具,用于监控账户中的计算池及其上运行的服务。有关更多信息,请参阅 Snowpark Container Services:监控服务。
使用服务¶
创建服务后,同一账户(创建服务的账户)中的用户可以使用该服务。如图所示,有三种使用服务的方法。用户需要访问具有必要权限的角色。
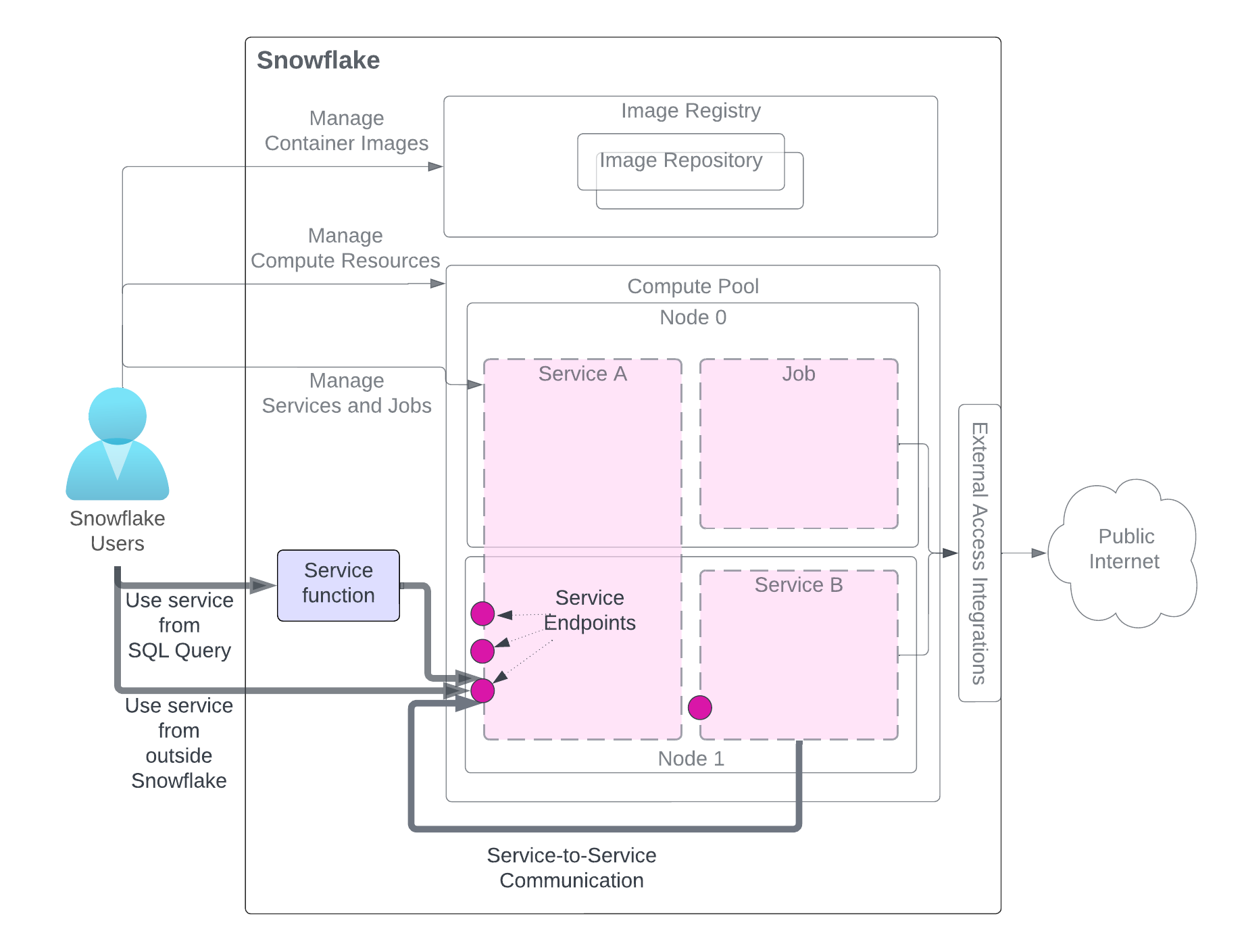
该图表突出显示了使用服务的方法,而为清楚起见,其他与服务相关的组件显示为灰色。有关服务组件的详细说明,请参阅本页开头的图表。
**通过 SQL 查询使用服务**(服务函数):您可以创建服务函数、与服务关联的用户定义函数 (UDF),然后将其用于 SQL 查询并利用您的服务提供的自定义数据处理。有关示例,请参阅 教程 1。
**从 Snowflake 外部使用服务**(入口):您可以将一个或多个服务端点声明为公共端点,以允许网络入口访问该服务。这可用于构建 Web 应用程序,也可以通过您的 Snowflake 数据公开 APIs。有关示例,请参阅 教程 1。
Use service from another service (Service-to-service communications): Services can communicate with each other by using Snowflake-assigned service DNS name for service-to-service communication For an example, see Tutorial 4.
如图所示,当使用这些方法中的任何一种与服务进行通信时,您会向该服务公开的端点发送请求并获得结果。
备注
Service functions cannot be used to communicate with a job service.
以下各节提供了详细信息。
服务函数:使用 SQL 查询中的服务¶
服务函数是使用 CREATE FUNCTION (Snowpark Container Services) 创建的用户定义函数 (UDF)。不过,您不用直接编写 UDF 代码,而可将 UDF 与您的服务关联起来。请注意,您只能将服务函数与支持 HTTP 协议的服务端点关联(请参阅 spec.endpoints 字段(可选))。
例如,在 教程 1 中,您创建了一个名为 echo_service 的服务,它公开了服务规范中定义的一个端点 (echoendoint):
echoendpoint 是一个用户友好型端点名称,代表相应的端口 (8080)。要与此服务端点通信,需要提供 SERVICE 和ENDPOINT 参数,创建一个服务函数,如下所示:
AS 参数提供服务代码的 HTTP 路径。您可以从服务代码中获取该路径值。例如,以下代码行来自 教程 1 中的 service.py。
您可以在 SELECT 语句中调用服务函数,如下所示:
Snowflake 将请求定向到相关的服务端点和路径。
备注
服务函数用于与服务通信,而不是与作业通信。换句话说,您只能将服务(而不是作业)与服务函数关联起来。
数据交换格式¶
对于服务函数和应用程序容器之间的数据交换,Snowflake 遵循外部函数使用的相同格式(请参阅 数据格式)。例如,假设有数据行存储在表 (input_table) 中:
要将这些数据发送到服务,您需要将这些行作为参数传递,从而调用服务函数:
Snowflake 会向容器发送一系列请求,请求正文中的数据行批次格式如下:
然后,容器会以以下格式返回输出结果:
所示输出示例假定结果是一个单列表,包含行(“a”、“b”...)。
配置批处理¶
CREATE FUNCTION 和 ALTER FUNCTION 命令支持用于配置 Snowflake 如何处理服务所处理的数据批次的参数。
配置批次大小
您可以使用 MAX_BATCH_ROWS 参数来限制批次大小,即 Snowflake 在单个请求中向您的服务发送的最大行数。这有助于控制传输的数据量。如果您的服务支持多个实例或并发请求,这也可能导致更多、更小的批次可以并行处理。
处理错误
您可以使用以下参数进行批次错误处理:
ON_BATCH_FAILURE、MAX_BATCH_RETRIES和BATCH_TIMEOUT_SECS。
例如,以下 ALTER FUNCTION 命令配置 my_echo_udf 服务函数的 MAX_BATCH_ROWS 和 MAX_BATCH_RETRIES 参数:
创建和管理服务函数所需的权限¶
要创建和管理服务函数,角色需要具备以下权限:
当前角色必须具有为 CREATE FUNCTION 或 ALTER FUNCTION 命令中引用的端点授予的服务角色。
要在 SQL 查询中使用服务函数,当前会话必须具有对该服务函数拥有使用权限的角色,并且必须向该服务函数的所有者角色授予关联服务端点的服务角色。
以下示例脚本显示了如何授予创建和使用服务函数的权限:
入口:使用来自 Snowflake 外部的服务¶
您可以在服务规范中将一个或多个端点声明为公共端点,以允许用户从公共场所使用该服务。请注意,用户必须是创建该服务的同一 Snowflake 账户中的 Snowflake 用户。
请注意,仅允许通过 HTTP 端点使用入口(请参阅 spec.endpoints 字段(可选))。
入口身份验证¶
当用户被授予允许访问公共端点的服务角色时,即可访问该端点。(请参阅 访问服务端点所需的权限(服务角色))。
然后,这些用户可以使用浏览器或以编程方式访问公共端点:
Accessing a public endpoint by using a browser: When the user uses a browser to access a public endpoint, Snowflake automatically redirects the user to a sign-in page. The user must provide their Snowflake credentials to sign in. After successfully signing in, the user has access to the endpoint. Behind the scenes, the user sign-in generates an OAuth token from Snowflake. The OAuth token is then used to send a request to the service endpoint.
For an example, see Tutorial 1.
Accessing a public endpoint programmatically: There are three ways for programmatic clients to access endpoints:
Using a programmatic access token (PAT): Your application passes the token in the
Authorizationheader of requests to the endpoint to represent its identity.Using key-pair authentication: Your application generates a JWT by using a key pair, exchanges the JWT with Snowflake for an OAuth token, and then passes the OAuth token in the
Authorizationheader of requests to the endpoint to represent its identity.Using the Python connector: Your application uses the Python connector to generate a session token, and then passes the session token in the
Authorizationheader of requests to the endpoint to represent its identity.
For related examples, see Tutorial 8.
入口请求中的用户特定标头¶
当公共端点的请求到达时,Snowflake 会自动将以下标头连同 HTTP 请求一起传递给容器。
您的容器代码可以选择读取标头信息,知道调用者是谁,并为不同用户应用特定于上下文的自定义。此外,Snowflake 还可以选择包含 Sf-Context-Current-User-Email 标头。要包含此标头,请联系 ` Snowflake 支持部门 `_。
服务到服务通信¶
服务实例可通过 TCP(包括 HTTP)直接相互通信。这既适用于属于同一服务的实例,也适用于属于不同服务的实例。
实例只能在服务规范中声明的 端点 上接收通信(请求)。客户端(发送请求的服务)必须具备连接该端点所需的角色和权限。(请参阅 访问服务端点所需的权限(服务角色))
默认情况下,服务实例可以在已声明端点上连接到同一服务的其他实例。从广义上讲,服务的 所有者角色 拥有连接到具有相同所有者角色的服务端点的权限。
为了使客户端服务连接到具有不同所有者角色的服务的端点,该客户端服务的所有者角色需要使用 服务角色 授予对其他服务的端点的访问权限,以调用该端点。有关更多信息,请参阅 访问服务端点所需的权限(服务角色)。
如果您想防止服务之间相互通信(出于安全等原因),请使用不同的 Snowflake 角色来创建这些服务。
可以使用服务 IP 地址或服务实例 IP 地址访问服务实例。
使用 IP 服务地址的请求会被路由到负载平衡器,而负载平衡器又会将请求路由到随机选择的服务实例。
使用服务实例 IP 地址的请求会直接路由到特定的服务实例。连接到使用
portRange ` 字段定义的端点时,必须使用服务实例 IP(请参见 :ref:`label-spcs_spec_ref_spec_endpoints)。
这两个 IP 地址都可使用 Snowflake 自动分配给每项服务的 DNS 名称进行查找。请注意,无法使用 DNS 连接到特定实例。例如,使用服务实例 DNS 名称构建 URL 没有意义,因为无法使用服务实例 DNS 名称来引用特定的服务实例。
启用 2025_01 行为变更捆绑包 时,服务实例 IP 的地址会显示在 SHOW SERVICE INSTANCES IN SERVICE 命令的输出中。
For a service-to-service communication example, see Tutorial 4.
请注意,如果创建服务端点仅为了允许服务到服务通信,则应该使用 TCP 协议(请参见 spec.endpoints 字段(可选))。
服务 DNS 名称¶
DNS 名称格式为:
使用 /sql-reference/sql/show-services`(或 :doc:/sql-reference/sql/desc-service`)获取服务的 DNS 名称。前面的 DNS 名称是完全限定名称。在同一架构下创建的服务可以只使用 <service-name> 进行通信。不同架构或数据库中的服务必须提供哈希值,如 <service-name>.<hash> 或提供完全限定名称 (:code:`<service-name>.<hash>.svc.spcs.internal `)。
使用 SYSTEM$GET_SERVICE_DNS_DOMAIN 函数查找给定架构的 DNS 域。DNS 哈希域特定于当前版本的架构。请注意以下事项:
如果该架构或其数据库重命名,哈希值不会变更。
如果架构被删除,然后重新创建(例如使用 CREATE OR REPLACE SCHEMA),则新架构将有一个新的哈希值。 如果您 UNDROP 架构,则哈希值保持不变。
DNS 名称有以下限制:
您的服务名称必须是有效的 DNS 标签。(另请参阅 ` <https://www.ietf.org/rfc/rfc1035.html#section-2.3.1 (https://www.ietf.org/rfc/rfc1035.html#section-2.3.1)> `_)。否则,创建服务将失败。
Snowflake 会将服务名称中的下划线 (_) 替换为 DNS 名称中的短划线 (-)。
DNS 名称仅用于在同一账户中运行的服务之间的 Snowflake 内部通信。从互联网访问此名称。
服务实例 DNS 名称¶
服务实例 DNS 名称格式为:
解析到服务实例 IP 地址列表,每个服务实例对应一个地址。请注意,DNS 返回的 IP 地址列表顺序没有保证。DNS 名称只应与 DNS APIs 一起使用,不应用作 URL 中的主机名。我们希望应用程序将此主机名与 DNS APIs 结合使用来收集服务实例集 IPs,然后以编程方式直接连接到这些实例 IPs。
可以通过此 IP 地址列表创建一个网状网络,用于在特定服务实例之间进行直接通信。
要选择的 DNS 名称¶
在服务到服务通信中连接服务时,选择使用哪个 DNS 名称需要考虑以下因素。
当出现以下情况时,请使用服务 DNS 名称:
您需要以尽可能简单的方式访问特定目标端口。
您希望将每个请求发送到随机选择的服务实例。
您不知道应用程序框架如何执行和缓存 DNS 响应。
出现以下情况时,请使用服务实例 DNS 名称或服务实例 IP:
您希望找到所有服务实例的 IP 地址。
您想跳过中间负载平衡器。
您使用的分布式框架或数据库(如 Ray 或 Cassandra)以服务实例 IP 地址作为身份。
Manage types of services allowed in your account¶
Snowflake supports different types of services (workload types) that you can create in your account. These types include user-deployed workloads, such as services and jobs, and first-party workloads that are managed by Snowflake, such as notebooks, model serving, and ML jobs. For a list of workload types, see ALLOWED_SPCS_WORKLOAD_TYPES.
When you list services in your account using SHOW SERVICES, you can include a filter to list only specific workload types. For example, show user-deployed services only:
You can restrict the types of workloads that are allowed in your Snowflake account by using the account-level parameters ALLOWED_SPCS_WORKLOAD_TYPES and DISALLOWED_SPCS_WORKLOAD_TYPES. For example, to allow only NOTEBOOK workloads, run the following statement:
备注
Workload types that are specified in DISALLOWED_SPCS_WORKLOAD_TYPES can't be deployed. If you configure both ALLOWED_SPCS_WORKLOAD_TYPES and DISALLOWED_SPCS_WORKLOAD_TYPES, the disallowed list takes precedence. For example, if both parameters specify the NOTEBOOK workload type, NOTEBOOK workloads aren't allowed to run on Snowpark Container Services.
Services that are created before you configure these account-level parameters continue to run. However, if you suspend a service whose workload type is disallowed, you can't restart it.
To delete all the previously created services of disallowed types, run the ALTER COMPUTE POOL ... STOP ALL OF TYPE command.
Passing credentials to a container using Snowflake secrets¶
There are many reasons why you might want to pass Snowflake managed credentials into your container. For example, your service might communicate with external endpoints (outside Snowflake), in which case you will need to provide credential information in your container for your application code to use.
To provide credentials, first store them in Snowflake secret objects. Then, in the service specification, use containers.secrets to specify which secret objects to use and where to place them inside the container. You can either pass these credentials to environment variables in the containers, or make them available in local files in the containers.
Specifying Snowflake secrets¶
Specify a Snowflake secret by name or reference (reference is applicable only in the Native Application scenario):
Pass Snowflake secret by name: You can pass a secret name as the
snowflakeSecretfield value.Note that you can optionally specify
<secret-name>directly as thesnowflakeSecretvalue.Pass Snowflake secret by reference: When using Snowpark Container Services to create a Native App (an app with containers), the app producer and consumers use different Snowflake accounts. In some contexts an installed Snowflake Native App needs to access existing secret objects in the consumer account that exist outside the APPLICATION object. In this case, developers can use the "secrets by reference" specification syntax to handle credentials as shown:
Note that the specification uses
objectReferenceinstead ofobjectNameto provide a secret reference name.
Specifying secrets placement inside the container¶
You can tell Snowflake to either place the secrets in the containers as environment variables or write them into local container files.
Pass secrets as environment variables¶
To pass Snowflake secrets to containers as environment variables, include envVarName in the containers.secrets field.
The secretKeyRef value depends on the type of Snowflake secret. Possible values are the following:
usernameorpasswordif the Snowflake secret is of thepasswordtype.secret_stringif the Snowflake secret is of thegeneric_stringtype.
Note that Snowflake does not update secrets passed as environment variables after a service is created.
Example 1: Passing secrets of the password type as environment variables¶
In this example, you create the following Snowflake secret object of the password type:
To provide this Snowflake secret object to the environment variables (for example, LOGIN_USER and LOGIN_PASSWORD)
in your container, add the following containers.secrets field in the specification file:
In this example, the snowflakeSecret value is a fully qualified object name because secrets can be stored in a different schema than the service that is being created.
The containers.secrets field in this example is a list of two snowflakeSecret objects:
The first object maps
usernamein the Snowflake secret object to theLOGIN_USERenvironment variable in your container.The second object maps the
passwordin the Snowflake secret object to theLOGIN_PASSWORDenvironment variable in your container.
Example 2: Passing secrets of the generic_string type as environment variables¶
In this example, you create the following Snowflake secret object of the generic_string type:
To provide this Snowflake secret object to environment variables (for example, GENERIC_SECRET) in your container, you add the
following containers.secrets field in the specification file:
Write secrets in local container files¶
To make Snowflake secrets available to your application container in local container files, include a containers.secrets
field:
To make Snowflake secrets available to your application container in local container files, include directoryPath in the containers.secrets:
Snowflake populates necessary files for the secret in this specified directoryPath; specifying the secretKeyRef is not necessary. Depending on the secret type, Snowflake creates the following files in the container under the directory path you provided:
usernameandpasswordif the Snowflake secret is of thepasswordtype.secret_stringif the Snowflake secret is of thegeneric_stringtype.access_tokenif the Snowflake secret is of theoauth2type.
备注
After a service is created, if the Snowflake secret object is updated, Snowflake will update the corresponding secret files in the running containers.
Example 1: Passing secrets of the password type in local container files¶
In this example, you create the following Snowflake secret object of the password type:
To make these credentials available in local container files, add the following containers.secrets field in the
specification file:
When you start your service, Snowflake creates two files inside the container: /usr/local/creds/username and
/usr/local/creds/password. Your application code can then read these files.
Example 2: Passing secrets of the generic_string type in local container files¶
In this example, you create the following Snowflake secret object of the generic_string type:
To provide this Snowflake secret object in local container files, you add the
following containers.secrets field in the specification file:
When you start your service, Snowflake creates this file inside the containers: /usr/local/creds/secret_string.
Example 3: Passing secrets of the oauth2 type in local container files¶
In this example, you create the following Snowflake secret object of the oauth2 type:
To make these credentials available in local container files, add the following containers.secrets field in the
specification file:
Snowflake fetches the access token from the OAuth secret object and creates /usr/local/creds/access_token in the
containers.
When a service uses secrets of the oauth2 type, the service is expected to use that secret to access an internet destination. An oauth secret must be allowed by External Access Integration (EAI); otherwise CREATE SERVICE or EXECUTE JOB SERVICE will fail. This extra EAI requirement only applies to secrets of the oauth2 type and not to other types of secrets.
In summary, the typical steps in creating such a service are:
Create a secret of the oauth2 type (shown earlier).
Create an EAI to allow use of the secret by a service. For example:
Create a service that includes a
containers.secretsfield in the specification. That also specifies the optional EXTERNAL_ACCESS_INTEGRATIONS property to include an EAI to allow use of the oauth2 secret.An example CREATE SERVICE (with inline specification) command:
For more information about egress, see 配置服务出口.
准则和限制¶
For more information, see Snowpark Container Services:准则和限制.