In Tutorial 1 and Tutorial 2, you use the SQL interface to create a Snowpark Container Services service and job. In this tutorial you use the Snowflake Python APIs to create the same service and job and thus explore using the Snowflake Python APIs to manage Snowpark Container Services resources.
The tutorial uses a Snowflake notebook to execute the Python code, but the code is independent of the notebook and you can execute the code in other environments.
Create a notebook. For instructions, see Create a new notebook. Note that the Python environment you choose in the UI (Run on warehouse or Run on container) doesn’t matter.
From the Packages drop-down menu, choose the “snowflake” package and install the latest version of the Snowflake Python APIs library.
Before you can create a service, you need Snowflake objects, such as a database, a user, a role, a compute pool, and an image repository. Some of these objects are account-scoped object that require administrative privileges to create them. The names of the objects created are defined in the preceding step.
Role (test_role). You grant this role all the privileges required to create and use the service. In the code, you grant this role to the current user to enable the user to create and use the service.
Database (tutorial_db). In the next step, you create a schema in this database.
Compute pool (tutorial_compute_pool). Your service container executes in this compute pool.
Warehouse (tutorial_warehouse). When the service connects to Snowflake and executes queries, this warehouse is used to execute the queries.
from snowflake.core.compute_pool import ComputePool
from snowflake.core.database import Database
from snowflake.core.grant import Grant, Grantees, Privileges, Securable, Securables
from snowflake.core.role import Role
from snowflake.core.warehouse import Warehouse
session = get_active_session()
session.use_role("ACCOUNTADMIN")
root = Root(session)
# CREATE ROLE test_role;
root.roles.create(
Role(name=user_role_name),
mode=CreateMode.if_not_exists)
print(f"Created role:", user_role_name)
# GRANT ROLE test_role TO USER <user_name>
root.grants.grant(Grant(
securable=Securables.role(user_role_name),
grantee=Grantees.user(name=current_user),
))
# CREATE COMPUTE POOL IF NOT EXISTS tutorial_compute_pool# MIN_NODES = 1 MAX_NODES = 1# INSTANCE_FAMILY = CPU_X64_XS
root.compute_pools.create(
mode=CreateMode.if_not_exists,
compute_pool=ComputePool(
name=compute_pool_name,
instance_family="CPU_X64_XS",
min_nodes=1,
max_nodes=2,
)
)
# GRANT USAGE, OPERATE, MONITOR ON COMPUTE POOL tutorial_compute_pool TO ROLE test_role
root.grants.grant(Grant(
privileges=[Privileges.usage, Privileges.operate, Privileges.monitor],
securable=Securables.compute_pool(compute_pool_name),
grantee=Grantees.role(name=user_role_name)
))
print(f"Created compute pool:", compute_pool_name)
# CREATE DATABASE IF NOT EXISTS tutorial_db;
root.databases.create(
Database(name=database_name),
mode=CreateMode.if_not_exists)
# GRANT ALL ON DATABASE tutorial_db TO ROLE test_role;
root.grants.grant(Grant(
privileges=[Privileges.all_privileges],
securable=Securables.database(database_name),
grantee=Grantees.role(name=user_role_name),
))
print("Created database:", database_name)
# CREATE OR REPLACE WAREHOUSE tutorial_warehouse WITH WAREHOUSE_SIZE='X-SMALL';
root.warehouses.create(
Warehouse(name=warehouse_name, warehouse_size="X-SMALL"),
mode=CreateMode.if_not_exists)
# GRANT USAGE ON WAREHOUSE tutorial_warehouse TO ROLE test_role;
root.grants.grant(Grant(
privileges=[Privileges.usage],
grantee=Grantees.role(name=user_role_name),
securable=Securables.warehouse(warehouse_name)
))
print("Created warehouse:", warehouse_name)
# GRANT BIND SERVICE ENDPOINT ON ACCOUNT TO ROLE test_role
root.grants.grant(Grant(
privileges=[Privileges.bind_service_endpoint],
securable=Securables.current_account,
grantee=Grantees.role(name=user_role_name)
))
print("Done: GRANT BIND SERVICE ENDPOINT")
As you create resources, the code also grants required privileges to the role (test_role) so the role can use these resources. Additionally, note that the echo service you create in this tutorial exposes one public endpoint. This public endpoint allows other users in your account to access the service from the public web (ingress). To create a service with a public endpoint, the role (test_role) must have the BIND SERVICE ENDPOINT privilege on the account.
The Python code in this section uses the test_role role to create a schema and objects in that schema. You don’t need administrative privileges to create these resources.
Schema (data_schema). You create an image repository, service, and job in this schema.
Image repository (tutorial_repository). You store your application image in this repository.
Stage (tutorial_stage). The stage is created only for illustration. While not demonstrated in this tutorial, stages can be used to pass data into
or collect data from your services.
请注意,仅当资源不存在时,脚本才会创建资源。
from snowflake.core.image_repository import ImageRepository
from snowflake.core.schema import Schema
from snowflake.core.stage import Stage, StageDirectoryTable
session = get_active_session()
session.use_role(user_role_name)
root = Root(session)
# CREATE SCHEMA IF NOT EXISTS {schema_name}
schema = root.databases[database_name].schemas.create(
Schema(name=schema_name),
mode=CreateMode.if_not_exists)
print("Created schema:", schema.name)
# CREATE IMAGE REPOSITORY IF NOT EXISTS {repo}
repo = schema.image_repositories.create(
ImageRepository(name=repo_name),
mode=CreateMode.if_not_exists)
print("Create image repository:", repo.fully_qualified_name)
repo_url = repo.fetch().repository_url
print("image registry hostname:", repo_url.split("/")[0])
print("image repository url:", repo_url + "/")
#CREATE STAGE IF NOT EXISTS tutorial_stage# DIRECTORY = ( ENABLE = true );
stage = schema.stages.create(
Stage(
name=stage_name,
directory_table=StageDirectoryTable(enable=True)),
mode=CreateMode.if_not_exists)
print("Created stage:", stage.fully_qualified_name)
You download locally the code as described in Tutorial 1, use Docker commands to build the image, and upload it to the image repository in your account.
Verify that the compute pool is ready. After you create a compute pool, it takes some time for Snowflake to provision all the nodes. Ensure that
the compute pool is ready before creating a service, because service containers execute within the specified compute pool.
创建并运行单元格以获取计算池状态:
import time
session = get_active_session()
session.use_role(user_role_name)
root = Root(session)
cp = root.compute_pools[compute_pool_name]
cpm = cp.fetch()
print(cpm.state, cpm.status_message)
if cpm.state == 'SUSPENDED':
cp.resume()
while cpm.state in ['STARTING', 'SUSPENDED']:
time.sleep(5)
cpm = cp.fetch()
print(cpm.state, cpm.status_message)
The code fetches the compute pool model (cpm) from the compute pool resource (cp) to retrieve the current compute pool state. If the compute pool is suspended, the code resumes the compute pool. The code loops, pausing for five seconds each time, until the compute pool is no longer in the STARTING or SUSPENDED state.
The last line of output should be “IDLE” or “ACTIVE”, which indicates that the compute pool is ready to run your service. For more information, see Compute pool lifecycle. If the compute pool is not ready, your services can’t start.
The code retrieves the repository URL, as done in the preceding step.
The code then creates the echo_service using an inline specification and the image from the specified image repository.
Snowflake sends a POST request to the service endpoint (echoendpoint). Upon receiving the request, the service echoes the input string in the response.
输出:
+--------------------------+|**MY_ECHO_UDF('HELLO!')**||------------------------- || Bob said hello!|+--------------------------+
从浏览器访问服务公开的公共端点。
获取公共端点的 URL。
# helper to check if service is ready and return endpoint urldefget_ingress_for_endpoint(svc, endpoint):
for _ inrange(10): # only try 10 times# Find the target endpoint.
target_endpoint = Nonefor ep in svc.get_endpoints():
if ep.is_public and ep.name == endpoint:
target_endpoint = ep
break;
else:
print(f"Endpoint {endpoint} not found")
returnNone# Return endpoint URL or wait for it to be provisioned.if target_endpoint.ingress_url.startswith("Endpoints provisioning "):
print(f"{target_endpoint.ingress_url} is still in provisioning. Wait for 10 seconds.")
time.sleep(10)
else:
return target_endpoint.ingress_url
print("Timed out waiting for endpoint to become available")
endpoint_url = get_ingress_for_endpoint(echo_service, "echoendpoint")
print(f"https://{endpoint_url}/ui")
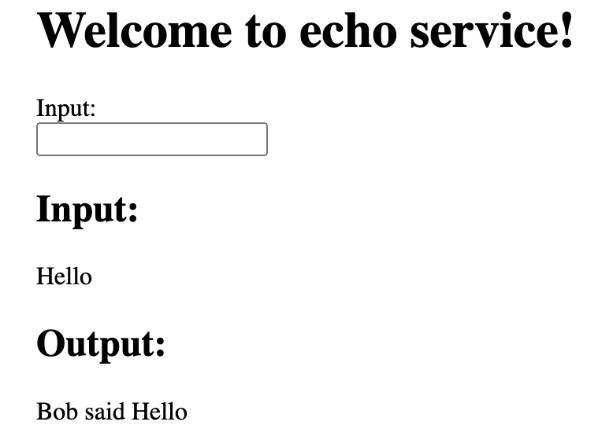
Paste the printed URL in a browser window. This causes the service to execute the ui() function (see echo_service.py).
In Tutorial 2, you use the SQL interface to create a Snowpark Container Services job. In this section, you create the same job using the Snowflake Python APIs.
session = get_active_session()
session.use_role(user_role_name)
# show that above job wrote to results table
session.sql(f"select * from {database_name}.{schema_name}.results").collect()
Stop the service and drop it. After dropping the service, Snowflake by default automatically suspends the compute pool (assuming there are no other services and job services running). For more information, see compute pool lifecycle.
session = get_active_session()
session.use_role(user_role_name)
root = Root(session)
schema = root.databases[database_name].schemas[schema_name]
# now let's clean up
schema.functions["my_echo_function(TEXT)"].drop()
schema.services[service_name].drop()