- Categories:
MATCH_
Recognizes matches of a pattern in a set of rows. MATCH_RECOGNIZE accepts a set of rows (from a table,
view, subquery, or other source) as input, and returns all matches for a given row pattern within this
set. The pattern is defined similarly to a regular expression.
此子句可以返回:
- 属于每个匹配项的所有行。
- 每个匹配项一个汇总行。
MATCH_RECOGNIZE is typically used to detect events in time series. For example, MATCH_RECOGNIZE can search a
stock price history table for shapes like V (down followed by up) or W (down, up, down, up).
MATCH_RECOGNIZE is an optional subclause of the FROM clause.
Note
You cannot use the MATCH_RECOGNIZE clause in a recursive common table expression (CTE).
语法
必需的分子句
DEFINE:定义符号¶
符号(也称为“模式变量”)是模式的基本组成部分。
符号由表达式定义。如果某行的表达式求值结果为 true,则向该行分配符号。可以向一行分配多个符号。
Symbols that are not defined in the DEFINE clause, but are used in the pattern, are always assigned to all
rows. Implicitly, they are equivalent to the following example:
Patterns are defined based on symbols and operators.
PATTERN:指定要匹配的模式¶
模式定义了表示匹配项的有效行序列。模式的定义类似于正则表达式 (regex),由符号、运算符和量词构成。
For example, suppose that symbol S1 is defined as stock_price < 55, and symbol S2 is defined
as stock price > 55. The following pattern specifies a sequence of rows in which the stock price increased
from less than 55 to greater than 55:
以下是有关模式定义的更复杂示例:
以下部分详细描述了此模式的各个组成部分。
Note
MATCH_RECOGNIZE uses backtracking to match patterns. As is the case with other regular expression engines that use backtracking, some combinations of patterns and data to match can take a long time to execute, which can result in high computation costs.
To improve performance, define a pattern that is as specific as possible:
- Make sure that each row matches only one symbol or a small number of symbols
- Avoid using symbols that match every row (e.g. symbols not in the
DEFINEclause or symbols that are defined as true) - Define an upper limit for quantifiers (e.g.
{,10}instead of*).
For example, the following pattern can result in increased costs if no rows match:
If there is an upper limit to the number of rows that you want to match, you can specify that limit in the quantifiers to
improve performance. In addition, rather than specifying that you want to find any_symbol that follows symbol1, you can
look for a row that is not symbol1 (not_symbol1, in this example);
In general, you should monitor the query execution time to verify that the query is not taking longer than expected.
- Symbols:
符号与其分配到的行相匹配。以下符号可用:
-
symbol. For example,S1, … ,S4Those are symbols that were defined in theDEFINEsubclause and are evaluated per row. (These can also include symbols that were not defined and are automatically assigned to all rows.) -
^(Start of partition.) This is a virtual symbol that denotes the start of a partition and has no row associated with it. You can use it to require a match to start only at the beginning of a partition.For an example, see Matching Patterns Relative to the Beginning or End of a Partition.
-
$(End of partition.) This is a virtual symbol that denotes the end of a partition and has no row associated with it. You can use it to require a match to end only at the end of a partition.For an example, see Matching Patterns Relative to the Beginning or End of a Partition.
- Quantifiers:
量词可以放在符号或运算之后。量词表示关联符号或运算出现的最小和最大次数。以下量词可用:
Quantifier Meaning +1 or more. For example, ( {- S3 -} S4 )+.*0 or more. For example, S2*?.?0 or 1. {n}Exactly n. {n,}n or more. {,m}0 to m. {n, m}n to m. For example, PERMUTE(S1, S2){1,2}.
By default, quantifiers are in “greedy mode”, which means they try to match the maximum quantity if possible. To put a
quantifier into “reluctant mode”, in which the quantifier tries to match the minimum quantity if possible,
place a ? after the quantifier (e.g. S2*?).
- Operators:
运算符指定在行序列中应以何种顺序出现符号或其他运算,以形成有效的匹配。以下运算符可用:
Operator Meaning ... ...(space)Concatenation. Specifies that a symbol or operation should follow another one. For example, S1 S2means that the condition defined forS2should occur after the condition defined forS1.{- ... -}Exclusion. Excludes the contained symbols or operations from the output. For example, {- S3 -}excludes operatorS3from the output. Excluded rows will not appear in the output, but will be included in the evaluation ofMEASURESexpressions.( ... )Grouping. Used to override the precedence of an operator or to apply the same quantifier for symbols or operations in the group. In this example, the quantifier +applies to the sequence{- S3 -} S4, not merelyS4.PERMUTE(..., ...)Permutation. Matches any permutation of the specified patterns. For example, PERMUTE(S1, S2)matches eitherS1 S2orS2 S1.PERMUTE()takes an unlimited number of arguments.... | ...Alternative. Specifies that either the first symbol or operation or the other one should occur. For example, ( S3 S4 ) | PERMUTE(S1, S2). The alternative operator has precedence over the concatenation operator.
可选分子句
ORDER BY:匹配前对行进行排序¶
{ORDER BY orderItem1 [ , orderItem2 ... ]}其中:
Define the order of the rows as you would for window functions. This is the order in which the individual rows of each partition are passed to the
MATCH_RECOGNIZEoperator.For more information, see Partitioning and Sorting the Rows.
PARTITION BY:将行分区到窗口¶
{PARTITION BY <expr1> [ , <expr2> ... ]}Partition the input set of rows as you would for window functions.
MATCH_RECOGNIZEperforms matching individually for each resulting partition.分区不仅将彼此相关的行进行分组,还利用了 Snowflake 的分布式数据处理能力,因为可以并行处理不同的分区。
For more information about partitioning, see Partitioning and Sorting the Rows.
MEASURES:指定其他输出列¶
“Measures” are optional additional columns that are added to the output of the MATCH_RECOGNIZE operator.
The expressions in the MEASURES subclause have the same capabilities as the expressions in the DEFINE
subclause. For further information, see Symbols.
Within the MEASURES subclause, the following functions specific to MATCH_RECOGNIZE are available:
MATCH_NUMBER()Returns the sequential number of the match. The MATCH_NUMBER starts from 1, and is incremented for each match.MATCH_SEQUENCE_NUMBER()Returns the row number within a match. The MATCH_SEQUENCE_NUMBER is sequential and starts from 1.CLASSIFIER()Returns a TEXT value that contains the symbol that the respective row matched. For example, if a row matched the symbolGT75, then theCLASSIFIERfunction returns the string “GT75”.
Note
When specifying measures, remember the restrictions mentioned in the 在 DEFINE 和 MEASURES 中使用的窗口函数的相关限制 section.
ROW(S) PER MATCH:指定要返回的行¶
指定要返回哪些行才能成功匹配。此分子句是可选的。
ALL ROWS PER MATCH: Return all rows in the match.ONE ROW PER MATCH: Return one summary row for each match, regardless of how many rows are in the match. This is the default.
请注意以下特殊情况:
-
Empty Matches: An empty match happens if a pattern is able to match against zero rows. For instance, if the pattern is defined as
A*and the first row at the beginning of a matching attempt is assigned to symbolB, then an empty match including only that row is generated, because the*quantifier in theA*pattern allows 0 occurrences ofAto be treated as a match. TheMEASURESexpressions are evaluated differently for this row:- CLASSIFIER 函数返回 NULL。
- 窗口函数返回 NULL。
- COUNT 函数返回 0。
-
Unmatched Rows: If a row was not matched against the pattern, it is called an unmatched row.
MATCH_RECOGNIZEcan be configured to return unmatched rows, too. For unmatched rows, expressions in theMEASURESsubclause return NULL.
-
排除
The exclusion syntax
({- ... -})in the pattern definition allows users to exclude certain rows from the output. If all matched symbols in the pattern were excluded, no row is generated for that match ifALL ROWS PER MATCHwas specified. Note that the MATCH_NUMBER is incremented anyway. Excluded rows are not part of the result, but are included for the evaluation ofMEASURESexpressions.
使用排除语法时,可以按以下方式指定 ROWS PER MATCH 分子句:
-
ONE ROW PER MATCH(默认)
Returns exactly one row for each successful match. The default window function semantic for window functions in the
MEASURESsubclause isFINAL.The output columns of the
MATCH_RECOGNIZEoperator are all expressions given in thePARTITION BYsubclause and allMEASURESexpressions. All resulting rows of a match are grouped by the expressions given in thePARTITION BYsubclause and theMATCH_NUMBERusing theANY_VALUEaggregation function for all measures. Therefore, if measures evaluate to a different value for different rows of the same match, then the output is non-deterministic.Omitting the
PARTITION BYandMEASURESsubclause results in an error indicating that the result does not include any columns.
对于空匹配项,将生成一行。不匹配的行不在输出中。
-
ALL ROWS PER MATCHReturns a row for each row that is part of the match, except for rows that were matched to a portion of the pattern that was marked for exclusion.
Excluded rows are still taken into account in computations in the
MEASURESsubclause.Matches might overlap based on the
AFTER MATCH SKIP TOsubclause, so the same row might appear multiple times in the output.The default window function semantic for window functions in the
MEASURESsubclause isRUNNING.The output columns of the
MATCH_RECOGNIZEoperator are the columns of the set of rows being input and the columns defined in theMEASURESsubclause.The following options are available for
ALL ROWS PER MATCH:SHOW EMPTY MATCHES (default)Add empty matches to the output. Unmatched rows are not output.OMIT EMPTY MATCHESNeither empty matches nor unmatched rows are output. However, the MATCH_NUMBER is still incremented by an empty match.WITH UNMATCHED ROWSAdds empty matches and unmatched rows to the output. If this clause is used, then the pattern must not contain exclusions.
For an example that uses exclusion to reduce irrelevant output, see Search for Patterns in Non-Adjacent Rows.
AFTER MATCH SKIP:指定匹配后在何处继续¶
此分子句指定找到正匹配项后在何处继续进行匹配。
PAST LAST ROW (default)
在当前匹配项的最后一行之后继续进行匹配。
This prevents matches that contain overlapping rows. For example, if you have a stock pattern that contains
3 V shapes in a row, then PAST LAST ROW finds one W pattern, not two.
TO NEXT ROW
在当前匹配项的第一行之后继续进行匹配。
This allows matches that contain overlapping rows. For example, if you have a stock pattern that contains 3 V
shapes in a row, then TO NEXT ROW finds two W patterns (the first pattern is based on the first two V
shapes, and the second W shape is based on the second and third V shapes; thus both patterns contain the
same V).
TO [ { FIRST | LAST } ] <symbol>
在已与给定符号匹配的第一行或最后一行(默认)处继续进行匹配。
至少需要将一行映射到给定符号,否则会引发错误。
如果这没有跳过当前匹配项的第一行,则会引发错误。
使用说明
DEFINE 和 MEASURES 子句中的表达式¶
The DEFINE and MEASURES clauses allow expressions. Those expressions can be complex and can include
window functions and special navigational functions (which are a type of
window function).
In most respects, expressions in DEFINE and MEASURES follow the rules for expressions elsewhere in Snowflake
SQL syntax. However, there are some differences, which are described below:
- Window Functions:
导航函数允许引用除当前行以外的其他行。例如,要创建定义价格下降的表达式,需要将一行中的价格与另一行中的价格进行比较。导航函数包括:
-
PREV( expr [ , offset [, default ] ] )Navigate to the previous row within the current match in the MEASURES subclause.This function is currently not available in the DEFINE subclause. Instead, you can use LAG which navigates to the previous row within the current window frame.
-
NEXT( expr [ , offset [ , default ] ] )Navigate to the next row within the current window frame. This function is equivalent to LEAD. -
FIRST( expr )Navigate to the first row of the current match in the MEASURES subclause.This function is currently not available in the DEFINE subclause. Instead, you can use FIRST_VALUE which navigates to the first row of the current window frame.
-
LAST( expr )Navigate to the last row of the current window frame. This function is similar to LAST_VALUE, but for LAST the window frame is limited to the current row of the current matching attempt when LAST is used within the DEFINE subclause.
For an example that uses the navigational functions, see Returning Information About the Match.
In general, when a window function is used inside a
MATCH_RECOGNIZEclause, the window function does not require its ownOVER (PARTITION BY ... ORDER BY ...)clause. The window is implicitly determined by thePARTITION BYandORDER BYof theMATCH_RECOGNIZEclause. (However, see 在 DEFINE 和 MEASURES 中使用的窗口函数的相关限制 for some exceptions.)In general, the window frame is also derived implicitly from the current context in which the window function is being used. The lower bound of the frame is defined as described below:
In the
DEFINEsubclause:The frame starts at the beginning of the current matching attempt except when using
LAG,LEAD,FIRST_VALUE, andLAST_VALUE.In the
MEASURESsubclause:框架在找到的匹配项的开头开始。
The edges of the window frame can be specified by using either
RUNNINGorFINALsemantics.RUNNING:通常,框架在当前行结束。但是,存在以下例外情况:
- In the
DEFINEsubclause, forLAG,LEAD,FIRST_VALUE,LAST_VALUE, andNEXT, the frame ends at the last row of the window. - In the
MEASURESsubclause, forPREV,NEXT,LAG, andLEAD, the frame ends at the last row of the window.
In the
DEFINEsubclause,RUNNINGis the default (and the only allowed) semantic.In the
MEASURESsubclause, when theALL ROWS PER MATCHsubclause is used,RUNNINGis the default.FINAL:框架在匹配项的最后一行结束。
FINALis allowed only in theMEASURESsubclause. It is the default there whenONE ROW PER MATCHapplies.-
- Symbol Predicates:
Expressions within the
DEFINEandMEASURESsubclauses allow symbols as predicates for column references.The
<symbol>indicates a row that was matched, and the<column>identifies a specific column within that row.带谓词的列引用意味着周围的窗口函数仅查看最终映射到指定符号的行。
Predicated column references can be used outside and inside of a window function. If used outside of a window function,
<symbol>.<column>is the same asLAST(<symbol>.<column>). Inside of a window function, all column references either need to be predicated with the same symbol or are all non-predicated.以下内容说明了与导航相关的函数在带谓词的列引用下的行为方式:
{PREV/LAG( ... <symbol>.<column> ... , <offset>)}Searches the window frame backwards starting from and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>, and then goes<offset>(default is 1) rows backwards, ignoring the symbol those rows were mapped to. If the searched part of the frame does not contain a row mapped to<symbol>or the search would go beyond the edge of the frame, then NULL is returned.{NEXT/LEAD( ... <symbol>.<column> ... , <offset>)}Searches the window frame backwards starting from and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>, and then goes<offset>(default is 1) rows forward, ignoring the symbol those rows were mapped to. If the searched part of the frame does not contain a row mapped to<symbol>or the search would go beyond the edge of the frame, then NULL is returned.{FIRST/FIRST_VALUE( ... <symbol>.<column> ... )}Searches the window frame forwards starting from and including the first row up to and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>. If the searched part of the frame does not contain a row mapped to<symbol>, NULL is returned.{LAST/LAST_VALUE( ... <symbol>.<column> ... )}Searches the window frame backwards starting from and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>. If the searched part of the frame does not contain a row mapped to<symbol>, NULL is returned.
Note
Restrictions on window functions are documented in the 在 DEFINE 和 MEASURES 中使用的窗口函数的相关限制 section.
在 DEFINE 和 MEASURES 中使用的窗口函数的相关限制¶
Expressions in the DEFINE and MEASURES subclauses can include window functions. However, there are some
limitations on using window functions in these subclauses. These limitations are shown in the table below:
Function DEFINE (Running) [column/symbol.column] MEASURES (Running) [column/symbol.column] MEASURES (Final) [column/symbol.column] Column ✔ / ❌ ✔ / ❌ ✔ / ✔ PREV(…) ❌ / ❌ ✔ / ❌ ✔ / ❌ NEXT(…) ✔ / ❌ ✔ / ❌ ✔ / ❌ FIRST(…) ❌ / ❌ ✔ / ❌ ✔ / ✔ LAST(…) ✔ / ❌ ✔ / ❌ ✔ / ✔ LAG() ✔ / ❌ ✔ / ❌ ✔ / ❌ LEAD() ✔ / ❌ ✔ / ❌ ✔ / ❌ FIRST_VALUE() ✔ / ❌ ✔ / ❌ ✔ / ✔ LAST_VALUE() ✔ / ❌ ✔ / ❌ ✔ / ✔ Aggregations [1] ✔ / ❌ ✔ / ✔ ✔ / ✔ Other window functions [1] ✔ / ❌ ✔ / ❌ ✔ / ❌
The MATCH_RECOGNIZE-specific functions MATCH_NUMBER(), MATCH_SEQUENCE_NUMBER(), and CLASSIFIER() are
currently not available in the DEFINE subclause.
故障排除
使用 ONE ROW PER MATCH 时出现错误消息:“SELECT with no columns”¶
When you use the ONE ROW PER MATCH clause, only columns and expressions from the PARTITION BY and MEASURES
subclauses are allowed in the projection clause of the SELECT. If you try to use MATCH_RECOGNIZE without either a
PARTITION BY or MEASURES clause, you get an error similar to SELECT with no columns.
For more information about ONE ROW PER MATCH vs. ALL ROWS PER MATCH,
see Generating One Row for Each Match vs Generating All Rows for Each Match.
示例
The topic Identifying Sequences of Rows That Match a Pattern contains many examples, including some that are simpler than
most of the examples here. If you are not already familiar with MATCH_RECOGNIZE, then you might want to read those
examples first.
以下一些示例使用下面的表和数据:
下图显示了曲线的形状:
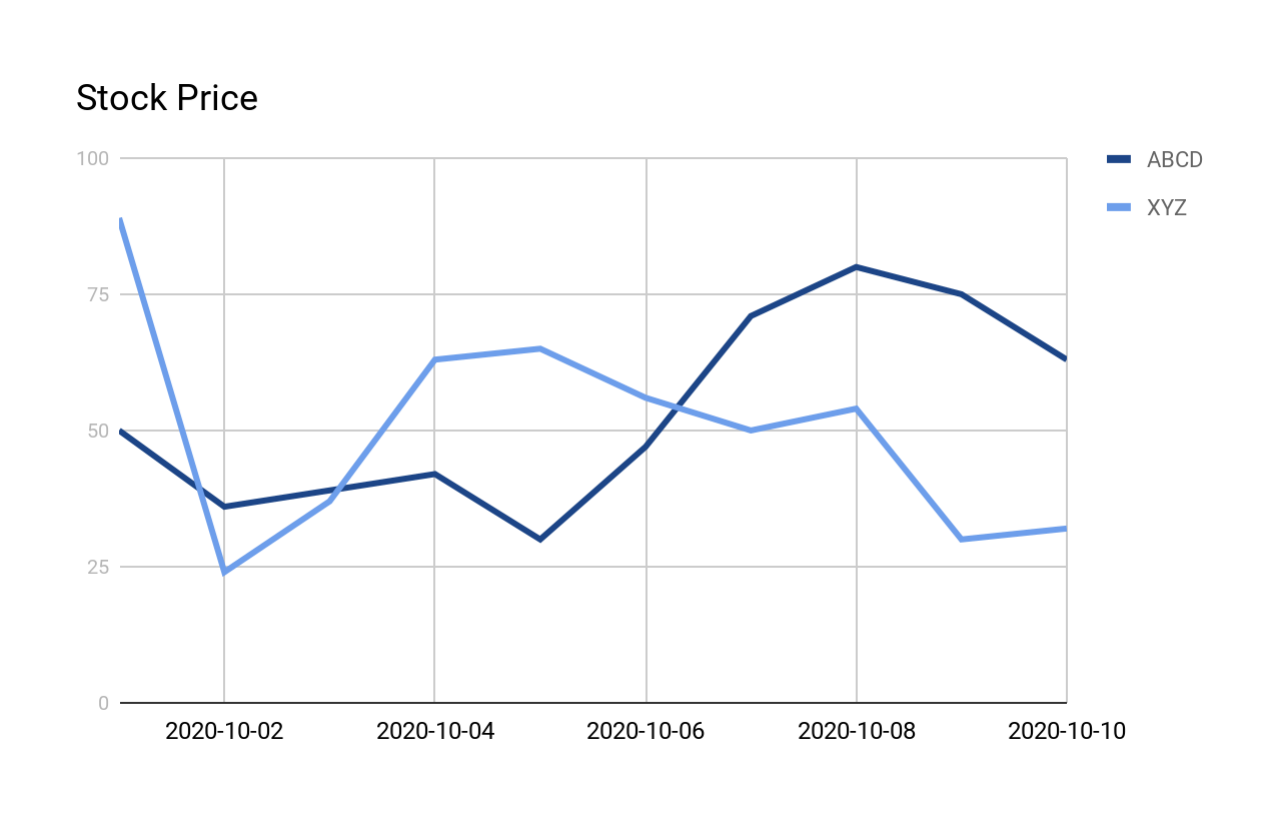
Report one summary row for each V shape¶
The following query searches for all V shapes in the previously presented stock_price_history. The output is
explained in more detail after the query and output.
输出为每个匹配项显示一行(无论匹配项中有多少行)。
输出包含以下列:
- COMPANY:公司的股票代码。
- The MATCH_NUMBER is a sequential number identifying which match this was within this data set (e.g. the first match has MATCH_NUMBER 1, the second match has MATCH_NUMBER 2, etc.). If the data was partitioned, then the MATCH_NUMBER is the sequential number within the partition (in this example, for each company/stock).
- START_DATE:模式的此次出现的开始日期。
- END_DATE:模式的此次出现的结束日期。
- ROWS_IN_SEQUENCE: This is the number of rows in the match. For example, the first match is based on the prices measured on 4 days (October 1 through October 4), so ROWS_IN_SEQUENCE is 4.
- NUM_DECREASES: This is the number of days (within the match) that the price went down. For example, in the first match, the price went down for 1 day and then went up for 2 days, so NUM_DECREASES is 1.
- NUM_INCREASES: This is the number of days (within the match) that the price went up. For example, in the first match, the price went down for 1 day and then went up for 2 days, so NUM_INCREASES is 2.
报告一家公司的所有匹配项的所有行
此示例返回每个匹配项中的所有行(而不仅仅是每个匹配项的一个汇总行)。此模式搜索“ABCD”公司的价格上涨:
省略空匹配项
此示例搜索高于公司整个图表的平均价格的价格范围。此示例省略了空匹配项。但请注意,空匹配项仍然会让 MATCH_NUMBER 递增:
演示 WITH UNMATCHED ROWS 选项¶
This example demonstrates the WITH UNMATCHED ROWS option. Like the
省略空匹配项 example above, this example searches for price ranges
above the average price of each company’s chart. Note that the quantifier in this query is +, while the
quantifier in the previous query was *:
在 MEASURES 子句中演示符号谓词¶
This example shows the use of <symbol>.<column> notation with symbol predicates: